Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Bene! Tutti noi amiamo le torte. Se dai un'occhiata più da vicino al processo di cottura, noterai come la giusta combinazione dei vari ingredienti e un agente di lievito intelligente, lievito in polvere, puoi decidere tu l'ascesa e la caduta della tua torta.
“Cuocere la torta” può sembrare fuori luogo nel whitepaper, ma penso che sia abbastanza riconoscibile e una deliziosa analogia per comprendere l'importanza dell'EDA nel processo di data science.
Quando cuocere la torta è per la pipeline della scienza dei dati, entonces agente lievitante intelligente (lievito in polvere) è per l'analisi esplorativa dei dati.
Prima che ti venga l'acquolina in bocca per una torta come la mia, capiamo.
Che cos'è esattamente l'analisi esplorativa dei dati??
L'analisi esplorativa dei dati è un approccio all'analisi dei dati che impiega una varietà di tecniche per:
- Ottieni informazioni dettagliate sui dati.
- Fai i controlli di integrità. (Per essere sicuri che le informazioni che stiamo estraendo provengano effettivamente dal set di dati corretto).
- Scopri dove mancano i dati.
- Controlla gli outlier.
- Riassumi i dati.
Prendi il famoso caso di studio di “SALDI DEL BLACK FRIDAY” capire, Perché abbiamo bisogno dell'EDA??

Il problema principale è comprendere il comportamento del cliente prevedendo l'importo dell'acquisto. Ma, Non è troppo astratto e ti lascia perplesso su cosa fare con i dati?, soprattutto quando hai tanti prodotti diversi con varie categorie?
Prima di continuare a leggere, pensa un po' a questa domanda: Metteresti tutti gli ingredienti disponibili in cucina così com'è nel forno per cuocere la torta?
Ovviamente, la risposta è no! Prima di prendere in considerazione l'intero set di dati, inserirlo nel modello di apprendimento automatico, vorrò
- Estrai informazioni importanti
- Identificazione variabile (se i dati contengono variabili categoriche o numeriche o una combinazione di entrambe).
- Il comportamento delle variabili (se le variabili hanno valori di 0 un 10 o de 0 un 1 milioni).
- Relazione tra variabili (come le variabili dipendono l'una dall'altra).
-
Verifica la consistenza dei dati
- Per garantire che tutti i dati siano presenti. (Se raccogliamo dati da tre anni, eventuali settimane mancanti possono essere un problema nelle fasi successive).
- C'è qualche valore mancante presente??
- Ci sono valori anomali nel set di dati?? (ad esempio: una persona con 2000 anni è sicuramente un'anomalia)
- Ingegneria delle funzioni
- Ingegneria delle caratteristiche (per creare nuove funzionalità dalle funzionalità grezze esistenti nel set di dati).
** EDA, in sostanza, può rompere o eseguire qualsiasi modello di apprendimento automatico. **
Fasi dell'analisi esplorativa dei dati

Ci sono 5 passi in EDA: ->
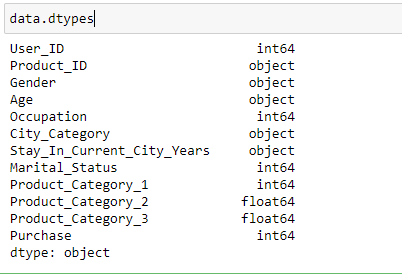
- Identificazione variabile: In questo passaggio, identifichiamo ogni variabile scoprendone il tipo. Secondo le nostre esigenze, possiamo cambiare il tipo di dati di qualsiasi variabile.

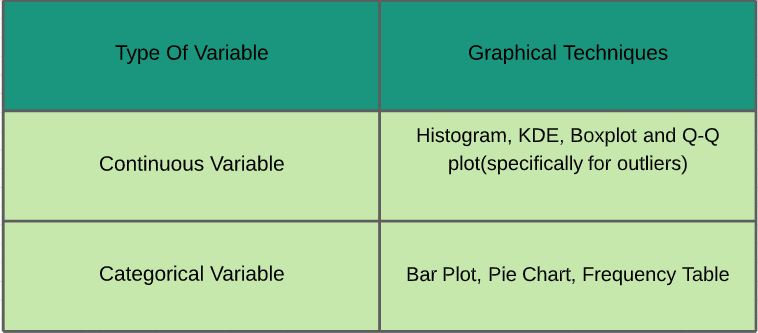
~ Le statistiche svolgono un ruolo importante nell'analisi dei dati. È un insieme di regole e concetti per l'analisi e l'interpretazione dei dati. Esistono diversi tipi di analisi che devono essere eseguite a seconda delle esigenze. ~ Studiamoli - Analisi invariate: In analisi univariata, studiamo le caratteristiche individuali di ogni caratteristica / variabile disponibile nel set di dati. Ci sono due tipi di funzioni: continuo e categorico. Nell'immagine qui sotto, Ho fornito un cheat sheet di varie tecniche grafiche che possono essere applicate per analizzarle.

Variabile continua:
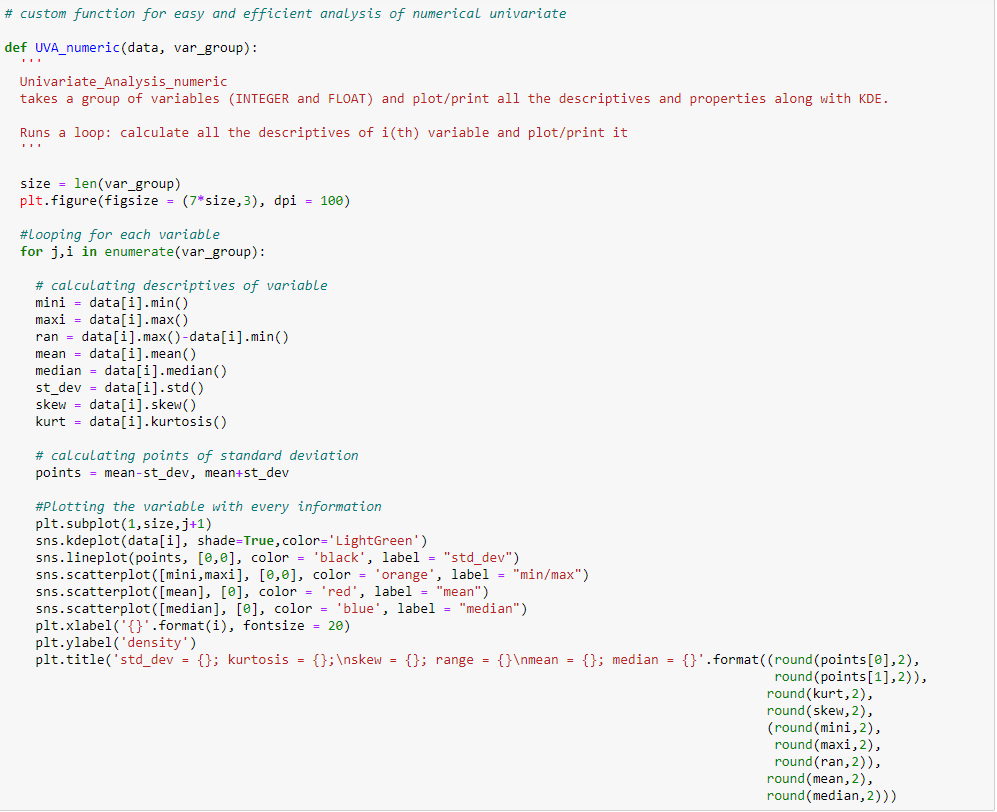
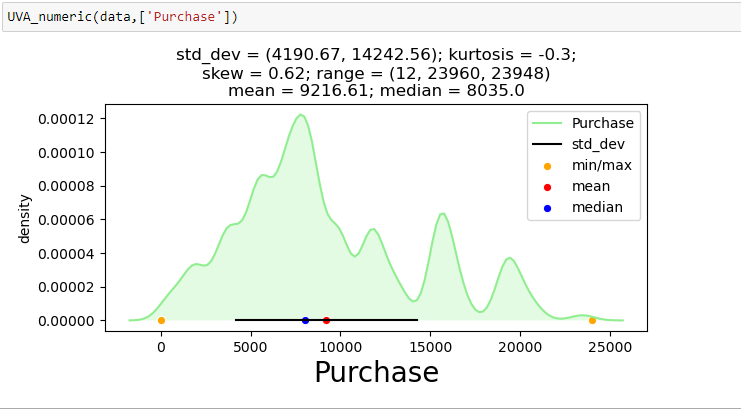
Per mostrare un'analisi univariata su una delle variabili continue dal set di dati di vendita del Black Friday: “Acquistare”, Ho creato una funzione che prende i dati come input e disegna un grafico KDE che spiega le caratteristiche della funzione.


Variabile categoriale
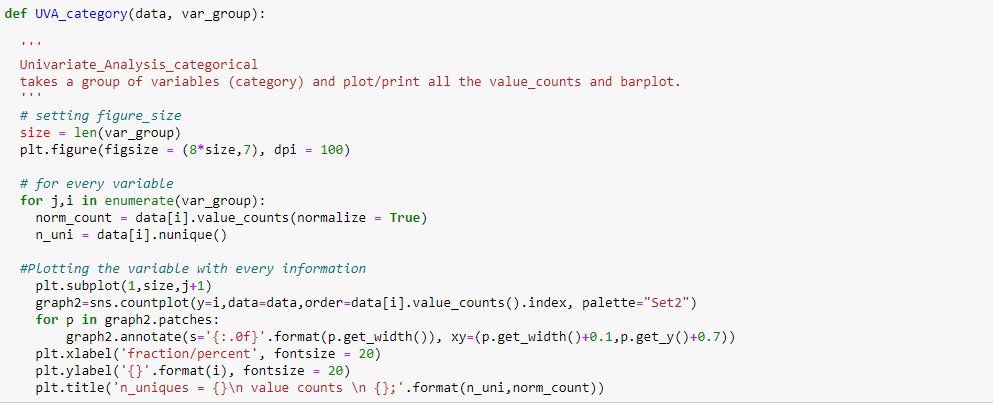
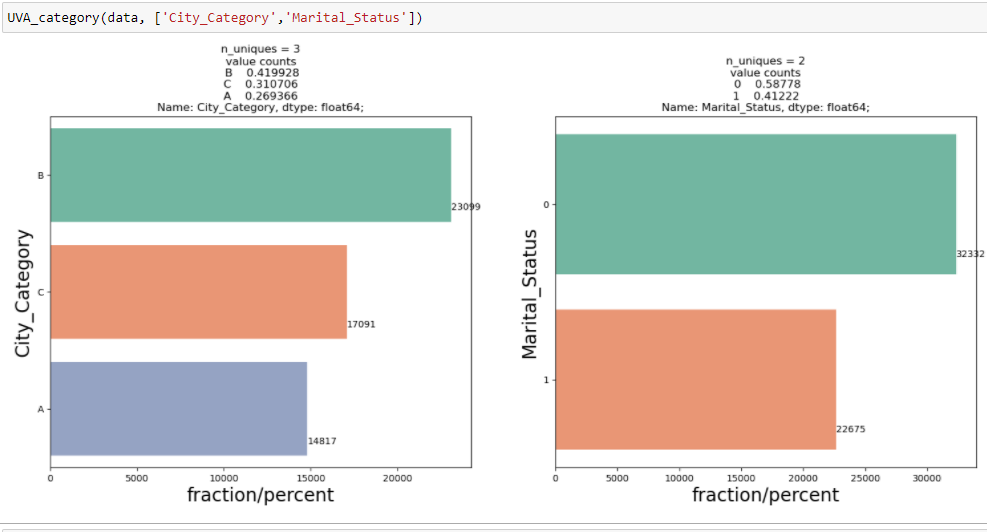
Per visualizzare l'analisi univariata sulle variabili categoriali nel set di dati di vendita del Black Friday: `City_Category` y` Stato_civile`, Ho creato una funzione che prende dati e caratteristiche come input che restituisce un grafico di conteggio che spiega la frequenza delle categorie nella caratteristica.


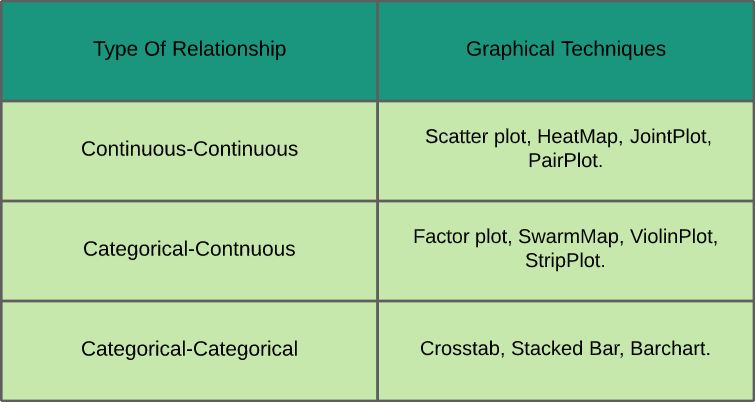
- Analisi bivariata: Nell'analisi bivariata, studiamo la relazione tra due variabili qualsiasi che possono essere categoriale-continue, categorico-categorico o continuo-continuo (come mostrato nel foglio di riferimento mostrato di seguito insieme alle tecniche grafiche utilizzate per analizzarli).

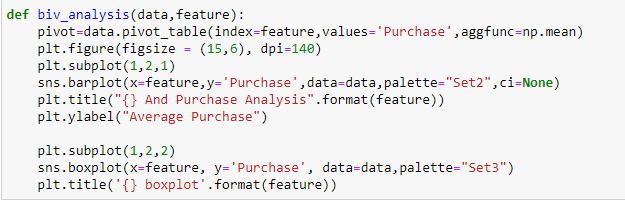
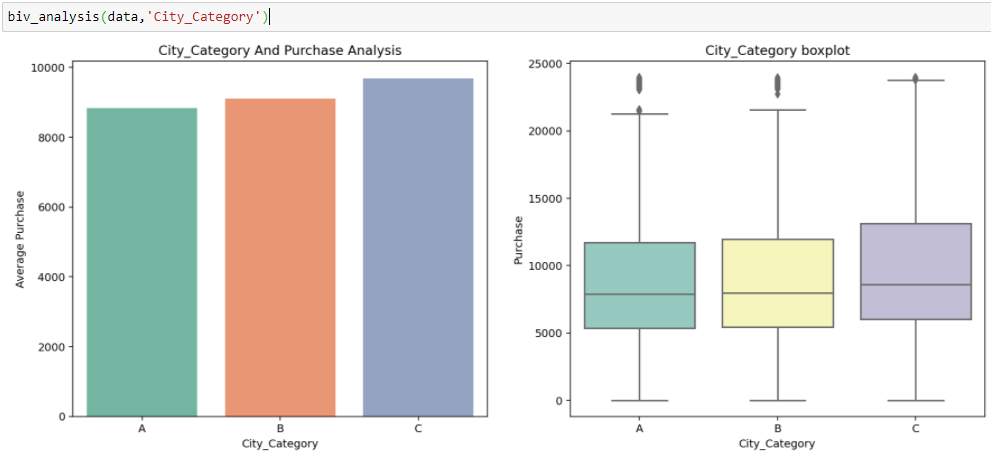
En Saldi del Black Friday, abbiamo variabili categoriche indipendenti e variabili target continue, così possiamo fare analisi categorico-continue per capire la relazione tra loro.

Inferenza:
Dalle due analisi precedenti, Abbiamo osservato nell'analisi univariata che un numero di clienti è massimo nella categoria di città B. Ma l'analisi bivariata eseguita tra `City_Category` e `Acquisto` mostra una storia diversa che l'acquisto medio è massimo della categoria di città C Pertanto, queste inferenze possono darci una migliore intuizione sui dati, che a sua volta aiuta una migliore preparazione dei dati e la progettazione delle funzionalità delle funzionalità.È importante notare che affidarsi semplicemente all'analisi univariata e bivariata può essere piuttosto fuorviante., quindi per verificare le inferenze tratte da questi due puoi convalidare con Verifica di ipotesi. Possiamo fare un t test, test del chi quadrato, Anova che ci permette di quantificare se due campioni sono significativamente simili o diversi tra loro. Qui ho creato una funzione per analizzare relazioni continue e categoriali che restituiscono il valore della statistica t.


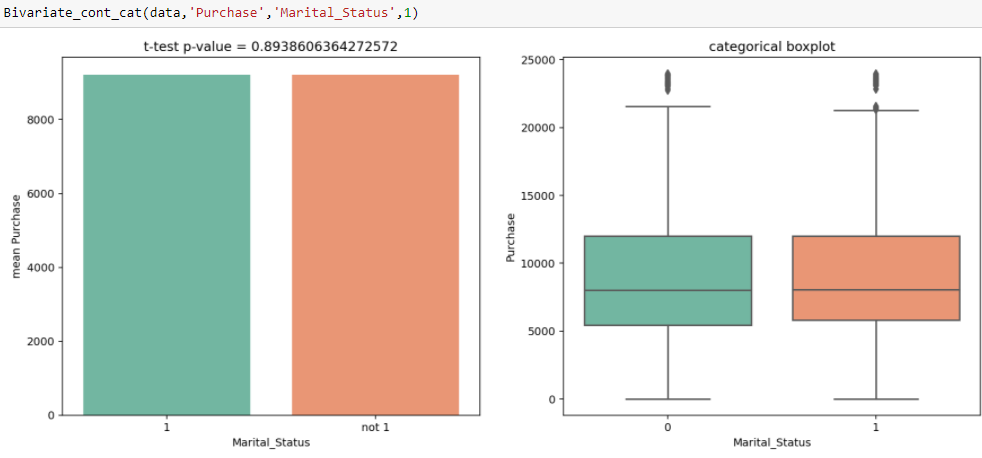
 Nell'analisi univariata osserviamo che c'è una differenza significativa tra il numero di clienti sposati e non sposati. Dal test t, otteniamo il valore della statistica t 0.89, che è maggiore del livello di significatività, vale a dire, 0.05, che mostra che non c'è differenza significativa tra l'acquisto medio da single e da sposato.
Nell'analisi univariata osserviamo che c'è una differenza significativa tra il numero di clienti sposati e non sposati. Dal test t, otteniamo il valore della statistica t 0.89, che è maggiore del livello di significatività, vale a dire, 0.05, che mostra che non c'è differenza significativa tra l'acquisto medio da single e da sposato. - Trattamento del valore perso : Il motivo principale di questo passaggio è scoprire se c'è un motivo specifico per cui mancano questi valori e come li trattiamo. Perché se non li trattiamo, può interferire con il modello che viene eseguito sui dati, che a sua volta può degradare le prestazioni del modello. Alcuni dei modi in cui i valori mancanti possono essere affrontati sono: – Riempili di media, mediano, modalità e può utilizzare gli imputer.
- Rimozione dei valori anomali : È essenziale comprendere la presenza di valori anomali, poiché alcuni dei modelli predittivi sono sensibili ad essi e dovremmo trattarli di conseguenza.

 Nell'analisi univariata osserviamo che c'è una differenza significativa tra il numero di clienti sposati e non sposati. Dal test t, otteniamo il valore della statistica t 0.89, che è maggiore del livello di significatività, vale a dire, 0.05, che mostra che non c'è differenza significativa tra l'acquisto medio da single e da sposato.
Nell'analisi univariata osserviamo che c'è una differenza significativa tra il numero di clienti sposati e non sposati. Dal test t, otteniamo il valore della statistica t 0.89, che è maggiore del livello di significatività, vale a dire, 0.05, che mostra che non c'è differenza significativa tra l'acquisto medio da single e da sposato.Note finali
In questo articolo, Ho discusso brevemente dell'importanza dell'EDA nella pipeline della scienza dei dati e dei passaggi necessari per un'analisi corretta. Ho anche mostrato come un'analisi errata o incompleta possa essere piuttosto fuorviante e possa influenzare significativamente le prestazioni dei modelli di machine learning..
“Se non bruni i tuoi dati, sei solo un'altra persona con un'opinione”;)





