introduzione
L'apprendimento automatico non è altro che costruire una "macchina"’ che impara’ dalla tua esperienza. E migliora con l'esperienza, proprio come gli umani. Impariamo anche dalle nostre esperienze. Destra ? Aziende come Google, Facebook, Microsoft utilizza tecniche di machine learning su larga scala.
tuttavia, un errore comune che le persone fanno è che hanno bisogno di imparare a programmare per avviare l'apprendimento automatico. Mentre la codifica diventa necessaria per chiunque sia seriamente interessato all'apprendimento automatico, ma non per avviarlo. Puoi guardare uno strumento guidato dalla GUI come Weka o anche Excel per iniziare con l'apprendimento automatico.
Qui, ti presenterò un modo più semplice per iniziare con l'apprendimento automatico.

Trovi difficile capire la codifica??
L'apprendimento automatico richiede potenti capacità di codifica / algoritmi. Ed è per questo che le persone con una laurea in informatica trovano relativamente più facile avere successo nel campo dell'apprendimento automatico..
Ma lo scenario è cambiato. tuttavia, non può sfuggire completamente alla crittografia, puoi ancora iniziare con l'apprendimento automatico. Una volta che inizi, puoi migliorare le tue capacità di programmazione.
La buona notizia è che ora puoi iniziare apprendimento automatico usando Microsoft Excel. sì! hai sentito bene.
Frontline Solvers ha introdotto ‘ESTRAZIONE DATI XMINER"Componente aggiuntivo per MS Excel". È uno strumento facile da usare, fatto per i professionisti, per la visualizzazione dei dati, previsione e data mining. È facile da usare se:
- Hai lavorato in MS Excel in passato
- Ha esperienza lavorativa con SPSS
Leggi anche: Trucchi semplici ma potenti per analizzare i dati in Excel
Quali sono le attività che XLMiner può eseguire?
Sapevo che sarebbe arrivato. Bene! XLMiner può fare molte cose che fai in R, Python o Julia. Anche quello, senza scrivere uno snippet di codice. Offre un ottimo affare sulle attività di machine learning e data mining. XLMiner è compatibile con Excel 2007, Eccellere 2010 ed eccellere 2013 (32 e 64 bit). Ecco l'elenco delle attività che possono essere eseguite con XLMiner:
- Esplorazione e visualizzazione dei dati
- Ingegneria delle funzioni
- Estrazione del testo
- Analisi delle serie temporali
- Apprendimento automatico
- Regressione
- Classificazione
- Raggruppamento
- Modellazione d'insieme
- Reti neurali
Nota: non disponibile gratuitamente. Puoi scaricarlo in un periodo di prova di 15 giorni e poi acquista una licenza di due anni per $ 2495.
In questo articolo, Dimostrerò i passaggi per eseguire la regressione, clasificación y raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. in excel. Ti consiglio di lavorare su piccoli set di dati in Excel, dal momento che potrebbe fallire. È utile usarlo su set di dati come Titanic.
Per ottenere il meglio da questo articolo, avrebbe dovuto / acquisire una conoscenza di base di questi algoritmi. Se hai bisogno di un rapido aggiornamento sull'apprendimento automatico, Ti consiglio di dare un'occhiata a questi tutorial: Nozioni di base sugli algoritmi di apprendimento automatico
Ho installato XLMiner. Dopo l'installazione, noterai che XMINER appare nelle schede principali (immagine sotto). Puoi vedere anche questo panoramica della piattaforma XLMiner.
Cominciamo !
Tutorial: regressione lineare multipla
La regressione non è un grosso problema. Puoi farlo anche usando il plugin ‘kit di strumenti per l'analisi dei dati'Disponibile in Excel. Va bene per l'analisi statistica. Per l'apprendimento automatico, avrebbe bisogno di XLMiner. Qui ho dimostrato la regressione multipla usando XLMiner. Per regressione lineare, tutti i passaggi rimangono gli stessi, excepto que selecciona una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... independiente para el modelado. Di seguito sono riportati i passaggi:
1. Ho usato il set di dati sugli alloggi di Boston. Questi dati rappresentano i prezzi delle case a Boston in base a vari fattori che influenzano. Puoi caricare il set di dati usando: Aiuto -> Esempi -> Boston Housing.
2. Ecco il set di dati.
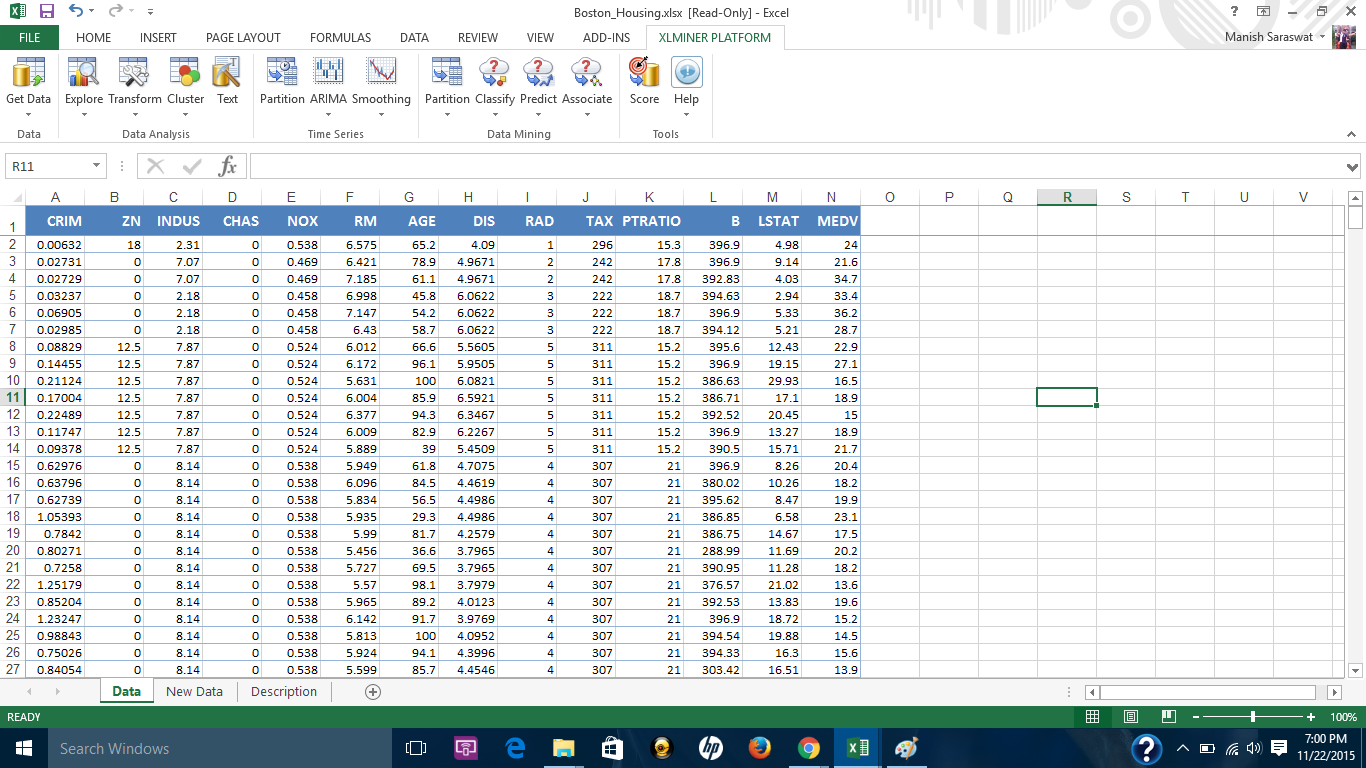
3. Non ci sono valori mancanti in questo set di dati. tuttavia, questo plugin fornisce una comoda opzione per gestire i valori mancanti. Puoi accedere a questa opzione da qui.
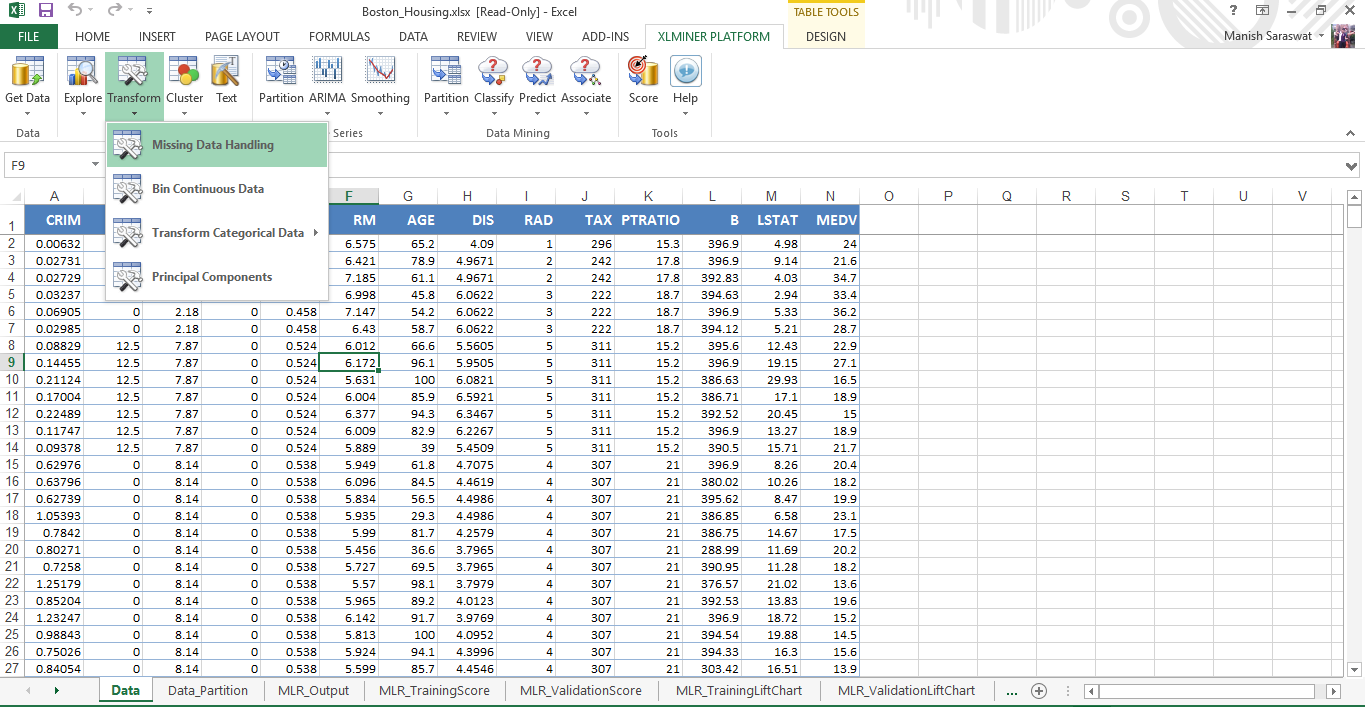
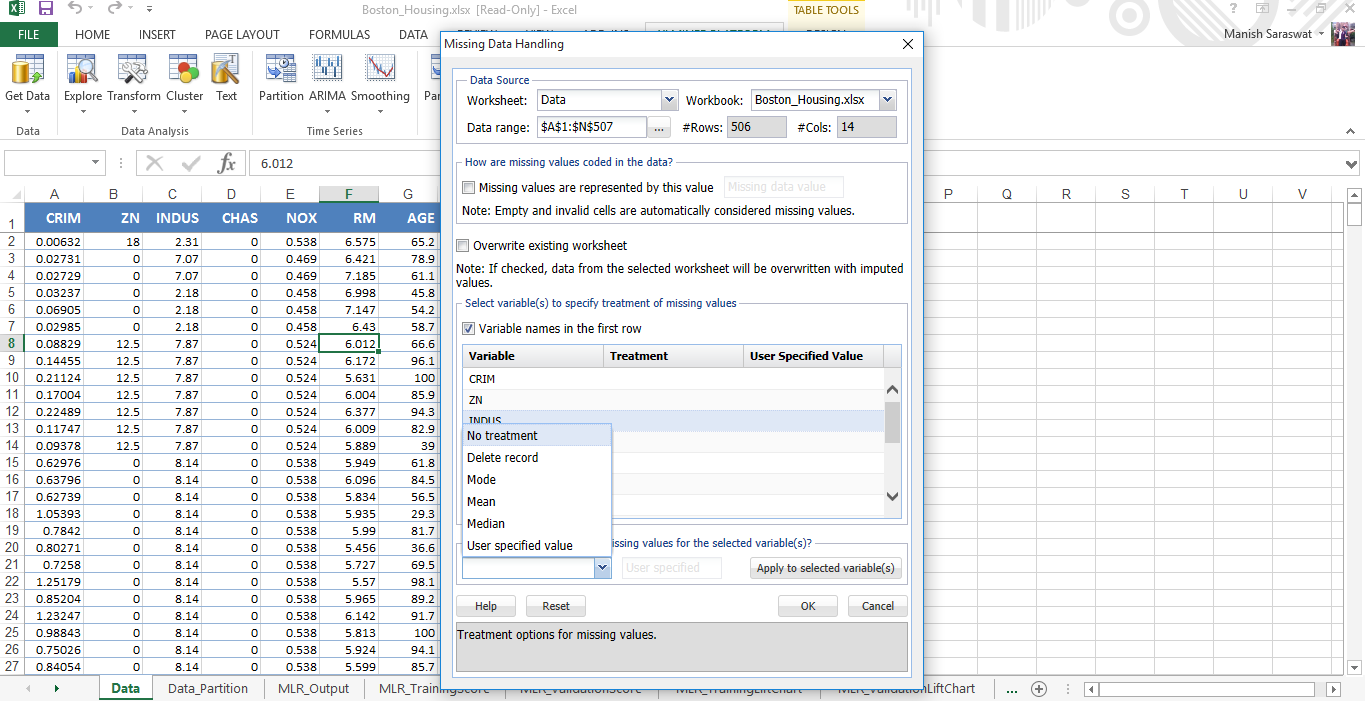
Semplicemente, seleziona le variabili dove trovi i valori mancanti. Se i valori mancanti sono rappresentati da 'null', 'N / UN’ o in qualsiasi altro modo, menzionalo. Finalmente, puoi scegliere il metodo di trattamento e voilà.
4. Ora faremo la selezione delle funzioni. MEDV è la variabile di risposta. MEDV rappresenta il valore mediano delle abitazioni di proprietà in $ 1000.
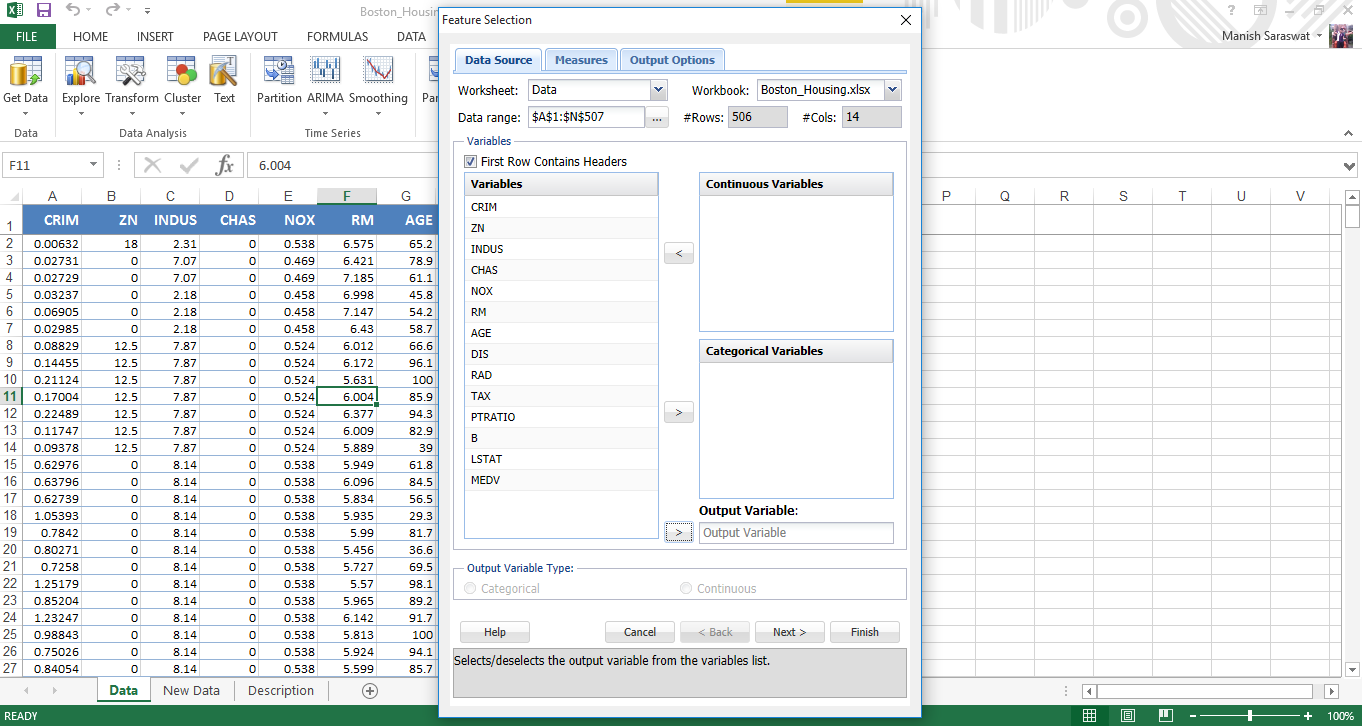
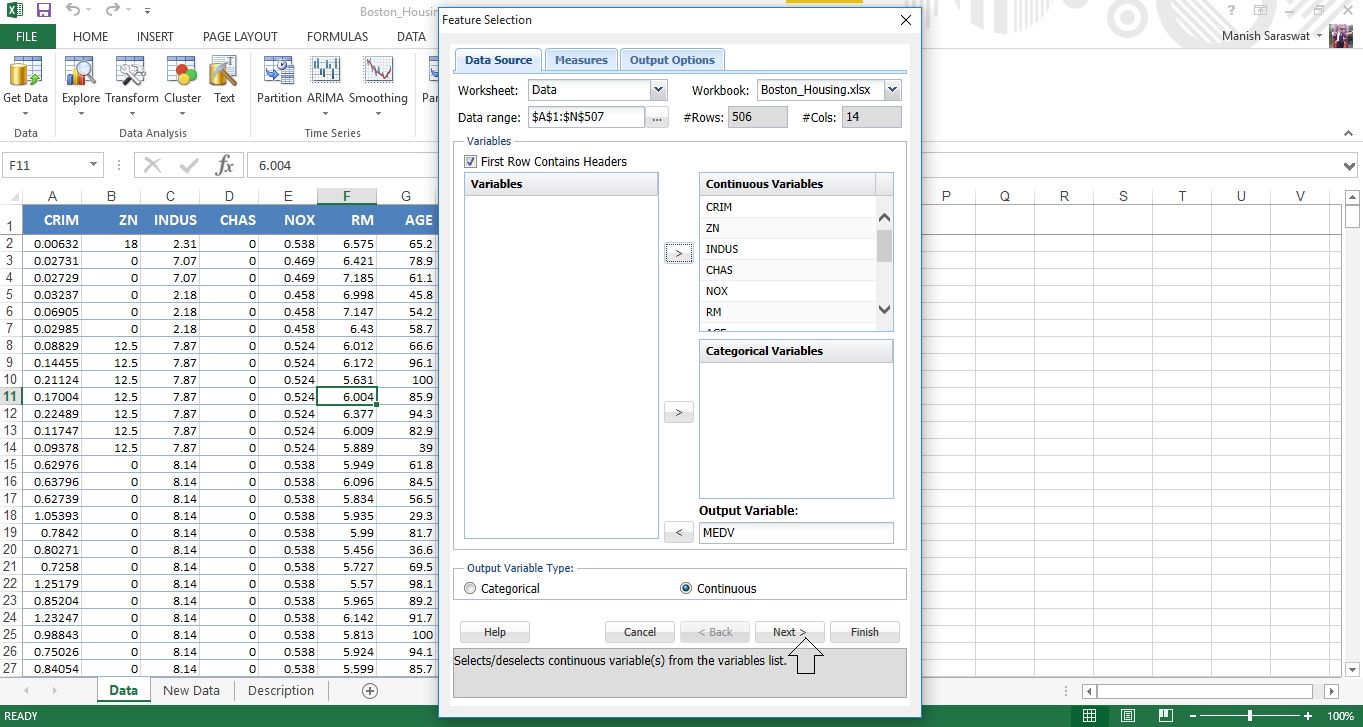
5. Usa Maiusc + fare clic per selezionare tutte le variabili indipendenti contemporaneamente. Invia MEDV alla variabile di output. Fare clic su Avanti.
6. Seleziona i filtri di correlazione. Le ho selezionate tutte e tre. Fare clic su Avanti
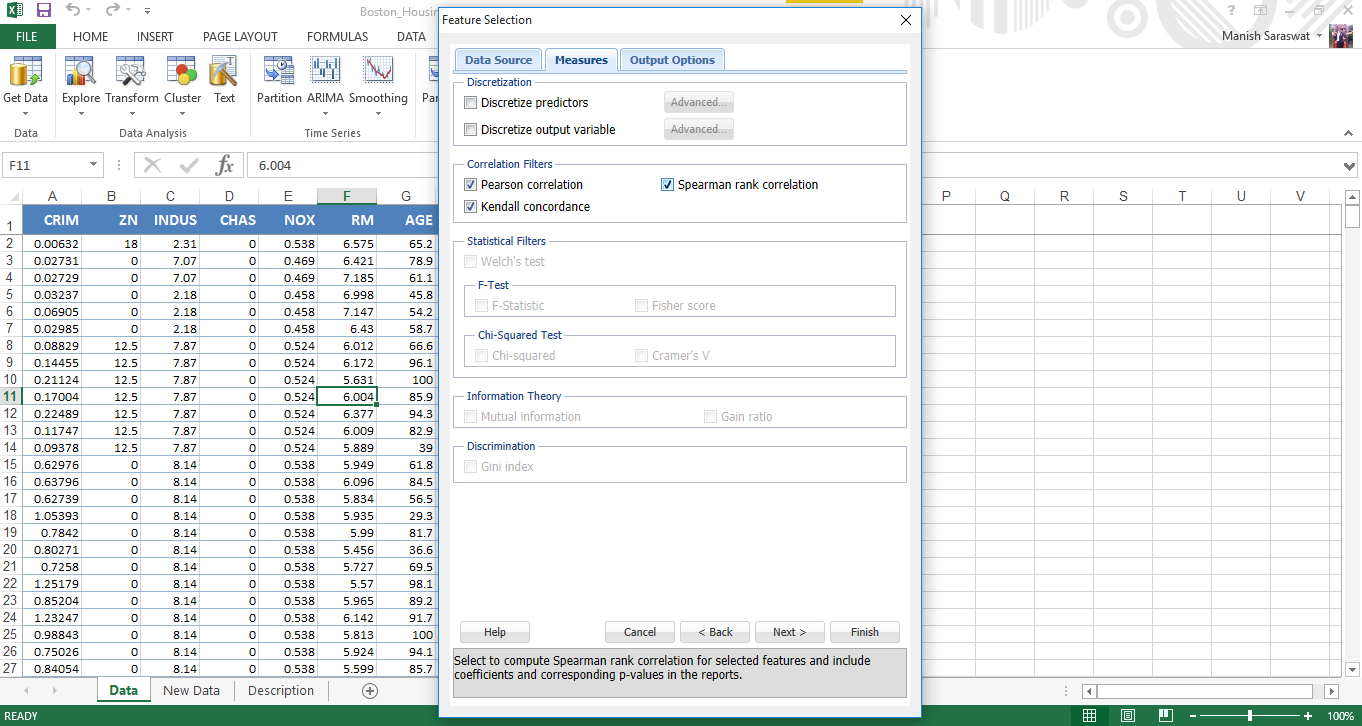
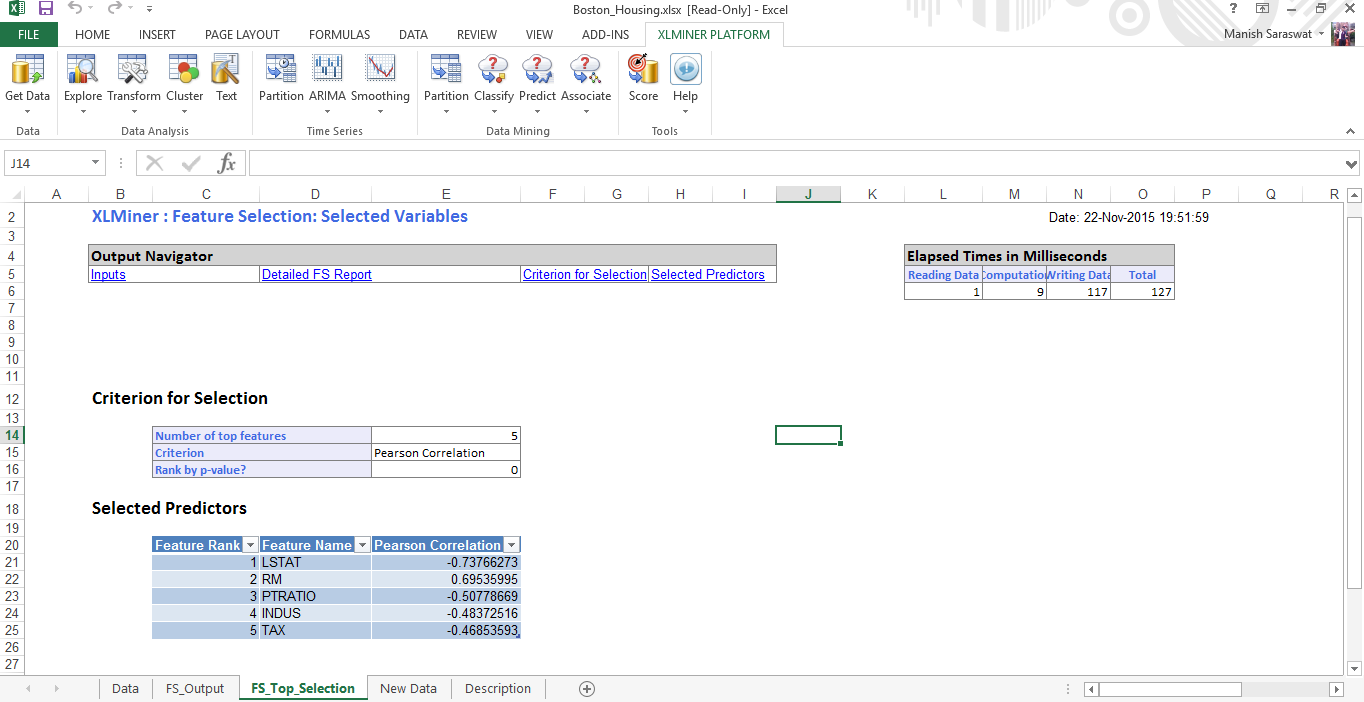
7. Ora seleziona le funzioni. Scopriamo il 5 principali variabili predittive importanti. Fare clic su Fine.
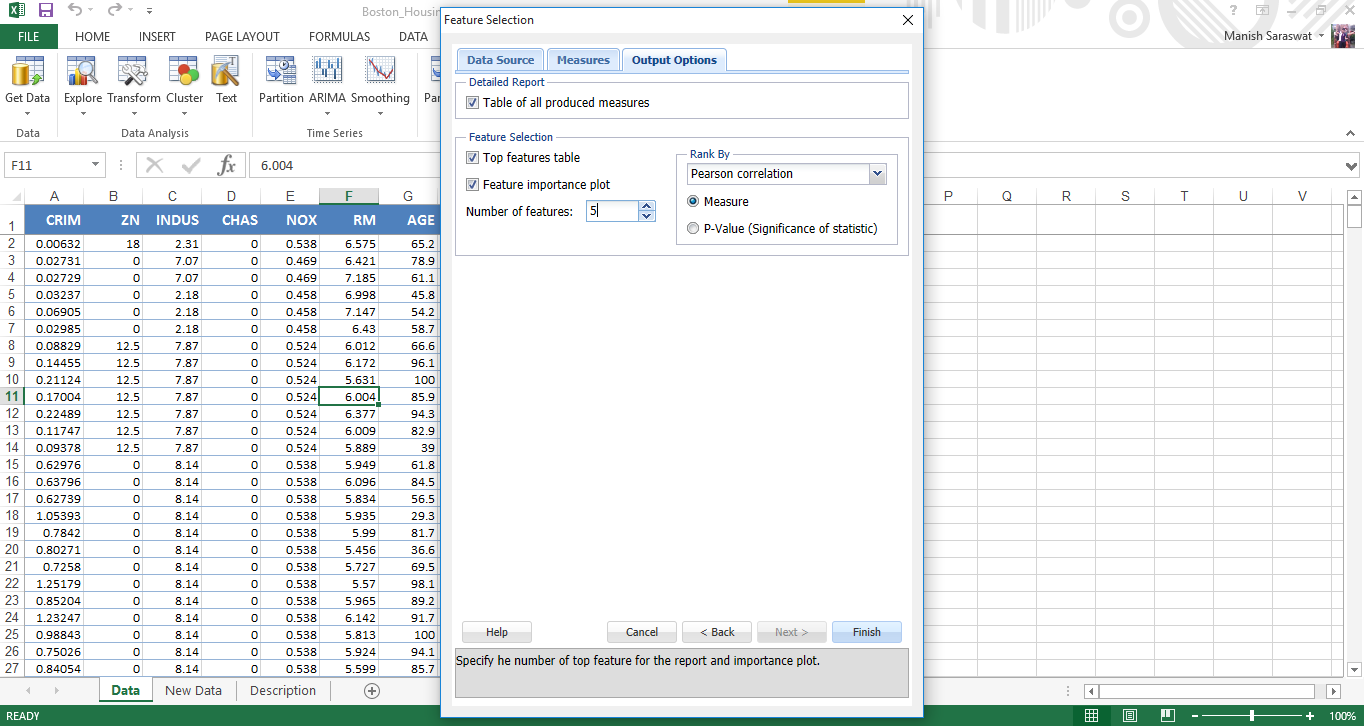
8. Ecco la tabella di importanza variabile. Vediamo, LSTAT è la variabile più importante, seguito da RM, LA PRATICA, INDUS e TAX.
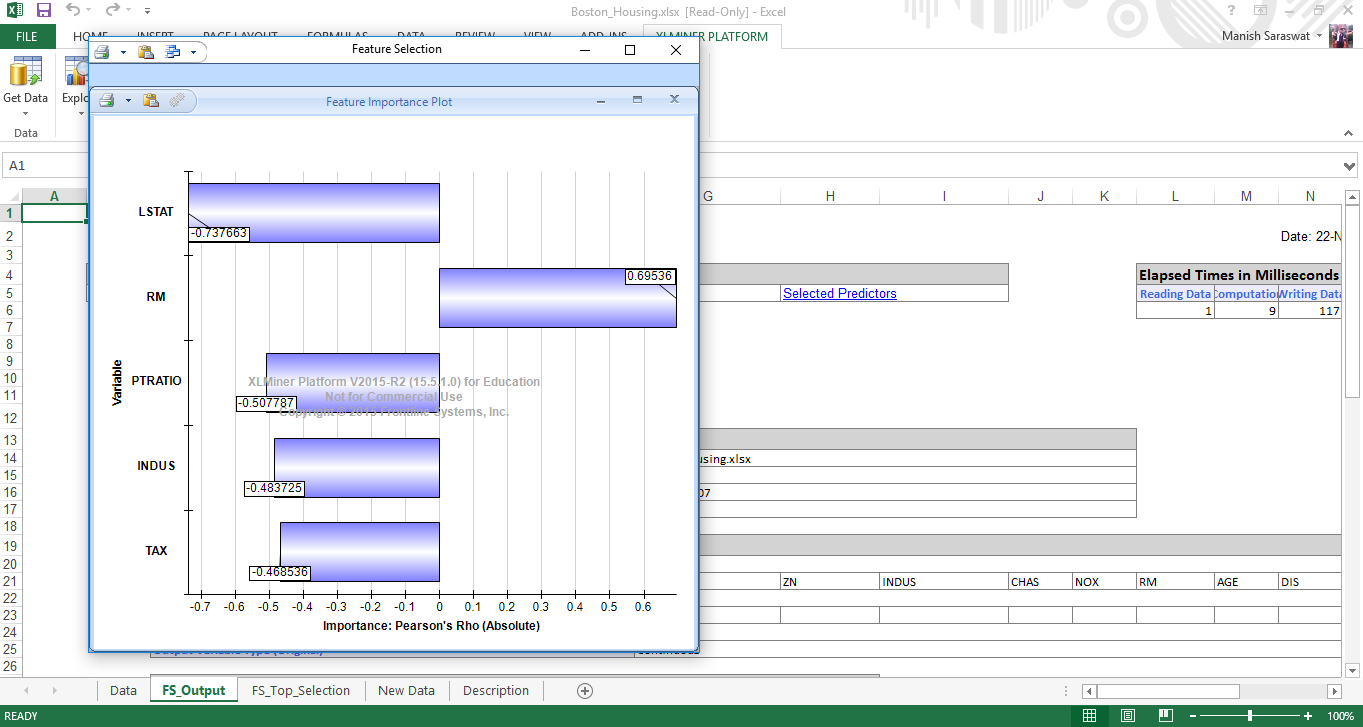
9. Chiudi questo grafico. Verá Output Navigator. Questo ti aiuta a navigare tra più fogli di output. Diamo un'occhiata ai "predittori selezionati".
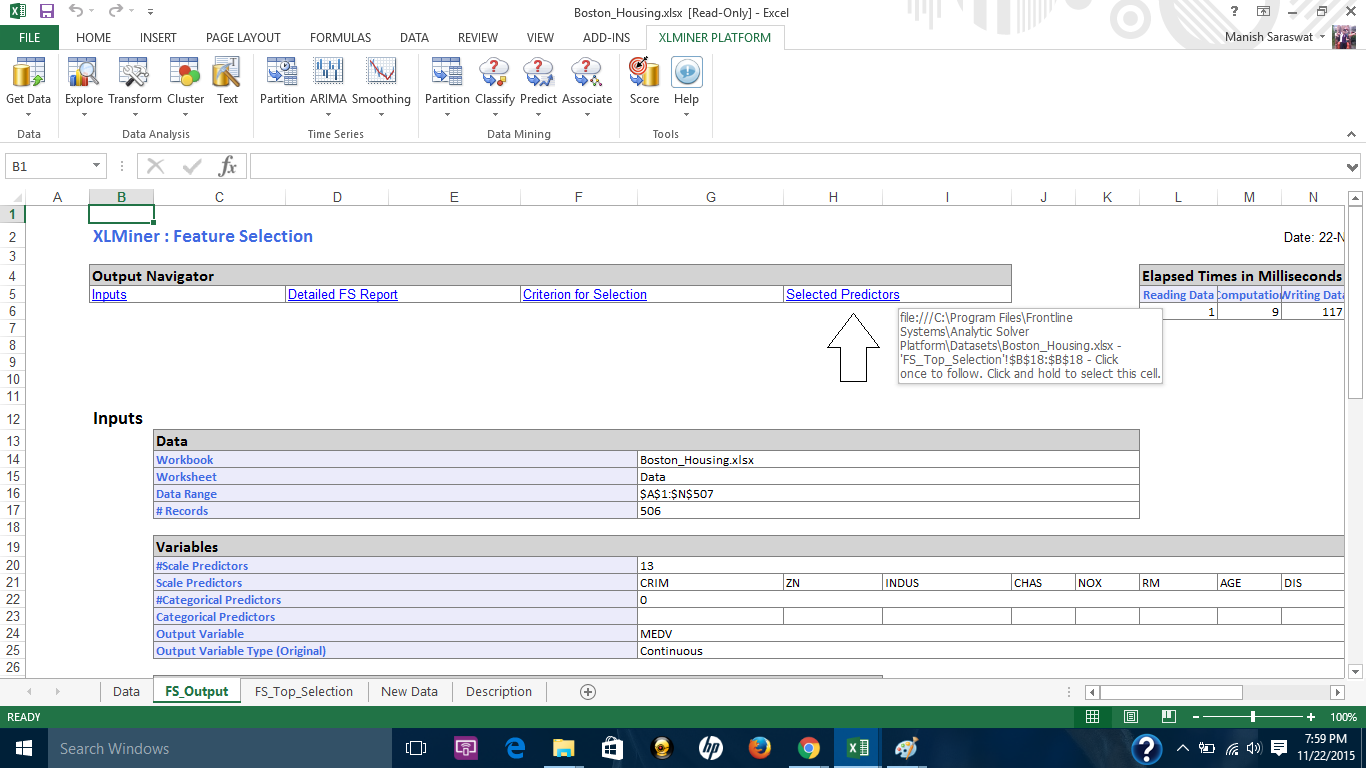
10. Ecco i predittori selezionati. Procediamo a costruire un modello di regressione utilizzando queste variabili.
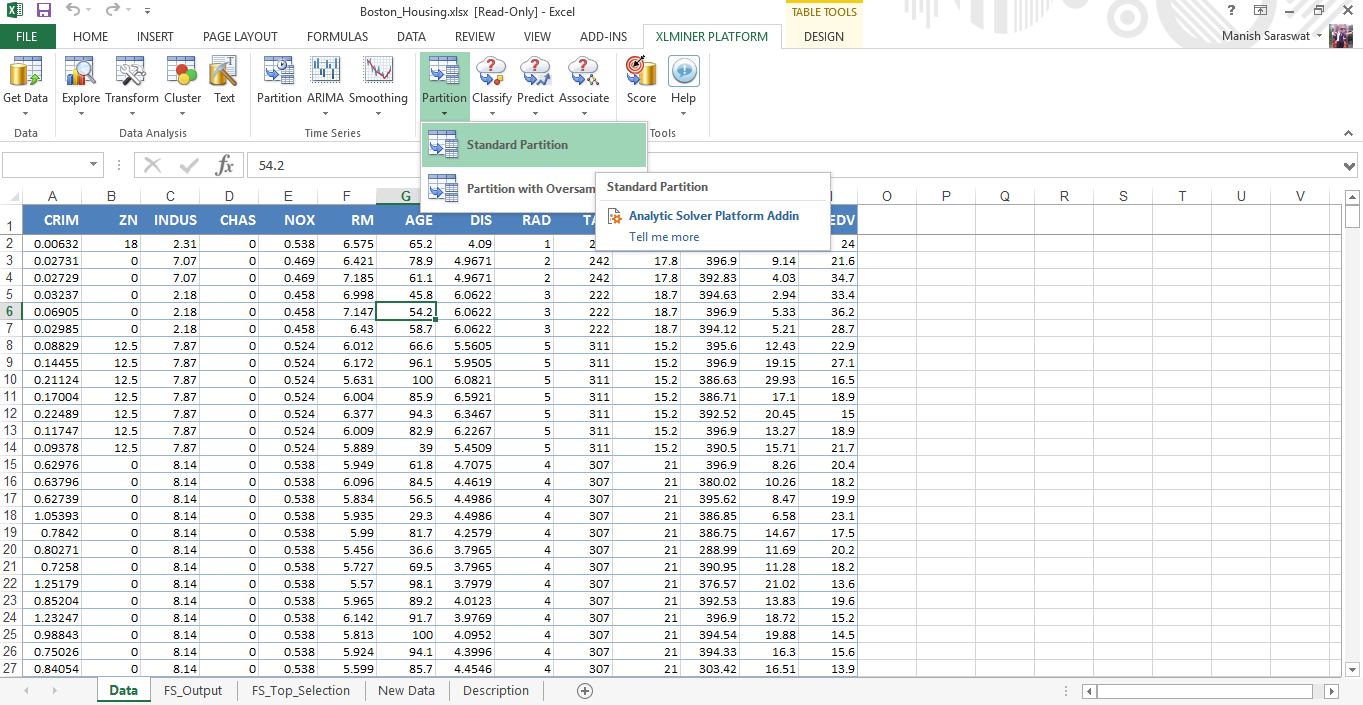
11. prima di fare la modella, dividere (partizioniamo) questi dati in treno e validazione.
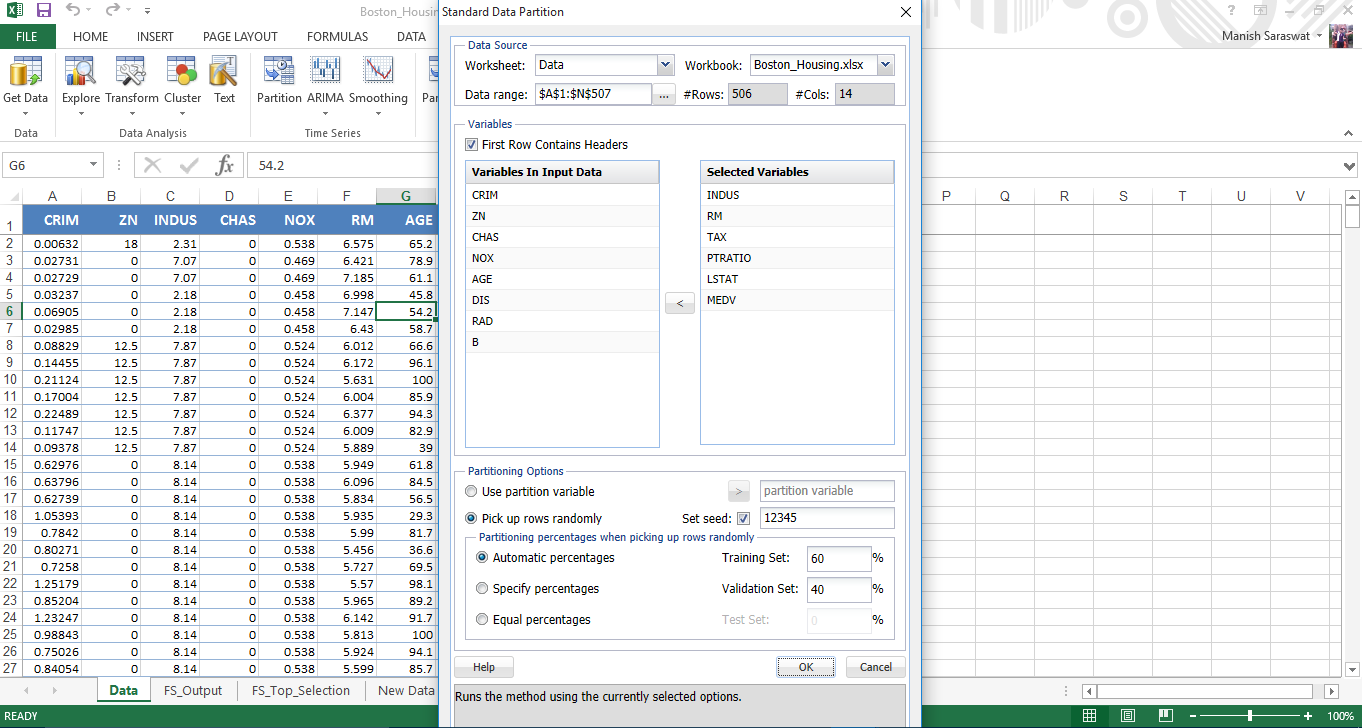
12. In base alla selezione delle caratteristiche, seleziona le variabili da includere nella partizione. Lascia il resto come predefinito e fai clic su OK.
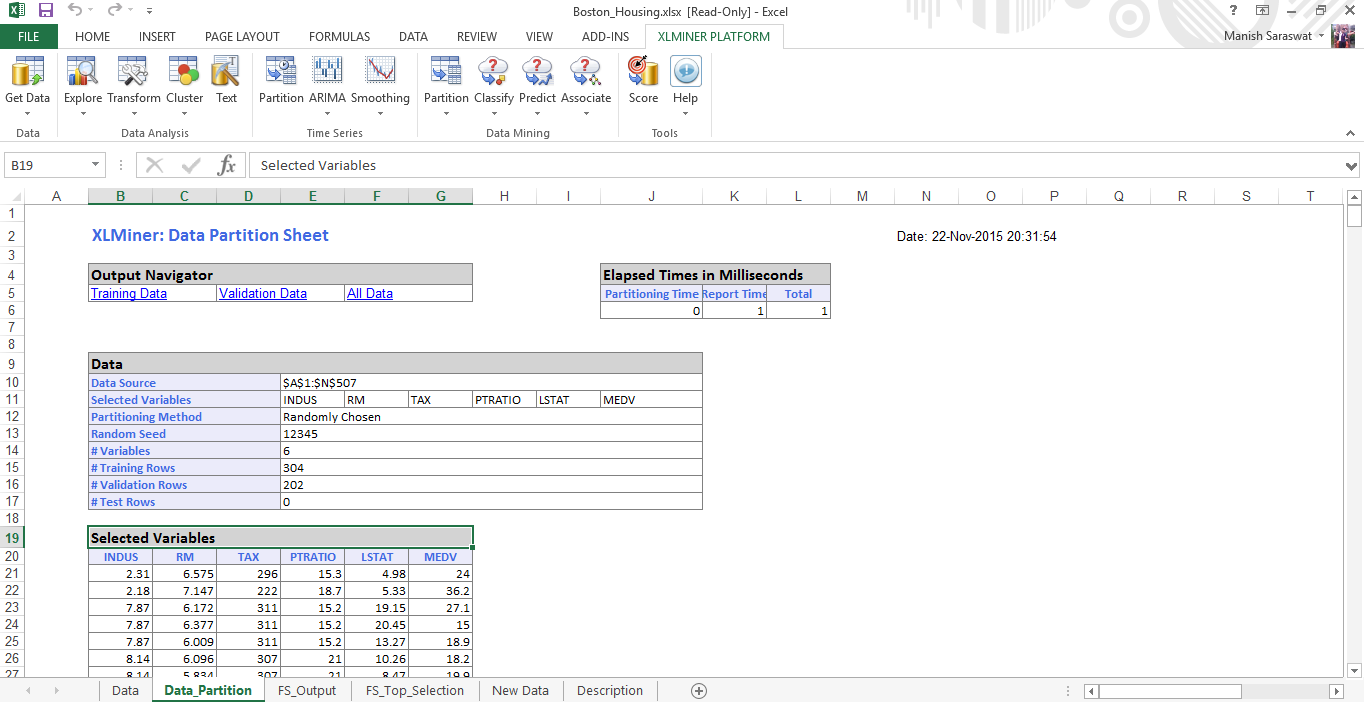
13. Y aquí tenemos el conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... listo para modelar.
14. Fare clic su qualsiasi cella in Variabili selezionate e procedere alla creazione del modello di regressione multipla. Fare clic su Regressione lineare multipla
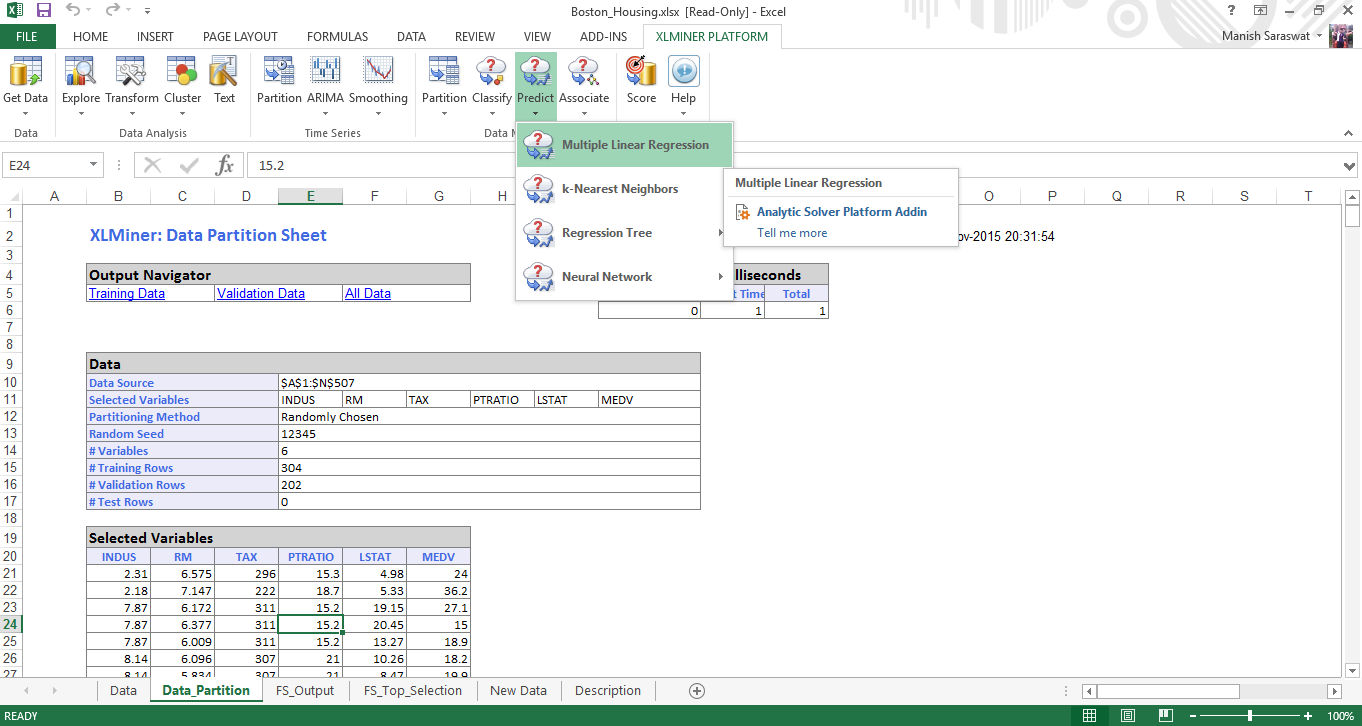
15. Seleziona l'insieme di predittori e variabili di risposta. Fare clic su Avanti
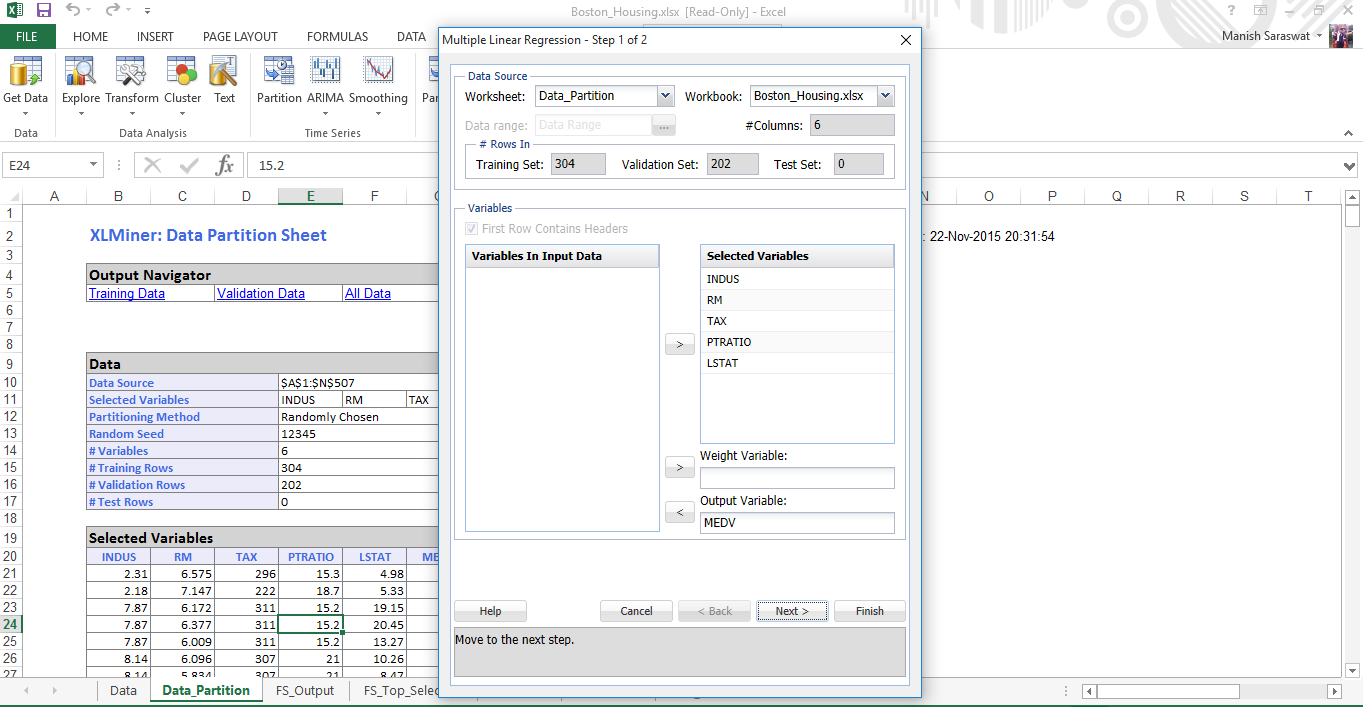
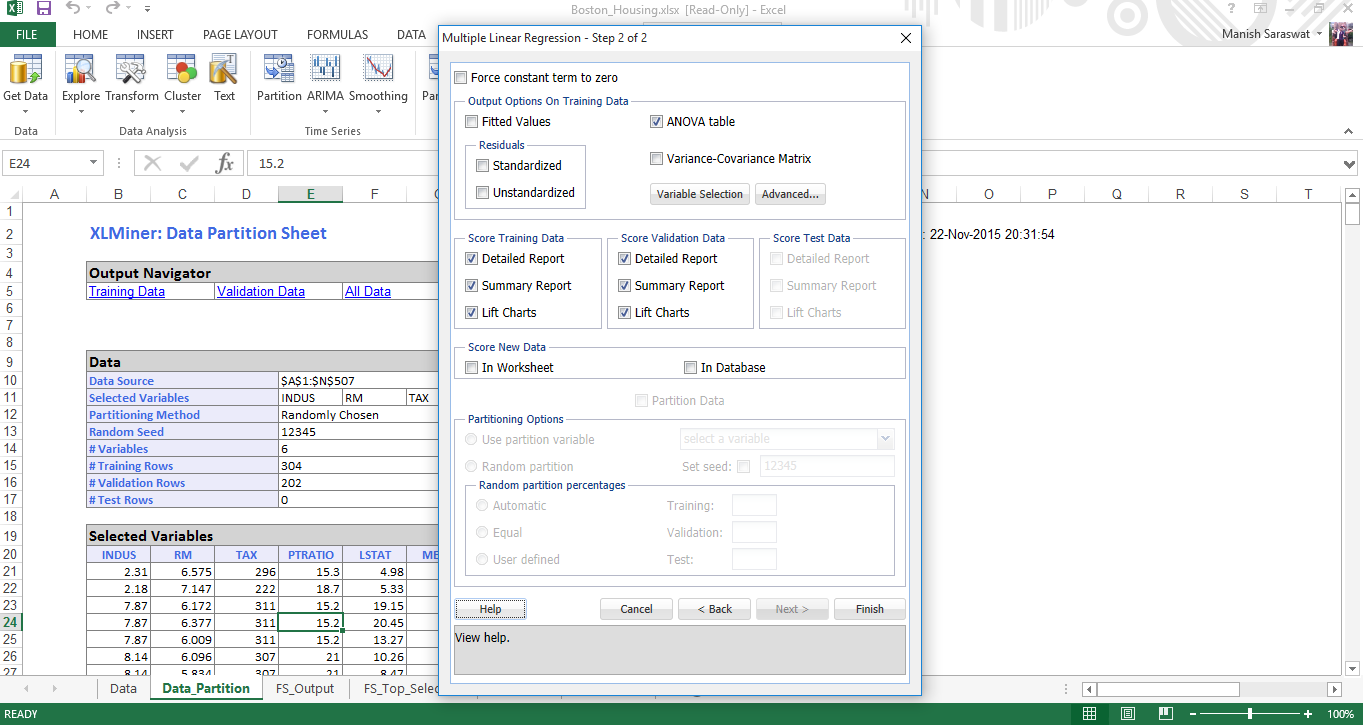
16. Seleziona le metriche richieste. Fare clic su Fine
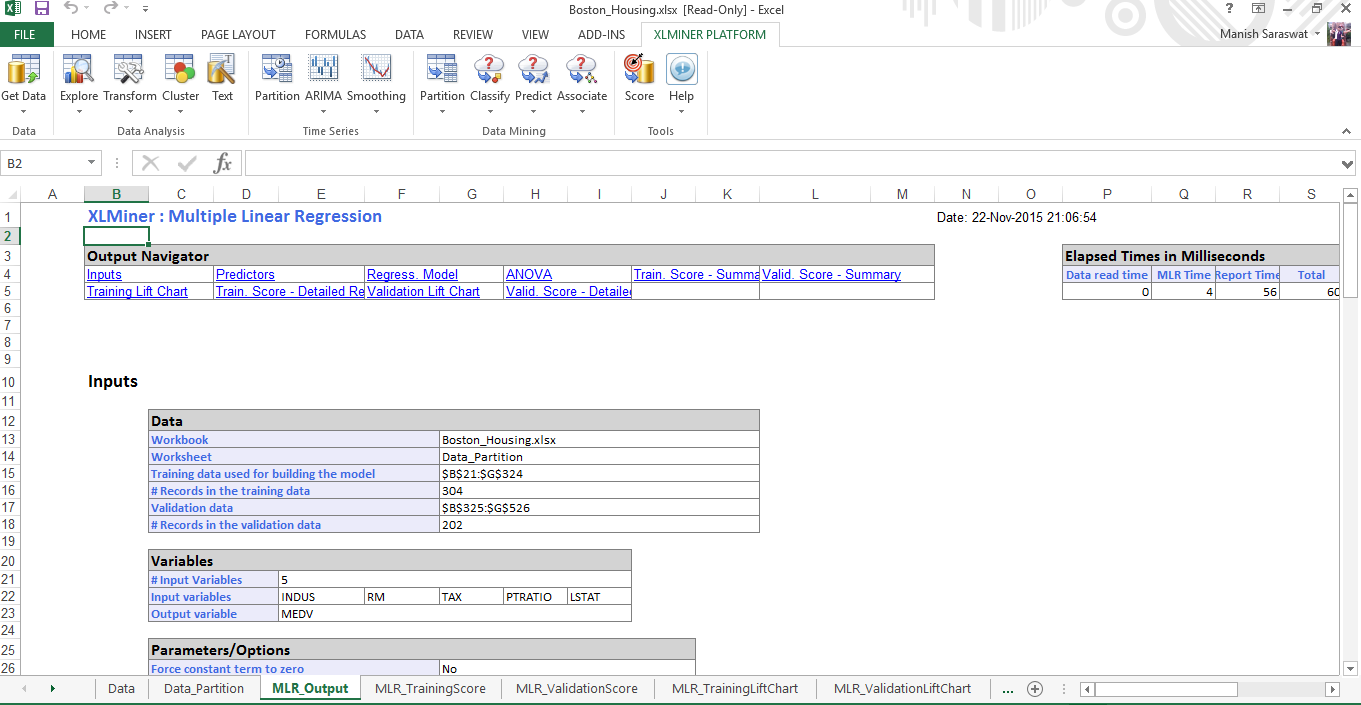
17. Il tuo modello di regressione lineare multipla è pronto. Usa il browser di output per accedere a diverse metriche e precisione del modello.
Tutorial: Regressione logistica
La regressione logistica è un classico esempio di algoritmo di classificazione. Simile alla regressione lineare multipla, Di seguito sono riportati i passaggi per costruire un modello di regressione logistica. Se vuoi aggiornare rapidamente i tuoi concetti di regressione logistica, puoi controllare questo tutorial: Semplice guida alla regressione logistica
1. Carica il set di dati "Charles_bookclub". Un nastro XLMiner, fare clic su Guida -> Esempio. Seleziona questo set di dati. Questo set di dati rappresenta le informazioni associate alle persone che sono membri di un club del libro. Costruiremo un modello per prevedere se una persona acquisterà un libro sulla città di Firenze sulla base di acquisti precedenti.
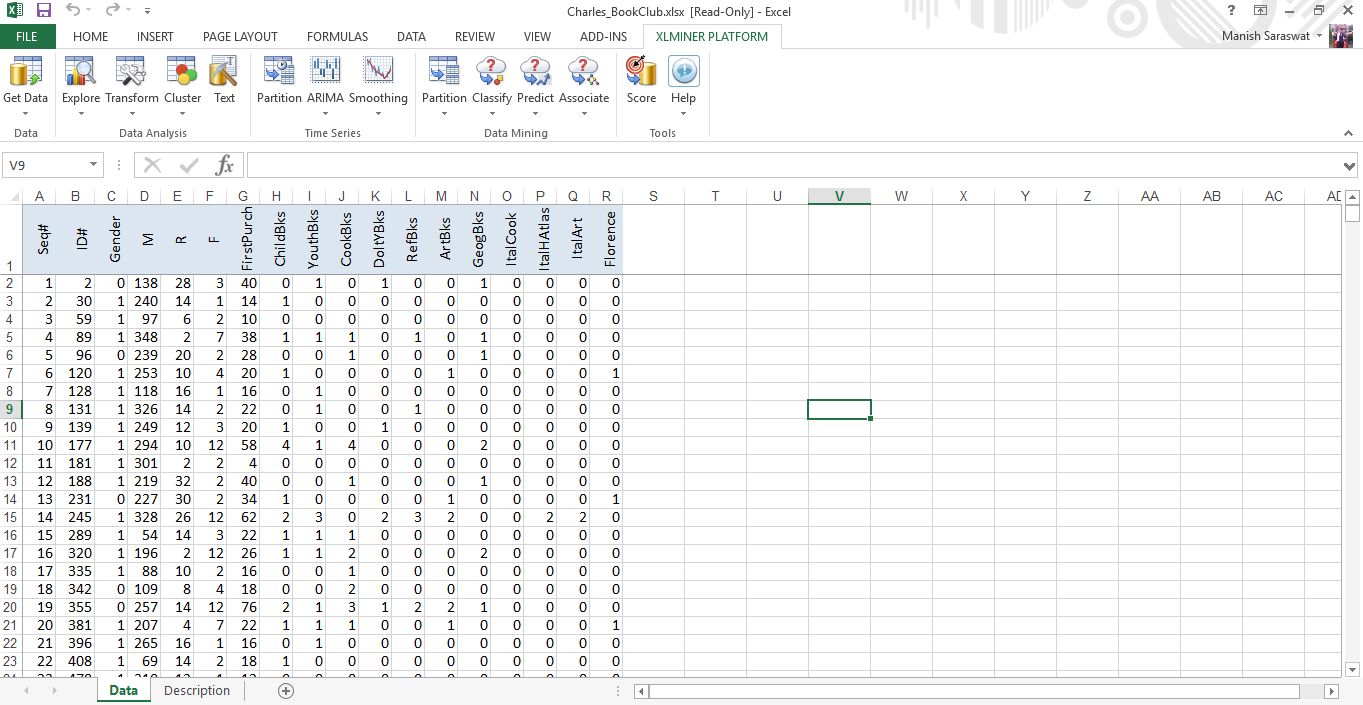
2. Ora, divideremo il set di dati in training (70%) e convalida (30%). Questa volta devi specificare le percentuali per la partizione. Fare clic su OK
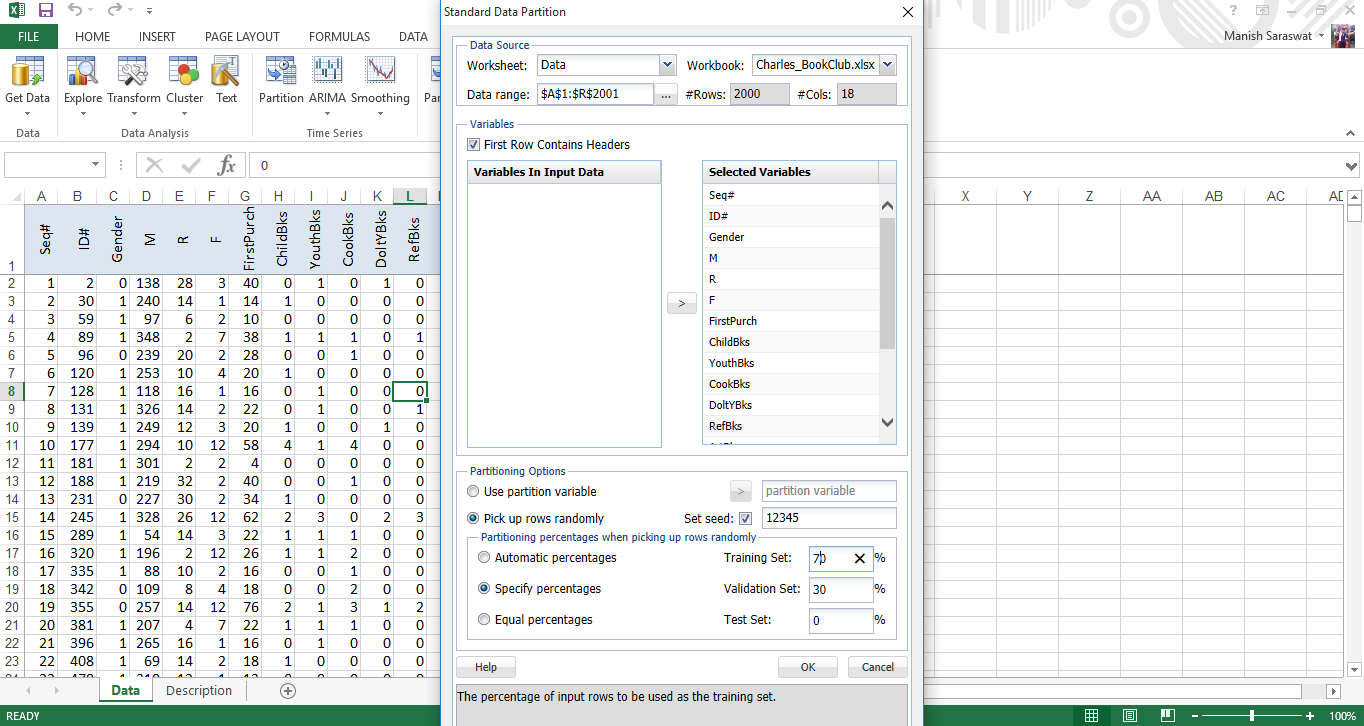
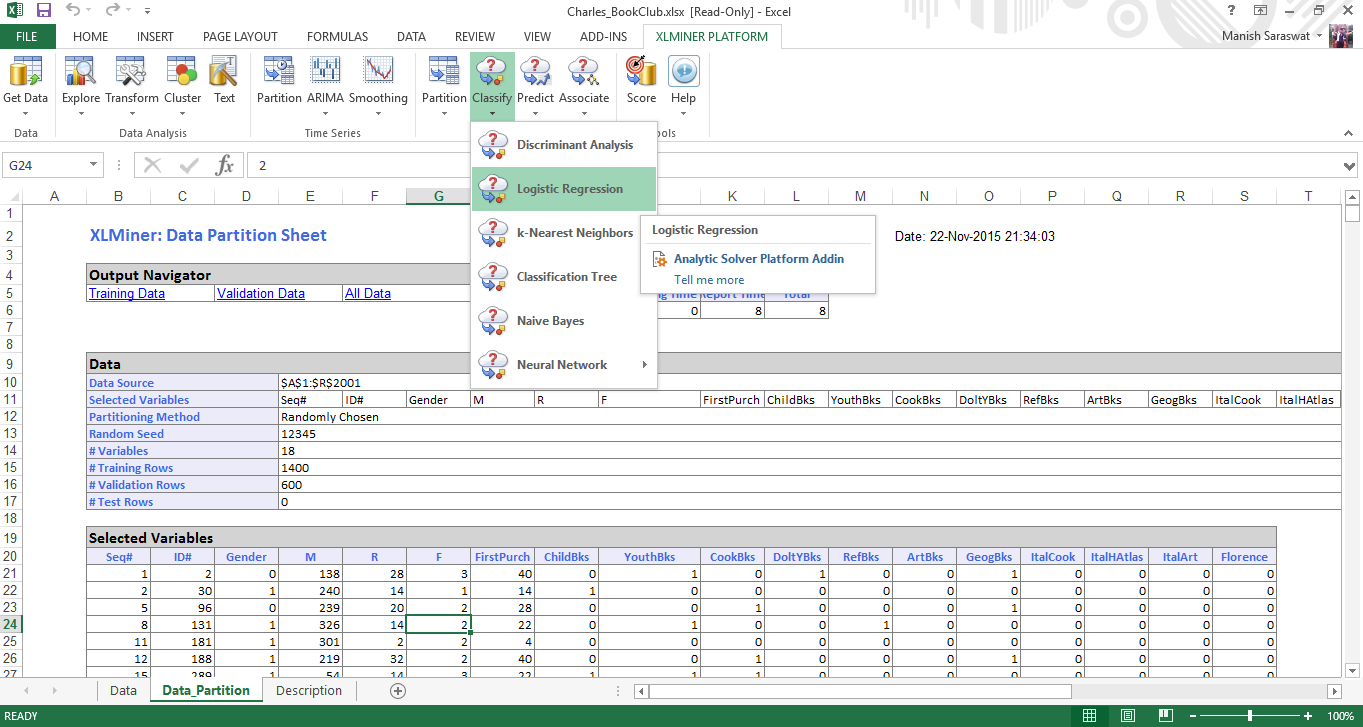
3. Vedrai un foglio di partizione dati. Fare clic su qualsiasi cella nella "tabella delle variabili selezionate"’ e fare clic su regressione logistica come mostrato.
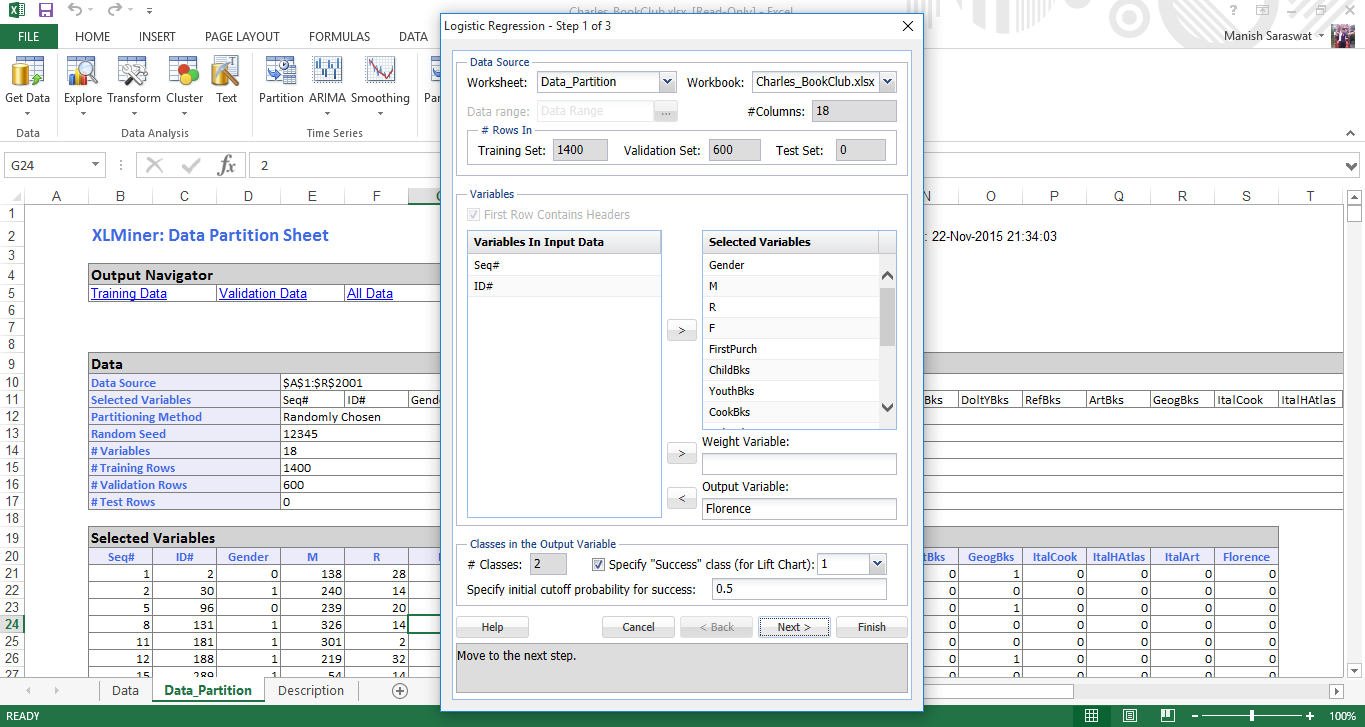
4. Qui seleziona le variabili di input e output. Firenze è la variabile di output dove ottieni 1 quando un cliente ha acquistato un libro sulla città di Firenze e 0 altrimenti. Qui 1 è successo?. 0 è un errore come indicato nella seguente opzione. Lascia il resto come predefinito. Fare clic su Avanti
5. Seleziona l'intervallo di confidenza come 95%. Se selezioni "Forza termine costante a zero", salterà il termine costante nella regressione. Perciò, non selezionarlo. Fare clic su avanzato e selezionare "esegui diagnostica collinearità". Mostrerà informazioni utili quando si tratta di variabili correlate che hanno grandi errori standard. Fare clic su OK. Ora, fare clic su Selezione variabile.
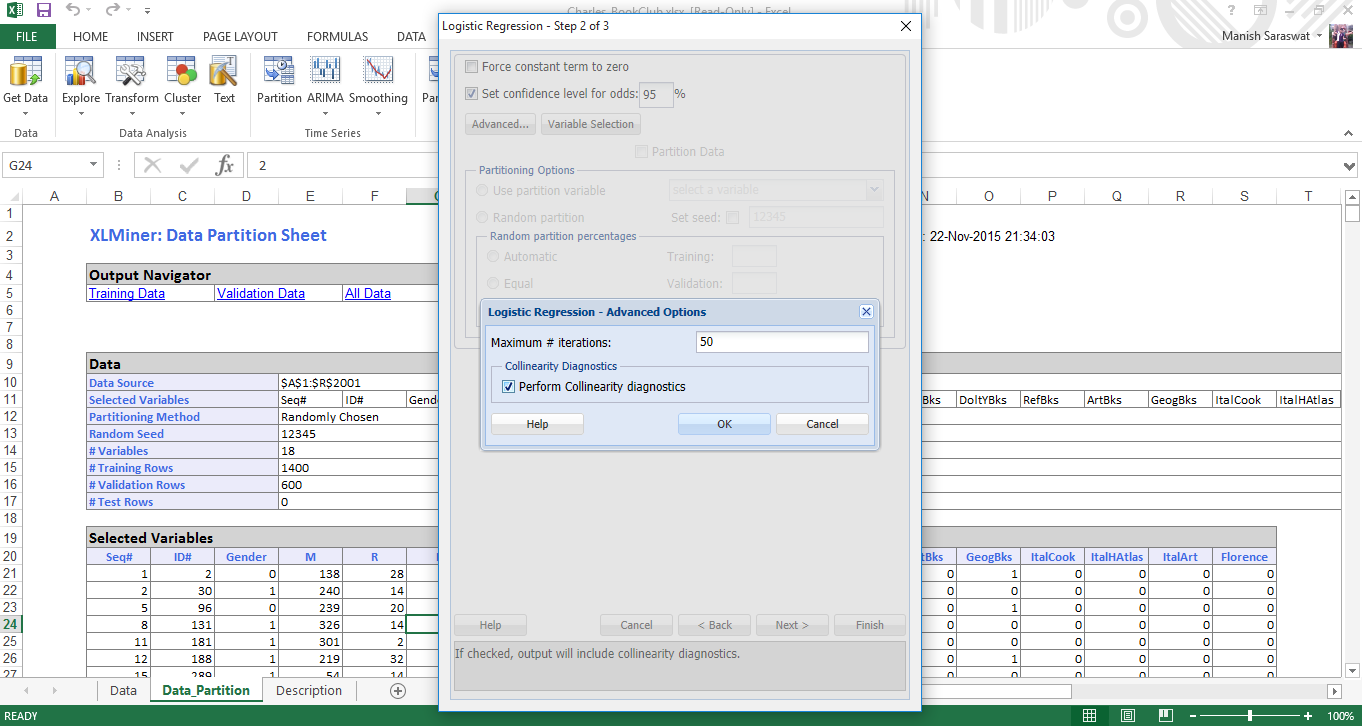
6. La selezione delle variabili ci aiuta a gestire un gran numero di variabili predittive e a trovare la migliore tra di esse.. ‘Dimensione massima del miglior sottoinsieme’ assume un valore di 1 un, dove N è il numero di variabili di input. Non cambieremo questo valore. Nella procedura di selezione, puoi sceglierne uno in base alle tue preferenze. Scegli "Migliori sottoinsiemi"’ perché cerca tutte le combinazioni di variabili e seleziona solo quelle che meglio si adattano. Fare clic su OK. Fare clic su Avanti.
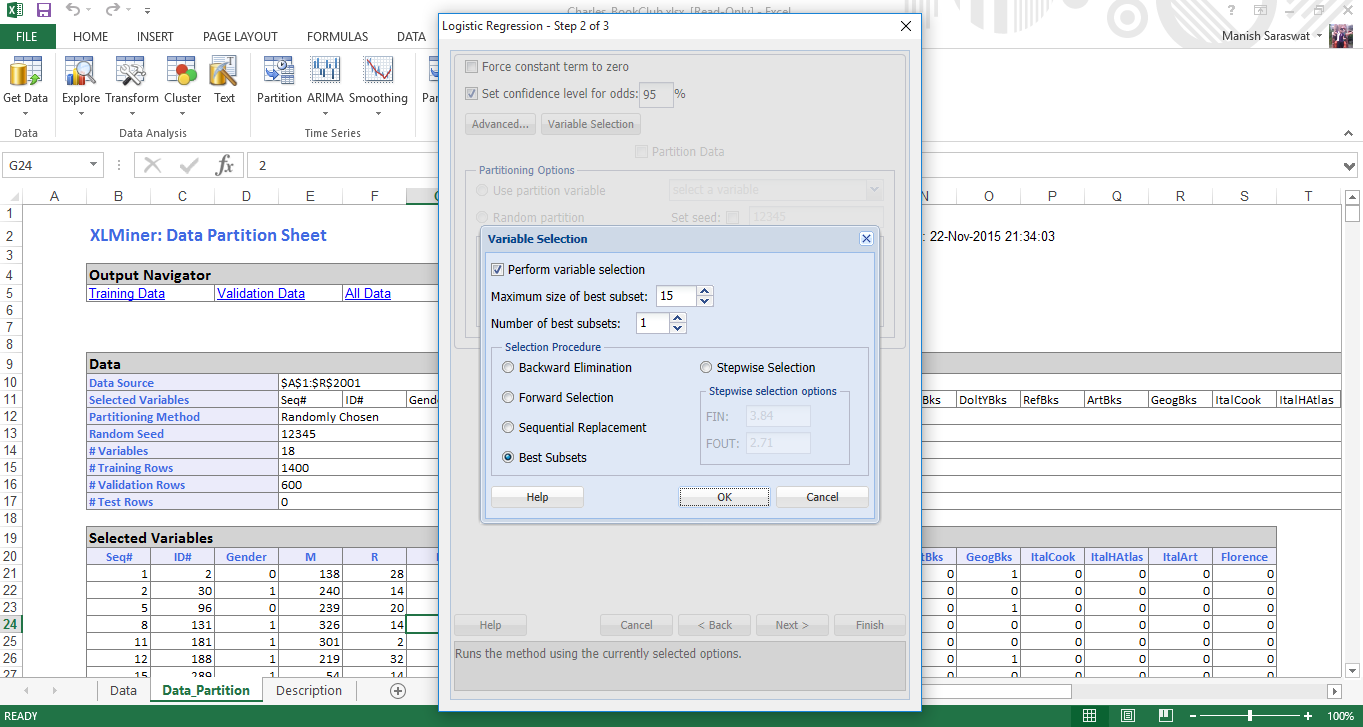
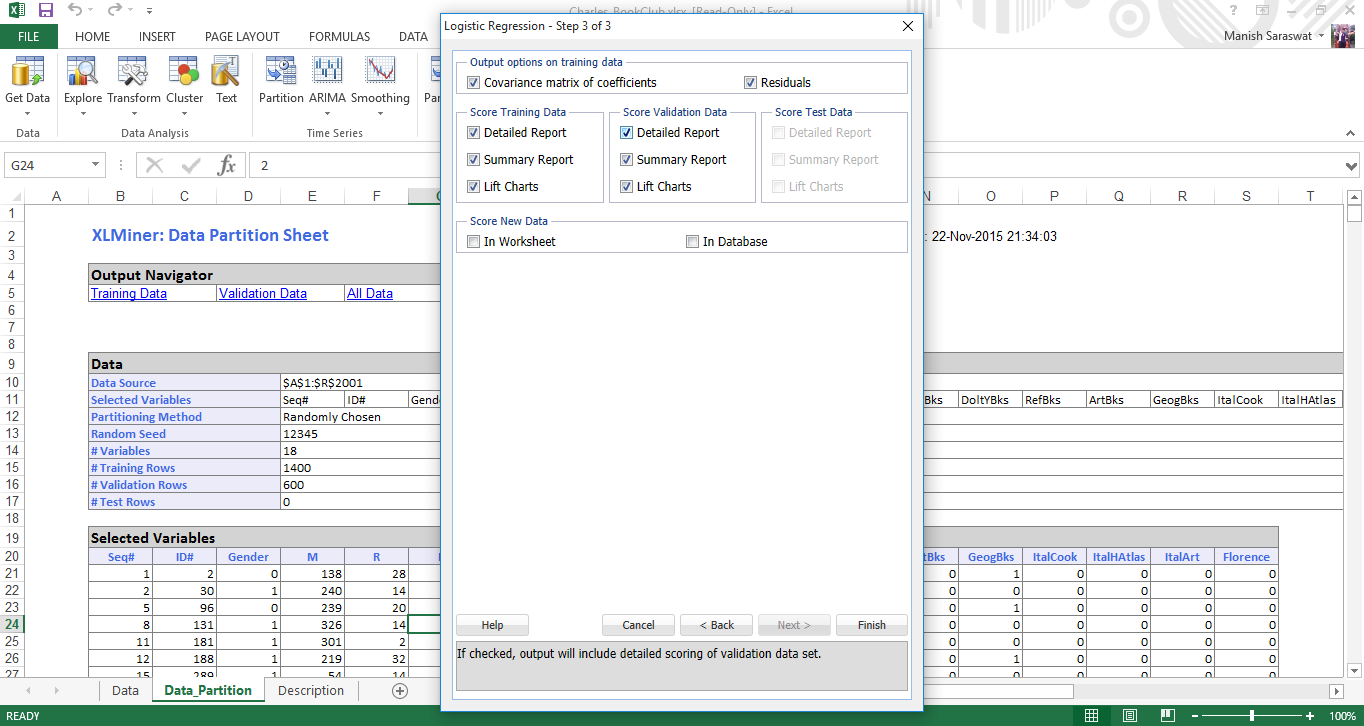
7. Ora selezioneremo i coefficienti di calcolo necessari per valutare il modello. Seleziona matrice di covarianza di coefficienti e residui. I residui produrranno una tabella di valori adattati e i loro residui nell'output. Fare clic su Fine.
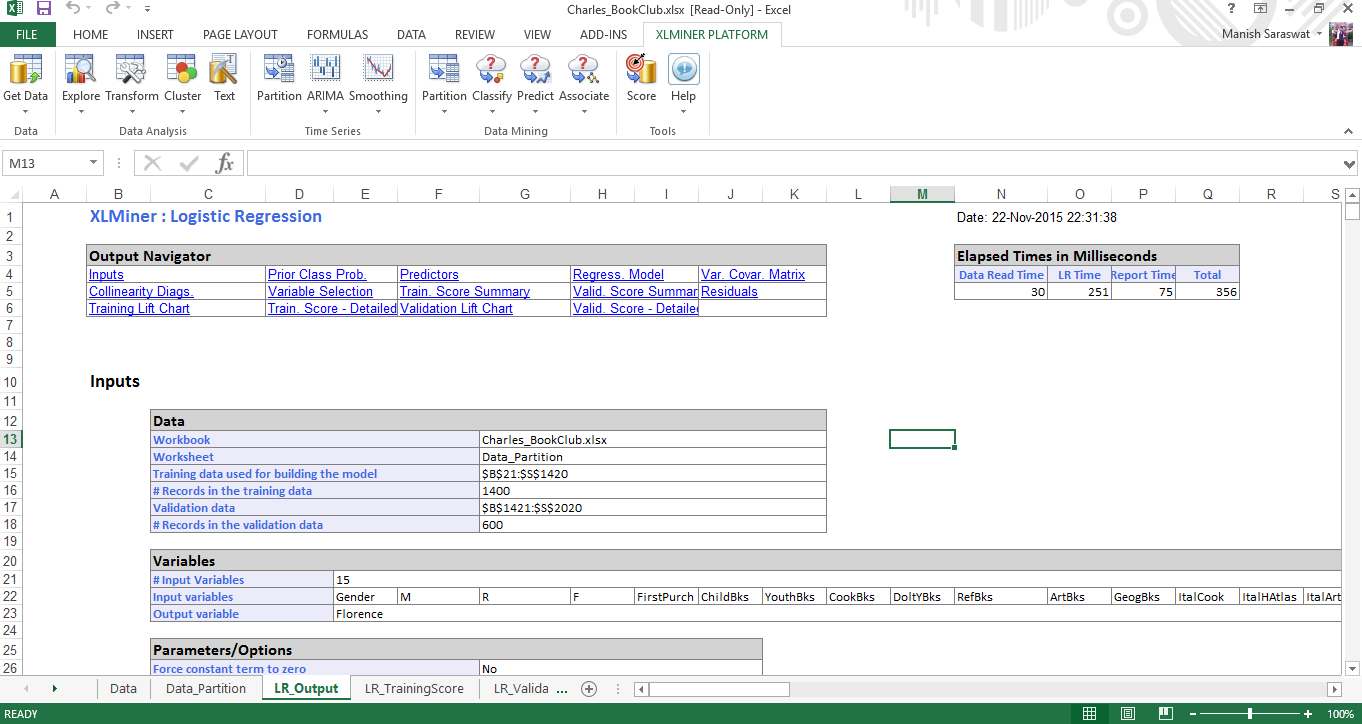
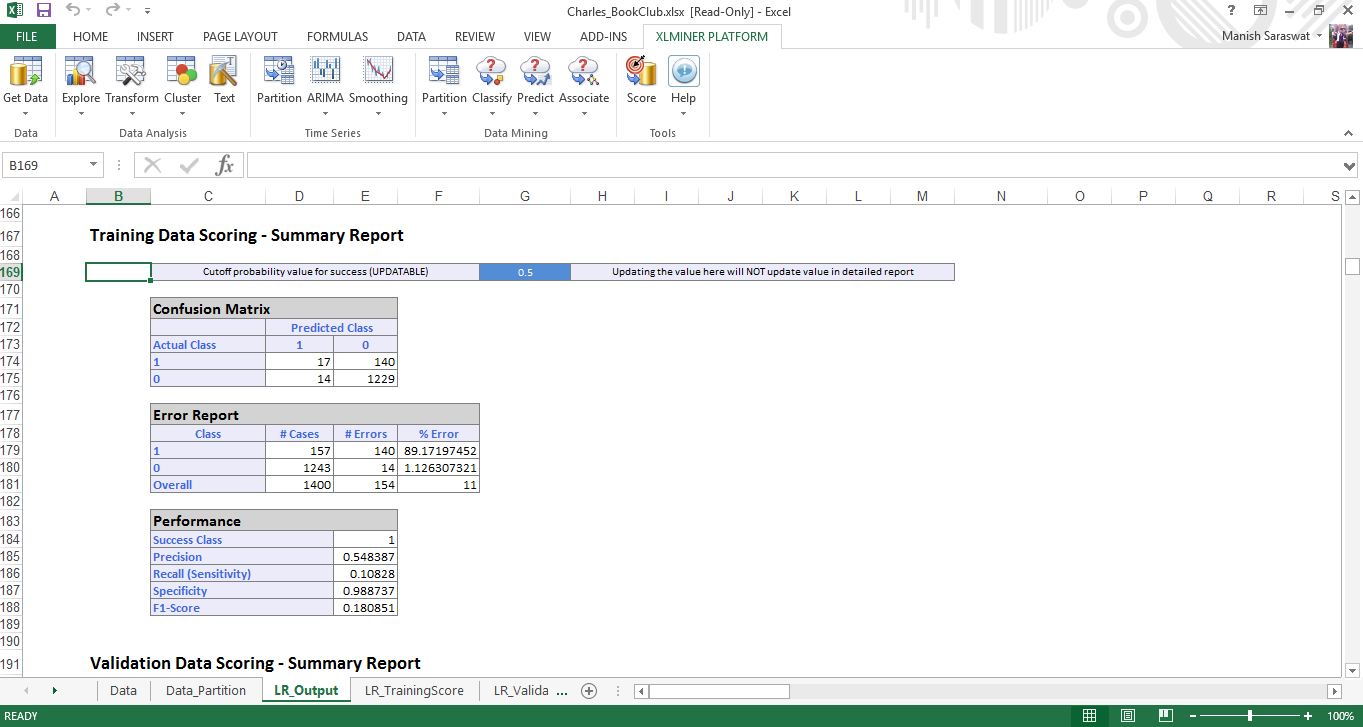
8. Ecco il tuo modello di regressione logistica. Se scorri verso il basso questo foglio, troverai diverse metriche utili per valutare le prestazioni di questo modello. Una metrica comunemente usata per verificare l'accuratezza del modello è la matrice di confusione. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que se desplaza hacia abajo, troverai questo.
Tutorial: K – Raggruppamento di mezzi
Se non conosci il clustering, questo è un rapido aggiornamento sull'analisi dei cluster. In parole semplici, il clustering è una tecnica di raggruppamento di variabili con attributi simili. Questa tecnica viene generalmente utilizzata per profilare i clienti e creare prodotti in base alle loro esigenze..
Diamo un'occhiata ai passaggi per eseguire il clustering k-means in XLMiner.
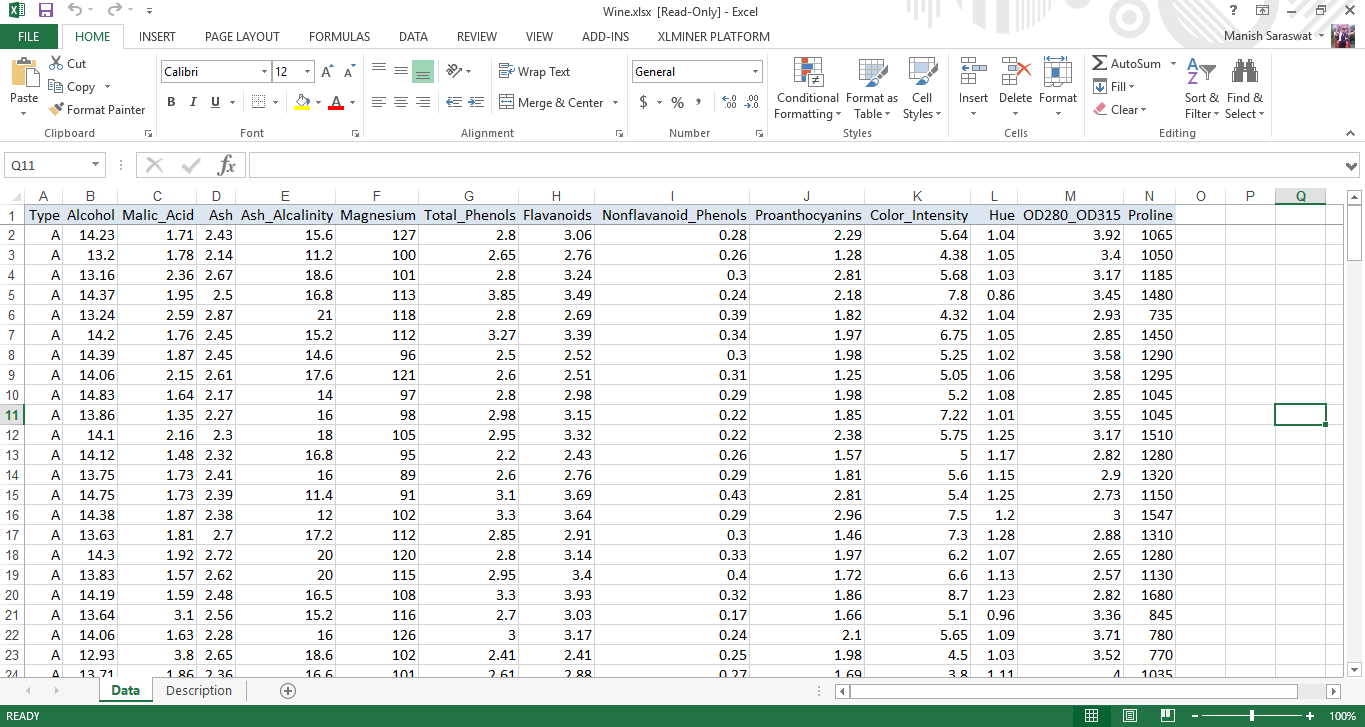
1. Carica il dataset di Wine. Vai al nastro XLMiner, fare clic su Guida -> Esempi. Seleziona Vino. In questo set di dati, ogni riga rappresenta un campione di vino che appartiene a 3 Lezioni (UN, Per C). Sulla base di questi dati, creeremo un modello di raggruppamento per determinare la classe del vino. Ecco il set di dati.
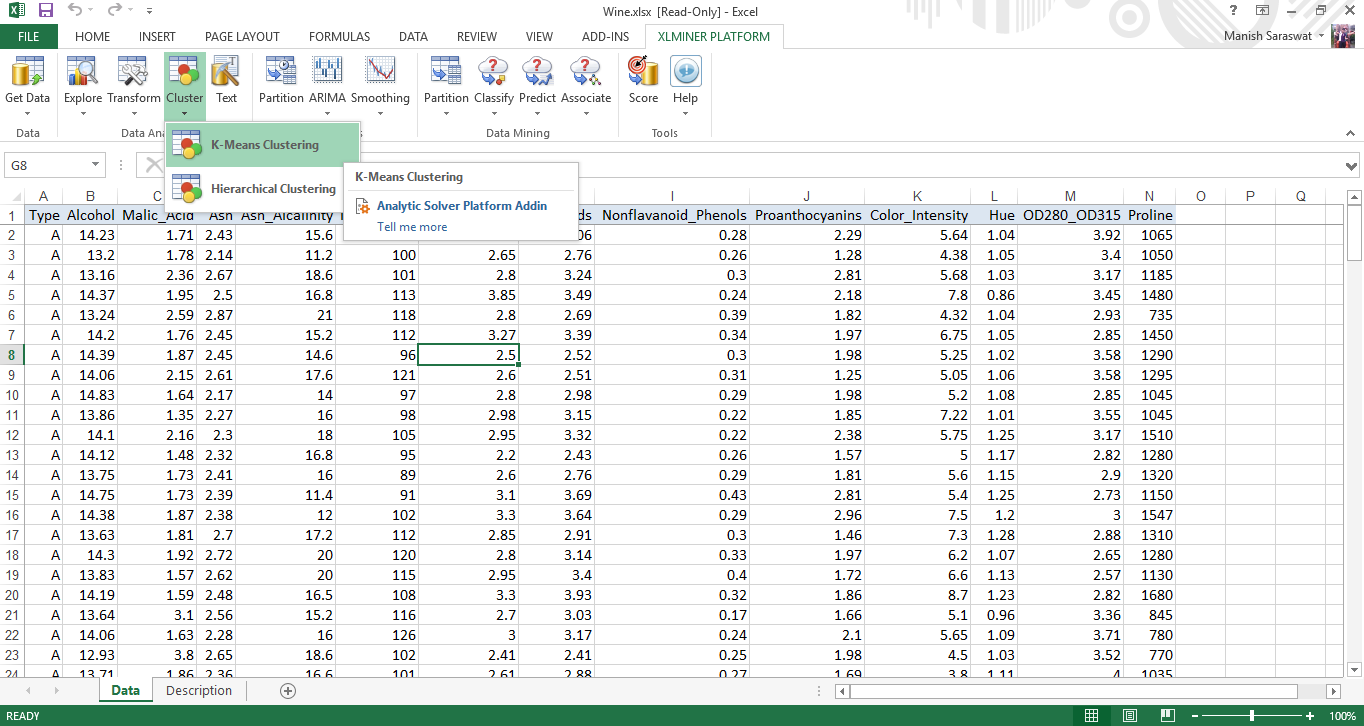
2. Fare clic su qualsiasi cella nel set di dati. Dopo, fare clic su k significa clustering.
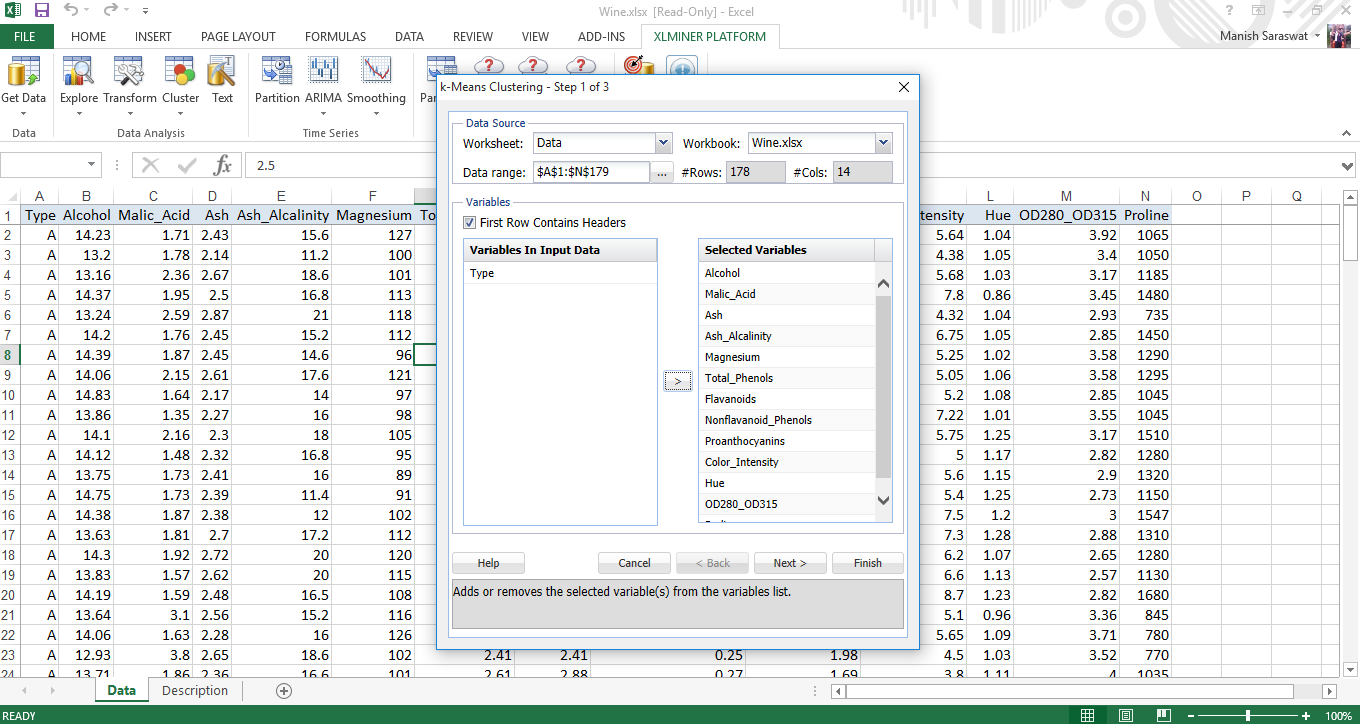
3. Il tipo è la variabile di output. Perciò, selezioneremo tutte le variabili tranne Type per usarle nel raggruppamento. Fare clic su Avanti.
4. Prendiamo il numero di cluster come 8. Perché, con un gran numero di cluster, la somma dell'errore al quadrato (SSE) ancora piccola. SSE è definito come la somma della distanza al quadrato tra ciascun membro del gruppo e il suo baricentro. Puoi impostare qualsiasi valore di k e valutare l'output di ciascuno per verificare qual è il migliore. Imposta un valore casuale per dire 5, consentirà a questo algoritmo di costruire il modello da qualsiasi punto casuale. Con questo, XLMiner genererà 5 conjuntos de clústeres y generará el resultado del mejor grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro..... Lascia riposare le impostazioni predefinite e fai clic su Avanti.
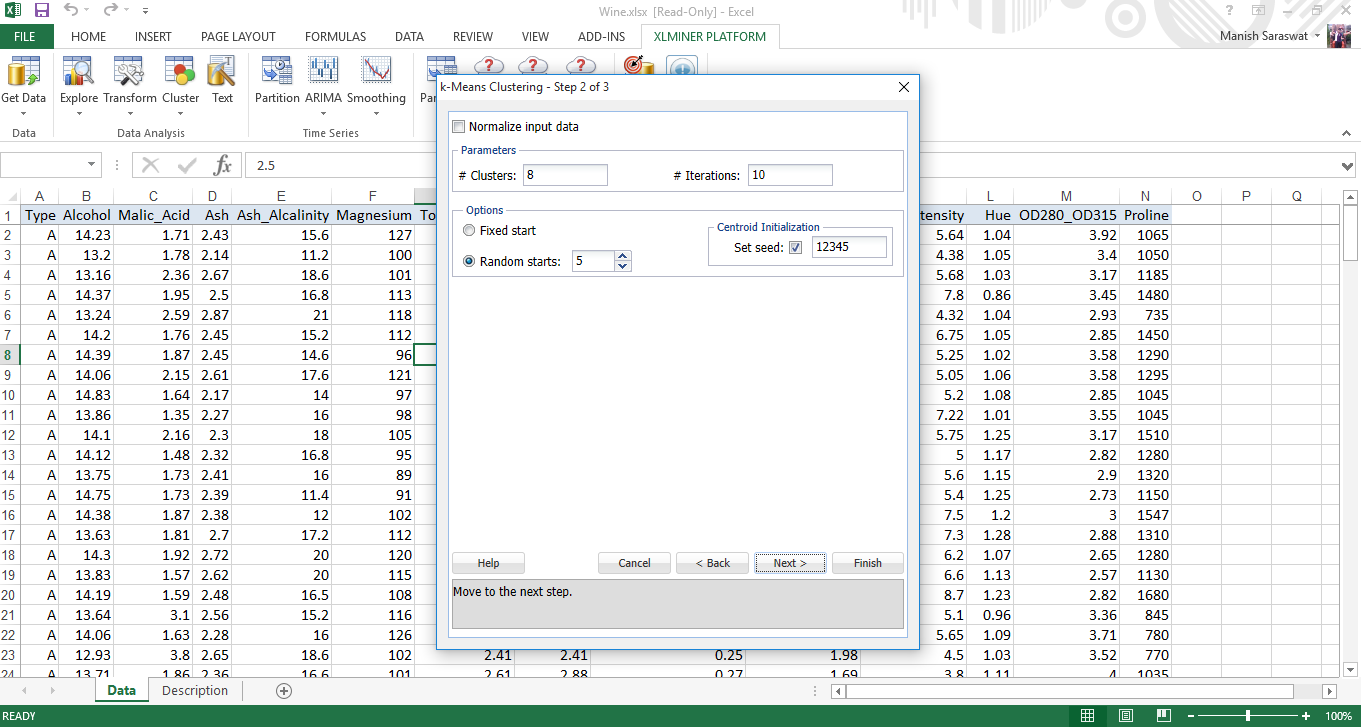
5. Lascia i valori predefiniti. Fare clic su Fine
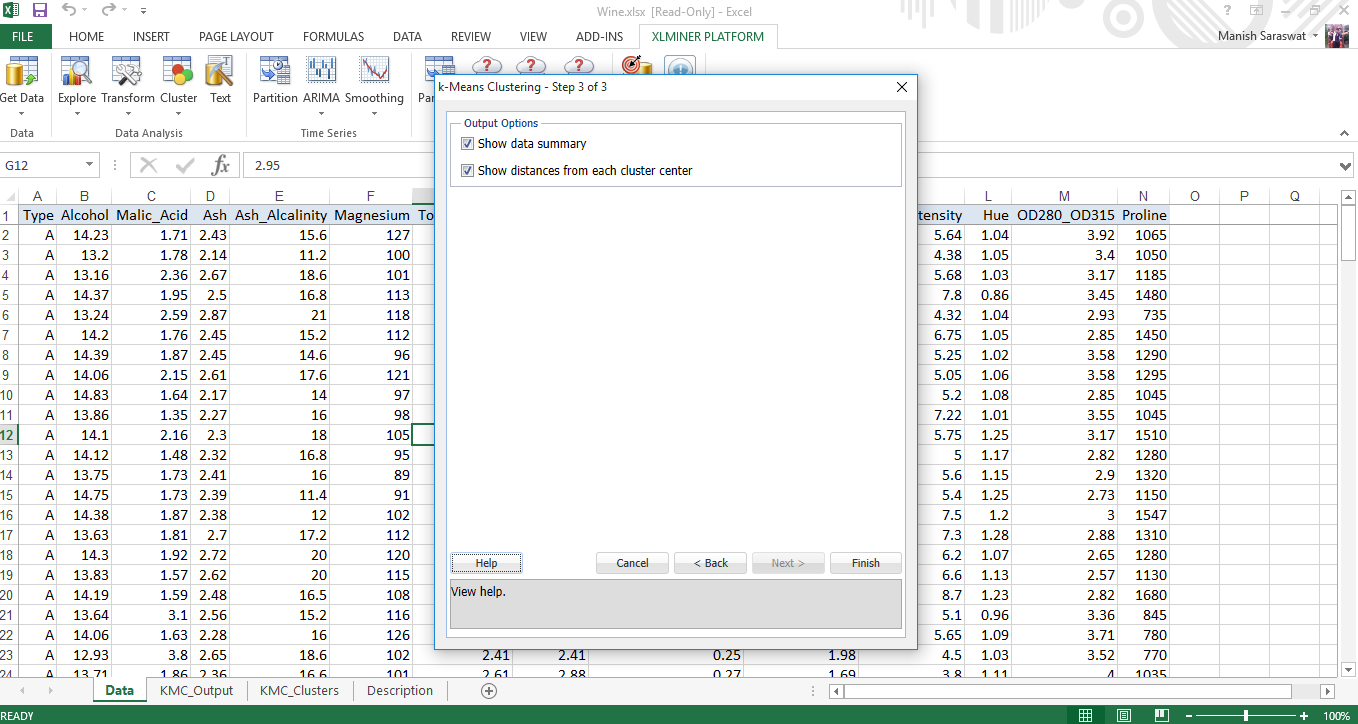
6. Ecco il tuo modello di raggruppamento. Dai un'occhiata alle nostre varie metriche di valutazione per determinare l'accuratezza di questo modello.
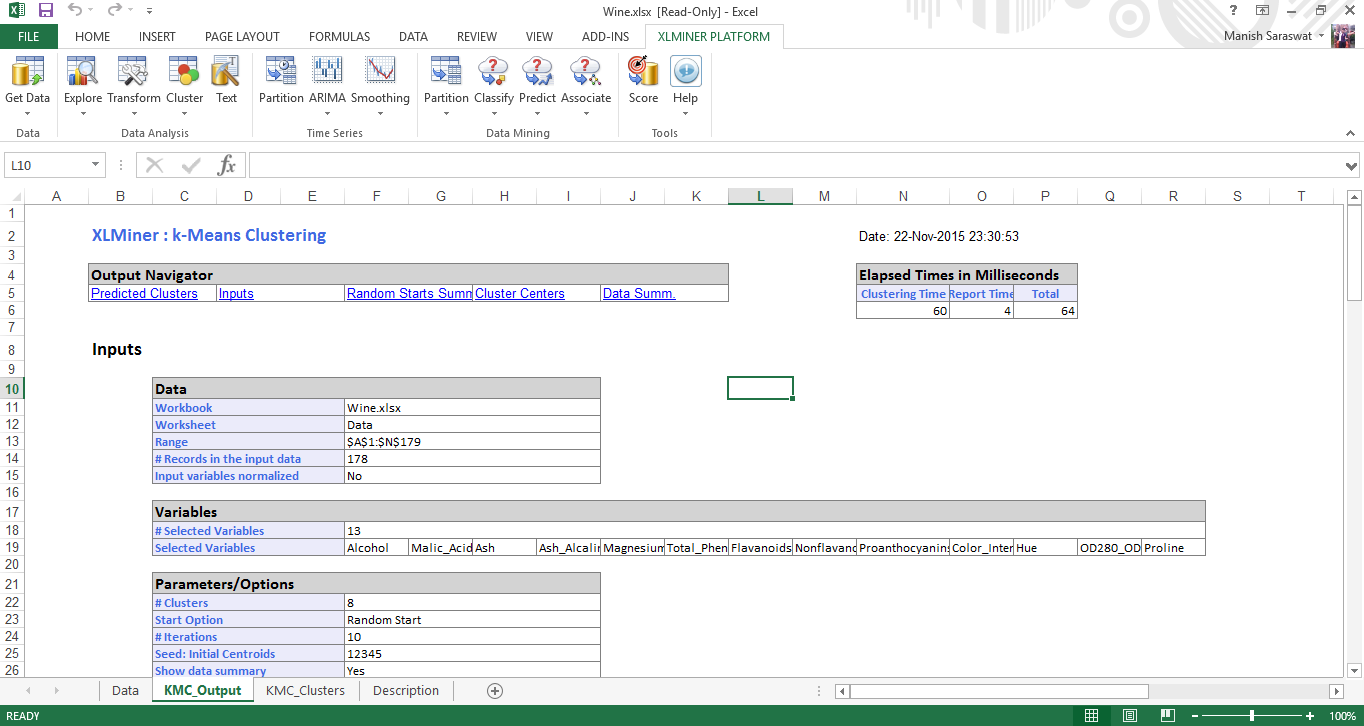
Riepilogo delle partenze casuali: Questa tabella determina l'inizio migliore con la somma dei quadrati della distanza più bassa. In questo caso (# 1) è il miglior inizio. Una volta determinato il miglior inizio, l'output rimanente del modello viene generato utilizzando l'inizio migliore come punto di partenza.
Centri cluster: Qui troverai due scatole. Il riquadro in basso mostra la distanza tra il baricentro dei cluster. Maggiore è la distanza, diversa sarà la natura dei gruppi. Ad esempio, la differenza tra il gruppo 4 e il gruppo 8 è 1176,59. Ciò suggerisce che questi gruppi sono molto diversi. La tabella in alto mostra i valori delle variabili nei centri dei cluster.
Riepilogo dati: Rappresenta la distanza media delle osservazioni dal centro di un gruppo. Possiamo dedurre che il cluster 2 ha la distanza media più bassa dal suo baricentro e dal cluster 6 ha il più alto.
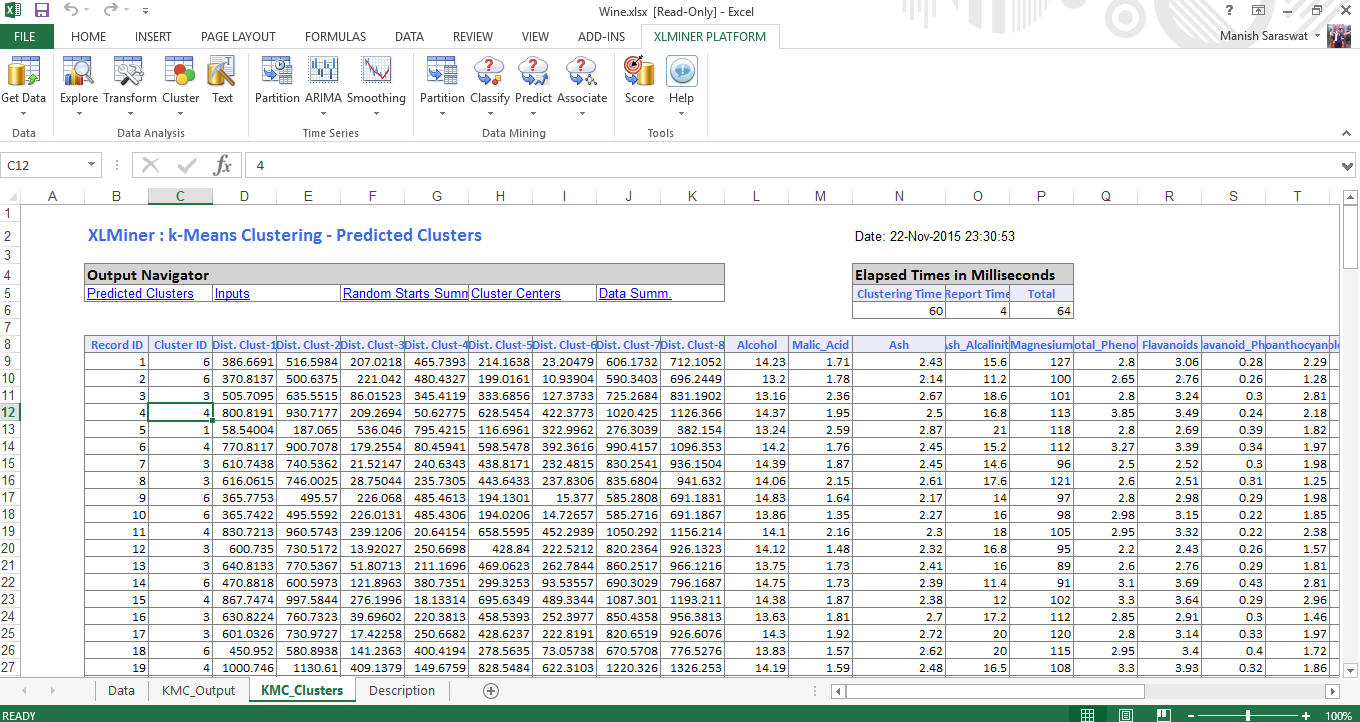
7. Fare clic sul foglio KMC_Clusters. Qui troverai i gruppi previsti. Controlla l'ID di registrazione 1. Si è qualificato nel girone 6. Perché la distanza di questa osservazione è minima per il gruppo 6. Allo stesso modo, tutte le altre osservazioni sono state classificate in base al loro gruppo più vicino.
Note finali
Ho scritto questo tutorial solo per iniziare con l'apprendimento automatico in Excel. Una volta compresi questi algoritmi, puoi facilmente usarli in R, Python o qualsiasi altro linguaggio di programmazione. Dal momento che molti di noi hanno lavorato in Excel ad un certo punto, non sarebbe difficile capire questi concetti in Excel. Se ti blocchi, puoi controllare l'opzione di aiuto in XLMiner Ribbon. La documentazione è utile e di facile comprensione.
Ora che conosci i passaggi, Ti suggerisco di prenderti del tempo per interpretare il modello e ripeterlo per ottenere la migliore vestibilità. Excel può rallentare con set di dati di grandi dimensioni, quindi dovresti lavorare con piccoli set di dati per risparmiare tempo nell'apprendimento.
Hai trovato questo articolo utile? Hai mai lavorato su XLMiner?? Mi piacerebbe sentire le vostre esperienze e suggerimenti nella sezione commenti qui sotto..





