prima di continuare, analizziamo brevemente Raschiato via e più tardi Raschiatore automatico:
Che cosa sta raschiando??
Il web scraping è una tecnica fondamentale utilizzata per estrarre informazioni utili come i contatti, email, immagini, URL, ecc... dei siti web. L'altra forma di web scraping è la scansione. Utilizzato quando abbiamo bisogno di una grande quantità di dati strutturati ed etichettati per i fondamentali industriali. Il software di web scraping può accedere direttamente al world wide web utilizzando i protocolli HTML.
Sai che le nuove forme di web scraping comportano l'osservazione del feed di dati sui server web, ad esempio, un archivo JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.. que se utiliza como transportador entre el cliente y el servidor web.
Ci sono molti grandi siti web che Google, Facebook, Amazon, eccetera. fornire API che ti consentono di accedere ai tuoi dati in un formato strutturato o taggato.
Ora, analizziamo brevemente la libreria AutoScraper:
Cos'è AutoScraper?
Quando si parla di raschiare, ci sono molte cose sul sito web che vogliamo rimuovere, ma gli script scrivibili impiegano molto tempo per rimuovere i dati ed è un processo molto lungo, per superare questo problema, un gruppo di sviluppatori Python sviluppa una libreria. che estrarrà tutti i dati da un sito Web in modo semplice. Quindi Raschiatore automatico è una libreria Python di web scraping utilizzata per raschiare i dati da un sito Web in modo semplice, facile e veloce. Ha un ambiente user-friendly da questo raschietto puoi interagire facilmente con questa libreria.

Utilizza gli URL del sito Web e il contenuto HTML per estrarre informazioni e dati affidabili.
Punto da considerare: impara le regole di scraping e restituisci articoli simili in un buon formato.
È facile rimuovere il contenuto del sito web che è stato facile rivedere come titolo, prezzo, Nome, giudizi, eccetera. Apetta un minuto! Cosa faremo con le immagini? È una bella domanda che si pone, possiamo dare l'immagine durante l'esecuzione del programma😅. Sto trovando un modo per rimuovere le immagini dai siti Web. Analizziamo di seguito:

Primo, andiamo per l'installazione di questa libreria:
Installa AutoScraper
Esistono due modi per installare AutoScraper:
Usando pip: –
Inserisci il seguente codice al prompt dei comandi,
pip installa raschiatore automatico
o con il repository git,
clon de git https://github.com/brandonrobertz/autoscrape-py
cd autoscrape-py /
pip install.[Tutti]
Ora importiamo moduli importanti:
Importazione modulo
# Importazione di AutoScraper da autoscraper import AutoScraper
Qui importiamo la classe AutoScraper dalla libreria.
Ora inviamo l'URL alla funzione AutoScraper per continuare a raschiare:
URL: – https://www.bookswagon.com/
Qui forniamo l'URL del sito di e-commerce alla classe AutoScraper per estrarre o grattare le immagini del libro.
Ora, prima di andare avanti, per prima cosa vediamo la demo grattando i titoli dei libri e i prezzi per ottenere una comprensione migliore e di base del codice da grattare:
Demo di raschiatura
Ora, alimenteremo l'elenco degli elementi da grattare, quindi prima dobbiamo inizializzare la classe AutoScraper con il suo oggetto:
Lista dei ricercati:
creare un elenco di elementi
# creare un elenco di elementi articoli = ['Rs.349' , "Il segreto dei Naga"]

Creazione di oggetti:
# creare oggetto raschiare = AutoScraper() # alimentazione per raschiare risultato_finale = scrape.build(URL,Oggetti) # visualizzare il risultato Stampa(risultato finale)

È ora di eliminare l'immagine
Ora, avere un'idea del codice di web scraping di cui abbiamo discusso in precedenza, quindi usiamo questo stesso metodo per raschiare le immagini del sito Web con alcune modifiche. Perciò, discuteremo il metodo o la tecnica per estrarre le immagini dai dati. vediamo dopo:
passo 1:
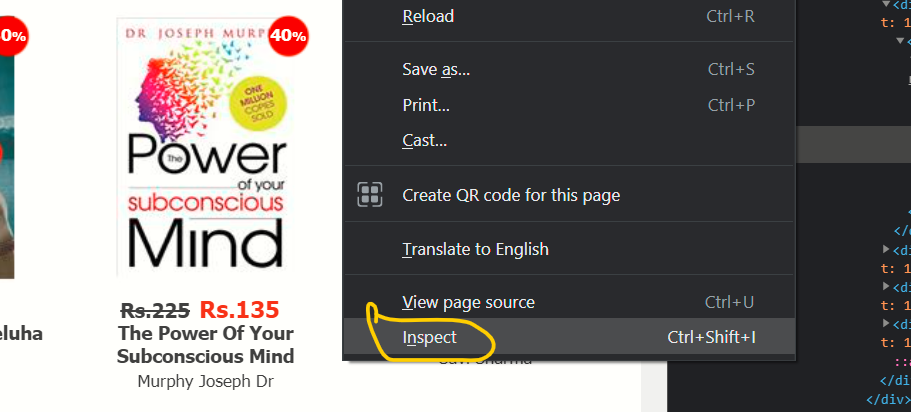
Nel primo passo, dobbiamo fare clic con il tasto destro del mouse e quindi selezionare l'opzione di ispezione dall'elenco dei menu:
passo 2:
Dopo aver selezionato l'opzione di ispezione, si apre una pagina di contenuto HTML accanto allo schermo, poi passerà sopra l'immagine del libro; al momento, avviso nella pagina del contenuto HTML che troverai il URL dell'immagine.
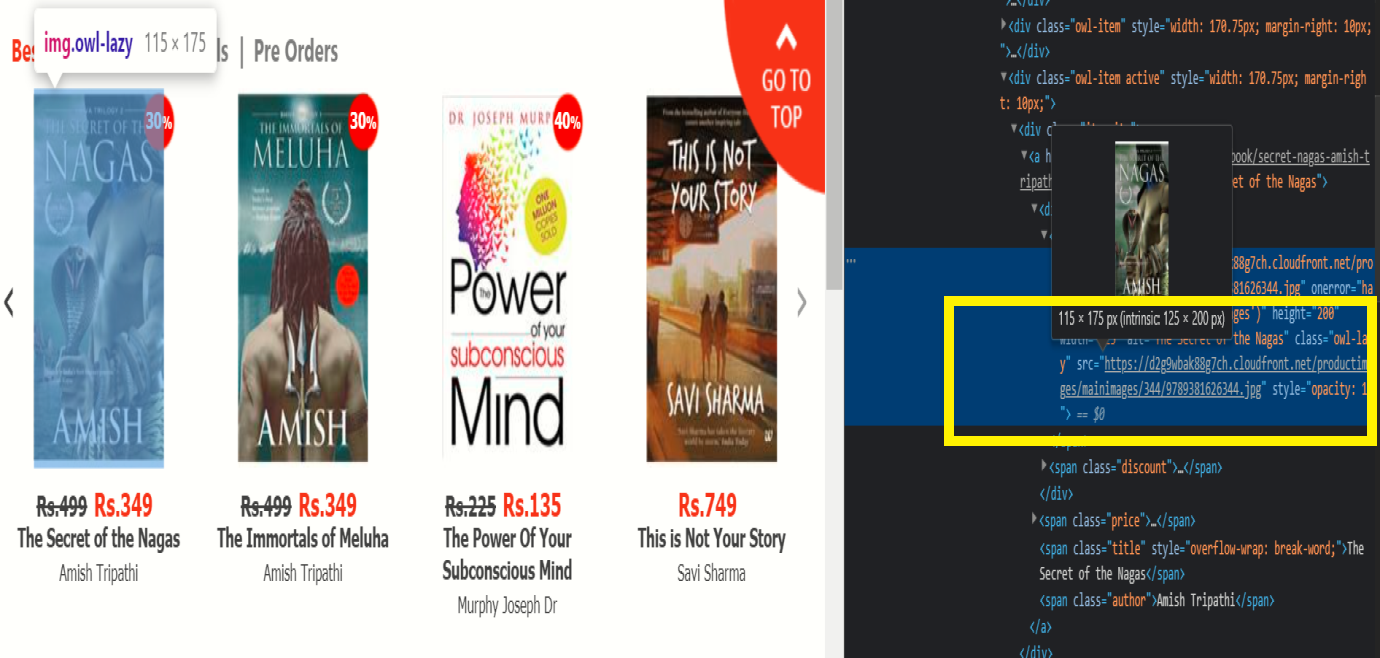
Quando trovi l'URL dell'immagine particolare, copialo e lo useremo nella lista dei desideri. Questo è solo il cambiamento necessario per raschiare le immagini dal sito web.
passo 3:
Ora, configureremo l'URL dell'immagine insieme ai libri che sono entrati nella nostra lista dei ricercati,
articolo = ['https://d2g9wbak88g7ch.cloudfront.net/productimages/mainimages/344/9789381626344.jpg',"Questa non è la tua storia"]
Dopo aver creato una lista, facciamo lo stesso processo che abbiamo fatto sopra:
# creare oggetto
raschiare = AutoScraper()
# building result
final_result = scrap.build( URL, articolo )
# visualizzare il risultato
Stampa(risultato finale)
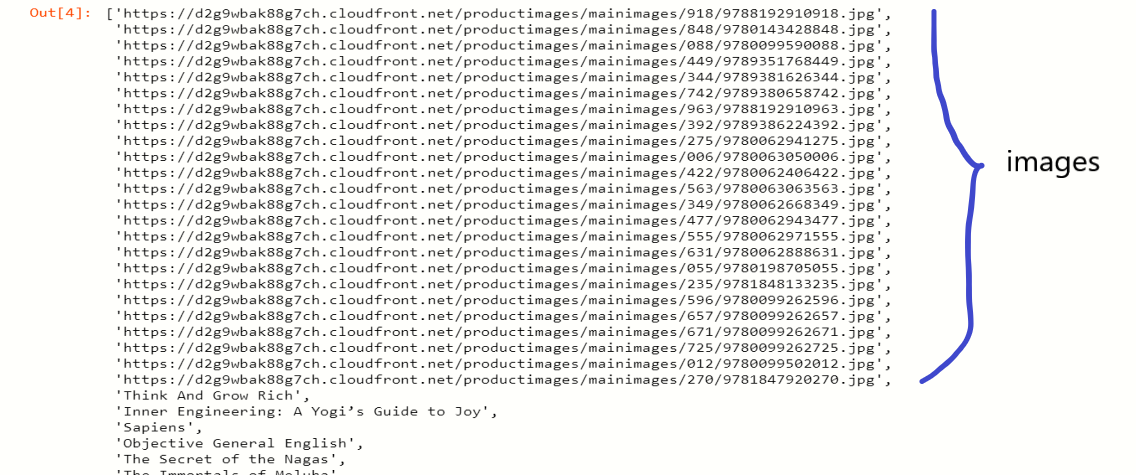
Nota: usa l'url delle immagini per estrarre le immagini dal sito
Quindi, questo è il processo per raschiare le immagini da qualsiasi sito web.
Nota finale
Quindi, qui discuteremo dello scraping delle immagini del sito web, se vuoi rimuovere le immagini dal sito web, usa questa tecnica. Sono molto sorpreso di usare questa libreria AutoViz. Spero che questo articolo ti sia piaciuto e grazie per aver letto questo articolo.
Puoi connetterti con me su Linkedin: Profilo URL
Leggi anche i miei altri articoli: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Grazie.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





