Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Queste situazioni possono essere affrontate comprendendo il caso d'uso di ciascuna metrica.
Tutti conoscono le basi di tutte le metriche di ranking utilizzate di frequente, ma quando si tratta di sapere qual è quello giusto per valutare le prestazioni del proprio modello di classificazione, pochissimi si fidano del prossimo passo da fare.
Il apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... normalmente se encuentra en regresión (avere obiettivi continui) o in classificazione (avere obiettivi discreti). tuttavia, in questo articolo, Cercherò di concentrarmi su una parte molto piccola ma molto importante del machine learning, questo è l'argomento preferito degli intervistatori, “chissà cosa”, può anche aiutarti a ottenere i tuoi concetti corretti nei modelli di classificazione e, Finalmente, su qualsiasi problema aziendale. Questo articolo ti aiuterà a sapere che quando qualcuno ti dice che un modello ml sta dando un 94% precisione, quali domande fare per scoprire se il modello funziona effettivamente come richiesto.

Quindi, Come decidere le domande che ti aiuteranno??
Ora, questo è un pensiero per l'anima.
Risponderemo a questo sapendo valutare un modello di classificazione, il modo corretto.
Esamineremo i seguenti argomenti in questo articolo:
-
Precisione
-
Difetti
-
Matrice di confusione
-
Metriche basate sulla matrice di confusione
-
Riepilogo
Dopo aver letto questo articolo, avrà la conoscenza di:
-
Che cos'è la matrice di confusione e perché è necessario utilizzarla?
-
Come calcolare una matrice di confusione per un problema di classificazione 2 Lezioni
-
Metriche basate sulla matrice di confusione e come usarle
Precisione e i suoi difetti:
Precisione (ACC) misura la frazione di previsioni corrette. è definito come “la relazione tra previsioni corrette e previsioni totali effettuate”.

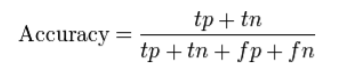
Problema con la precisione:
Nascondi i dettagli di cui hai bisogno per comprendere meglio le prestazioni del tuo modello di ranking. Puoi seguire gli esempi seguenti per aiutarti a capire il problema:
-
VariabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de destino de varias clases: quando i tuoi dati hanno più di 2 Lezioni. Insieme a 3 o più classi, puoi ottenere una sorta di precisione del 80%, ma non sai se è perché tutte le classi prevedono ugualmente bene o se il modello sta trascurando una o due classi.
-
da sbilanciato
Un tipico esempio di dati sbilanciati è in un problema di classificazione delle email in cui le email sono classificate come spam o non spam. Qui, il numero di spam è considerevolmente molto basso (meno di 10%) rispetto al numero di email pertinenti (niente spam) (più di 90%). Quindi, la distribuzione originale a due classi porta a un set di dati sbilanciato.
Se prendiamo due lezioni, allora i dati bilanciati significherebbero che abbiamo 50% punti per ciascuna delle classi. Cosa c'è di più, si ci sono 60-65% punti per una classe e 40% F
L'accuratezza della classificazione non mette in evidenza i dettagli necessari per diagnosticare le prestazioni del modello. Questo può essere evidenziato usando una matrice di confusione.

Matrice di confusione:
Wikipedia definisce il termine come “una matrice di confusione, noto anche come matrice di errore, è un design specifico della tabella che consente la visualizzazione delle prestazioni di un algoritmo ".

Di seguito è riportata una matrice di confusione per due classi (+, -).
Ci sono quattro quadranti nella matrice di confusione, che sono simboleggiati di seguito.
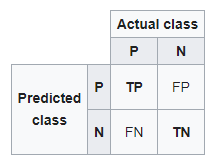
matrice di confusione
- : Il numero di in
- Aveva previsto che un'e-mail fosse spam e in realtà lo è.
- Falso negativo (FN): Il numero di istanze positive (+) e sono stati erroneamente classificati come negativi (-). È anche conosciuto come Errore di digitazione 2.
- Prevede che un'e-mail non è spam e in realtà lo è.
- Vero negativo (TN): Il numero di istanze negative (-) e sono stati correttamente classificati come (-).
- Prevede che un'e-mail non è spam e in effetti non lo è.
- Falso positivo (FP): Il numero di istanze negative (-) e sono stati erroneamente classificati come (+). Questo noto anche come Errore di digitazione 1.
- Prevede che un'e-mail non è spam e in realtà lo è.
Per aggiungere un po' di chiarezza:
In alto a sinistra: veri positivi per valori di evento correttamente previsti.
In alto a destra: falsi positivi per valori di evento previsti in modo errato.
In basso a sinistra: falsi negativi per valori non-evento correttamente previsti.
In basso a destra: Veri negativi per valori senza eventi errati previsti.
Metriche basate sulla matrice di confusione:
-
Precisione
-
Ricordare
-
Punteggio F1
Precisione
La precisione calcola la capacità di un classificatore di non etichettare una vera osservazione negativa come positiva.
Precisione=TP/(TP+FP)
Usando la precisione
Usiamo la precisione quando lavoriamo su un modello simile al set di dati di rilevamento dello spam, poiché Recall calcola effettivamente quanti dei positivi effettivi cattura il nostro modello etichettandolo come positivo.
Ricordare (sensibilità)
Recall calcola la capacità di un classificatore di trovare osservazioni positive nel set di dati. Se volevi essere sicuro di trovare tutti i commenti positivi, potrebbe massimizzare la memoria.
Richiamo=TP/(TP+FN)
Tendiamo sempre a usare il ritiro quando abbiamo bisogno di identificare correttamente scenari positivi, come in un set di dati di rilevamento del cancro o in un caso di rilevamento di frodi. L'accuratezza o la precisione non saranno così utili qui.
MisurareIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... F
Per confrontare due modelli qualsiasi, usiamo il punteggio F1. È difficile confrontare due modelli con bassa precisione e alto recupero o viceversa. Il punteggio F1 aiuta a misurare il recupero e la precisione allo stesso tempo. Usa la media armonica invece della media aritmetica quando punisci di più i valori estremi.
Comprendere la matrice di confusione
Diciamo che abbiamo un problema di classificazione binaria in cui vogliamo prevedere se un paziente ha il cancro o no., a seconda dei sintomi (le caratteristiche) introdotto nel modello di apprendimento automatico (sorter).
Come precedentemente studiato, il lato sinistro della matrice di confusione mostra la classe prevista dal classificatore. Intanto, la riga superiore dell'array mostra le etichette di classe effettive dagli esempi.
Se il problema ha più di due classi, la matrice di confusione cresce solo del rispettivo numero di classi. Ad esempio, se ci sono quattro classi, sarebbe un array di 4 X 4.
In parole semplici, il numero di classi non importa, il principale rimarrà lo stesso: il lato sinistro della matrice sono i valori previsti e la parte superiore i valori effettivi. Quello che dobbiamo controllare è dove si intersecano per vedere il numero di esempi previsti per una data classe rispetto al numero effettivo di esempi per quella classe.
Mentre puoi calcolare manualmente metriche come la matrice di confusione, precisione e recupero, la maggior parte delle librerie di apprendimento automatico, come imparare Scikit per Python, avere metodi incorporati per ottenere queste metriche.
Generazione di una matrice di confusione in Scikit Learn
Abbiamo già trattato la teoria su come funziona la matrice di confusione, qui condivideremo i comandi Python per ottenere l'output di qualsiasi classificatore come array.
Per ottenere la matrice di confusione per il nostro classificatore, dobbiamo istanziare la matrice di confusione che abbiamo importato da Sklearn e passargli gli argomenti pertinenti: i veri valori e le nostre previsioni.
de sklearn.metrics importare confusion_matrix
c_matrix = confusione_matrice (test_y, predizioni)
stampare (c_matrix)
Riepilogo
In un breve riassunto, noi analizziamo:
-
precisione
-
problemi che può portare in tavola
-
matrice di confusione per comprendere meglio il modello di classificazione
-
accuratezza e recupero e scenario su dove usarli
Propendiamo per l'uso della precisione perché tutti hanno un'idea di cosa significa. È necessario aumentare l'uso di metriche più adatte, come recupero e precisione, può sembrare strano. Ora hai un'idea intuitiva del perché funzionano meglio per alcuni problemi, come compiti di smistamento sbilanciati.

Le statistiche ci forniscono definizioni formali per valutare queste misure.. Il nostro lavoro come data scientist è conoscere gli strumenti giusti per il lavoro giusto, e questo comporta la necessità di andare oltre la precisione quando si lavora con i modelli di classificazione.
Utilizzo del ripristino, precisione e punteggio F1 (precisione media armonica e recupero) ci permette di valutare modelli di classificazione e ci fa anche pensare di usare solo la precisione di un modello, soprattutto per problemi di squilibrio. Come abbiamo imparato, la precisione non è uno strumento di valutazione utile in vari problemi, quindi implementiamo altre misure aggiunte al nostro arsenale per valutare il modello.
Pantaloni Rohit





