Matrice di confusione: Non così confuso!
Ti sei mai trovato in una situazione in cui ti aspettavi che il tuo modello di machine learning funzionasse davvero bene?, ma ha restituito scarsa precisione? Hai fatto tutto il duro lavoro, poi, Dove è andato storto il modello di classificazione?? Come puoi correggere questo??
Ci sono molte alternative per misurare le prestazioni del tuo modello di classificazione, ma nessuno ha resistito alla prova del tempo come la matrice di confusione. Ci aiuta a esaminare come ha funzionato il nostro modello, dove è andato storto e ci offre una guida per correggere il nostro percorso.

In questo post, esploreremo come una matrice di confusione fornisce una visione olistica delle prestazioni del tuo modello. E a differenza del suo nome, noterai che una matrice di confusione è un concetto abbastanza semplice ma potente. Quindi sveliamo il mistero attorno alla matrice di confusione!!

Imparare le basi nel campo dell'apprendimento automatico? Questi corsi ti aiuteranno a seguire il tuo percorso:
Questo è ciò che tratteremo:
- Che cos'è una matrice di confusione?
- Vero positivo
- Vero negativo
- Falso positivo: errore di digitazione 1
- Falso negativo – Errore di digitazione 2
- Perché hai bisogno di una matrice di confusione??
- Precisione vs recupero
- Punteggio F1
- Matrice di confusione in Scikit-learn
- Matrice di confusione per la classificazione di più classi
Che cos'è una matrice di confusione?
La domanda da un milione di dollari: che cos'è, Dopotutto, una matrice di confusione?
Una matrice di confusione è una matrice N x N che viene utilizzata per esaminare le prestazioni di un modello di classificazione., dove N è il numero di classi target. La matrice confronta i valori target effettivi con quelli previsti dal modello di machine learning. Questo ci dà una visione olistica delle prestazioni del nostro modello di classificazione e del tipo di errori che sta commettendo..
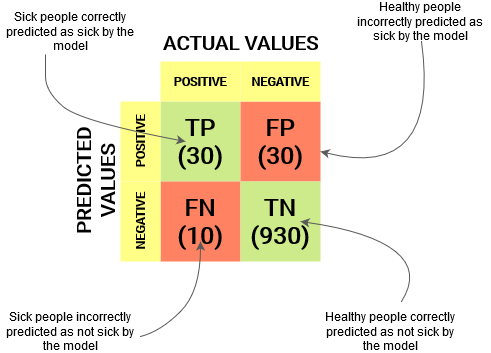
Per un ostacolo di classificazione binaria, avremmo una matrice di 2 X 2 come mostrato di seguito con 4 valori:
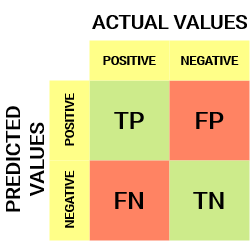
Decififichiamo la matrice:
- Il variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de destino tiene dos valores: Positivo oh Negativo
- il colonne rappresentare il valori attuali della variabile target
- il righe rappresentare il valori previsti della variabile target
Ma aspetta, Cos'è tp, FP, FN e TN qui? Questa è la parte cruciale di una matrice di confusione.. Comprendiamo ogni termine di seguito.
Comprendi il vero positivo, il vero negativo, il falso positivo e il falso negativo in una matrice di confusione
Vero positivo (TP)
- Il valore previsto corrisponde al valore effettivo
- Il valore vero era positivo e il modello prevedeva un valore positivo.
Vero negativo (TN)
- Il valore previsto corrisponde al valore effettivo
- Il valore effettivo era negativo e il modello prevedeva un valore negativo.
Falso positivo (FP): errore di digitazione 1
- Il valore previsto è stato erroneamente previsto
- Il valore effettivo era negativo ma il modello prevedeva un valore positivo
- Conosciuto anche come Errore di digitazione 1
Falso negativo (FN): errore di digitazione 2
- Il valore previsto è stato erroneamente previsto
- Il valore effettivo era positivo ma il modello prevedeva un valore negativo
- Conosciuto anche come Errore di digitazione 2
Ti faccio un esempio per conoscerlo meglio. Supponiamo di avere un set di dati di classificazione con 1000 punti dati. Mettiamo un classificatore su di esso e otteniamo la prossima matrice di confusione:
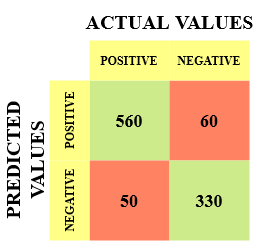
I diversi valori della matrice di confusione sarebbero i seguenti:
- Vero positivo (TP) = 560; che significa che 560 i punti dati di classe positivi sono stati classificati correttamente dal modello
- Vero negativo (TN) = 330; che significa che 330 i punti dati di classe negativi sono stati classificati correttamente dal modello
- Falso positivo (FP) = 60; il che significa che il modello è classificato in modo errato 60 punti dati di classe negativa come appartenenti alla classe positiva
- Falso negativo (FN) = 50; il che significa che il modello è classificato in modo errato 50 punti dati di classe positiva come appartenenti a classe negativa
Questo si è rivelato un classificatore abbastanza decente per il nostro set di dati considerando il numero relativamente maggiore di valori veri positivi e veri negativi..
Ricorda errori di digitazione 1 e tipo 2. Gli intervistatori amano chiedere la differenza tra questi due!! Puoi prepararti al meglio per tutto questo dal nostro Corso di apprendimento automatico online
Perché abbiamo bisogno di una matrice di confusione??
Prima di rispondere a questa domanda, Pensiamo ad un ipotetico ostacolo di classifica.
Supponiamo di voler prevedere quante persone sono infette da un virus contagioso prima che mostrino i sintomi e di isolarle dalla popolazione sana. (Qualcosa suona ancora?? ?). I due valori della nostra variabile target sarebbero: Malato e non malato.
Ora, devi chiederti: Perché abbiamo bisogno di una matrice di confusione quando abbiamo il nostro amico per tutte le stagioni?: precisione? Bene, vediamo dove la precisione fallisce.
Il nostro set di dati è un esempio di set di dati sbilanciato. Ci sono 947 punti dati per la classe negativa e 3 punti dati per la classe positiva. Ecco come calcoleremo la precisione: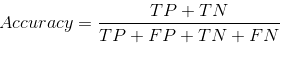
Vediamo come ha funzionato il nostro modello:
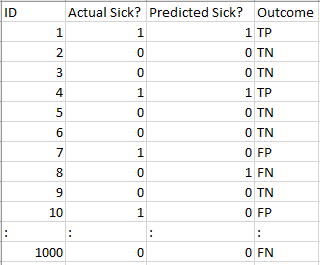
I valori totali del risultato sono:
TP = 30, TN = 930, FP = 30, FN = 10
Quindi, la precisione del nostro modello risulta essere:
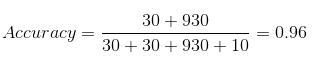
96%! Niente di male!
Ma stai dando un'idea sbagliata del risultato. Pensaci.
Il nostro modello dice “Posso prevedere le persone malate il 96% tempo metereologico”. Nonostante questo, sta facendo il contrario. Stai prevedendo persone che non si ammaleranno di a 96% precisione mentre i malati diffondono il virus!
Pensi che questa sia una metrica corretta per il nostro modello data la gravità del problema?? Non dovremmo misurare quanti casi positivi possiamo prevedere correttamente per fermare la diffusione del virus contagioso? O forse, di casi correttamente previsti, Quanti sono i casi positivi per verificare l'affidabilità del nostro modello?
È qui che incontriamo il duplice concetto di Precisione e Richiamo.
Precisione vs. recupero
L'accuratezza ci dice quanti dei casi correttamente previsti sono stati veramente positivi.
Prossimo, spiega come calcolare la precisione:
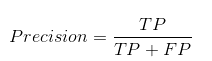
Questo determinerebbe se il nostro modello è affidabile o meno..
Il richiamo ci dice quanti dei casi positivi effettivi siamo stati in grado di prevedere correttamente con il nostro modello.
Ed è così che possiamo calcolare Recall:
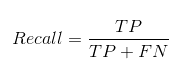
Possiamo facilmente calcolare Precisione e Richiamo per il nostro modello inserendo i valori nelle domande sopra:
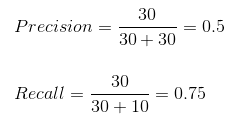
Il 50% dei casi correttamente previsti si sono rivelati casi positivi. Mentre il nostro modello ha previsto con successo il 75% dei lati positivi. Degno di nota!
L'accuratezza è una metrica utile nei casi in cui i falsi positivi sono una preoccupazione maggiore dei falsi negativi.
La precisione è essenziale nei sistemi di raccomandazione di musica o video, siti di e-commerce, eccetera. Risultati errati possono portare alla perdita di clienti ed essere dannoso per l'azienda.
Il recupero è una metrica utile nei casi in cui il falso negativo vince sul falso positivo.
Il richiamo è essenziale nei casi medici in cui non importa se diamo un falso allarme, Ma i veri casi positivi non dovrebbero passare inosservati!!
Nel nostro esempio, Il richiamo sarebbe una metrica migliore perché non vogliamo dimettere accidentalmente una persona infetta e lasciarla mescolare con la popolazione sana, diffondendo così il virus contagioso.. Ora puoi capire perché la precisione era una pessima metrica per il nostro modello.
Ma ci saranno casi in cui non c'è una chiara distinzione tra se la precisione è più importante o il recupero. Cosa dobbiamo fare in questi casi? Li combiniamo!
Punteggio F1
In pratica, quando cerchiamo di aumentare la precisione del nostro modello, il recupero diminuisce e viceversa. Il punteggio F1 cattura entrambe le tendenze in un unico valore:
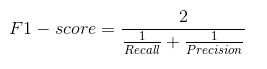
Il punteggio F1 è una media armonica di precisione e richiamo, quindi dà un'idea combinata di queste due metriche. È massimo quando Precisione è uguale a Richiamo.
Ma c'è un problema qui. L'interpretabilità del punteggio F1 è scarsa. Ciò significa che non sappiamo cosa stia massimizzando il nostro classificatore: Precisione o ricordo? Quindi, lo usiamo in combinazione con altre metriche di valutazione che ci danno un quadro completo del risultato.
Matrice di confusione usando scikit-learn in Python
Conosci già la teoria, ora mettiamolo in pratica. Codifichiamo una matrice di confusione con la libreria Scikit-learn (chiaro) e Python.

Sklearn ha due grandi funzioni: matrice di confusione() e classificazione_report ().
- Sklearn matrice di confusione() restituisce i valori della matrice di confusione. Nonostante questo, il risultato è leggermente diverso da quello che abbiamo studiato finora. Prendi le righe come valori effettivi e le colonne come valori previsti. Il resto del concetto rimane lo stesso.
- Sklearn classificazione_report () genera precisione, recupero e punteggio f1 per ogni classe di destinazione. Allo stesso tempo di questo, ha anche alcuni valori extra: micro media, macro media, e media ponderata
Mirco Media è la precisione / Recupero / punteggio f1 calcolato per tutte le classi.
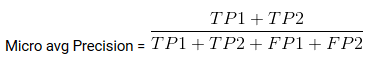
Media macro è la precisione media / Io ricordo / punteggio f1.
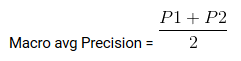
Peso medio è solo la media ponderata della precisione / Recupero / punteggio f1.
Matrice di confusione per la classificazione di più classi
Come funzionerebbe una matrice di confusione per un ostacolo alla classificazione di più classi?? Bene, Non grattarti la testa! Daremo un'occhiata a questo qui..
Disegniamo una matrice di confusione per un ostacolo multiclasse in cui dobbiamo prevedere se una persona ama Facebook, Instagram o Snapchat. La matrice di confusione sarebbe una matrice di 3 X 3 come va:
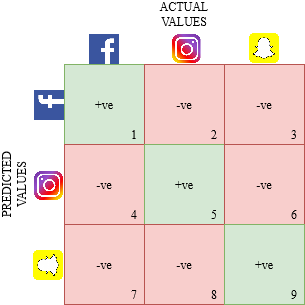
Il vero positivo, vero negativo, falsi positivi e falsi negativi di ciascuna classe verrebbero calcolati sommando i valori delle celle come segue:
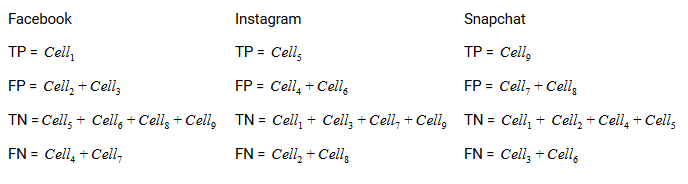
Questo è tutto! Sei pronto a decifrare qualsiasi matrice di confusione N x N!!
Note finali
E improvvisamente, la matrice di confusione non è più così confusa! Questo post dovrebbe fornirti una solida base su come interpretare e utilizzare una matrice di confusione per gli algoritmi di classificazione nell'apprendimento automatico..
Presto pubblicheremo un post sulla curva AUC-ROC e continueremo lì la nostra discussione. Fino alla prossima volta, non perdere la speranza nel tuo modello di classificazione, Potresti utilizzare la metrica di valutazione sbagliata!





