Panoramica:
- Scopri cos'è il Big Data e come sono rilevanti nel mondo di oggi
- Scopri le caratteristiche dei Big Data
introduzione
Il termine “Grandi dati” è un nome inappropriato, in quanto implica che i dati preesistenti sono in qualche modo piccoli (non lo sono) o che l'unica sfida sono le sue grandi dimensioni (la dimensione è una di queste, ma spesso c'è di più ).
In sintesi, il termine Big Data si applica alle informazioni che non possono essere elaborate o analizzate da processi o strumenti tradizionali.

Sempre più, Le organizzazioni di oggi si trovano ad affrontare sempre più sfide legate ai Big Data. Avere accesso a una grande quantità di informazioni, ma non sanno come estrarre valore da esso perché è nella sua forma più grezza o in un formato semi-strutturato o non strutturato; e di conseguenza, non sanno nemmeno se vale la pena tenerlo (o anche se possono tenerlo).
In questo articolo, analizziamo il concetto di big data e di cosa si tratta.
Sommario
- Cosa sono i Big Data??
- Caratteristiche dei Big Data
- Il volume di dati
- La varietà di dati
- La velocità dei dati
Cosa sono i Big Data??
Noi ne facciamo parte!, Ogni giorno!
Un sondaggio IBM ha rilevato che più della metà dei leader aziendali di oggi si rende conto di non avere accesso alle informazioni di cui ha bisogno per svolgere il proprio lavoro.. Le aziende affrontano queste sfide in un clima in cui hanno la capacità di archiviare qualsiasi cosa e generano dati come mai prima d'ora nella storia.; combinato, Ciò rappresenta una vera e propria sfida informativa.

È un enigma: le aziende di oggi hanno più accesso alle potenziali informazioni che mai, tuttavia, man mano che questa potenziale miniera d'oro di dati si accumula, la percentuale di dati che l'azienda può elaborare viene rapidamente ridotta. In poche parole, l'era dei Big Data è oggi in pieno vigore perché il mondo sta cambiando.
Attraverso la strumentazione, possiamo sentire più cose e, se riusciamo a sentirlo, tendiamo a cercare di conservarlo (o almeno una parte di esso). Attraverso i progressi nella tecnologia delle comunicazioni, le persone e le cose sono sempre più interconnesse, e non solo a volte, ma sempre. Questo tasso di interconnettività è un treno fuori controllo.. Generalmente noto come machine-to-machine (M2M ·), l'interconnettività è responsabile dei tassi di crescita dei dati a due cifre anno su anno (YoY).
Finalmente, perché i piccoli circuiti integrati sono ora così economici, possiamo aggiungere intelligenza a quasi tutto. Anche qualcosa di banale come un vagone ferroviario ha centinaia di sensori.. In un vagone ferroviario, Questi sensori tracciano cose come le condizioni vissute dal carro, lo stato delle singole parti e i dati basati su GPS per il monitoraggio e la logistica delle spedizioni. Dopo i deragliamenti dei treni che hanno causato pesanti perdite di vite umane, i governi hanno introdotto regolamenti per questo tipo di dati da archiviare e analizzare per prevenire disastri futuri.
Anche i vagoni ferroviari stanno diventando più intelligenti: sono stati aggiunti processori per interpretare i dati dei sensori sulle parti soggette a usura, come i cuscinetti, per identificare le parti che necessitano di riparazione prima che si guastino e causino ulteriori danni, o peggio, un disastro. Ma non sono solo i vagoni ferroviari ad essere intelligenti., le rotaie reali hanno sensori ogni pochi metri. Cosa c'è di più, i requisiti di archiviazione dei dati sono per l'intero ecosistema: Auto, Binario, sensori per attraversamenti ferroviari, modelli meteorologici che causano movimenti ferroviari, eccetera.
Ora aggiungi questo per tenere traccia del carico di un vagone ferroviario, orari di arrivo e partenza, e sarai in grado di vedere molto rapidamente che hai un problema di Big Data tra le mani. Anche se ogni bit di questi dati era relazionale (e non lo è), tutto sarà grezzo e avrà formati molto diversi, il che rende impraticabile o impossibile elaborarli in un sistema relazionale tradizionale. I carri sono solo un esempio, ma ovunque guardiamo, vediamo i domini con velocità, volume e varietà che si combinano per creare il problema dei Big Data.
Quali sono le caratteristiche dei Big Data?
Tre caratteristiche definiscono i Big Data: volume, varietà e velocità.
Insieme, Queste caratteristiche definiscono "Big Data". Hanno creato la necessità di una nuova classe di capacità per aumentare il modo in cui le cose vengono fatte oggi per fornire una migliore linea di vista e controllo sui nostri domini di conoscenza esistenti e la capacità di agire su di essi..
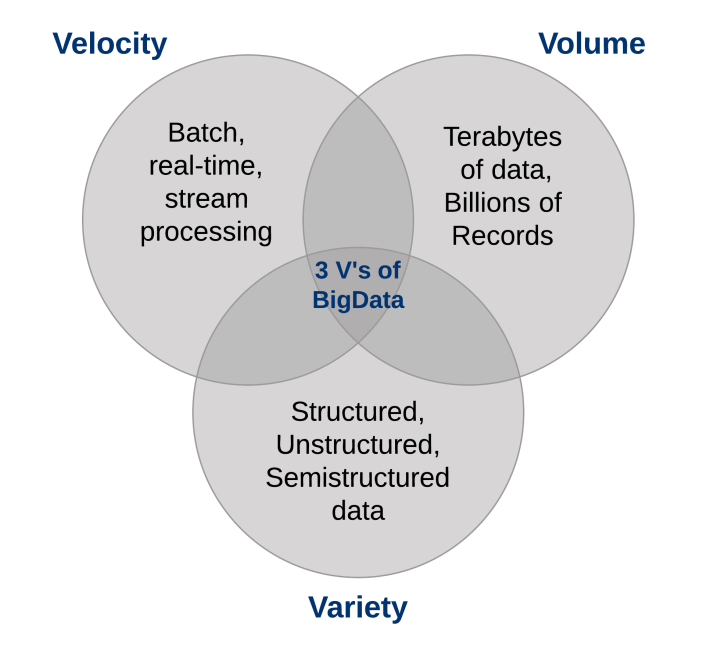
1. Il volume di dati
L'enorme volume di dati archiviati oggi è alle stelle. Nell'anno 2000, sono stati memorizzati 800.000 fornendo vantaggi come i seguenti (PB) di dati nel mondo. Certo, molti dei dati che vengono creati oggi non vengono analizzati affatto e questo è un altro problema che deve essere preso in considerazione.. Si prevede che questo numero raggiunga 35 zettabyte (Zb) per 2020. Twitter genera solo più di 7 terabyte (TB) di dati ogni giorno, Facebook 10 TB e alcune aziende generano terabyte di dati ogni ora di ogni giorno dell'anno. Non è più raro che le singole aziende dispongano di cluster di storage contenenti petabyte di dati..

Quando ti fermi e ci pensi, è un po' strano che stiamo annegando nei dati. Conserviamo tutto: dati ambientali, dati finanziari, dati medici, dati di monitoraggio e l'elenco potrebbe continuare all'infinito. Ad esempio, togliere lo smartphone dalla custodia genera un evento; quando la porta del treno dei pendolari si apre per salire a bordo, è un evento; registrarsi per prendere un aereo, entra nel lavoro, acquista una canzone su iTunes, cambiare il canale TV, prendere un pedaggio elettronico: Ognuna di queste azioni genera dati.
Concordare, hai capito il punto: ci sono più dati che mai e tutto ciò che devi fare è guardare il tasso di penetrazione dei terabyte per i personal computer in casa come un segno rivelatore.. Eravamo soliti tenere un elenco di tutti gli archivi dati di cui eravamo a conoscenza che superavano i terabyte quasi un decennio fa.; basti pensare che le cose sono cambiate per quanto riguarda il volume..
Come implicito dal termine “Grandi dati”, le organizzazioni devono affrontare enormi volumi di dati. Le organizzazioni che non sanno come gestire questi dati ne sono sopraffatte.. Ma c'è l'opportunità, con la giusta piattaforma tecnologica, per analizzare quasi tutti i dati (o almeno più di loro identificando i dati che ti sono utili) per ottenere una migliore comprensione della tua attività, i tuoi clienti e il mercato. E questo porta all'attuale enigma che le aziende di oggi devono affrontare in tutti i settori..
Con l'aumentare della quantità di dati a disposizione dell'azienda, la percentuale di dati che è possibile elaborare, la comprensione e l'analisi sono in declino, creando così la zona cieca.
Cosa c'è in quella zona cieca?
Non lo sai: può essere una grande cosa o forse niente di niente, ma "Non lo so" è il problema (o l'opportunità, a seconda di come lo guardi). La conversazione sui volumi di dati si è spostata da terabyte a petabyte con un inevitabile passaggio a zettabyte, e tutti questi dati non possono essere memorizzati nei vostri sistemi tradizionali.
2. La varietà di dati
Il volume associato al fenomeno dei Big Data porta con sé nuove sfide per i data center che cercano di affrontarlo.: la sua varietà.
Con l'esplosione di sensori e dispositivi intelligenti, così come le tecnologie di collaborazione sociale, i dati in un'azienda sono diventati complessi, perché includono non solo dati relazionali tradizionali, ma anche dati grezzi, pagine web semi-strutturate e non strutturate, file di weblog (inclusi i dati clickstream), indici di ricerca, forum sui social media, E-mail, documenti, dati dei sensori da sistemi attivi e passivi, eccetera.
Cosa c'è di più, i sistemi tradizionali possono avere difficoltà a memorizzare ed eseguire le analisi necessarie per comprendere il contenuto di questi record perché gran parte delle informazioni generate non si prestano alle tecnologie di database tradizionali.. Nella mia esperienza, anche se alcune aziende si stanno muovendo in avanti sulla strada, generalmente, la maggior parte sta appena iniziando a capire le opportunità dei Big Data.
In poche parole, La varietà rappresenta tutti i tipi di dati: un cambiamento fondamentale nei requisiti di analisi dei dati strutturati tradizionali per includere i dati grezzi, semi-strutturato e non strutturato come parte del processo decisionale e di conoscenza. Le piattaforme di analisi tradizionali non sono in grado di gestire la varietà. tuttavia, il successo di un'organizzazione dipenderà dalla sua capacità di estrarre informazioni dai vari tipi di dati disponibili., che includono sia tradizionale che non tradizionale.
Quando guardiamo indietro alle nostre carriere nei database, a volte è umiliante vedere che passiamo più del nostro tempo solo nel 20 percentuale di dati: il tipo relazionale che è perfettamente formattato e si adatta molto bene ai nostri schemi rigorosi. Ma la verità della questione è che il 80 percentuale dei dati mondiali (e sempre più di questi dati sono responsabili dell'impostazione di nuovi record di velocità e volume) non sono strutturati o, nel migliore dei casi, semi-strutturato. Se guardi un feed di Twitter, vedrai la struttura nel suo formato JSON, ma il testo effettivo non è strutturato e la comprensione può essere gratificante.
Le immagini e le immagini video non vengono archiviate in modo semplice o efficiente in un database relazionale, Alcune informazioni sugli eventi possono cambiare dinamicamente (come i modelli meteorologici), ciò che non è adatto per schemi rigorosi, e altro ancora. Capitalizzare l'opportunità dei Big Data, le aziende devono essere in grado di analizzare tutti i tipi di dati, sia relazionale che non relazionale: testo, dati del sensore, Audio, video, transazionale e altro ancora.
3. La velocità dei dati
Proprio come il volume e la varietà di dati che raccogliamo e il negozio sono cambiati., Ha anche cambiato la velocità con cui vengono generati e devono essere gestiti. Una comprensione convenzionale della velocità di solito considera la velocità con cui i dati arrivano e si memorizzano., e i relativi tassi di recupero. Mentre gestire tutto questo rapidamente è buono., e i volumi di dati che stiamo vedendo sono una conseguenza della velocità con cui i dati arrivano.
Per adattarsi alla velocità, un nuovo modo di pensare a un problema deve iniziare dal punto di partenza dei dati. Invece di limitare l'idea di velocità ai tassi di crescita associati ai tuoi archivi di dati, Ti suggeriamo di applicare questa definizione ai dati in movimento: la velocità con cui i dati fluiscono.
Dopotutto, siamo d'accordo sul fatto che le aziende di oggi hanno a che fare con petabyte di dati invece di terabyte, e l'aumento dei sensori RFID e di altri flussi di informazioni ha portato a un flusso costante di dati a un ritmo che ha reso impossibile per i sistemi tradizionali. maneggiare. Qualche volta, guadagnare un vantaggio sulla concorrenza può significare identificare una tendenza, problema o opportunità solo pochi secondi, o anche microsecondi, prima di qualcun altro.
Cosa c'è di più, sempre più dati che vengono prodotti oggi hanno una vita utile molto breve, quindi le organizzazioni devono essere in grado di analizzare questi dati quasi in tempo reale se si aspettano di trovare informazioni preziose in questi dati.. Nella lavorazione tradizionale, può pensare di eseguire query con dati relativamente statici: ad esempio, la domanda “Mostrami tutte le persone che vivono nella zona di inondazione ABC” risulterebbe in un singolo set di risultati che verrebbe utilizzato come elenco di avviso di un meteo in arrivo. Modello. Con il flow computing, È possibile eseguire un processo simile a una query continua che identifica le persone che si trovano attualmente in “nelle zone di inondazione ABC”, ma si ottengono risultati continuamente aggiornati perché le informazioni sulla posizione dai dati GPS vengono aggiornate in tempo reale.
Gestire efficacemente i Big Data richiede di eseguire analisi rispetto al volume e alla varietà di dati mentre sono ancora in movimento, non solo dopo che sono a riposo. Considera esempi dal monitoraggio della salute neonatale ai mercati finanziari; in tutti i casi, richiedono la gestione del volume e della varietà di dati in modi nuovi.
Note finali
Non puoi permetterti di esaminare tutti i dati a tua disposizione nei tuoi processi tradizionali; sono troppi dati con troppo poco valore noto e troppi costi scommessi. Le piattaforme Big Data ti offrono un modo per archiviare ed elaborare economicamente tutti quei dati e scoprire ciò che è prezioso e vale la pena sfruttare.. Cosa c'è di più, poiché parliamo di analisi dei dati a riposo e dati in movimento, I dati effettivi da cui è possibile trovare valore non sono solo più ampi, possono anche utilizzarli e analizzarli più rapidamente in tempo reale.
Ti consiglio di leggere questi articoli per familiarizzare con gli strumenti per i big data:
Fateci sapere i vostri pensieri nei commenti qui sotto..
Riferimento
Informazioni sui Big Data: Analisi per Hadoop di classe enterprise e flussi di dati.





