Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Apache Spark è un framework utilizzato negli ambienti di cluster computing per analizzare i big data. Apache Spark può funzionare in un ambiente distribuito su un gruppo di computer in un cluster per elaborare in modo più efficace set di dati di grandi dimensioni. Questo motore Spark open source supporta un'ampia gamma di linguaggi di programmazione, compreso Scala, Giava, R e Python.
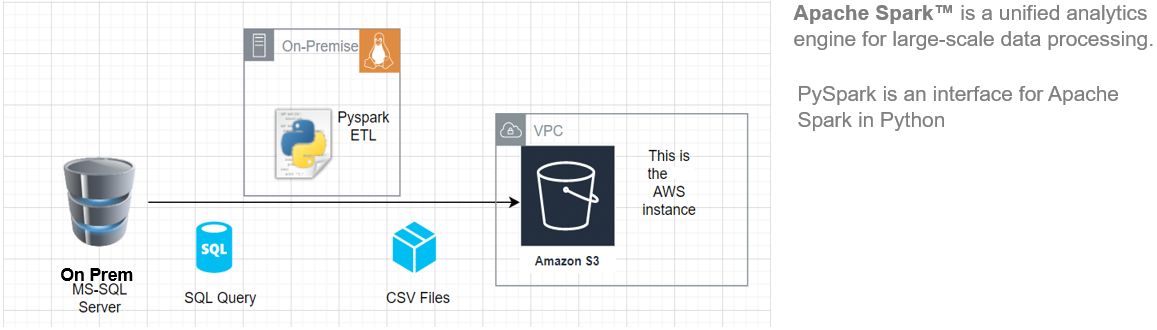
In questo articolo, Ti mostrerò come iniziare a installare Pyspark sul tuo Ubuntu macchina e quindi creare una pipeline ETL di base per estrarre i dati di carico di trasferimento da un sistema RDBMS remoto a a AWS S3 Benna.
Questa architettura ETL può essere utilizzata per trasferire centinaia di Gigabyte di dati da qualsiasi server di database RDBMS. (in questo articolo abbiamo utilizzato MS SQL Server) ha un bucket Amazon S3.
Principali vantaggi dell'utilizzo di Apache Spark:
- Esegui carichi di lavoro 100 volte più veloce di Hadoop
- Compatibile con Java, Scala, Pitone, R e SQL
Fonte: Questa è un'immagine originale.
Requisiti
Iniziare, dobbiamo avere i seguenti prerequisiti:
- Un sistema con Ubuntu 18.04 o Ubuntu 20.04
- Un account utente con privilegi sudo
- Un account AWS con accesso in caricamento al bucket S3
Prima di scaricare e configurare Spark, è necessario installare le dipendenze del pacchetto necessarie. Assicurati che i seguenti pacchetti siano già configurati sul tuo sistema.
Per confermare le dipendenze installate eseguendo questi comandi:
java -versione; git --version; python --versione

Installa PySpark
Scarica la versione di Spark che desideri dal sito Web ufficiale di Apache. Scaricheremo Spark 3.0.3 con Hadoop 2.7 poiché è la versione attuale. Prossimo, usa il comando wget e l'URL diretto per scaricare il pacchetto Spark.
Cambia la tua directory di lavoro in / optare / scintilla.
cd /opt/spark
sudo wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz

Estrai il pacchetto salvato usando il comando tar. Una volta completato il processo di diffusione, l'output mostra i file che sono stati decompressi dall'archivio.
tar xvf spark-*
ls -lrt spark-*

Configura l'ambiente Spark
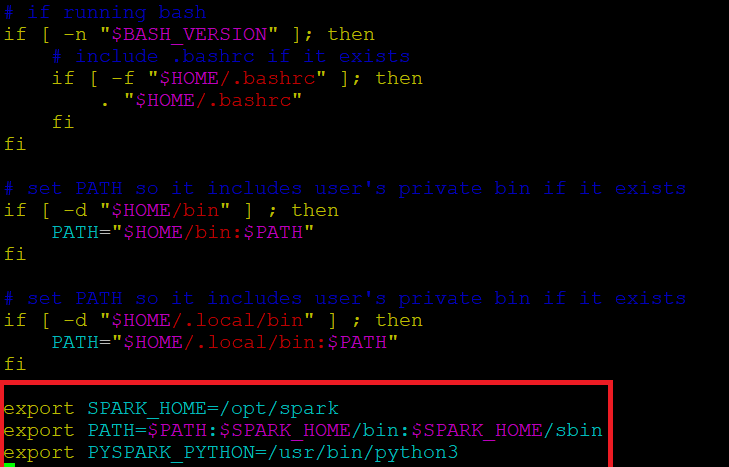
Prima di avviare un server Spark, dobbiamo impostare alcune variabili d'ambiente. Ci sono alcune directory Spark che dobbiamo aggiungere al profilo predefinito. Usa l'editor vi o qualsiasi altro editor per aggiungere queste tre righe a .profile:
vi ~ / .profilo
Inserisci questi 3 righe alla fine del file .profile.
esporta SPARK_HOME=/opt/spark esporta PERCORSO=$PERCORSO:$SPARK_HOME/bin:$SPARK_HOME/sbin esporta PYSPARK_PYTHON=/usr/bin/python3
Salva le modifiche ed esci dall'editor. Quando hai finito di modificare il file, caricare il .profilo file sulla riga di comando digitando. In alternativa, possiamo uscire dal server e accedere nuovamente per rendere effettive le modifiche.
sorgente ~/.profilo
Cominciare / Ferma il maestro delle scintille & Lavoratore
Vai alla directory di installazione di Spark / optare / scintilla / scintilla *. Ha tutti gli script necessari per iniziare / interrompere i servizi Spark.
Esegui questo comando per avviare Spark Master.
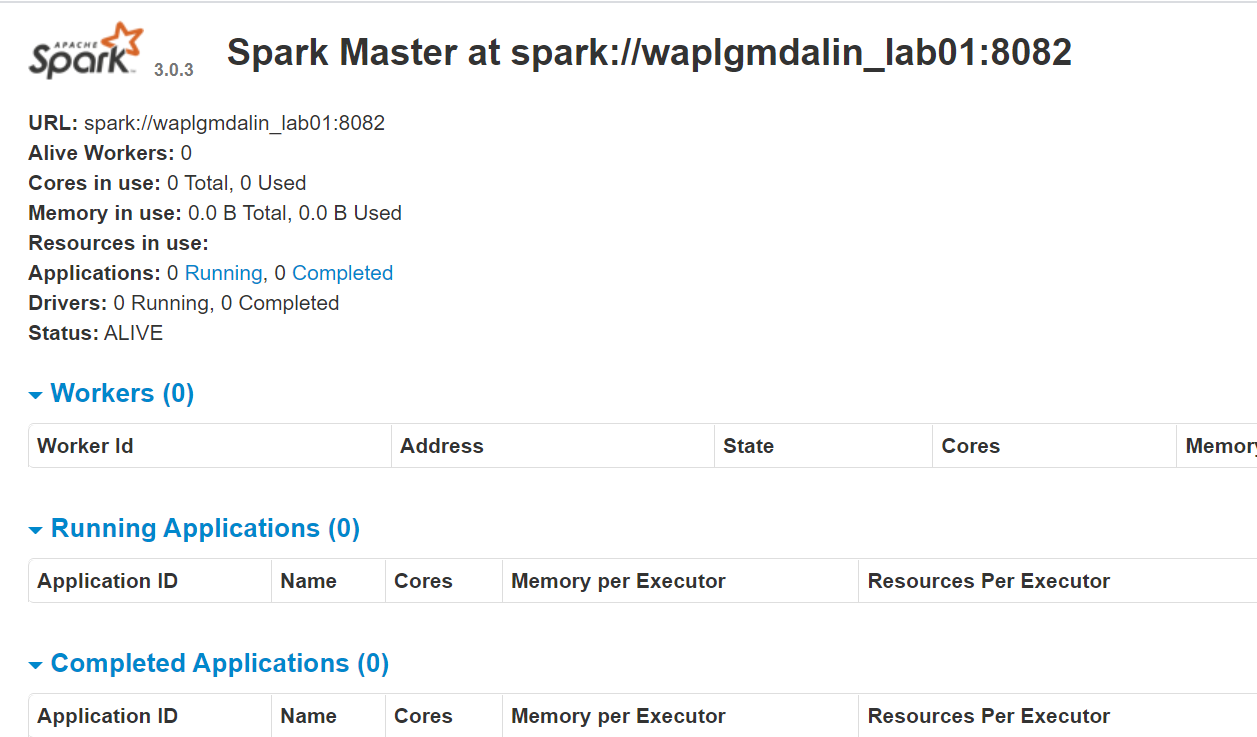
start-master.shPer visualizzare l'interfaccia web di Spark, apri un browser web e inserisci l'indirizzo IP dell'host locale nella porta 8080. (Questa è la porta predefinita che Spark usa se devi cambiarla, fallo nello script start-master.sh). In alternativa, può sostituire 127.0.0.1 con l'indirizzo IP di rete effettivo della macchina host.
http://127.0.0.1:8080/La pagina web mostra l'URL Spark Master, nodi di lavoro, Utilizzo delle risorse della CPU, la memoria, applicazioni in esecuzione, eccetera.
Ora, esegui questo comando per avviare un'istanza di lavoro Spark.
start-slave.sh spark://0.0.0.0:8082
oh
start-slave.sh spark://waplgmdalin_lab01:8082
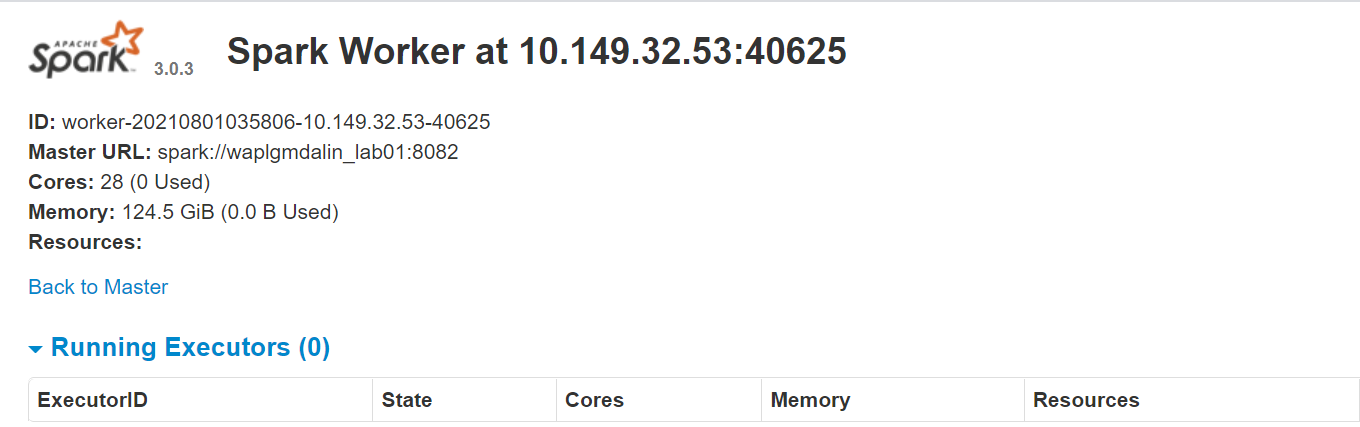
Il sito web del lavoratore funziona su http://127.0.0.1:8084/ ma deve essere collegato all'insegnante. Questo è il motivo per cui passiamo l'URL master Spark come parametro allo script start-slave.sh. Per confermare se il lavoratore è correttamente collegato al master, apri il link in un browser.
Assegnazione di risorse al lavoratore Spark
Per impostazione predefinita, quando avvii un'istanza di lavoro, utilizza tutti i nuclei disponibili sulla macchina. tuttavia, per motivi pratici, potresti voler limitare il numero di core e la quantità di RAM assegnata a ciascun lavoratore.
start-slave.sh spark://0.0.0.0:8082 -C 4 -m 512 M
Qui, abbiamo assegnato 4 nuclei e 512 MB RAM al lavoratore. Confermiamo questo riavviando l'istanza di lavoro.
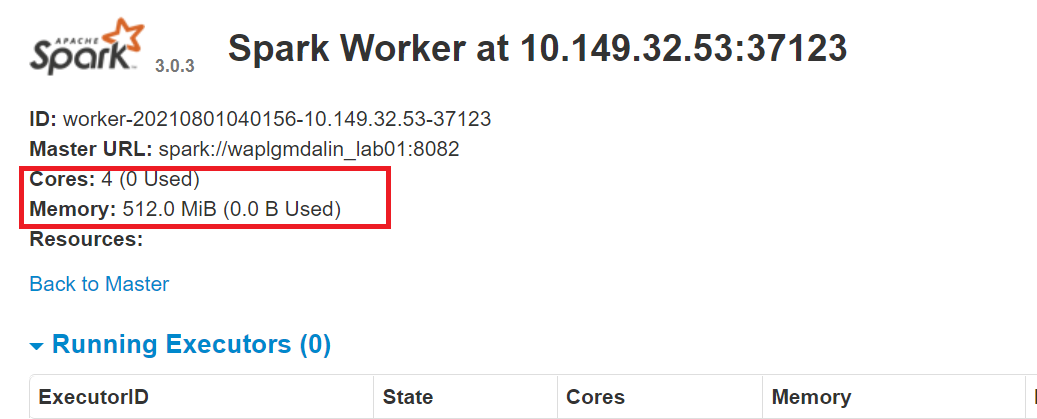
Per fermare il maestro istanza avviata eseguendo lo script precedente, correre:
stop-master.shPer fermare un lavoratore in corsa processi, inserisci questo comando:
stop-slave.shConfigura la connessione MS SQL
In questo PySpark ETL, ci collegheremo a un'istanza del server MS SQL come sistema di origine ed eseguiremo query SQL per ottenere dati. Quindi, prima dobbiamo scaricare le dipendenze necessarie.
Scarica il file jar MS-SQL (mssql-jdbc-9.2.1.jre8) dal sito Web di Microsoft e copiarlo nella directory “/ optare / scintilla / barattoli”.
https://www.microsoft.com/en-us/download/details.aspx?id=11774
Scarica il file jar Spark SQL (chispa-sql_2.12-3.0.3.jar) dal sito di download di Apache e copiarlo nella directory "/ opt" / scintilla / barattoli ".
https://jar-download.com/?search_box=org.apache.spark+spark.sql
Modifica il .profilo, aggiungi le classi PySpark e Py4J al percorso Python:
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$PYTHONPATH
Configura la connessione AWS S3
Per connettersi a un'istanza AWS, dobbiamo scaricare i tre file jar e copiarli nella directory “/ optare / scintilla / barattoli”. Controlla la versione di Hadoop che stai attualmente utilizzando. Puoi ottenerlo da qualsiasi jar presente nella tua installazione Spark. Se la versione di Hadoop è 2.7.4, scarica il file jar per la stessa versione. Per Java SDK, devi scaricare la stessa versione utilizzata per generare il pacchetto Hadoop-aws.
Assicurati che le versioni siano le ultime.
- hadoop-aws-2.7.4.jar
- aws-java-sdk-1.7.4.jar
- getti3t-0.9.4.barattolo
sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk/1.11.30/aws-java-sdk-1.7.4.jar sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/2.7.3/hadoop-aws-2.7.4.jar sudo wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar
Sviluppo Python
Crea una directory di lavoro chiamata "script"’ per memorizzare tutti gli script Python e i file di configurazione. Crea un file chiamato “sqlfile.py” che conterrà le query SQL che vogliamo eseguire sul server del database remoto.
vi sqlfile.py
Inserisci la seguente query SQL nel file sqlfile.py che estrarrà i dati. Prima di questo passaggio, si consiglia di eseguire un test di questa query SQL sul server per avere un'idea del numero di record restituiti.
query1 = """(Selezionare * da dati di vendita dove data >= '2021-01-01' e stato="Completato")"""
Salva ed esci dal file.
Crea un file di configurazione chiamato “config.ini” che memorizzerà le credenziali di accesso e i parametri del database.
vi config.ini
Inserisci i seguenti parametri di connessione AWS e MSSQL nel file. Nota che abbiamo creato sezioni separate per memorizzare i parametri di connessione AWS e MSSQL. Puoi creare tutte le istanze di connessione DB necessarie, purché ognuno sia tenuto nella propria sezione (mssql1, mssql2, aws1, aws2, eccetera.).
[aws]
ACCESS_KEY=BBIYYTU6L4U47BGGG&^CF SECRET_KEY=Uy76BBJabczF7h6vv+BFssqTVLDVkKYN/f31puYHtG BUCKET_NAME=s3-nome-secchio DIRECTORY=directory-dati-vendite [mssql] url = jdbc:server SQL://PPOP24888S08YTA.APAC.PAD.COMPANY-DSN.COM:1433;databaseName=Transazioni database = Transazioni utente = MSSQL-USER password = MSSQL-Password dbtable = dati di vendita nome file = data_extract.csv
Salva ed esci dal file.
Crea uno script Python chiamato “Estrazione dati.py”.
Importa librerie per Spark e Boto3
Spark è implementato in Scala, un linguaggio che gira nella JVM, ma poiché stiamo lavorando con Python useremo PySpark. La versione attuale di PySpark è 2.4.3 e funziona con Python 2.7, 3.3 e più in alto. Puoi pensare a PySpark come a un contenitore basato su Python sopra l'API Scala.
Qui, SDK AWS per Python (Boto3) creare, configurare e gestire i servizi AWS, come Amazon EC2 e Amazon S3. L'SDK fornisce un'API orientata agli oggetti, così come l'accesso di basso livello ai servizi AWS.
Importa le librerie Python per avviare una sessione Spark, query1 da sqlfile.py e boto3.
da pyspark.sql import SparkSession import shutil importare il sistema operativo importare globo importare boto3 da sqlfile import query1 da configparser importa ConfigParser
Crea una SparkSession
SparkSession fornisce un unico punto di ingresso per interagire con il motore Spark sottostante e consente la programmazione Spark con API DataFrame e Dataset. Ancora più importante, limita il numero di concetti e build con cui uno sviluppatore deve lavorare mentre interagisce con Spark.. A questo punto, puoi usare il ‘Scintilla – scintilla’ variabile come oggetto istanza per accedere ai tuoi metodi e istanze pubblici per la durata del tuo lavoro Spark. Dai un nome all'app.
nomeapp = "Esempio di PySpark ETL - tramite MS-SQL JDBC"
maestro = "Locale"
scintilla = SparkSession
.costruttore
.maestro(maestro)
.nome dell'applicazione(nome dell'applicazione)
.config("spark.driver.extraClassPath","/opt/spark/jars/mssql-jdbc-9.2.1.jre8.jar")
.getOrCreate()
Leggi il file di configurazione
Abbiamo memorizzato i parametri in un file “config.ini” per separare i parametri statici dal codice Python. Questo aiuta a scrivere codice più pulito senza alcuna codifica. Este modulo implementa un linguaggio di configurazione di base che fornisce una struttura simile a quella che vediamo nei file .ini di Microsoft Windows.
url = config.get('mssql-onprem', "URL")
utente = config.get('mssql-onprem', 'utente')
password = config.get('mssql-onprem', 'parola d'ordine')
dbtable = config.get('mssql-onprem', 'dbtable')
nome file = config.get('mssql-onprem', 'nome del file')
ACCESS_KEY=config.get('aw', 'CHIAVE DI ACCESSO')
SECRET_KEY=config.get('aw', 'CHIAVE SEGRETA')
BUCKET_NAME=config.get('aw', 'BUCKET_NAME')
DIRECTORY=config.get('aw', 'RUBRICA')
Esegui l'estrazione dei dati
Spark include un'origine dati in grado di leggere i dati da altri database utilizzando JDBC. Esegui SQL sul database remoto connettendoti utilizzando il driver JDBC di Microsoft SQL Server e i parametri di connessione. In opzione “domanda”, se vuoi leggere un'intera tabella, fornire il nome della tabella; altrimenti, se vuoi eseguire la query di selezione, specificare lo stesso. I dati restituiti da SQL sono archiviati in un frame di dati Spark.
jdbcDF = spark.read.format("jdbc")
.opzione("URL", URL)
.opzione("interrogazione", query2)
.opzione("utente", utente)
.opzione("parola d'ordine", parola d'ordine)
.opzione("autista", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.carico()
jdbcDF.show(5)
Salva frame di dati come file CSV
Il frame di dati può essere archiviato sul server come file. Archivio CSV. Qualcosa, questo passaggio è facoltativo nel caso in cui si desideri scrivere il frame di dati direttamente su un bucket S3, questo passaggio può essere saltato. PySpark, predefinito, creare più partizioni, per evitare ciò possiamo salvarlo come un singolo file usando la funzione coalesce (1). Prossimo, spostiamo il file nella cartella di output designata. Facoltativamente, rimuovi la directory di output creata se vuoi solo salvare dataframe nel bucket S3.
percorso="produzione"
jdbcDF.coalesce(1).write.option("intestazione","vero").opzione("settembre",",").modalità("sovrascrivi").csv(il percorso)
Shutil.mossa(glob.glob(os.getcwd() + '/' + il percorso + '/' + r '*.csv')[0], os.getcwd()+ '/' + nome del file )
shutil.rmtree(os.getcwd() + '/' + il percorso)
Copia frame di dati nel bucket S3
Primo, creare una "sessione boto3"’ utilizzando l'accesso AWS e i valori delle chiavi segrete. Recupera i valori dal bucket S3 e dalla sottodirectory in cui desideri caricare il file. il Caricare un file() accetta un nome di file, un nome di bucket e un nome di oggetto. Il metodo gestisce file di grandi dimensioni dividendoli in blocchi più piccoli e caricando ciascun blocco in parallelo.
sessione = boto3.Sessione(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
)
bucket_name=BUCKET_NAME
s3_output_key=DIRECTORY + nome del file
s3 = sessione.risorsa('s3')
# Nome del file - File da caricare
# Benna - Secchio su cui caricare (la directory di primo livello in AWS S3)
# Chiave - Nome oggetto S3 (può contenere sottodirectory). Se non specificato, viene utilizzato file_name
s3.meta.client.upload_file(nomefile=nomefile, Secchio=nome_secchio, Chiave=s3_output_key)
Pulizia dei file
Dopo aver caricato il file nel bucket S3, eliminare tutti i file rimasti sul server; altrimenti, Ho lanciato un errore.
if os.path.isfile(nome del file):
rimuove(nome del file)
altro:
Stampa("Errore: %s file non trovato" % nome del file)
conclusione
Apache Spark è un framework di elaborazione cluster open source con capacità di elaborazione in memoria. È stato sviluppato nel linguaggio di programmazione Scala. Spark offre molte caratteristiche e capacità che lo rendono un efficiente framework per Big Data. Prestazioni e velocità sono i principali vantaggi di Spark. Puoi caricare i terabyte di dati ed elaborarli senza problemi configurando un cluster multi-nodo. Questo articolo dà un'idea di come scrivere un ETL basato su Python.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





