introduzione
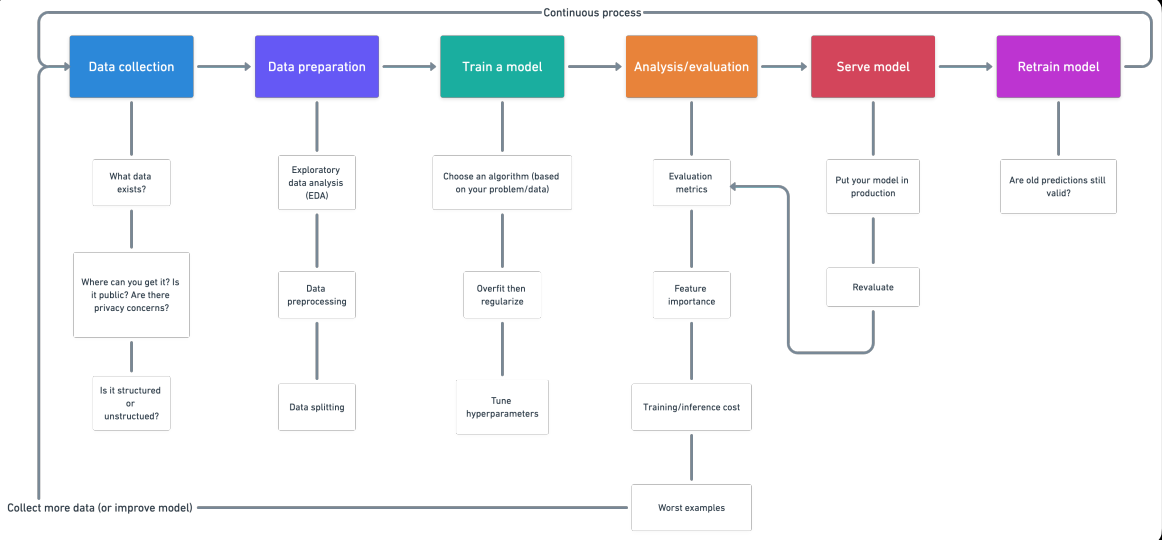
1. Raccolta dati
- Che tipo di problema stiamo cercando di risolvere??
- Quali origini dati esistono già?
- Quali problemi di privacy esistono?
- I dati sono pubblici??
- Dove dobbiamo archiviare i file??
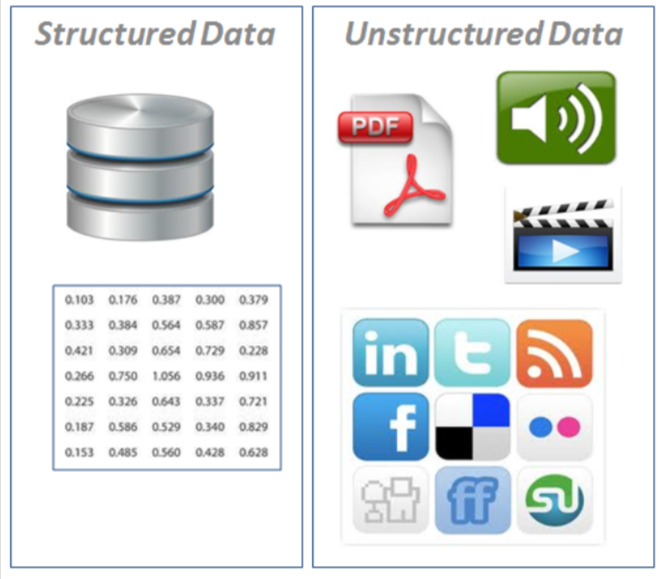
- Dati strutturati: vengono visualizzati in formato tabellare (Stile di righe e colonne, come quello che troveresti in un foglio di calcolo Excel). Contiene diversi tipi di dati, ad esempio, Serie temporali numeriche, Categorico.
- · Nominale / categorico – Una cosa o l'altra (Escludono). Ad esempio, per bilance automobilistiche, Il colore è una categoria. Un'auto può essere blu ma non bianca. Non importa un ordine.
- Numerico: Qualsiasi valore continuo in cui la differenza tra loro è importante. Ad esempio, Quando si vendono case, $ 107,850 è più che $ 56,400.
- Ordinale: Dati che hanno ordine ma la distanza tra i valori è sconosciuta. Ad esempio, Una domanda come, Come valuteresti la tua salute dal 1 al 5? 1 essere poveri, 5 sano. Puoi rispondere 1, 2, 3, 4, 5, Ma la distanza tra ogni valore non significa necessariamente che una risposta di 5 è cinque volte meglio di un 1. serie temporaliUna serie temporale è un insieme di dati raccolti o misurati in tempi successivi, di solito a intervalli di tempo regolari. Questo tipo di analisi consente di identificare i modelli, Tendenze e cicli dei dati nel tempo. La sua applicazione è ampia, che coprono settori come l'economia, Meteorologia e sanità pubblica, facilitare la previsione e il processo decisionale basato su informazioni storiche....: Dati nel tempo. Ad esempio, I valori storici di vendita delle ruspe 2012 un 2018.
- serie temporali: Dati nel tempo. Ad esempio, I valori storici di vendita delle ruspe 2012 un 2018.
- Dati non strutturati: Dati senza struttura rigida (immagini, video, voce, Forse sarebbe un'analogia migliore
Testo in lingua)
2. Preparazione dei dati
- Analisi esplorativa dei dati (EDA), Scopri di più sui dati con cui stai lavorando
- Quali sono le variabili caratteristiche? (iscrizione) E la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de destino (Uscita)? Ad esempio, per predire le malattie cardiache, Le variabili caratteristiche possono essere l'età, Peso, La frequenza cardiaca media e il livello di attività fisica di una persona. E la variabile bersaglio sarà se hanno o meno una malattia.
- Che tipo di hai? Serie temporali strutturate, Destrutturati, Numerico. C'è una mancanza di valori?? Nel caso in cui li elimini o li completi, La funzione di assegnazione dell'account.
- Dove sono i valori anomali?? Quanti ce ne sono?? Perché sono lì?? Ci sono domande che posso porre a un esperto di dominio in merito ai dati?? Ad esempio, Un medico cardiologo potrebbe far luce sul tuo set di dati sulle malattie cardiache??
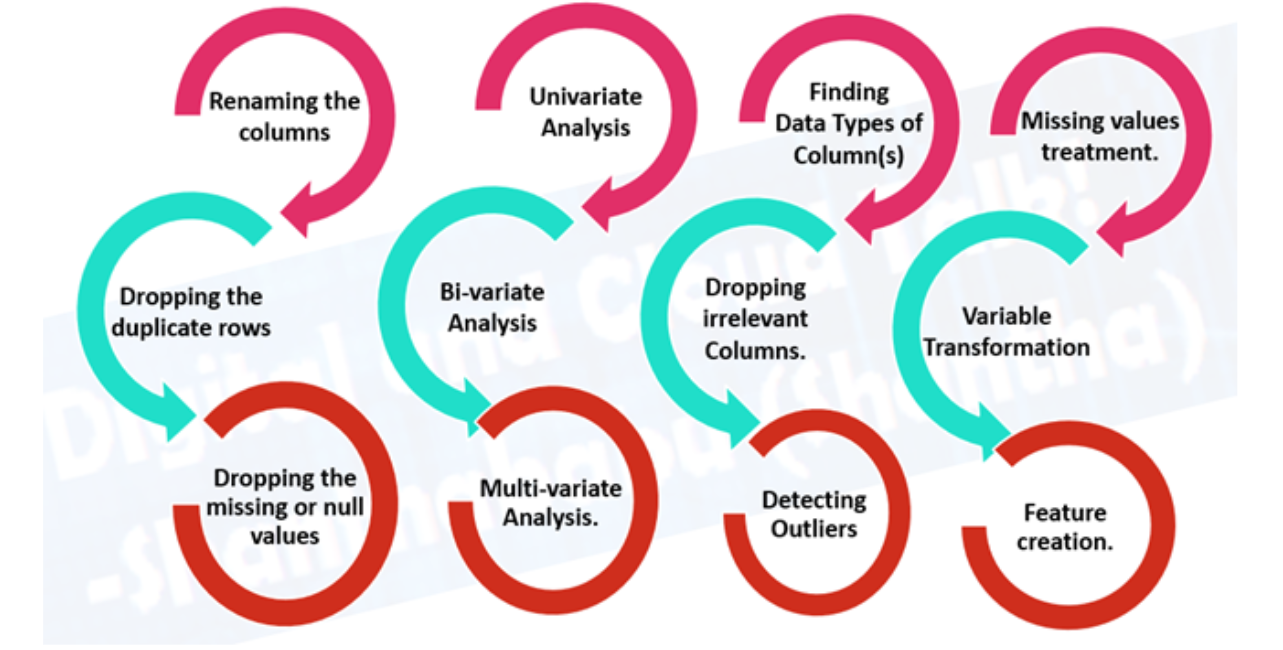
- Pretrattamento dei dati, Preparazione dei dati per la modellazione.
- Funzione di assegnazione dell'account: Inserire i valori mancanti (Un modello di Machine Learning non è in grado di apprendere
in dati che non ci sono)
- Assegnazione di un singolo account: Riempire con la calza, una mediana della colonna vertebrale.
- Assegnazioni di account multipli: Modellare altri valori mancanti e ciò che il modello trova.
- KNN (K Vicini più prossimi): Popolare i dati con un valore di un altro esempio simile.
- Molti altri, come l'imputazione casuale, L'ultima osservazione fatta (per le serie temporali), La finestra mobile e la più frequente.
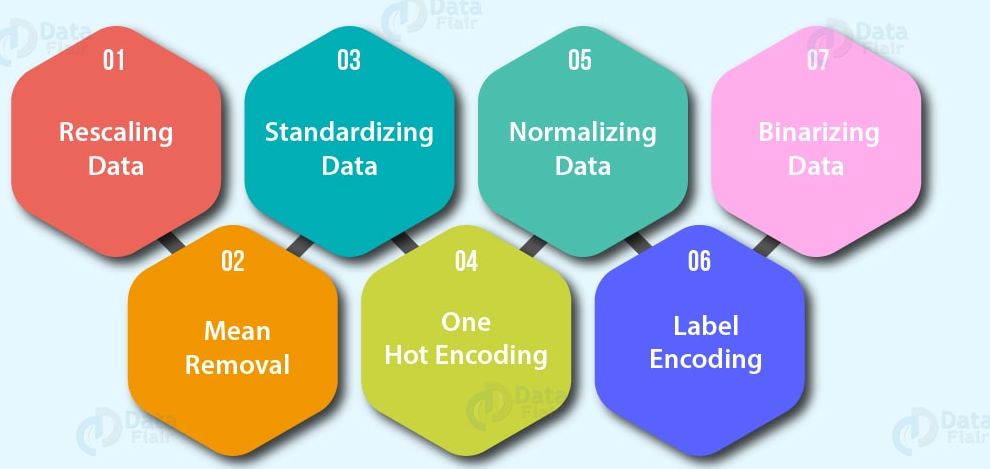
- Codifica delle funzioni (Converti valori in numeri). Un modello di Machine Learning
richiede che tutti i valori siano numerici)
- Una codifica a caldo: Converti tutti i valori univoci in elenchi di zeri e uno in cui il valore di destinazione è 1 E il resto sono zeri. Ad esempio, Quando un'auto si colora di verde, rosso, blu, verde, Il futuro del colore dell'auto sarebbe raffigurato come [1, 0, e 0] E uno rosso serio [0, 1, e 0].
- Codificatore di etichette: Convertire le etichette in valori numerici distinti. Ad esempio, Se le variabili target sono animali diversi, Come un cane, gatto, uccello, Questi potrebbero diventare 0, 1 e 2, rispettivamente.
- Incorporare la codifica: Impara una rappresentazione tra tutti i diversi punti dati. Ad esempio, Un modello linguistico è una rappresentazione di come parole diverse si relazionano tra loro. L'embedding sta diventando sempre più disponibile anche per i dati strutturati (Tabulare).
- NormalizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... de funciones (ridimensionato) o Standardizzazione: Quando le variabili numeriche sono su scale diverse (ad esempio, número_de_bathroom è tra 1 e 5 e la tamaño_of_land tra 500 e 20000 piedi quadrati), Alcuni algoritmi di apprendimento automatico non funzionano molto bene. La scalabilità e la standardizzazione aiutano a risolvere questo problema.
- Ingegneria delle funzioni: Trasformare i dati in una rappresentazione (potenzialmente) Più significativo aggiungendo la conoscenza del dominio
- Scomporre
- Discretizzazione: Convertire gruppi di grandi dimensioni in gruppi più piccoli
- Funzioni di crossover e interazione: Combinazione di due o più funzioni
- Le caratteristiche dell'indicatore: Utilizzo di altre parti dei dati per indicare qualcosa di potenzialmente significativo
- Selezione delle funzioni: Selezione
Le funzionalità più preziose del set di dati per la modellazione. Potencialmente reduciendo el tiempo de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y sobreajuste (Meno sovraccarico di dati e meno dati ridondanti da addestrare) e migliorare la precisione.
- Riduzione della dimensionalità: Un metodo comune per la riduzione della dimensionalità, La PCA o Principal Component Analysis richiede molte dimensioni (caratteristiche) e utilizza l'algebra lineare per ridurli a meno dimensioni. Ad esempio, Supponiamo di avere 10 Funzioni numeriche, potrebbe eseguire PCA per ridurlo a 3.
- Importanza della funzione (Modellazione successiva): Adattare un modello a un set di dati, Quindi ispezionare quali caratteristiche sono state più importanti per i risultati, Elimina quelli meno importanti.
- Metodi di confezionamento In che modo gli algoritmi genetici e la rimozione ricorsiva delle funzionalità comportano la creazione di grandi sottoinsiemi di opzioni di funzionalità e quindi la rimozione di quelle che non contano.
- Affrontare gli squilibri: I tuoi dati hanno 10,000 Esempi di una classe, ma solo 100 Esempi di altri?
- Raccogli più dati (Se potete,)
- Usa il pacchetto sbilanciato scikit-learn-contrib- imparare
- Utilizzo di SMOTE: Tecnica di sovracampionamento delle minoranze sintetiche. Crea esempi sintetici della tua classe secondaria per cercare di livellare il campo di gioco.
- Un articolo utile da consultare è “Imparare dai dati sbilanciati”.
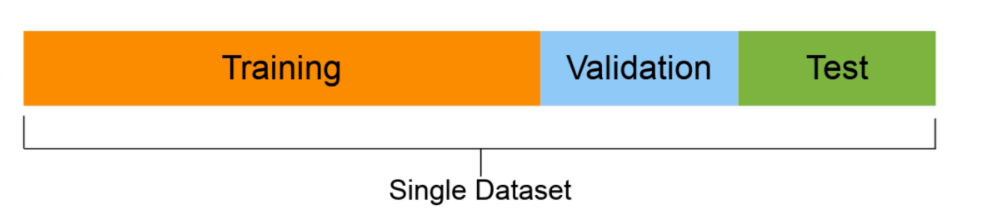
- Set di formazione (in genere 70-80% dei dati): Il modello viene a conoscenza di questo.
- Set di convalida (Di solito da 10 al 15% dei dati): Gli iperparametri del modello sono conformi a questo
- Test Set (Normalmente tra il 10% e il 15% dei dati): Su questa base vengono valutate le prestazioni finali dei modelli. Se l'hai fatto bene, Si spera che i risultati del set di test forniscano una buona indicazione di come il modello dovrebbe comportarsi nel mondo reale. Non utilizzare questo set di dati per adattarlo al modello.
3. Eseguire il training del modello sui dati (3 Passi: Scegliere un algoritmo, Regolare il modello, reduzca el ajuste con regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni....)
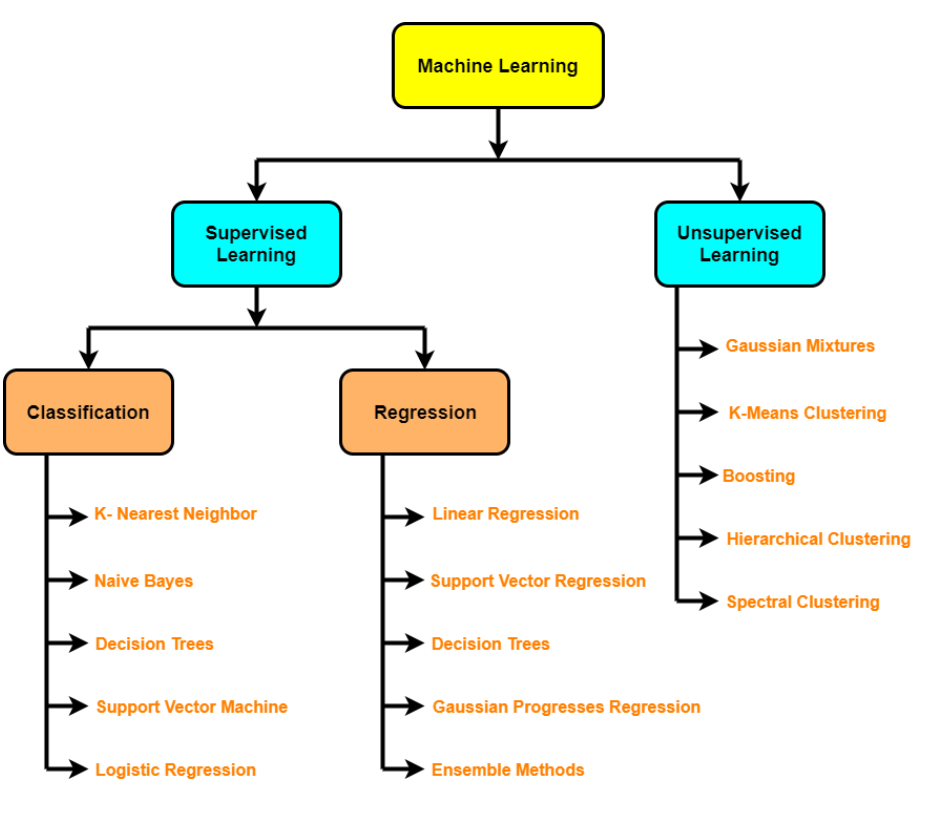
- Algoritmi supervisionati: regressione lineare, Regressione logistica, KNN, SVM, Albero decisionale e foreste casuali, AdaBoost / Macchina per l'aumento del gradiente (impulso)
- Algoritmi non supervisionati: raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.., riduzione dimensionale (PCA, Encoder automatici, t-SNE), rilevamento anomalie
- Apprendimento in batch
- Impara online
- Trasferire l'apprendimento
- Apprendimento attivo
- Assemblea
- Mancata corrispondenza – Succede quando il modello non funziona come si vorrebbe sui dati. Provare a eseguire il training per un modello più lungo o più avanzato.
- Sovra-regolazione– Si verifica quando la perdita di convalida inizia ad aumentare o quando le prestazioni del modello sono migliori nel set di training rispetto al set di test.
- regolarizzazione: Una raccolta di tecnologie per la prevenzione / Riduci l'overfitting (ad esempio, L1, L2 ·, Abbandono, Arresto anticipato, aumento dei dati, Normalizzazione batch)
- Ottimizzazione degli iperparametri – Esegui una serie di esperimenti con diverse impostazioni e vedi quale funziona meglio
4. Analisi / Valutazione
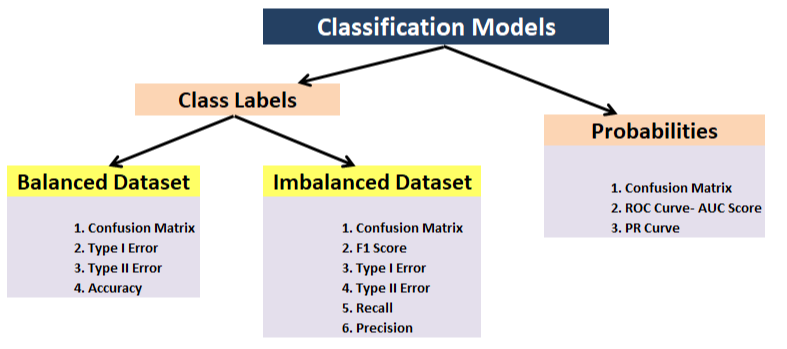
- Classificazione: precisione, precisione, Recupero, F1, matrice di confusione, Precisione media (rilevamento di oggetti)
- Regressione – MSE, Amico, R^ 2
- Metrica basata sulle attività: ad esempio, per l'auto a guida autonoma, Potresti voler conoscere il numero di disconnessioni
- Importanza della funzione
- Addestramento / Tempo di inferenza / costo
- E se l'opzione: Come si confronta il mio modello con altri modelli?
- Esempi meno sicuri: Dove sbaglia il modello??
- Compensazione del bias / varianza
5. Modello di servizio (Implementazione di un modello)
- Impostare il modello su produzione E vedere come va.
- Strumenti Cosa puoi usare: TensorFlow Servinf, PyTorch Serving, Piattaforma AI di Google, Creatore di saggi
- MLOps: Dove l'ingegneria del software incontra l'apprendimento automatico, Essenzialmente tutta la tecnologia necessaria intorno a un modello di machine learning per farlo funzionare in produzione

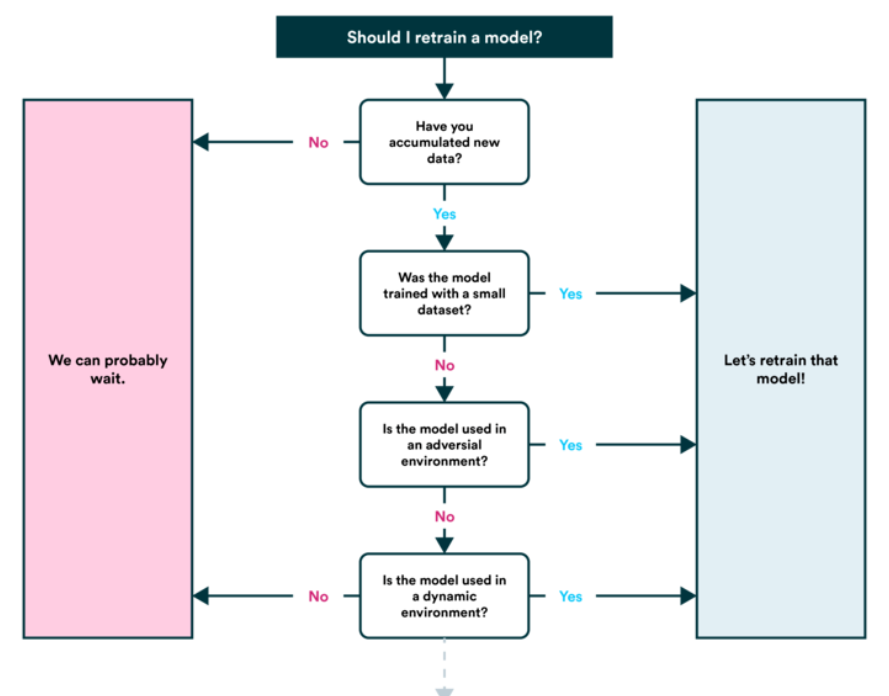
6. Ripetere il training del modello
- Scopri come funziona il modello dopo la pubblicazione (o prima della pubblicazione) in base a varie metriche di valutazione e fare riferimento ai passaggi precedenti, se necessario (ricordare, L'apprendimento automatico è molto sperimentale, Quindi è qui che vorrai tenere traccia dei tuoi dati ed esperimenti.
- Scoprirai anche che le previsioni del tuo modello stanno iniziando a "invecchiare"’ (Generalmente non in uno stile elegante) o 'derivare', ad esempio quando le origini dati cambiano o vengono aggiornate (Nuovo hardware, eccetera.). Questo è il momento in cui vorrai riaddestrarlo.
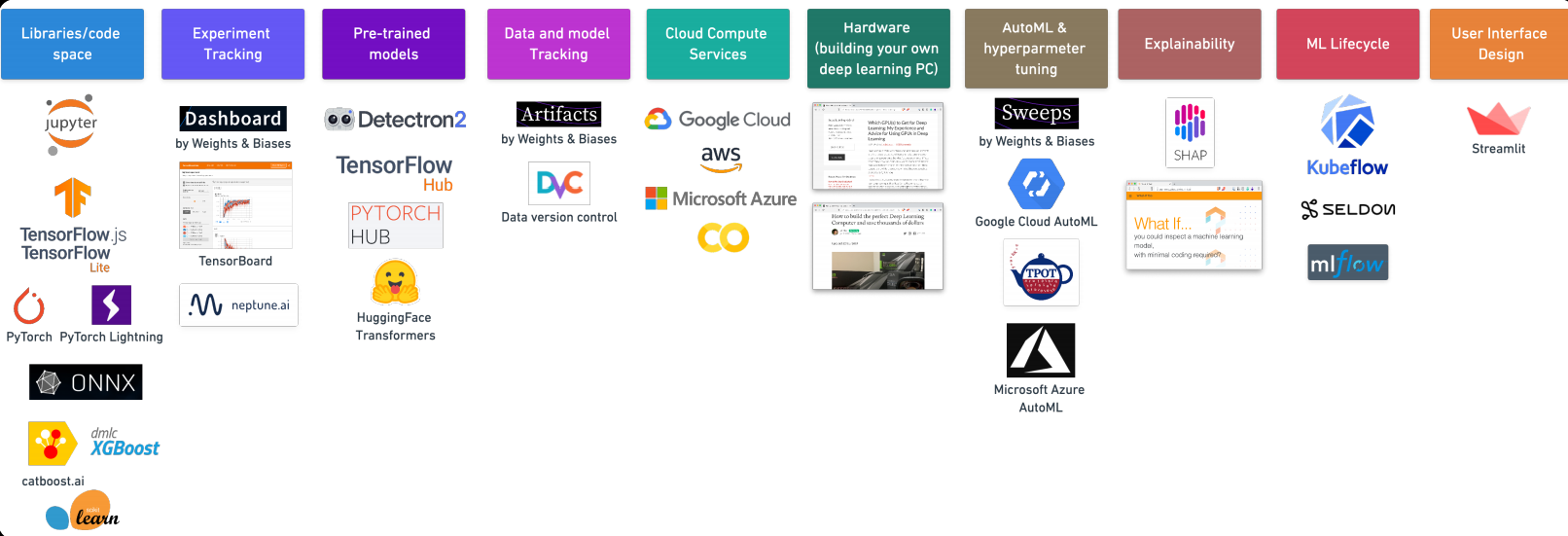
7. Strumenti di apprendimento automatico
Grazie per aver letto questo. se ti piace questo articolo, Condividi con i tuoi amici. In caso di qualsiasi suggerimento / dubbio, commenta qui sotto.
Identificazione e-mail: [e-mail protetta]
Seguimi su LinkedIn: LinkedIn
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





