Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione

Il Web Scraping è un metodo o un'arte per ottenere o eliminare dati da Internet o da siti Web e archiviarli localmente sul tuo sistema. Il Web Scripting è una strategia programmata per acquisire molte informazioni dai siti.
La stragrande maggioranza di queste informazioni sono informazioni non strutturate in un layout HTML che vengono successivamente convertite in informazioni organizzate in una pagina di contabilità o in un set di dati., quindi tende ad essere utilizzato in diverse applicazioni. Esiste un'ampia gamma di approcci al web scraping per ottenere informazioni dai siti. Questi includono l'uso di applicazioni web, API specifica di, in ogni caso, crea il tuo codice per il web scraping senza alcuna preparazione.
Numerosi siti enormi come Google, Twitter, Facebook, StackOverflow, eccetera. avere API che ti consentono di accedere alle tue informazioni in un'organizzazione organizzata. Questa è l'opzione più ideale, ma localizzazioni diverse non consentono ai client di accedere a molte informazioni in una struttura organizzata o, in sostanza, non progrediscono in modo così meccanico. Laggiù, è ideale utilizzare Web Scraping per trovare informazioni sul sito.

I Web Scraper possono estrarre tutte le informazioni su destinazioni specifiche o le informazioni particolari di cui un cliente ha bisogno. Preferibilmente, è l'ideale se indichi le informazioni di cui hai bisogno in modo che il web scraper concentri semplicemente quelle informazioni rapidamente. Ad esempio, dovresti grattare una pagina Amazon per i tipi di spremiagrumi disponibili, tuttavia, potresti aver bisogno solo delle informazioni sui modelli dei vari spremiagrumi e non degli audit dei clienti.
Quindi, quando un debugger web ha bisogno di graffiare un sito web, prima ti vengono forniti gli URL delle impostazioni locali richieste. A quel punto, impilare tutto il codice HTML per quelle destinazioni e uno scraper più sviluppato può anche concentrare tutti i componenti CSS e Javascript. A quel punto, lo scraper acquisisce le informazioni necessarie da questo codice HTML e trasferisce queste informazioni all'organizzazione indicata dal cliente.
In genere, è come una pagina di contabilità Excel o un record CSV, tuttavia, le informazioni possono anche essere archiviate in diverse organizzazioni, ad esempio, un documento JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software...

Librerie Python popolari per il web scraping
- petizioni
- Bella zuppa 4
- lxml
- Selenio
- Scrapy
Raschiatore automatico
È una libreria di web scraping Python per rendere intelligente lo scraping web, automatico, facile e veloce. È anche leggero, il che significa che non influenzerà molto il tuo PC. Un utente può facilmente utilizzare questo strumento di scraping dei dati grazie alla sua interfaccia user-friendly.. Iniziare, devi solo scrivere poche righe di codice e vedrai la magia.
Devi solo fornire l'URL o il contenuto HTML della pagina web da cui vuoi rimuovere i dati, Cosa c'è di più, un riepilogo delle informazioni sul test che dovremmo rimuovere da quella pagina. Queste informazioni possono essere di testo, URL o qualsiasi tag HTML su quella pagina. Impara le regole del gratta e vinci da solo e restituisci articoli simili.
In questo articolo, indagheremo su Autoscraper e vedremo come possiamo usarlo per rimuovere informazioni da noi.

Installazione
Ci sono 3 modi per installare questa libreria sul tuo sistema.
- Installa dal repository git usando pip:
pip installa git+https://github.com/alirezamika/autoscraper.git
pip installa raschiatore automatico
python setup.py installa
Importazione della libreria
Importeremo solo un raschietto automatico, in quanto è adatto solo per graffiare il web. Di seguito il codice da importare:
da autoscraper import AutoScraper
Definizione della funzione web scraping
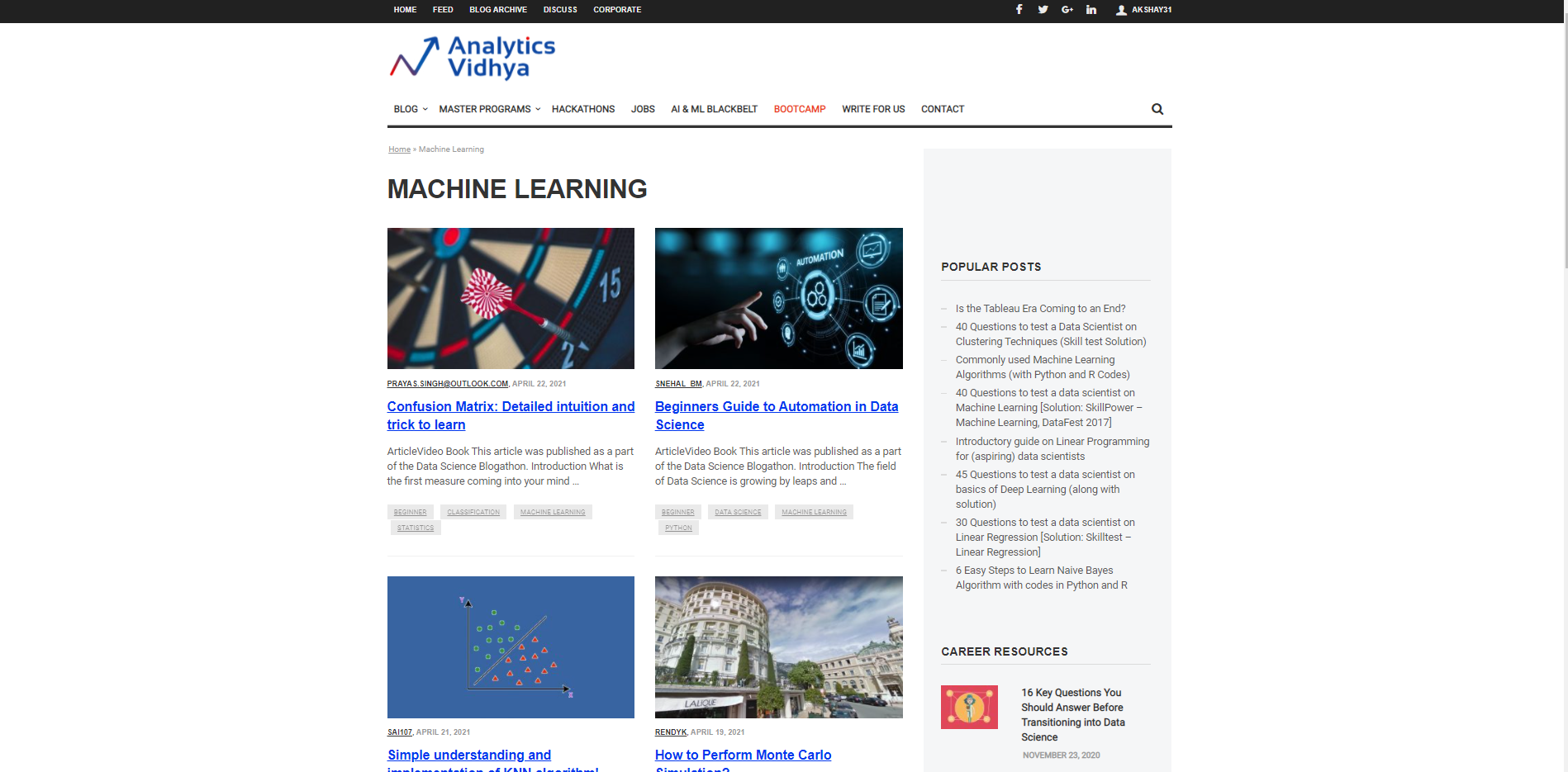
Iniziamo caratterizzando un URL da cui verrà utilizzato per portare le informazioni e la prova delle informazioni necessarie da portare. Supponiamo di voler cercare il Titoli per diversi articoli sull'apprendimento automatico sul sito Web di DataPeaker. Perciò, dobbiamo passare l'URL della sezione del blog sull'apprendimento automatico di DataPeaker e la seconda lista di ricercati. La lista dei ricercati è una lista che è Dati di esempio che vogliamo estrarre da quella pagina. Ad esempio, qui l'elenco dei ricercati è un titolo di qualsiasi blog nella sezione del blog sull'apprendimento automatico di DataPeaker.
URL="https://www.analyticsvidhya.com/blog/category/machine-learning/" lista_ricercati = ["Matrice di confusione": Intuizione dettagliata e trucco per imparare']
Possiamo aggiungere uno o più candidati alla lista dei ricercati. Puoi anche inserire gli URL nell'elenco dei ricercati per recuperare gli URL.
Avvia l'AutoScraper
Il passaggio successivo dopo aver avviato l'URL e l'elenco dei ricercati è chiamare la funzione AutoScraper. Il nostro obiettivo è utilizzare questa funzione per costruire il modello di scraper ed eseguire il web scraping su quella particolare pagina.
Questo può essere avviato utilizzando il seguente codice:
raschietto = AutoScraper()
Costruire l'oggetto
Questo è il passaggio finale nel web scraping con questa particolare libreria. Qui, crea l'oggetto e mostra il risultato del web scraping.
raschietto = AutoScraper() risultato = scraper.build(URL, Wanted_list) Stampa(risultato)

Qui, nella foto sopra, puoi vedere che torna. il titolo dei blog sul sito DataPeaker nella sezione machine learning, allo stesso modo, possiamo ottenere gli URL dei blog semplicemente passando l'URL di esempio nell'elenco dei ricercati che abbiamo definito in precedenza.
URL="https://www.analyticsvidhya.com/blog/category/machine-learning/" lista_ricercati = ['https://www.analyticsvidhya.com/blog/2021/04/confusion-matrix-detailed-intuition-and-trick-to-learn/'] raschietto = AutoScraper() risultato = scraper.build(URL, Wanted_list) Stampa(risultato)
Ecco l'output del codice sopra. Puoi vedere che questa volta ho passato l'URL nell'elenco dei ricercati, di conseguenza, puoi vedere il risultato come URL del blog

Salva il modello
Ci permette di salvare il modello che dobbiamo costruire per poterlo ricaricare quando necessario.
Per salvare il modello, usa il seguente codice
raschietto.salva("blog") #Assegnagli un percorso di file
Per caricare il modello, usa il seguente codice:
raschiatore.carico("blog")
Nota: Oltre a ciascuna di queste funzionalità, lo scraper automatico consente anche di caratterizzare gli indirizzi IP proxy in modo da poterli utilizzare per ottenere informazioni. Abbiamo semplicemente bisogno di caratterizzare i proxy e passarli come argomento alla funzione build come mostrato di seguito:
proxy = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
risultato = scraper.build(URL, Wanted_list, request_args=dict(proxy=proxy))
Per maggiori informazioni, vedi il link qui sotto: Raschiatore automatico
conclusione
In questo articolo, percepiamo come possiamo usare Autoscraper per il web scraping creando un modello di base e semplice da usare. Abbiamo visto diversi formati in cui le informazioni possono essere recuperate utilizzando Autoscraper. Possiamo anche salvare e caricare il modello per usarlo in seguito, che fa risparmiare tempo e fatica. Il raschietto automatico è fantastico, facile da usare ed efficiente.
Grazie per aver letto questo articolo e per la tua pazienza.. Lasciami nella sezione commenti sui commenti. Condividi questo articolo, mi darà la motivazione per scrivere più blog per la comunità di data science.
Identificazione e-mail: gakshay1210@ gmail.com
Seguimi su LinkedIn: LinkedIn
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





