Potenzia l'algoritmo nell'apprendimento automatico
Impulso può essere chiamato un insieme di algoritmi la cui funzione principale è trasformare studenti deboli in studenti forti. Sono diventati mainstream Industria della scienza dei dati perché sono stati nel comunità di apprendimento automatico durante gli anni. L'impulso è stato inserito per la prima volta da Freund e Schapire nell'anno 1997 con il suo Algoritmo AdaBoost, e da allora, l'impulso è stata una tecnica predominante per risolvere problemi di classificazione binaria.
Perché gli algoritmi di impulso sono così popolari??
Per sapere questo, in parole più semplici. potenziare gli algoritmi può superare algoritmi più semplici come foresta casuale, alberi decisionali o regressione logistica. È uno dei motivi principali per l'aumento della promozione degli algoritmi da parte di molti concorrenti di machine learning a causa del fatto che gli algoritmi di impulso sono potenti.. Comunque, può migliorare accuratezza della previsione del tuo modello da un numero considerevole di fattori. Molti concorrenti di machine learning utilizzano un singolo algoritmo boost o più algoritmi boost per risolvere i rispettivi problemi..
Spiegazione dell'algoritmo degli impulsi
Impulso combinare studenti deboli per formare uno studente forte, dove un studente debole imposta un classificatore leggermente correlato con la classificazione effettiva. A differenza di uno studente debole, uno studente forte è un classificatore associato alle categorie corrette.
Per sapere questo, prendiamo uno scenario:
Supponiamo di costruire un Modello di foresta casuale che ti dà una precisione di 75% nel set di dati di convalida e, prossimo, decidere di testare qualche altro modello sullo stesso set di dati. Supponi di provare lineare modello di regressione e kNN sullo stesso set di dati di convalida, e ora il tuo modello ti dà una precisione di 69% e 92%, rispettivamente. È chiaro che i tre modelli funzionano in modi assolutamente diversi e forniscono risultati assolutamente diversi sullo stesso set di dati..
Hai mai pensato, invece di usare solo uno di questi modelli, e se usiamo una combinazione di tutti questi modelli per fare le previsioni finali??
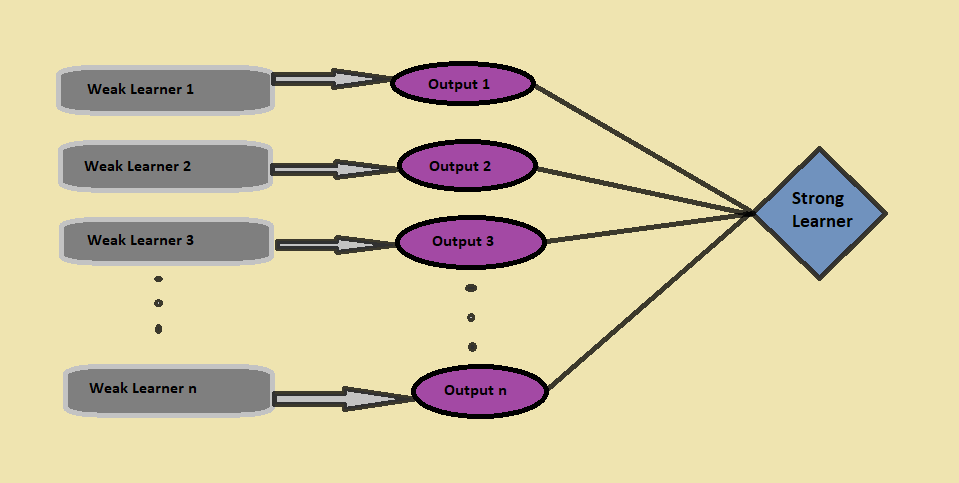
Acquisiremo più informazioni dai dati prendendo la media delle previsioni da questi modelli.; Equivalentemente, l'algoritmo boost combina diversi modelli più semplici (chiamati anche studenti deboli) per generare il risultato finale (chiamato anche studente forte).
Ora penseresti a come identificare gli studenti deboli??
Per identificare gli studenti deboli, noi usiamo algoritmi di apprendimento automatico con una distribuzione diversa per ogni iterazione e per ogni algoritmo, genera una nuova regola di previsione debole. Dopo molte iterazioni, l'algoritmo boost combina tutti gli studenti vulnerabili per formare un'unica regola di previsione a catena.
Un'altra cosa essenziale a cui prestare attenzione qui è, 'Come determiniamo una distribuzione diversa per ogni round??’
Ci sono tre passaggi che dobbiamo considerare per selezionare la distribuzione corretta:
- Lo studente debole considera tutte le distribuzioni e poi assegna uguale peso a ciascuna osservazione, dopo
- Se l'errore è generato dalla previsione del primo algoritmo di apprendimento debole, viene prestata maggiore attenzione all'errore di previsione delle osservazioni. Si applica il seguente algoritmo di apprendimento debole.
- Finalmente, ripetere il secondo passaggio fino a quando l'algoritmo di apprendimento di base raggiunge il limite o si ottiene la precisione desiderata.
Finalmente, dovuto, l'algoritmo boost combina tutti i risultati deboli degli studenti. Presenta con uno studente più forte e più potente, che alla fine migliora l'accuratezza della previsione del modello (como se ve en la figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... anteriore).
Aumentando, invece di combinare solo i classificatori isolati, utilizza il meccanismo di aumentare i pesi dei punti dati classificati erroneamente nei classificatori di cui sopra.
Tipi di algoritmi di impulsoS
È ora di discutere alcuni dei tipi essenziali di algoritmi di momentum.
1. Aumento de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in...
In aumento del gradiente algoritmo, addestriamo più modelli in sequenza, e per ogni nuovo modello, el modelo minimiza gradualmente la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... usando el método Gradient Descent. il Algoritmo di aumento dell'albero del gradiente accetti alberi decisionali come il debole magro perché i nodi in un albero decisionale considerano un diverso ramo di caratteristiche per scegliere la migliore divisione, il che significa che non tutti gli alberi sono uguali. Perché, può catturare diversi output di dati in ogni momento.
L'algoritmo di aumento dell'albero del gradiente è costruito in sequenza perché, per ogni nuovo albero, il modello considera gli errori dell'ultimo albero, e la decisione di ogni albero successivo si basa sugli errori commessi dall'albero precedente.
Gli algoritmi Gradient Boosting sono utilizzati principalmente per problemi di classificazione e regressione.
Codice Python:
da sklearn.ensemble importare GradientBoostingClassifier #Per la classificazione
da sklearn.ensemble import GradientBoostingRegressor #Per la regressione
cl = GradientBoostingClassifier (n_estimatori = 100, tasso_di_apprendimento = 1.0, profondità_max = 1)
cl.fit (Xtrain, ytrain)
dove:
n_estimatori Il parametro viene utilizzato per controllare il numero di studenti deboli,
tasso di apprendimento Il parametro controlla il contributo di tutti gli studenti vulnerabili al risultato finale,
Profondità massima Il parametro è per la profondità massima dei singoli stimatori di regressione per limitare il numero di nodi nell'albero.
2. AdaBoost (rinforzo adattivo)
L'algoritmo AdaBoost, Corto per Azionamento adattivo, è una tecnica di spinta nell'apprendimento automatico che viene utilizzata come Imposta metodo. Sopra Azionamento adattivo, tutti i pesi vengono riassegnati a ciascuna istanza in cui vengono assegnati pesi maggiori a modelli classificati in modo errato, e si adatta alla sequenza di studenti deboli con pesi diversi.
ADABOOST inizia con fare previsioni sul set di dati originale in un linguaggio semplice, e poi dare lo stesso peso ad ogni osservazione. Se la previsione fatta con il primo studente non è corretta, assegna il maggiore rilevanza per l'istruzione prevista in modo errato e la procedura iterativa. Continua ad aggiungere nuovi studenti fino a quando non viene raggiunto il limite nel modello.
Podemos utilizar cualquier algoritmo de aprendizaje automático con Adaboost como estudiantes débiles si acepta pesos en el conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y se utiliza tanto para problemas de regresión como de clasificación.
Codice Python:
da sklearn.ensemble import AdaBoostClassifier #Per la classificazione
da sklearn.ensemble import AdaBoostRegressor #For Regression
da sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier ()
cl = Classificatore AdaBoost (n_estimatori = 100, base_estimator = dtree, tasso_di_apprendimento = 1)
cl.fit (xtrain, ytrain)
dove:
n_estimatori e il parametro learning_rate ha lo stesso scopo del caso dell'algoritmo Gradient Boosting,
base_estimator Il parametro aiuta a specificare diversi algoritmi di apprendimento automatico.
3. XGBoost
L'algoritmo XGBoost, abbreviazione di Extreme Gradient Boosting, È semplicemente una versione estemporanea del algoritmo di aumento del gradiente, e la procedura di lavoro di entrambi è quasi la stessa. Un punto cruciale in XGBoost è questo Implementa procesamiento paralelo a nivel de nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi...., rendendolo più potente e più veloce dell'algoritmo di aumento del gradiente.. XGBoost riduce il sovradattamento e migliora le prestazioni complessive a través de la inclusión de varias técnicas de regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni.... a través de el establecimiento de los hiperparámetros del algoritmo XGBoost.
Un punto importante a cui prestare attenzione XGBoost è questo non devi preoccuparti dei valori mancanti nel set di dati perché, durante tutta la procedura di formazione, il modello stesso impara dove inserire i valori mancanti, In altre parole, il nodo sinistro o il nodo destro.
XGBoost è utilizzato principalmente per problemi di ordinamento, ma può essere usato per problemi di regressione.
Codice Python:
importa xgboost come xgb
xgb_model = xgb.XGBClassifier (tasso_di_apprendimento = 0,001, max_profondità = 1, n_estimators_100)
xbg_model.fit (x_treno, y_train)
NOTE FINALI
Questo post ha esaminato gli algoritmi di impulso nell'apprendimento automatico, spiegato cosa sono gli algoritmi di impulso e i tipi di algoritmi di impulso: ADABOOST, Aumento del gradiente y XGBoost. Además miramos sus respectivos códigos y parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de Python involucrados.
Se hai dei dubbi, puoi raggiungermi sul mio LinkedIn @Mrinalwalia.
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





