obbiettivo
- El impulso es una técnica de aprendizaje conjunto en la que cada modelo intenta corregir los errores del modelo anterior.
- Aprenda sobre el algoritmo de aumento de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... y las matemáticas detrás de él.
introduzione
In questo articolo, vamos a discutir un algoritmo que funciona en la técnica de impulso, el algoritmo de aumento de gradiente. Es más conocido como Gradient Boosting Machine o GBM.
Nota: Se sei più interessato ad apprendere concetti in un formato audiovisivo, abbiamo questo articolo completo spiegato nel video qui sotto. Se non è così, puoi continuare a leggere.
Los modelos en Gradient Boosting Machine se están construyendo secuencialmente y cada uno de estos modelos posteriores intenta reducir el error del modelo anterior. Pero la pregunta es ¿cómo cada modelo reduce el error del modelo anterior? Se hace construyendo el nuevo modelo sobre errores o residuales de las predicciones anteriores.
Esto se hace para determinar si hay algún patrón en el error que el modelo anterior pasa por alto. Capiamolo con un esempio.
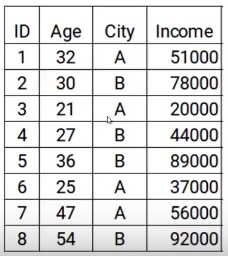
Aquí tenemos los datos con dos características: edad y ciudad, E la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... objetivo es el ingreso. Quindi, según la ciudad y la edad de la persona, tenemos que predecir los ingresos. Tenga en cuenta que a lo largo del proceso de aumento de gradiente, actualizaremos lo siguiente: el objetivo del modelo, el residuo del modelo y la predicción.
Pasos para construir el modelo de máquina de aumento de gradiente
Para simplificar la comprensión de la máquina de aumento de gradiente, hemos dividido el proceso en cinco pasos simples.
passo 1
El primer paso es construir un modelo y hacer predicciones sobre los datos dados. Volvamos a nuestros datos, para el primer modelo, el objetivo será el valor de Ingresos dado en los datos. Quindi, he establecido el objetivo como valores originales de Ingresos.
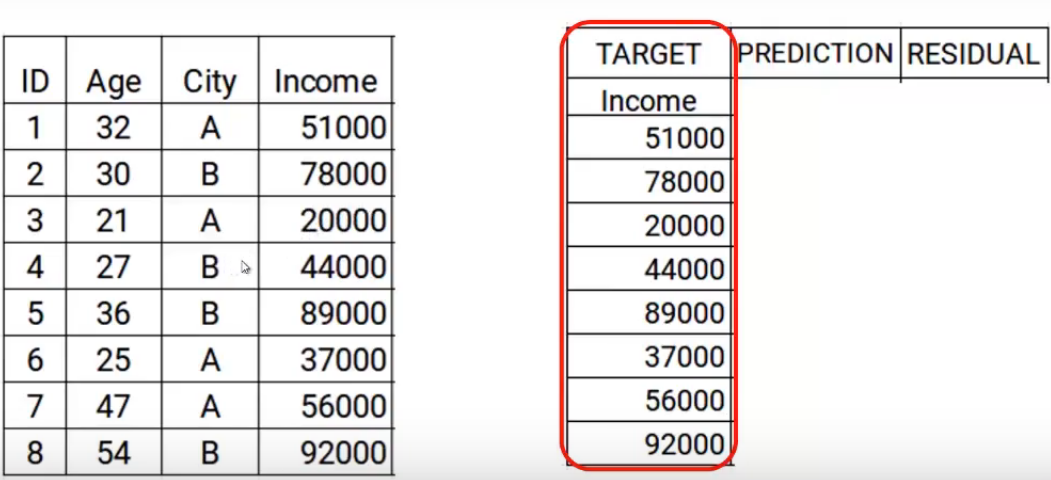
Ahora construiremos el modelo usando las características edad y ciudad con el ingreso objetivo. Este modelo entrenado podrá generar un conjunto de predicciones. Los cuales se suponen como sigue.
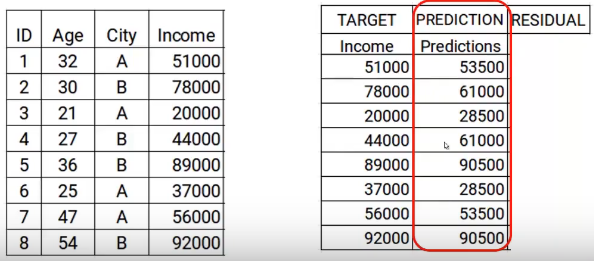
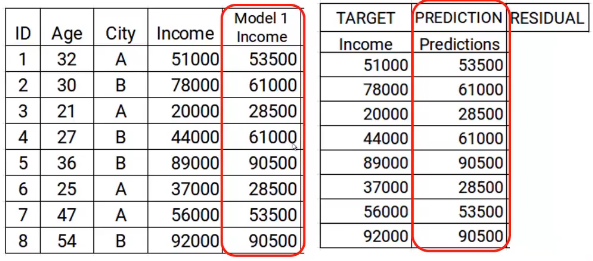
Ahora almacenaré estas predicciones con mis datos. Aquí es donde completo el primer paso.
passo 2
El siguiente paso es utilizar estas predicciones para obtener el error, que se utilizará más adelante como objetivo. Por el momento tenemos los valores de Ingresos reales y las predicciones del modelo1. Usando estas columnas, calcularemos el error simplemente restando los ingresos reales y las predicciones de ingresos. A se muestra a continuación.
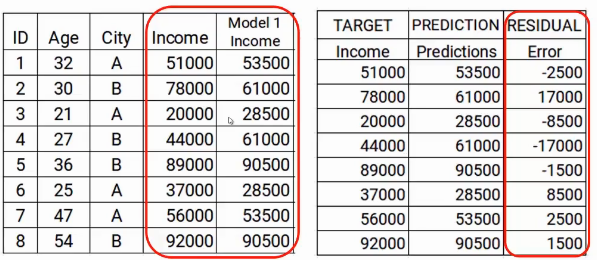
Como mencionamos anteriormente, los modelos sucesivos se centran en el error. Quindi, los errores aquí serán nuestro nuevo objetivo. Eso cubre el paso dos.
passo 3
Nel prossimo passo, crearemos un modelo sobre estos errores y realizaremos las predicciones. Aquí la idea es determinar si hay algún patrón oculto en el error.
Quindi, usando el error como objetivo y las características originales Edad y Ciudad, generaremos nuevas predicciones. Tenga en cuenta que las predicciones, in questo caso, serán los valores de error, no los valores de ingresos previstos, ya que nuestro objetivo es el error. Digamos que el modelo da las siguientes predicciones
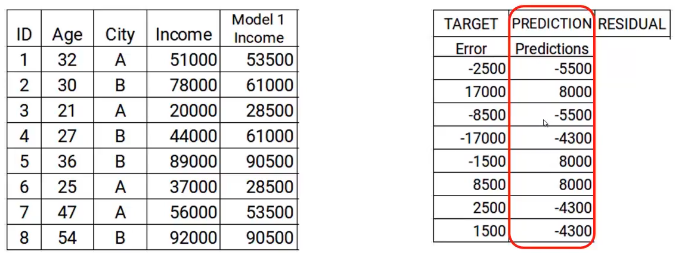
passo 4
Ahora tenemos que actualizar las predicciones de model1. Agregaremos la predicción del paso anterior y la agregaremos a la predicción de model1 y la llamaremos Model2 Income.
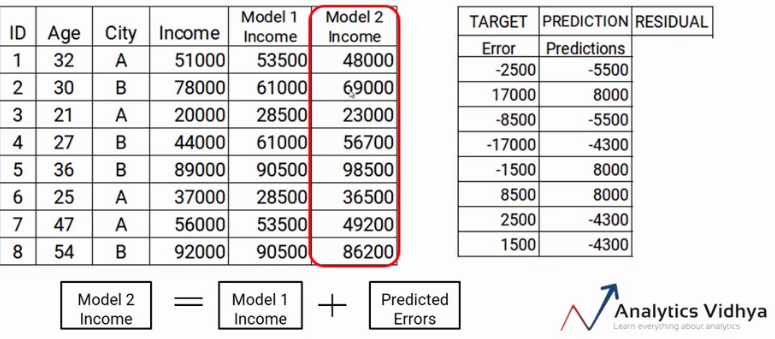
Come potete vedere, mis nuevas predicciones se acercan más a los valores reales de mis ingresos.
Finalmente, repetiremos los pasos 2 un 4, lo que significa que estaremos calculando nuevos errores y estableciendo este nuevo error como objetivo. Repetiremos este proceso hasta que el error sea cero o hayamos alcanzado el criterio de detención, que dice la cantidad de modelos que queremos construir. Ese es el proceso paso a paso de construir un modelo de aumento de gradiente.
In poche parole, construimos nuestro primer modelo que tiene características xy objetivo y, llamémosle a este modelo H0 que es una función de xey. Luego construimos el siguiente modelo sobre los errores del último modelo y un tercer modelo sobre los errores del modelo anterior y así sucesivamente. Hasta que construyamos n modelos.
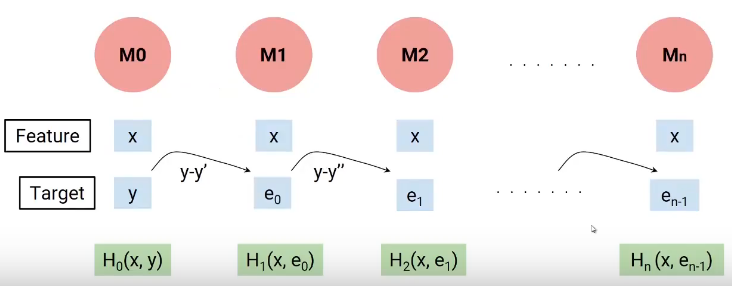
Cada modelo sucesivo trabaja sobre los errores de todos los modelos anteriores para intentar identificar cualquier patrón en el error. Efectivamente, puedo decir que cada uno de estos modelos son funciones individuales que tienen la variable independiente x como característica y el objetivo es el error del modelo combinado anterior.
Quindi, para determinar la ecuación final de nuestro modelo, construimos nuestro primer modelo H0, que me dio algunas predicciones y generó algunos errores. Llamemos a este resultado combinado F0 (X).
Ahora creamos nuestro segundo modelo y agregamos nuevos errores predichos a F0 (X), esta nueva función será F1 (X). Allo stesso modo, construiremos el siguiente modelo y así sucesivamente, hasta que tengamos n modelos como se muestra a continuación.
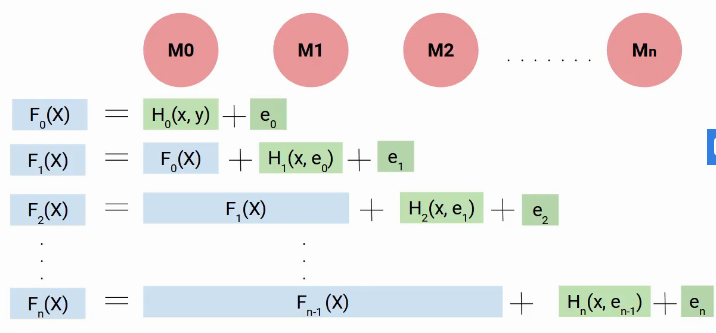
Quindi, in ogni passo, intentamos modelar los errores, lo que nos ayuda a reducir el error general. Idealmente, queremos que este ‘en’ sea cero. Come potete vedere, cada modelo aquí está tratando de aumentar el rendimiento del modelo, così, usamos el término impulso.
Pero por qué usamos el término gradiente, aquí está el truco. En lugar de agregar directamente estos modelos, los agregamos con peso o coeficiente, y el valor correcto de este coeficiente se decide utilizando la técnica de aumento de gradiente.
Perciò, una forma más generalizada de nuestra ecuación será la siguiente.
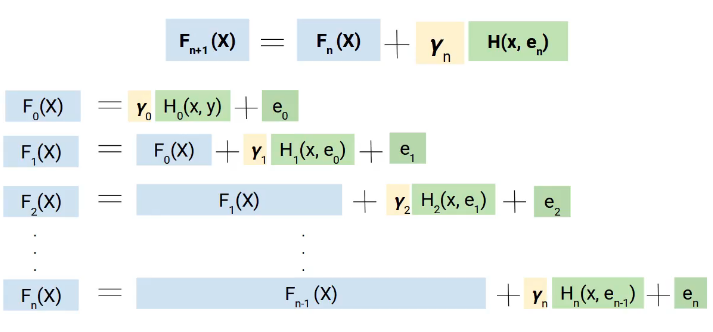
Las matemáticas detrás de Gradient Boosting Machine
Espero que ahora tengas una idea amplia de cómo funciona el aumento de gradiente. De aquí en adelante, nos centraremos en cómo se calcula el valor de Yn.
Usaremos la técnica de descenso de gradiente para obtener los valores de estos coeficientes gamma (E), de manera que minimicemos la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e.... Ahora profundicemos en esta ecuación y comprendamos el papel de la función de pérdida y gamma.
Qui, la función de pérdida que estamos usando es (y-y ‘) 2. y es el valor real e y ‘es el valor final predicho por el último modelo. Quindi, podemos reemplazar y ‘con Fn (X) que representa el objetivo real menos las predicciones actualizadas de todos los modelos que hemos construido hasta ahora.
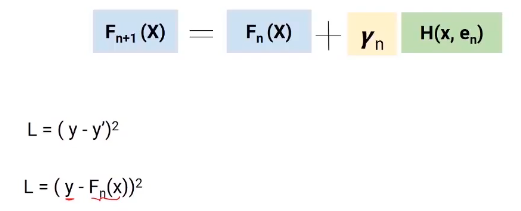
Diferenciación parcial
Creo que estará familiarizado con el proceso de descenso de gradientes, ya que vamos a utilizar el mismo concepto. Diferenciaremos la ecuación de L con respecto a Fn (X), obtendrás la siguiente ecuación, que también se conoce como pseudo residual. Cuál es el gradiente negativo de la función de pérdida.
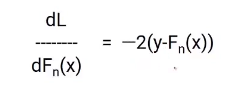
Para simplificar esto, multiplicaremos ambos lados por -1. El resultado será algo como esto.
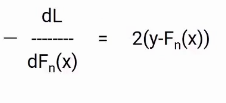
Ora, sabemos que el error en nuestra ecuación de Fn + 1 (X) es el valor real menos las predicciones actualizadas de todos los modelos. Perciò, podemos reemplazar el en en nuestra ecuación final con estos pseudo residuos como se muestra en la imagen a continuación.
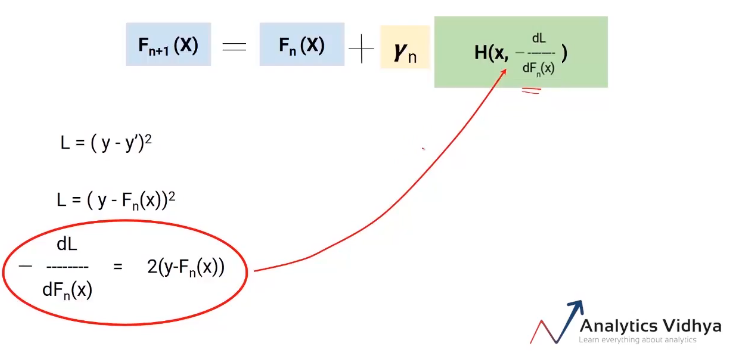
Entonces esta es nuestra ecuación final. La mejor parte de este algoritmo es que le da la libertad de decidir la función de pérdida. La única condición es que la función de pérdida sea diferenciable. Per facilitare la comprensione, usamos una función de pérdida muy simple (y-y ‘) 2 pero puede cambiarla a una pérdida de bisagra o una pérdida logit o cualquier cosa.
El objetivo es minimizar la pérdida total. Veamos cuál sería la pérdida total aquí, será la pérdida hasta el modelo n más la pérdida del modelo actual que estamos construyendo. Aquí está la ecuación.
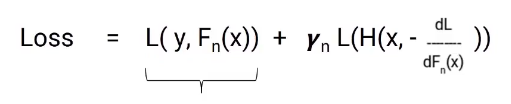
En esta ecuación, la primera parte es fija, pero la segunda parte es la pérdida del modelo en el que estamos trabajando actualmente. La pérdida de este modelo aún no se puede cambiar, pero podemos cambiar el valor de gamma. Ahora tenemos que seleccionar el valor de gamma de modo que la pérdida total se minimice y este valor se seleccione mediante el proceso de descenso de gradiente.
Quindi, la idea es reducir la pérdida general al decidir el valor óptimo de gamma para cada modelo que construimos.
Árbol de decisión de aumento de gradiente
Hablo de un caso especial de aumento de gradiente, vale a dire, árbol de decisión de aumento de gradiente (GBDT). Qui, cada modelo sería un árbol y el valor de gamma se decidirá en cada nivel de hoja, no en el nivel general del modelo. Quindi, come mostrato nell'immagine seguente, cada hoja tendría un valor gamma.
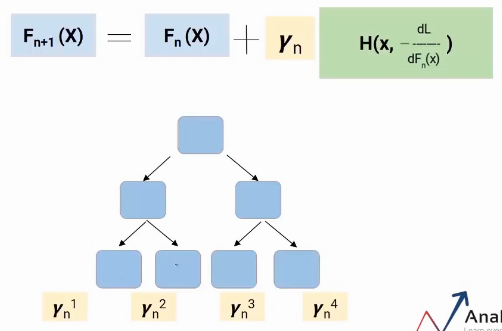
Así es como funciona Gradient Boosting Decision Tree.
Note finali
Impulsar es un tipo de aprendizaje conjunto. Es un proceso secuencial donde cada modelo intenta corregir los errores del modelo anterior. Esto significa que cada modelo sucesivo depende de sus predecesores. In questo articolo, vimos el algoritmo de aumento de gradiente y las matemáticas detrás de él.
Como tenemos una idea clara del algoritmo, intente construir los modelos y obtenga algo de experiencia práctica con él.
Se stai cercando di iniziare il tuo viaggio nella scienza dei dati e desideri tutti gli argomenti sotto lo stesso tetto, la tua ricerca si ferma qui. Dai un'occhiata alle certificazioni AI e ML BlackBelt di DataPeaker Più Programma
Se hai qualche domanda, fammi sapere nella sezione commenti!
Se hai qualche domanda, fammi sapere nei commenti qui sotto.





