Panoramica
- Che cos'è K sta per Clustering??
- Implementación de K significa Clustering
- WCSS y método de codo para encontrar el número de conglomerados
- Implementación de Python de K significa Clustering
K means es uno de los algoritmos de aprendizaje automático no supervisados más populares utilizados para resolver problemas de clasificación. K Significa que segrega los datos sin etiquetar en varios grupos, llamados clústeres, en función de tener características similares, patrones comunes.
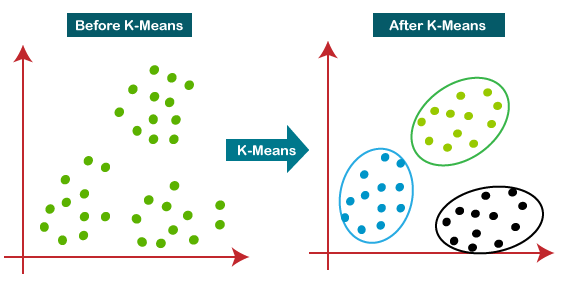
Sommario
- ¿Qué es la agrupación en clústeres?
- ¿Qué es el algoritmo de K significa?
- Implementación esquemática de la agrupación en clústeres de KMeans
- Elegir el número correcto de clústeres
- Implementazione Python
1. ¿Qué es la agrupación en clústeres?
Supongamos que tenemos un número N de conjuntos de datos multivariados sin etiquetar de varios animales como perros, gatos, pájaros, eccetera. La técnica para segregar conjuntos de datos en varios grupos, sobre la base de tener características y características similares, se denomina Clustering..
Los grupos que se forman se conocen como Clusters. La técnica de agrupación en clústeres se está utilizando en varios campos, como el reconocimiento de imágenes, el filtrado de correo no deseado
La agrupación en clústeres se utiliza en el algoritmo de Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso... en el aprendizaje automático como se pueden segregar datos multivariados en varios grupos, sin ningún supervisor, sobre la base de un patrón común oculto dentro de los conjuntos de datos.
2. ¿Qué es el algoritmo de K significa?
El algoritmo Kmeans es un algoritmo iterativo que divide un grupo de n conjuntos de datos en k subgrupos / clústeres en función de la similitud y su distancia media desde el centroide de ese subgrupo / formado en particular..
K, aquí está el número predefinido de clusters que formará el algoritmo. Si K = 3, significa que el número de conglomerados que se formarán a partir del conjunto de datos es 3
Pasos del algoritmo de K medias
El funcionamiento del algoritmo K-Means se explica en los siguientes pasos:
passo 1: Seleccione el valor de K para decidir el número de conglomerados que se formarán.
passo 2: Seleccione K puntos aleatorios que actuarán como centroides.
passo 3: Asigne cada punto de datos, en función de su distancia desde los puntos seleccionados al azar (centroide), al centroide más cercano / cercano que formará los grupos predefinidos.
passo 4: coloque un nuevo centroide de cada grupo.
passo 5: Ripetere il passaggio 3, que reasigna cada punto de datos al nuevo centroide más cercano de cada grupo.
passo 6: Si ocurre alguna reasignación, vaya al paso 4; altrimenti, vaya al paso 7.
passo 7: TERMINAR
3. Implementación esquemática de la agrupación en clústeres de K medias
PASO 1:Elijamos el número k de conglomerados, vale a dire, K = 2, para segregar el conjunto de datos y colocarlos en diferentes conglomerados respectivos. Elegiremos algunos 2 puntos aleatorios que actuarán como centroide para formar el grupo.
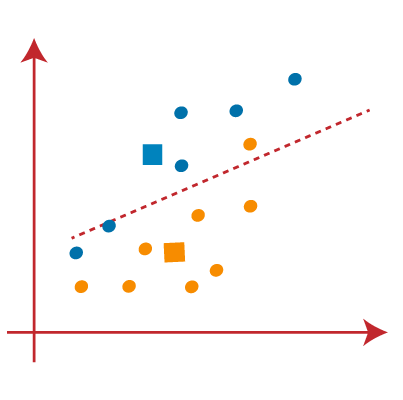
PASO 2: Ahora asignaremos cada punto de datos a un Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate.... basado en su distancia desde el punto K o centroide más cercano. Se hará dibujando una medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... entre ambos centroides. Considera la seguente immagine:
PASO 3: los puntos del lado izquierdo de la línea están cerca del centroide azul y los puntos a la derecha de la línea están cerca del centroide amarillo. El de la izquierda forma un grupo con centroide azul y el de la derecha con el centroide amarillo.
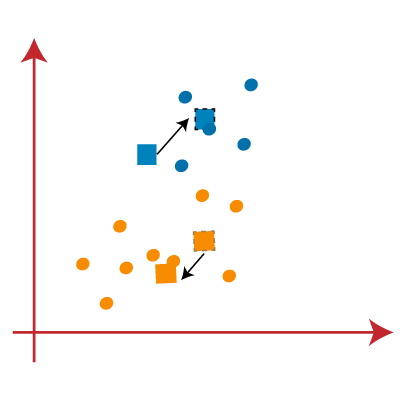
 PASO 4:repita el proceso eligiendo un nuevo centroide. Per scegliere i nuovi centroidi, encontraremos el nuevo centro de gravedad de estos centroides, mostrato sotto:
PASO 4:repita el proceso eligiendo un nuevo centroide. Per scegliere i nuovi centroidi, encontraremos el nuevo centro de gravedad de estos centroides, mostrato sotto:
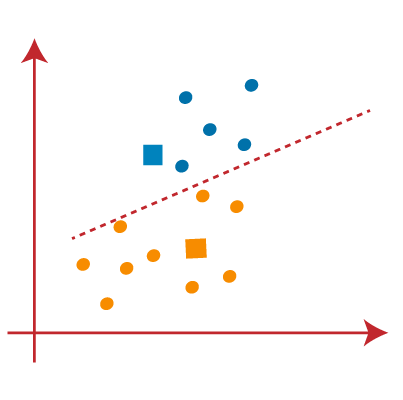
PASO 5: Prossimo, reasignaremos cada punto de datos al nuevo centroide. Repetiremos el mismo proceso anterior (usando una línea mediana). El punto de datos amarillo en el lado azul de la línea mediana se incluirá en el grupo azul
PASO 6: UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que se haya realizado la reasignación, repetiremos el paso anterior de encontrar nuevos centroides.
PASO 7: Repetiremos el proceso anterior de encontrar el centro de gravedad de los centroides, come mostrato di seguito.
PASO 8: Después de encontrar los nuevos centroides, dibujaremos nuevamente la línea mediana y reasignaremos los puntos de datos, como en los pasos anteriores.
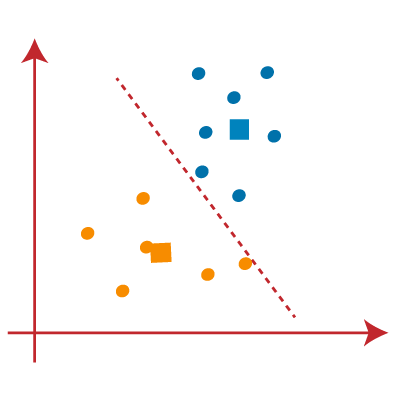
PASO 9: Finalmente, segregaremos puntos basados en la línea mediana, de manera que se formen dos grupos y ningún punto diferente se incluya en un solo grupo.
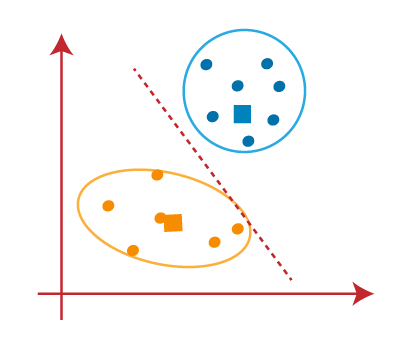
El grupo final que se está formando es el siguiente
4. Elegir el número correcto de clústeres
El número de clústeres que elegimos para el algoritmo no debe ser aleatorio. Todos y cada uno de los conglomerados se forman calculando y comparando las distancias medias de cada punto de datos dentro de un conglomerado desde su centroide.
Podemos elegir el número correcto de clústeres con la ayuda del método de suma de cuadrados dentro del grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... (WCSS).
WCSS Representa la suma de los cuadrados de las distancias de los puntos de datos en todos y cada uno de los grupos desde su centroide.
La idea principal es minimizar la distancia entre los puntos de datos y el centroide de los conglomerados. El proceso se itera hasta alcanzar un valor mínimo para la suma de distancias.
Para encontrar el valor óptimo de los clústeres, el método del codo sigue los pasos a continuación:
1 Eseguire il comando raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. de K-medias en un conjunto de datos dado para diferentes valores de K (que van del 1 al 10).
2 Per ogni valore di K, calcula el valor WCSS.
3 Traza un gráfico / curva entre los valores WCSS y el número respectivo de conglomerados K.
4 El punto agudo de curvatura o un punto (que parece una articulación del codo) de la trama como un brazo, se considerará como el mejor / óptimo valor de K
5. Implementazione Python
Importar bibliotecas relevantes
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
da sklearn.cluster importa KMeans
Caricamento dei dati
data = pd.read_csv('Countryclusters.csv')
dati
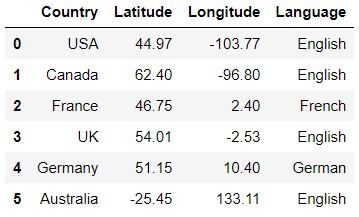
Graficar los datos
plt.scatter(dati['Longitude'],dati['Latitude']) plt.xlim(-180,180) plt.ylim(-90,90) plt.mostra()
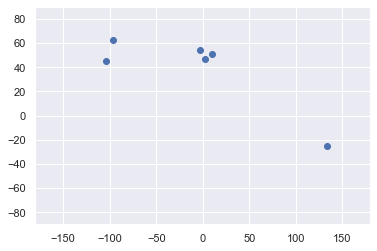
Seleccionar la función
x = data.iloc[:,1:3] # 1t for rows and second for columns
x
Raggruppamento
kmsignifica = KMezzi(3)
means.fit(X)
Resultados de la agrupación en clústeres
identified_clusters = kmeans.fit_predict(X) identified_clusters
Vettore([1, 1, 0, 0, 0, 2])
data_with_clusters = data.copy() data_with_clusters['Clusters'] = identified_clusters plt.scatter(data_with_clusters['Longitude'],data_with_clusters['Latitude'],c=data_with_clusters['Clusters'],cmap='rainbow')
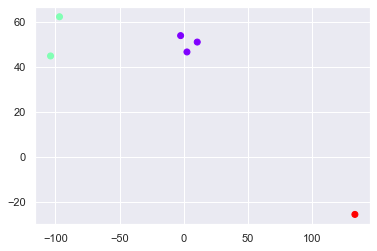
Probar un método diferente (para encontrar no. De grupos para seleccionar)
WCSS y método del codo
wcss=[] per io nel raggio d'azione(1,7): kmsignifica = KMezzi(io) kmeans.fit(X) wcss_iter = kmeans.inertia_ wcss.append(wcss_iter) number_clusters = range(1,7) plt.trama(number_clusters,wcss) plt.titolo('The Elbow title') plt.xlabel('Numero di cluster') plt.ylabel('WCSS')
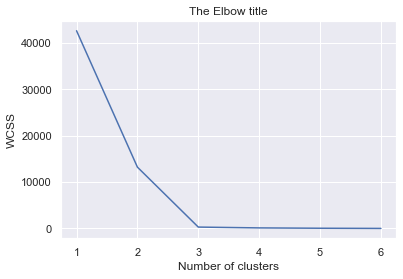
podemos elegir 3 como no. de conglomerados, este método muestra cuál es el buen número de conglomerados.
Con questo chiudo questo blog..
Ciao a tutti, Namaste
Mi nombre es Pranshu Sharma y soy un entusiasta de la ciencia de datos
Grazie mille per aver dedicato del tuo tempo prezioso a leggere questo blog.. Sentiti libero di segnalare eventuali errori (Dopotutto, sono un apprendista) e fornire i commenti corrispondenti o lasciare un commento.
Dhanyvaad !!
Feedback:
E-mail: [e-mail protetta]
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





