Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Pretrattamento dei dati
È anche un passo importante nel data mining, poiché non possiamo lavorare con dati grezzi. La qualità dei dati deve essere controllata prima di applicare algoritmi di machine learning o data mining.
Perché la pre-elaborazione dei dati è importante??
La pre-elaborazione dei dati è principalmente per verificare la qualità dei dati. La qualità può essere verificata dal seguente
- Precisione: Per verificare se i dati inseriti sono corretti o meno.
- lo completo: Per verificare se i dati sono disponibili o non registrati.
- Consistenza: Per verificare se gli stessi dati sono salvati in tutti i luoghi corrispondenti o meno.
- Opportunità: I dati devono essere aggiornati correttamente.
- Credibilità: I dati devono essere affidabili.
- Interpretabilità: Comprensibilità dei dati.
- Pulizia dei dati
- Integrazione dei dati
- Riduzione dei dati
- Trasformazione dei dati
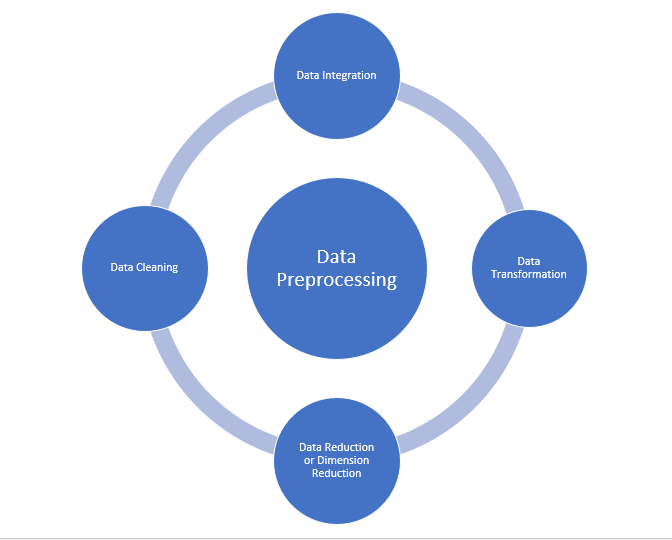
Fonte: medium.com
Pulizia dei dati:
La pulizia dei dati è il processo per eliminare i dati errati, dati incompleti e dati imprecisi provenienti da set di dati, e sostituisce anche i valori mancanti. Esistono alcune tecniche di pulizia dei dati
Gestione dei valori mancanti:
- I valori standard possono essere utilizzati come “Non disponibile” oh “N / A” Per sostituire i valori mancanti.
- I valori mancanti possono anche essere completati manualmente, Ma non consigliato quando il set di dati è di grandi dimensioni.
- Il valore medio dell'attributo può essere utilizzato per sostituire il valore mancante quando i dati sono distribuiti normalmente.
in cui, nel caso di una distribuzione non normale, È possibile utilizzare il valore mediano dell'attributo. - Quando si utilizzano algoritmi ad albero decisionale o di regressione, Il valore mancante può essere sostituito dal valore più probabile.
valore.
Rumoroso:
Rumoroso di solito significa errore casuale o contenente punti dati non necessari. Ecco alcuni dei metodi per gestire i dati rumorosi.
- Binning: Questo metodo viene utilizzato per semplificare o gestire dati rumorosi. Primo, I dati vengono ordinati e quindi i valori ordinati vengono separati e memorizzati sotto forma di contenitori. Esistono tre metodi per semplificare i dati del contenitore. Levigatura con il metodo bin mean: In questo metodo, i valori del contenitore vengono sostituiti dal valore medio del contenitore; Suavizado por medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... de bin: In questo metodo, i valori del contenitore sono sostituiti dal valore mediano; Levigatura dei bordi del contenitore: In questo metodo, Vengono presi i valori di utilizzo minimo e massimo dei valori di ubicazione e i valori vengono sostituiti dal valore limite più vicino.
- Regressione: Viene utilizzato per facilitare i dati e aiuterà a gestire i dati quando ci sono dati non necessari. Per l'analisi, la regresión de propósito ayuda a decidir la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... que es adecuada para nuestro análisis.
- Raggruppamento: Utilizzato per trovare valori anomali e anche per raggruppare i dati. La agrupación en clústeres se utiliza generalmente en el Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso....
Integrazione dei dati:
Il processo di combinazione di più origini in un unico set di dati. Il processo di integrazione dei dati è uno dei componenti principali nella gestione dei dati. Ci sono alcuni problemi di cui essere a conoscenza durante l'integrazione dei dati.
- Integrazione dello schema: Integrare i metadati (un dataset che descrive altri dati) da fonti diverse.
- Problema di identificazione dell'entità: Identificazione di entità da più database. Ad esempio, el sistema o el uso deben saber el _id de estudiante de una Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... y el nombre de estudiante de otra base de datos pertenece a la misma entidad.
- Scopri e risolvi i concetti relativi al valore dei dati: I dati tratti da diverse banche dati durante la fusione possono differire. In che modo i valori degli attributi di un database possono differire da un altro database. Ad esempio, Il formato della data può differire come “MILLIMETRO / DD / AAAA” oh “DD / MILLIMETRO / AAAA”.
Riduzione dei dati:
Questo processo consente di ridurre il volume di dati, che facilita l'analisi e produce lo stesso o quasi lo stesso risultato. Questa riduzione aiuta anche a ridurre lo spazio di archiviazione.. Alcune delle tecniche di riduzione dei dati sono la riduzione della dimensionalità, Riduzione della numerosità, Compressione dei dati.
- Riduzione della dimensionalità: Questo processo è necessario per le applicazioni del mondo reale, Poiché la dimensione dei dati è grande. In questo processo, La riduzione degli attributi o delle variabili casuali viene eseguita in modo da ridurre la dimensionalità del dataset. Combinare e unire gli attributi dei dati senza perdere le caratteristiche originali. Ciò aiuta anche a ridurre lo spazio di archiviazione e i tempi di calcolo. Quando i dati sono molto dimensionali, Il problema chiamato “La maledizione della dimensionalità”.
- Riduzione della numerosità: In questo metodo, La rappresentazione dei dati diventa più piccola riducendo il volume. Non ci sarà alcuna perdita di dati in questa riduzione.
- Compressione dei dati: La forma compressa dei dati è chiamata compressione dei dati. Questa compressione può essere lossless o lossy. Quando non c'è perdita di informazioni durante la compressione, si chiama compressione senza perdita di dati. Mentre la compressione con perdita di dati riduce le informazioni, ma rimuove solo le informazioni non necessarie.
Trasformazione dei dati:
La modifica apportata al formato o alla struttura dei dati è denominata trasformazione dei dati. Questo passaggio può essere semplice o complesso a seconda dei requisiti. Esistono alcuni metodi nella trasformazione dei dati.
- Levigatura: Con l'aiuto di algoritmi, Possiamo rimuovere il rumore dal set di dati e aiuta a conoscere le caratteristiche importanti del set di dati. Smussando possiamo anche trovare un semplice cambiamento che aiuta nella previsione.
- Aggregazione: In questo metodo, i dati vengono memorizzati e presentati in forma sintetica. Il dataset che proviene da più fonti è integrato con la descrizione dell'analisi dei dati. Questo è un passo importante in quanto l'accuratezza dei dati dipende dalla quantità e dalla qualità dei dati.. Quando la qualità e la quantità dei dati sono buone, i risultati sono più rilevanti.
- Discretizzazione: I dati continui qui sono divisi in intervalli. La discretizzazione riduce le dimensioni dei dati. Ad esempio, invece di specificare l'ora della lezione, possiamo impostare un intervallo come (3 pm-17, 6 pm-20).
- NormalizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi....: È il metodo per ridimensionare i dati in modo che possano essere rappresentati in un intervallo più piccolo. Esempio che va da -1.0 un 1.0.
Fasi di pre-elaborazione dei dati nell'apprendimento automatico
Importare librerie e set di dati
import pandas as pd
import numpy as np
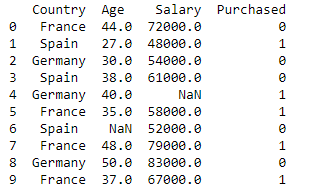
dataset = pd.read_csv('Set di dati.csv')
Stampa (data_set)
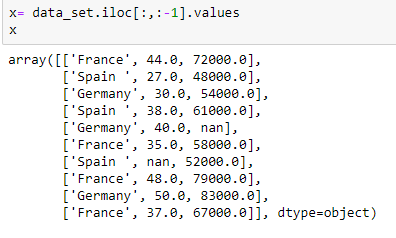
Estrazione di variabili indipendenti:
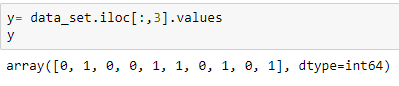
Estrazione della variabile dipendente:
Popolare il dataset con il valore medio dell'attributo
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values="Nan", strategy='mean', asse = 0)
imputerimputer= imputer.fit(X[:, 1:3])
X[:, 1:3]= imputer.transform(X[:, 1:3])
X
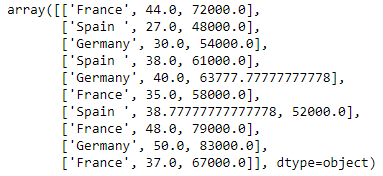
Codifica della variabile country
I modelli di machine learning utilizzano equazioni matematiche. Quindi, i dati categorici non sono accettati, quindi li convertiamo in forma numerica.
from sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
X[:, 0]= label_encoder_x.fit_transform(X[:, 0])
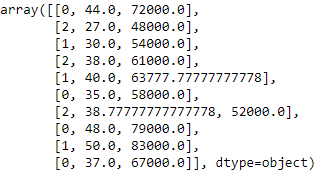
Codifica fittizia
Queste variabili fittizie sostituiscono i dati categorici come 0 e 1 in assenza o presenza di dati categorici specifici.
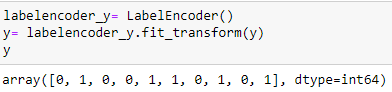
Codifica della variabile acquistata
labelencoder_y= LabelEncoder() y= labelencoder_y.fit_transform(e)
Dividir el conjunto de datos en conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e test:
da sklearn.model_selection import train_test_split x_treno, x_test, y_train, y_test = train_test_split(X, e, test_size= 0.2, stato_casuale=0)
Scala delle feature
da Sklearn.preprocessing importare StandardScaler
st_x= StandardScaler() x_train= st_x.fit_transform(x_treno)

x_test= st_x.transform(x_test)
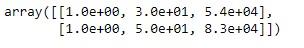
conclusione:
In questo articolo, Ho spiegato che il passaggio più cruciale nell'apprendimento automatico è la pre-elaborazione dei dati. Spero che questo articolo ti aiuti a capire meglio il concetto.
Riferimento:
https://www.javatpoint.com/data-preprocessing-machine-learning
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





