Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Pulizia dei dati è il processo di analisi dei dati per trovare valori errati, corrotti e mancanti e rimuoverli per renderli adatti all'input per l'analisi dei dati e vari algoritmi di apprendimento automatico.
È il passaggio principale e fondamentale che viene eseguito prima di poter eseguire qualsiasi analisi dei dati.. Non ci sono regole fisse da seguire per la pulizia dei dati. Dipende totalmente dalla qualità del set di dati e dal livello di precisione da raggiungere.
Motivi per la corruzione dei dati:
- I dati vengono raccolti da varie fonti strutturate e non strutturate e quindi combinati, portando a valori duplicati e erroneamente etichettati.
- Diverse definizioni del dizionario dati per i dati archiviati in più posizioni.
- Errore di immissione manuale / errori tipografici.
- Maiuscole errate.
- Categorie: / classi erroneamente etichettate.
Qualità dei dati
La qualità dei dati è della massima importanza per l'analisi. Ci sono diversi criteri di qualità che devono essere controllati:

Attributi di qualità dei dati

- lo completo: Definito come la percentuale di voci completate nel set di dati. La percentuale di valori mancanti nel set di dati è un buon indicatore della qualità del set di dati..
- Precisione: È definito come la misura in cui gli input nel set di dati sono vicini ai loro valori effettivi.
- Uniformità: Definito come la misura in cui i dati vengono specificati utilizzando la stessa unità di misura.
- Consistenza: È definito come la misura in cui i dati sono coerenti all'interno dello stesso set di dati e tra più set di dati.
- Validità: È definito come la misura in cui i dati sono conformi alle restrizioni applicate dalle regole aziendali. Ci sono diverse limitazioni:

Rapporto sul profilo dei dati
La profilazione dei dati è il processo di esplorazione dei nostri dati e ricerca di informazioni da essi. Pandas Profiling Report è il modo più veloce per estrarre informazioni complete sul tuo set di dati. Il primo passo per la pulizia dei dati è eseguire un'analisi esplorativa dei dati.
Come utilizzare la profilazione dei panda:
passo 1: Il primo passo è installare il pacchetto di profilatura dei panda usando il comando pip:
pip install pandas-profilingpasso 2: Carica il set di dati usando i panda:
import pandas as pddf = pd.read_csv(r"C:UsersDellDesktopDatasethousing.csv")
passo 3: Leggi le prime cinque righe:
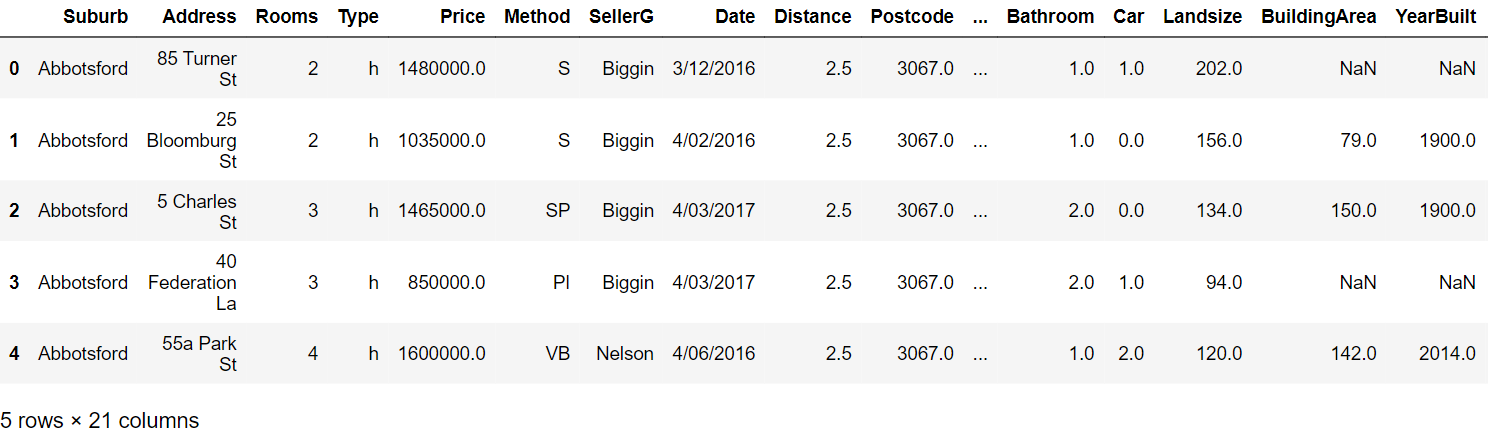
passo 4: Genera il report di profilazione con i seguenti comandi:
from pandas_profiling import ProfileReportprof = ProfileReport(df)prof.to_file(output_file="output.html")
Rapporto di profilazione:
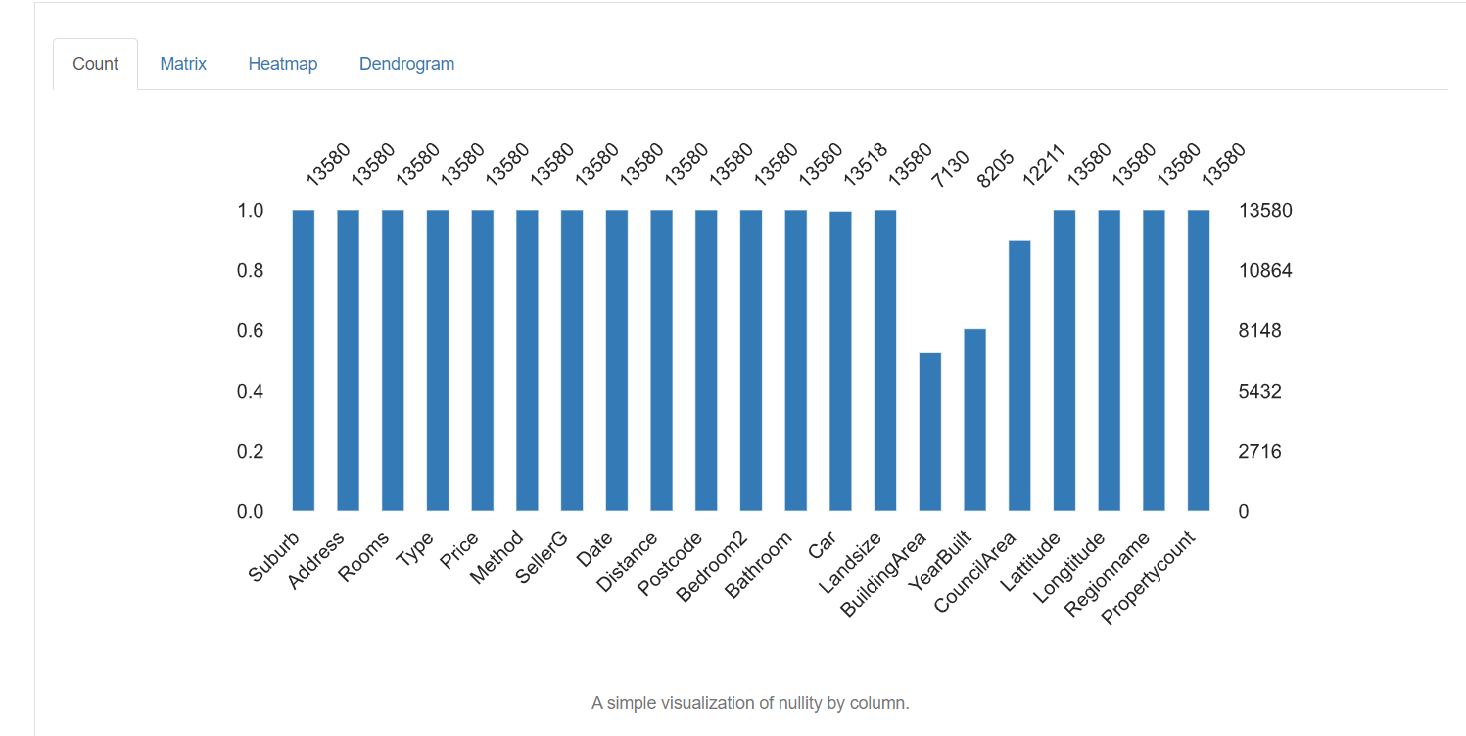
Il rapporto di profilazione si compone di cinque parti: descrizione generale, variabili, interazioni, correlazione e valori mancanti.
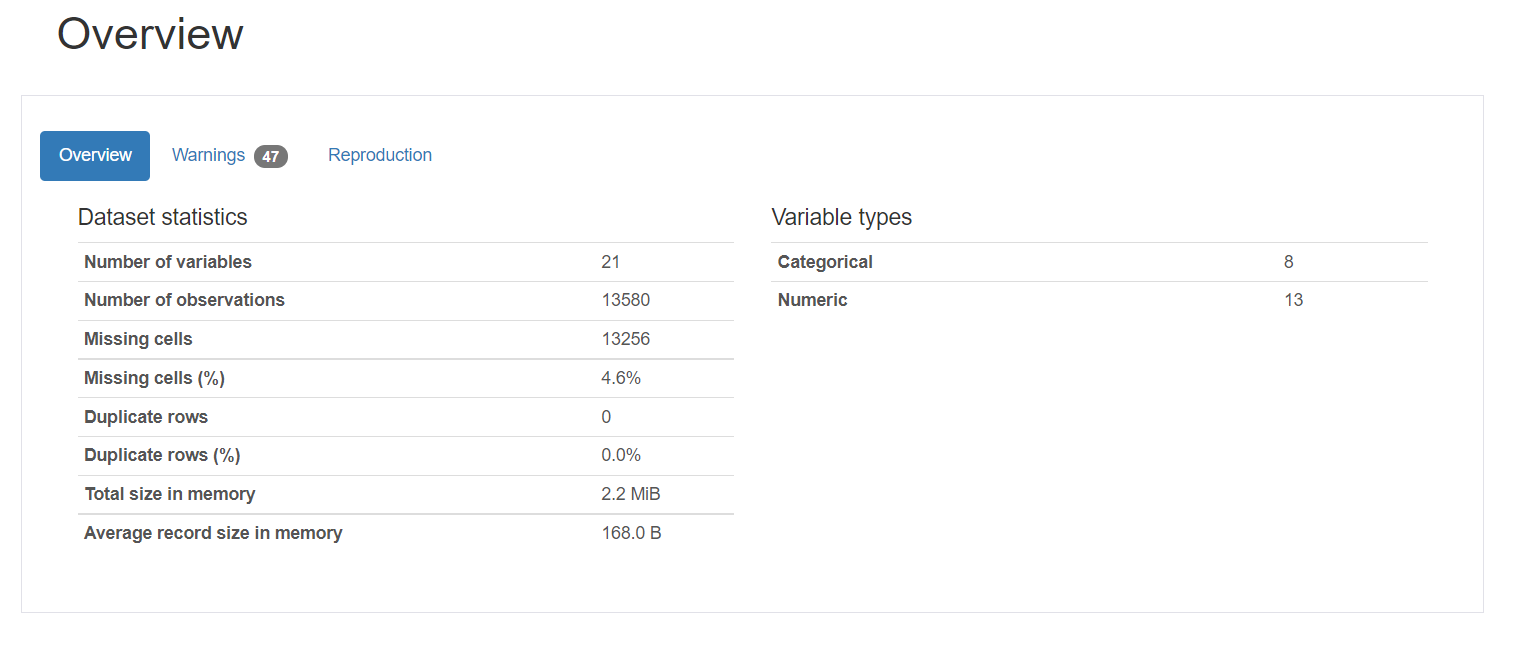
1. Panoramica fornisce statistiche generali sul numero di variabili, il numero di osservazioni, i valori mancanti, duplicati e il numero di variabili categoriali e numeriche.
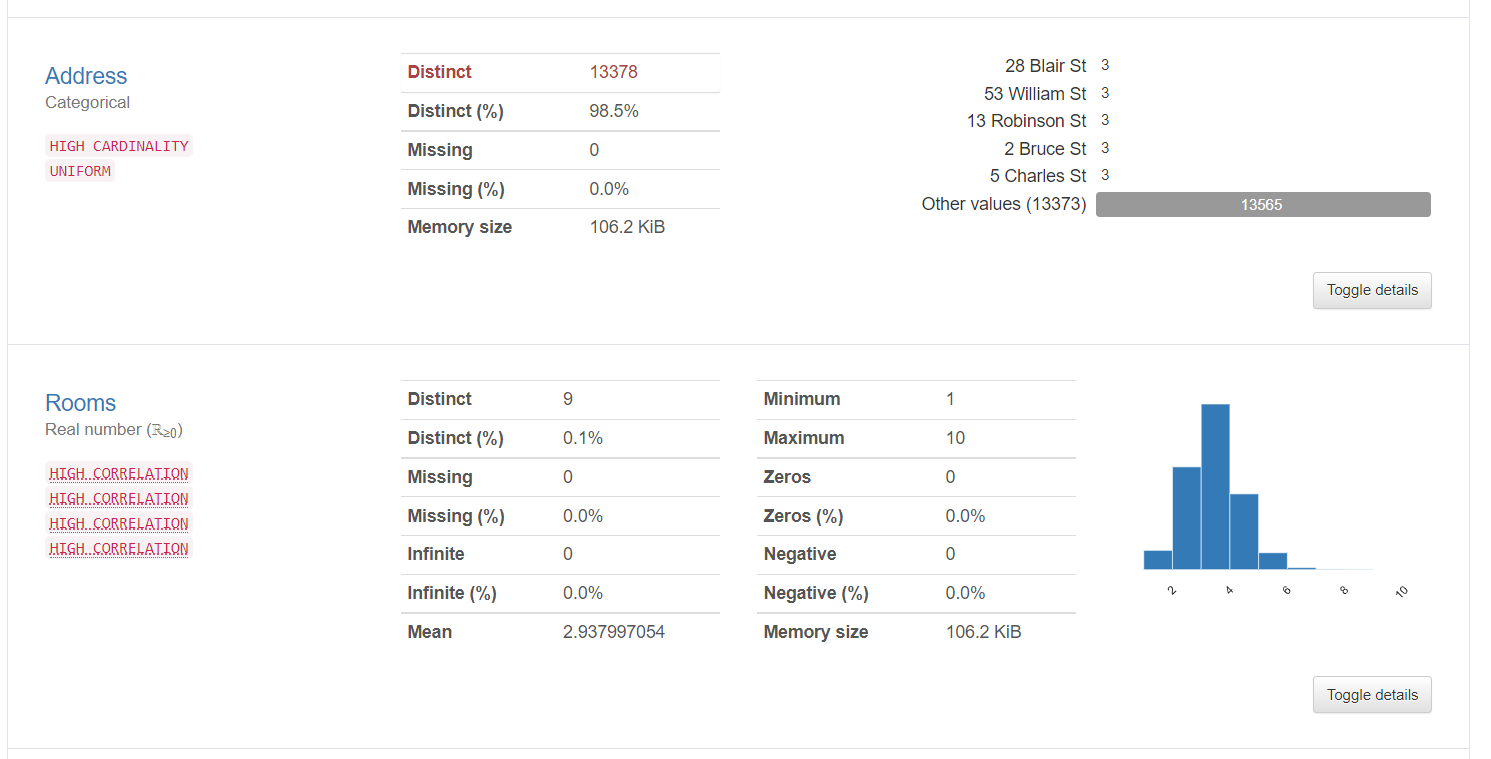
2. Le informazioni sulle variabili forniscono informazioni dettagliate sui valori distinti, i valori mancanti, media, mediano, eccetera. Ecco le statistiche su una variabile categoriale e una variabile numerica:
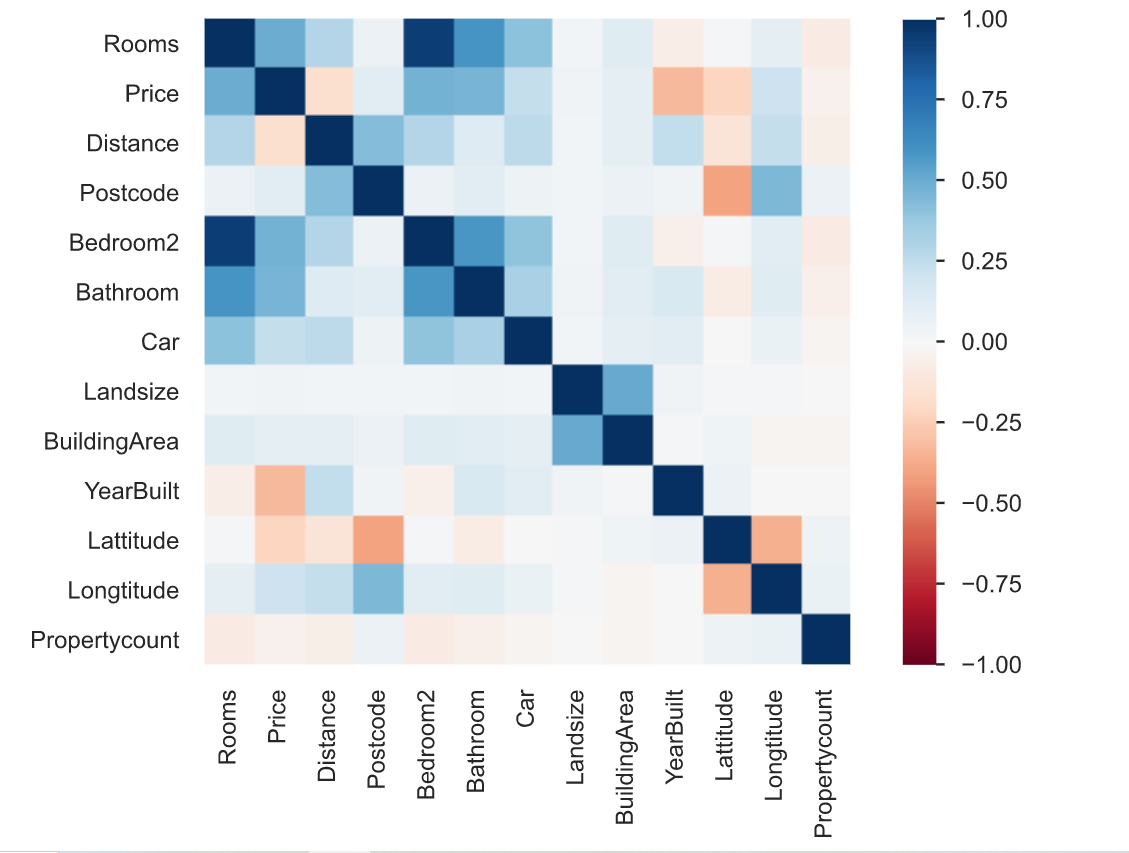
3. La correlazione è definita come il grado in cui due variabili sono correlate tra loro. Il rapporto di profilazione descrive la correlazione di diverse variabili tra loro sotto forma di mappa termica.
Interazioni: questa parte del report mostra le interazioni delle variabili tra loro. È possibile selezionare qualsiasi variabile sui rispettivi assi.
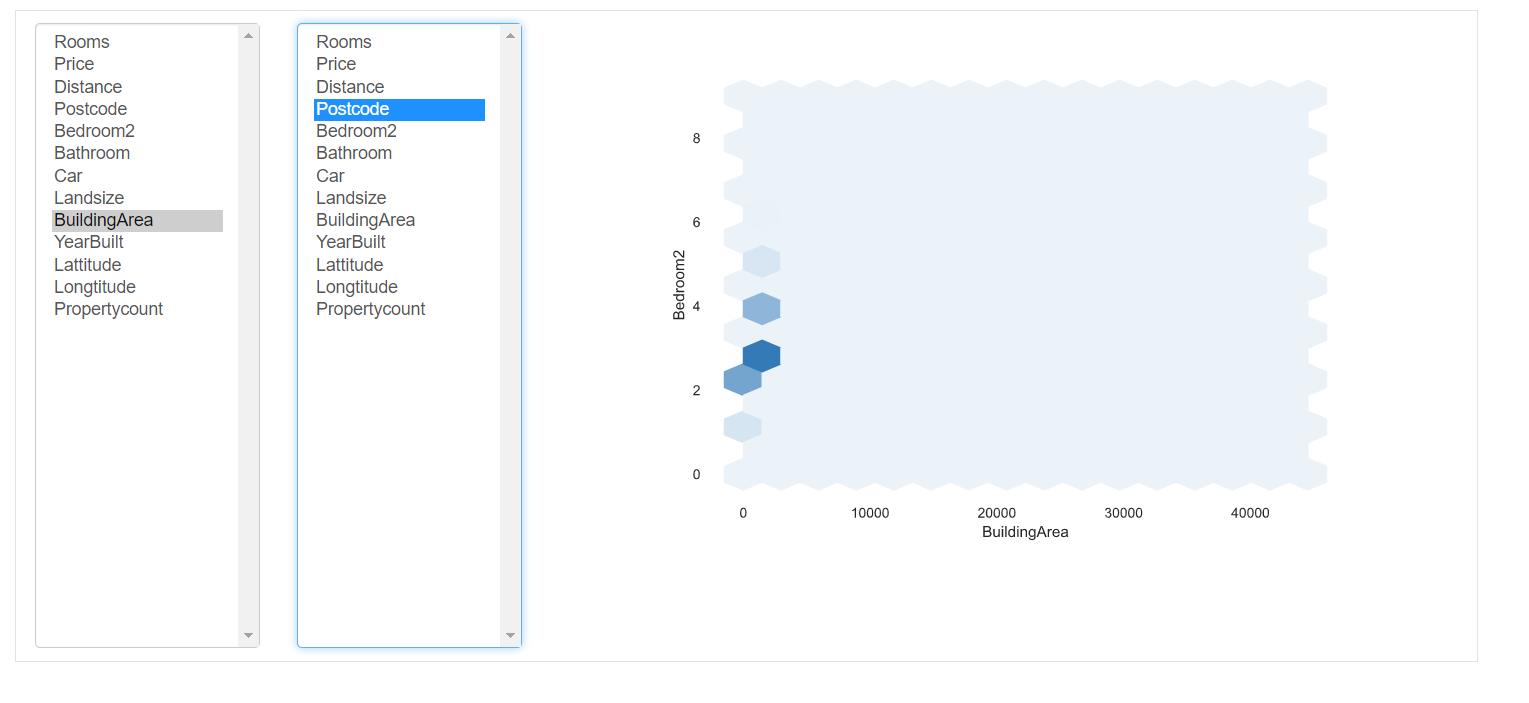
5. Valori mancanti: rappresenta il numero di valori mancanti in ogni colonna.
Tecniche di pulizia dei dati
Ora abbiamo una conoscenza dettagliata dei dati mancanti, valori errati e categorie erroneamente etichettate nel set di dati. Ora vedremo alcune delle tecniche utilizzate per pulire i dati. Dipende totalmente dalla qualità del set di dati, i risultati che si ottengono da come gestite i vostri dati. Alcune delle tecniche sono le seguenti:
Gestione dei valori mancanti:
La gestione dei valori mancanti è il passaggio più importante nella pulizia dei dati. La prima domanda da porsi è perché mancano i dati?? Manca solo perché l'operatore di inserimento dati non lo ha registrato o è stato lasciato intenzionalmente vuoto? Puoi anche rivedere la documentazione per trovare il motivo dello stesso.
Esistono diversi modi per gestire questi valori mancanti:
1. Elimina i valori mancanti: Il modo più semplice per gestirli è semplicemente rimuovere tutte le righe che contengono valori mancanti. Se non vuoi scoprire perché mancano i valori e hai solo una piccola percentuale di valori mancanti, puoi rimuoverli usando il seguente comando:
tuttavia, non è consigliabile perché tutti i dati sono importanti e hanno una grande importanza per i risultati complessivi. Generalmente, la percentuale di voci mancanti in una particolare colonna è alta. Quindi smettere non è una buona opzione.
2. Imputazione: L'imputazione è il processo di sostituzione dei valori null / perso per un certo valore. Per colonne numeriche, un'opzione è sostituire ogni voce mancante nella colonna con il valore medio o il valore mediano. Un'altra opzione potrebbe essere quella di generare numeri casuali tra un intervallo di valori adatti per la colonna. L'intervallo potrebbe essere compreso tra la media e la deviazione standard della colonna. Puoi semplicemente importare un imputer dal pacchetto scikit-learn ed eseguire l'imputazione come segue:
from sklearn.impute import SimpleImputer
#Imputation
my_imputer = SimpleImputer()
imputed_df = pd.DataFrame(my_imputer.fit_transform(df))Gestione dei duplicati:
Le righe duplicate si verificano generalmente quando i dati vengono combinati da più origini. A volte si replica. Un problema comune è quando gli utenti hanno lo stesso numero ID o il modulo è stato inviato due volte.
La soluzione a queste tuple duplicate è semplicemente rimuoverle. Puoi usare la funzione unica () per scoprire i valori univoci presenti nella colonna e poi decidere quali valori devono essere rimossi.
codifica:
La codifica dei caratteri è definita come l'insieme di regole definite per la mappatura uno a uno di stringhe di byte binari grezze su stringhe di testo leggibili dall'uomo. Sono disponibili varie codifiche: ASCII, utf-8, US-ASCII, utf-16, utf-32, eccetera.
Potresti notare che alcuni dei campi di caratteri di testo hanno modelli irregolari e irriconoscibili. Questo perché utf-8 è la codifica Python predefinita. Tutto il codice è in utf-8. Perciò, quando i dati provengono da più fonti strutturate e non strutturate e sono conservati in un luogo comune, modelli irregolari sono osservati nel testo.
La soluzione al problema di cui sopra è scoprire prima la codifica dei caratteri del file con l'aiuto del modulo charet in Python come segue:
import chardetwith open("C:/Users/Desktop/Dataset/housing.csv",'rb') as rawdata:result = chardet.detect(rawdata.read(10000))# check what the character encoding might beprint(result)
Dopo aver trovato il tipo di codifica, se diverso da utf-8, salva il file usando la codifica “utf-8” usando il seguente comando.
df.to_csv("C:/Users/Desktop/Dataset/housing.csv")Ridimensionamento e normalizzazione
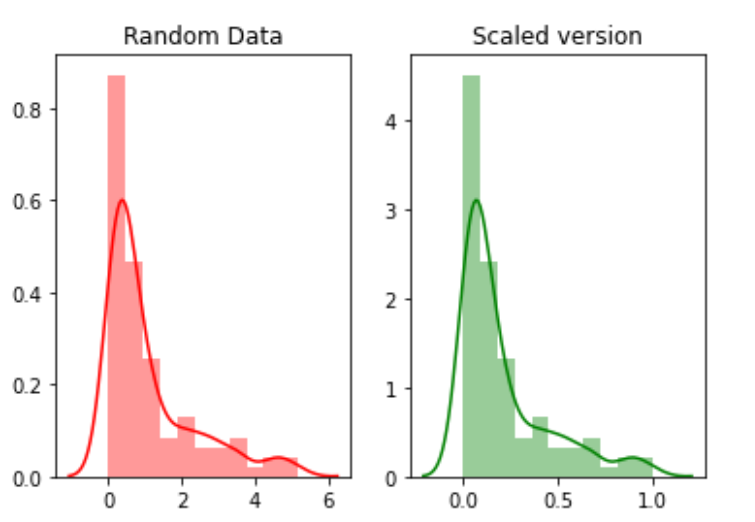
La scala si riferisce alla trasformazione dell'intervallo di dati e alla sua modifica in un altro intervallo di valori. Questo è utile quando vogliamo confrontare diversi attributi sulla stessa base.. Un esempio utile potrebbe essere la conversione di valuta.
Ad esempio, creeremo 100 punti casuali da una distribuzione esponenziale e poi li tracceremo. Finalmente, li convertiremo in una versione ridimensionata usando il pacchetto python mlxtend.
# for min_max scalingfrom mlxtend.preprocessing import minmax_scaling# plotting packagesimport seaborn as snsimport matplotlib.pyplot as plt
Ora ridimensionando i valori:
random_data = np.random.exponential(size=100)# mix-max scale the data between 0 and 1scaled_version = minmax_scaling(random_data, columns=[0])
Finalmente, tracciando le due versioni.
La normalizzazione si riferisce alla modifica della distribuzione dei dati in modo che possa rappresentare una curva a campana in cui i valori degli attributi sono equamente distribuiti sulla media. Il valore della media e della mediana è lo stesso. Questo tipo di distribuzione è anche chiamato distribuzione gaussiana.. È necessario per quegli algoritmi di apprendimento automatico che presuppongono che i dati siano normalmente distribuiti.
Ora, normalizzeremo i dati utilizzando la funzione boxcox:
from scipy import statsnormalized_data = stats.boxcox(random_data)# plot both together to comparefig,ax=plt.subplots(1,2)sns.distplot(random_data, ax=ax[0],color="pink")ax[0].set_title("Random Data")sns.distplot(normalized_data[0], ax=ax[1],color="purple")ax[1].set_title("Normalized data")
Gestione della data
Il campo della data è un attributo importante che deve essere gestito durante la pulizia dei dati. Esistono diversi formati in cui i dati possono essere inseriti nel set di dati. Perciò, standardizzare la colonna della data è un compito critico. Alcune persone potrebbero aver trattato la data come una colonna di stringhe, altri come colonna DateTime. Quando il set di dati viene combinato da diverse fonti, questo può creare un problema per l'analisi.
La soluzione è trovare prima il tipo di colonna della data utilizzando il seguente comando.
df['Data'].dtype
Se il tipo di colonna è diverso da DateTime, convertilo in DateTime usando il seguente comando:
import datetimedf['Date_parsed'] = pd.to_datetime(df['Date'], format="%m/%d/%y")
Gestire problemi di immissione dati incoerenti
Ci sono un gran numero di voci incoerenti che non possono essere trovate manualmente o con calcoli diretti. Ad esempio, se la stessa voce è scritta in maiuscolo o minuscolo o un misto di maiuscolo e minuscolo. Quindi, questa voce dovrebbe essere standardizzata su tutta la colonna.
Una soluzione è convertire tutte le voci in una colonna in minuscolo e tagliare lo spazio extra da ciascuna voce. Questo può essere annullato in seguito una volta completata l'analisi.
# convert to lower casedf['ReginonName'] = df['ReginonName'].str.lower()# remove trailing white spacesdf['ReginonName'] = df['ReginonName'].str.strip()
Un'altra soluzione è usare la corrispondenza fuzzy per trovare quali stringhe nella colonna sono più vicine tra loro e quindi sostituire tutte quelle voci con una soglia particolare con la voce iniziale.
Primo, scopriremo i nomi unici delle regioni:
region = df['Regionname'].unique()Quindi calcoliamo i punteggi utilizzando la corrispondenza approssimativa:
import fuzzywuzzyfromfuzzywuzzy import processregions=fuzzywuzzy.process.extract("WesternVictoria",region,limit=10,scorer=fuzzywuzy.fuzz.token_sort_ratio)

Convalida del processo.
Una volta completato il processo di pulizia dei dati, è importante verificare e convalidare che le modifiche apportate non abbiano ostacolato le restrizioni poste sul set di dati.
E infine, … Non c'è bisogno di dire,
Grazie per aver letto!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





