Panoramica
- Comprendi in dettaglio il significato di partizionamento e raggruppamento in Hive.
- Vedremo, come creare partizioni e cubi su Hive.
introduzione
Potresti aver visto un'enciclopedia nella tua biblioteca scolastica o universitaria. È una serie di libri che ti daranno informazioni su quasi tutto. Sai qual è il meglio dell'enciclopedia??

sì, hai indovinato. Le parole sono disposte in ordine alfabetico. Ad esempio, ha una parola in mente “piramidi”. Andrai direttamente a ritirare il libro con il titolo "P". Non devi cercarlo in altri libri. Riesci a immaginare quanto sarebbe difficile il compito di cercare un singolo libro se non fossero conservati in ordine??
Qui, memorizzare le parole in ordine alfabetico rappresenta l'indicizzazione, ma l'utilizzo di una posizione diversa per le parole che iniziano con lo stesso carattere è noto come raggruppamento.
Esistono tipi simili di tecniche di archiviazione, come partizioni e raggruppamenti, Su Apache Hive così possiamo ottenere risultati più rapidi per le query di ricerca. In questo articolo, vedremo cos'è la partizione e il raggruppamento, e quando usare quale.
Sommario
- Che cos'è il partizionamento??
- Quando usare il partizionamento?
- Che cos'è il raggruppamento??
- Quando usare il raggruppamento?
Che cos'è il partizionamento??
Apache Hive ci permette di organizzare la tabella in più partizioni dove possiamo raggruppare lo stesso tipo di dati. Utilizzato per distribuire il carico orizzontalmente. Capiamo con un esempio:
Supponiamo di dover creare una tabella nell'alveare contenente i dettagli del prodotto per un'azienda di e-commerce di moda. Ha le seguenti colonne:
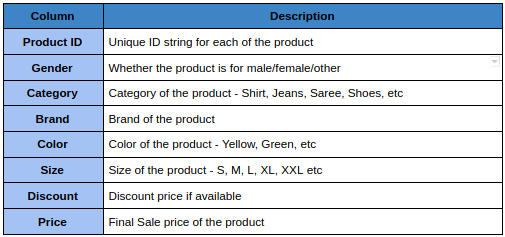
Ora, il primo filtro utilizzato dalla maggior parte dei clienti è Gender, quindi seleziona categorie come Camicia, le sue dimensioni e il colore. Vediamo come creare le partizioni per questo esempio.
CREA TABELLA prodotti ( stringa id_prodotto,
stringa di marca,
stringa di dimensioni,
sconto galleggiante,
prezzo fluttuante )
DIVISO DA (stringa di genere,
stringa di categoria,
stringa di colore);
Ora, l'alveare memorizzerà i dati nella struttura della directory come:
/user/hive/warehouse/mytable/gender=male/category=shoes/color=black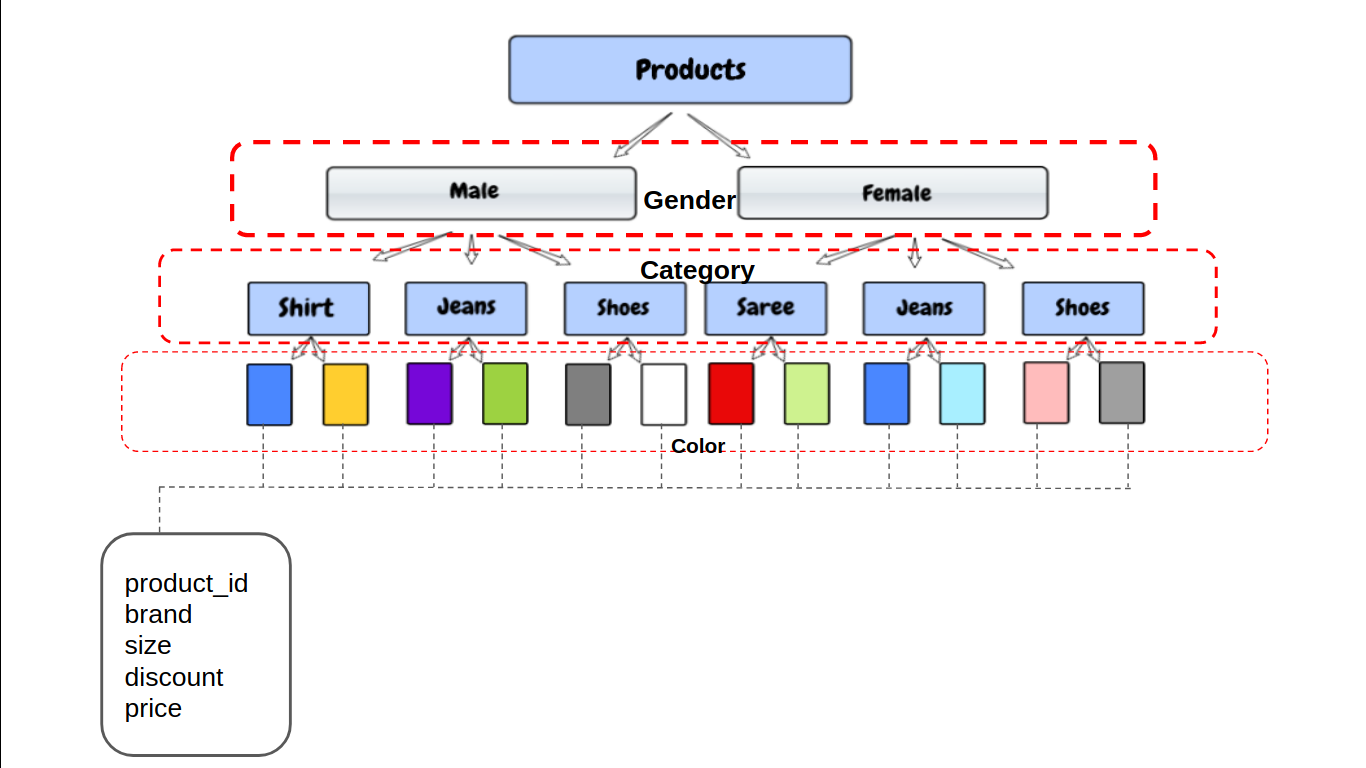
Il partizionamento dei dati ci offre vantaggi in termini di prestazioni e ci aiuta anche a organizzare i dati. Ora, vediamo quando usare la partizione in hive.
Quando usare il partizionamento?
- Quando la colonna con una query di ricerca alta ha una cardinalità bassa. Ad esempio, se crei una partizione con il nome del paese, un massimo di 195 le partizioni e l'alveare saranno in grado di gestire così tante directory.
- In secondo luogo, non partizionare colonne con cardinalità molto alta. Ad esempio, numero identificativo del prodotto, timestamp e prezzo perché creerà milioni di directory che sarà impossibile gestire per l'alveare.
- È efficace quando il volume di dati su ciascuna partizione non è molto elevato. Ad esempio, se hai i dati della compagnia aerea e vuoi calcolare il numero totale di voli in un giorno. Quindi, il risultato impiegherà più tempo per il calcolo sulla partizione “Dubai”, poiché ha uno degli aeroporti più trafficati del mondo, mentre per un paese come “Albania” restituirà i risultati più velocemente.
Che cos'è il raggruppamento??
Nell'esempio sopra, sappiamo che non possiamo partizionare sul prezzo della colonna perché il suo tipo di dati è float e ci sono un numero infinito di possibili prezzi unici.
Hive dovrà generare una directory separata per ciascuno dei prezzi unici e sarebbe molto difficile per Hive gestirli. Invece di questo, possiamo definire manualmente il numero di depositi che vogliamo per queste colonne.
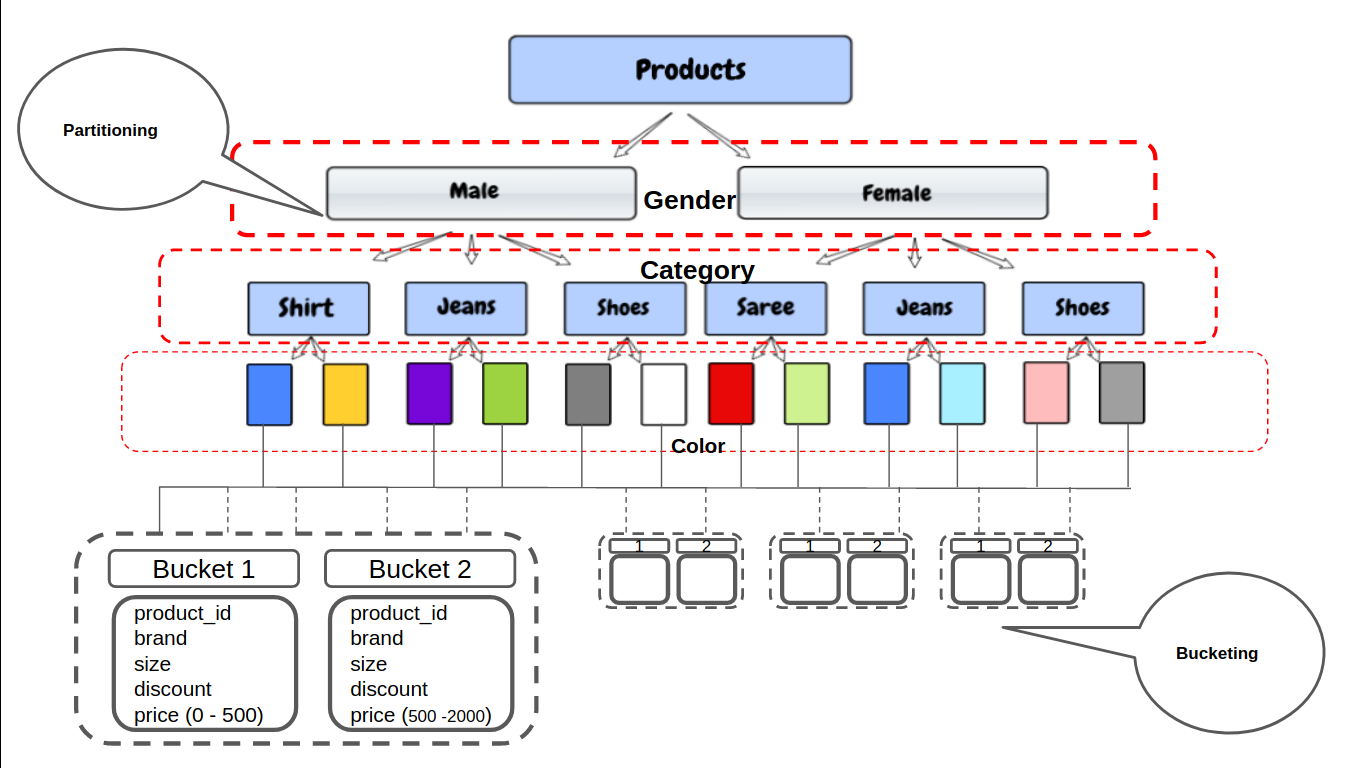
In raggruppamento, le partizioni possono essere suddivise in gruppi in base alla funzione hash di una colonna. Fornisce una struttura aggiuntiva ai dati che possono essere utilizzati per query più efficienti.
CREA TABELLA prodotti ( stringa id_prodotto,
stringa di marca,
stringa di dimensioni,
sconto galleggiante,
prezzo fluttuante )
DIVISO DA (stringa di genere,
stringa di categoria,
stringa di colore)
RAGGRUPPATO DA (prezzo) IN 50 SECCHI;
Ora, sarà solo creato 50 depositi, non importa quanti valori univoci ci sono nella colonna del prezzo. Ad esempio, nel primo cubo, tutti i prodotti con un prezzo [ 0 – 500 ] Iran, e nel prossimo gruppo di prodotti con un prezzo [ 500 – 200 ] e così via.
Quando usare il raggruppamento?
- Non possiamo dividere in una colonna con una cardinalità molto alta. Troppe partizioni genereranno più file Hadoop, che aumenterà il carico sullo stesso nodo, poiché deve trasportare i metadati di ciascuna delle partizioni.
- Se alcune combinazioni del lato della mappa sono coinvolte nelle tue query, i tavoli raggruppati sono una buona opzione. L'unione lato mappa è un processo in cui due tabelle vengono unite utilizzando la sola funzione mappa senza alcuna funzione ridotta. Ti consiglio di leggere questo articolo per capire meglio le combinazioni dei lati della mappa: Il lato della mappa si unisce a Hive
Note finali
In questo articolo, abbiamo visto cos'è la partizione e il raggruppamento, come crearli e quali sono i loro pro e contro.
Consiglio vivamente di consultare le seguenti risorse per saperne di più su Apache Hive:
Se hai domande relative a questo articolo, fammi sapere nella sezione commenti qui sotto.





