introduzione
Cos'è la pulizia dei dati?? Rimozione di record nulli, rimozione di colonne non necessarie, il trattamento dei valori mancanti, rettifica di valori indesiderati o valori anomali, ristrutturare i dati per modificarli in un formato più leggibile, eccetera., è noto come pulizia dei dati.

Uno degli esempi più comuni di pulizia dei dati è la sua applicazione nei data warehouse. Un data warehouse memorizza una serie di dati provenienti da numerose fonti e li ottimizza per l'analisi prima che possa essere eseguito qualsiasi adattamento del modello.
La pulizia dei dati non consiste solo nel rimuovere le informazioni esistenti per aggiungerne di nuove, ma trova un modo per massimizzare l'accuratezza di un set di dati senza necessariamente rinunciare alle informazioni esistenti. Diversi tipi di dati richiederanno diversi tipi di pulizia, ma ricorda sempre che il giusto approccio è il fattore decisivo.
Dopo aver pulito i dati, diventerà coerente con altri set di dati simili nel sistema.. Vediamo i passaggi per pulire i dati;
Cancella record nulli / duplicati
Se in una determinata riga mancano una quantità significativa di dati, allora sarebbe meglio eliminare quella riga, poiché non aggiungerebbe alcun valore al nostro modello. può imputare il valore; fornire un sostituto appropriato per i dati mancanti. Ricorda anche di cancellare sempre i valori duplicati / ridondante del tuo set di dati, poiché potrebbero causare un pregiudizio nel tuo modello.
Come esempio, considerare il set di dati dello studente con i seguenti record.
| Nome | punto | Indirizzo | altezza | il peso |
| UN | 56 | Vai a | 165 | 56 |
| B | 45 | Bombay | 3 | Sessantacinque |
| C | 87 | Delhi | 170 | 58 |
| D | ||||
| me | 99 | Mysore | 167 | 60 |
Come si vede corrisponde al nome dello studente “D”, la maggior parte dei dati è mancante, perché, scartiamo quella particolare riga.
student_df.dropna() # elimina righe con 1 o più valore Nan
#produzione
| Nome | punto | Indirizzo | altezza | il peso |
| UN | 56 | Vai a | 165 | 56 |
| B | 45 | Bombay | 3 | Sessantacinque |
| C | 87 | Delhi | 170 | 58 |
| me | 99 | Mysore | 167 | 60 |
Elimina le colonne non necessarie
Quando riceviamo dati da soggetti interessati, in generale è enorme. Potrebbe esserci un record di dati che potrebbe non aggiungere alcun valore al nostro modello. È meglio cancellare questi dati, poiché lo farebbe con risorse preziose come memoria e tempo di elaborazione.
Come esempio, osservare le prestazioni degli studenti in un test, il peso o l'altezza degli studenti non hanno nulla a che fare con il modello.
studente_df.drop(['altezza','il peso'], asse = 1, posto = vero) #La colonna Drops Height forma il dataframe
#Produzione
| Nome | punto | Indirizzo |
| UN | 56 | Vai a |
| B | 45 | Bombay |
| C | 87 | Delhi |
| me | 99 | Mysore |
Rinomina colonne
È sempre meglio rinominare le colonne e formattarle nel formato più leggibile che sia il data scientist che l'azienda possano comprendere.. Come esempio, nel set di dati dello studente, rinomina colonna “Nome” Che cosa “Nome_Sudent” ha senso.
student_df.rename(colonne={'nome': 'Nome dello studente'}, inplace=Vero) #rinomina la colonna del nome in Student_Name
#Produzione
| Nome dello studente | punto | Indirizzo |
| UN | 56 | Vai a |
| B | 45 | Bombay |
| C | 87 | Delhi |
| me | 99 | Mysore |
Gestire i valori mancanti
Esistono molte alternative per prendersi cura dei valori mancanti in un set di dati. Spetta allo scienziato dei dati e al set di dati a disposizione selezionare il metodo più appropriato. I metodi più utilizzati sono l'imputazione del set di dati con media, medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... o moda. Eliminazione di quei record particolari con uno o più valori mancanti e, in alcuni casi, anche la creazione di algoritmi di apprendimento automatico come la regressione lineare e il vicino più prossimo K viene utilizzata per gestire i valori mancanti.
| Nome dello studente | punto | Indirizzo |
| UN | 56 | Vai a |
| B | 45 | Bombay |
| C | Delhi | |
| me | 99 | Mysore |
Student_df['col_name'].riempire((Student_df['col_name'].Significare()), inplace=Vero) # I valori Na in col_name sono sostituiti con mean
#Produzione
| Nome dello studente | punto | Indirizzo |
| UN | 96 | Vai a |
| B | 45 | Bombay |
| C | 66 | Delhi |
| me | 99 | Mysore |
Rilevamento di valori atipici
I valori anomali possono essere considerati rumore nel set di dati. Ci possono essere diverse ragioni per i valori anomali, come errore di immissione dei dati, errore manuale, errore sperimentale, eccetera.
Come esempio, nel seguente esempio, punteggio dello studente “B” tu entri 130, che chiaramente non è corretto.
| Nome dello studente | punto | Indirizzo | altezza | il peso |
| UN | 56 | Vai a | 165 | 56 |
| B | 45 | Bombay | 3 | Sessantacinque |
| C | 66 | Delhi | 170 | 58 |
| me | 99 | Mysore | 167 | 60 |
Tracciare l'altezza su un box plot dà il seguente risultato
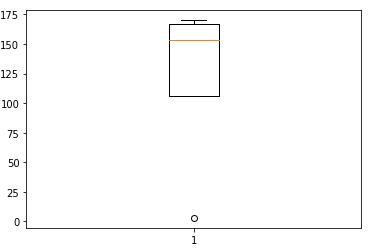
Non tutti i valori estremi sono valori anomali, alcuni possono anche portare a scoperte interessanti, ma questo è un argomento per un altro giorno. È possibile utilizzare test come il test del punteggio Z, il box plot o semplicemente tracciando i dati sul grafico riveleranno i valori anomali.
Riforma / ristrutturare i dati
La maggior parte dei dati aziendali forniti al data scientist non è nel formato più leggibile. È nostro compito rimodellare i dati e portarli in un formato che possa essere utilizzato per l'analisi.. Come esempio, creando una nueva variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... a partir de las variables existentes o combinando 2 o più variabili.
Note a piè di pagina
Certamente, ci sono molti vantaggi nel lavorare con dati puliti, pochi dei quali sono la migliorata precisione dei modelli, migliore processo decisionale da parte delle parti interessate, la facilidad de implementación del modelo y el ajuste de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto...., risparmiando tempo e risorse, e molti altri. Ricorda sempre di pulire i dati come primo e più importante passo prima di montare qualsiasi modello.
Riferimenti
https://www.geeksforgeeks.org/
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





