Questo post è stato pubblicato come parte del Blogathon sulla scienza dei dati
introduzione
En estadística aplicada y aprendizaje automático, Visualizzazione dati es una de las habilidades más importantes.
La visualización de datos proporciona un conjunto importante de herramientas para identificar una comprensión cualitativa. Esto puede ser útil cuando intentamos explorar el conjunto de datos y extraer información para conocer un conjunto de datos y puede ayudar con identificación de patrones, datos corruptos, Valori atipici, e altro ancora.
Si tenemos un poco de conocimiento del dominio, las visualizaciones de datos se pueden utilizar para expresar e identificar relaciones clave en gráficos y gráficos que sean más útiles para usted y las partes interesadas que las medidas de asociación o relevancia.
In questo post, discutiremos algunos de los gráficos básicos oh parcelas que puede usar para comprender y visualizar mejor sus datos.
Sommario
1. Cos'è la visualizzazione dei dati??
2. Beneficios de una buena visualización de datos
3. Diferentes tipos de análisis para la visualización de datos
4. Técnicas de análisis univariante para la visualización de datos
- Parcela de distribución
- Diagrama de caja y bigotes
- Cornice per violino
5. Técnicas de análisis bivariado para la visualización de datos
- Grafico a linee
- Grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia....
- Grafico a dispersioneUn grafico a dispersione è una rappresentazione visiva che mostra la relazione tra due variabili numeriche utilizzando punti su un piano cartesiano. Ogni asse rappresenta una variabile, e la posizione di ciascun punto indica il suo valore in relazione ad entrambi. Questo tipo di grafico è utile per identificare i modelli, Correlazioni e tendenze nei dati, facilitare l'analisi e l'interpretazione delle relazioni quantitative....
Cos'è la visualizzazione dei dati??
La visualización de datos se establece como representación grafica que contiene el informazione e il dati.
Usando ítems visuales como grafica, graficas, e mappe, las técnicas de visualización de datos proporcionan una forma alcanzable de ver y comprender tendencias, valores atípicos y patrones en los datos.
Attualmente, tenemos muchos datos en nuestras manos, In altre parole, en el mundo de Grandi dati, las herramientas y las tecnologías de visualización de datos son cruciales para analizar cantidades masivas de información y tomar decisiones sustentadas en datos.
Se utiliza en muchas áreas como:
- Modelar eventos complejos.
- Visualizar fenómenos que no se pueden observar de forma directa, Che cosa patrones meteorológicos, condiciones médicas, oh relaciones matemáticas.
Beneficios de una buena visualización de datos
Dado que nuestros ojos pueden capturar los colores y patrones, perché, podemos identificar rápidamente la parte roja del azul, el cuadrado del círculo, nuestra cultura es visual, che include tutto, desde el arte y los anuncios hasta la televisión y las películas.
Quindi, la visualización de datos es otra técnica de arte visual que capta nuestro interés y mantiene nuestro enfoque principal en el mensaje capturado con la ayuda de los ojos.
Siempre que visualizamos un gráfico, identificamos rápidamente las tendencias y valores atípicos presentes en el conjunto de datos.
Los usos básicos de la técnica de visualización de datos son los siguientes:
- Es una técnica poderosa para explorar los datos con presentable e interpretable risultati.
- In procedimiento de minería de datos, actúa como un paso principal en la parte de preprocesamiento.
- Es compatible con procedimiento de limpieza de datos encontrando datos incorrectos y valores dañados o faltantes.
- Además ayuda a construir y elegir variables, lo que significa que tenemos que determinar qué variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... incluir y descartar en el análisis.
- En el procedimiento de Diminuzione dei dati, además juega un papel crucial al combinar las categorías.

Fonte immagine: Google Immagini
Diferentes tipos de análisis para la visualización de datos
Principalmente, existen tres tipos diferentes de análisis para la visualización de datos:
Analisi invariate: En el análisis univariado, usaremos una sola característica para analizar casi todas sus propiedades.
Analisi bivariata: Cuando comparamos los datos entre exactamente 2 caratteristiche, se conoce como análisis bivariado.
Analisi multivariabile: En el análisis multivariado, voluntad estar comparando más de 2 variabili.
NOTA:
In questo post, nuestro principal objetivo es comprender los siguientes conceptos:
- ¿Cómo hallar algunas inferencias de las técnicas de visualización de datos?
- ¿En qué condición, qué técnica es más útil que otras?
No vamos a profundizar en la parte de codificación / implementación de diferentes técnicas en un conjunto de datos en particular, pero intentamos hallar la solución a las preguntas anteriores y comprender solo el código del fragmento con la ayuda de diagramas de muestra para cada una de las técnicas de visualización de datos. .
Ora, comencemos con las diferentes técnicas de visualización de datos:
Técnicas de análisis univariante para la visualización de datos
1. Parcela de distribución
- Es uno de los mejores gráficos univariados para conocer la distribución de datos.
- Cuando queremos analizar el impacto en la variable objetivo (Uscita) con respecto a una variable independiente (iscrizione), usamos mucho las gráficas de distribución.
- Esta gráfica nos da una combinación de funciones de densidad de probabilidad (PDF) e histograma en una sola gráfica.
Implementazione:
- La gráfica de distribución está presente en el Seaborn pacchetto.
El fragmento de código es el siguiente:
sns.FacetGrid(hb,tonalità="SurvStat",size=5).carta geografica(sns.distplot,'età').aggiungi_leggenda()
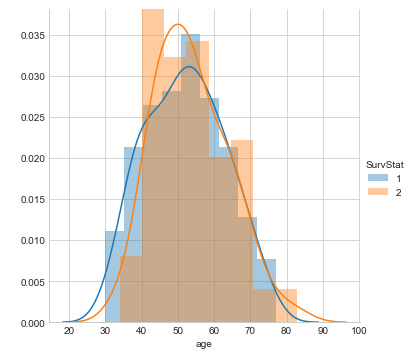
Algunas conclusiones inferidas del diagrama de distribución anterior:
De la gráfica de distribución anterior podemos concluir las siguientes observaciones:
- Hemos observado que creamos una gráfica de distribución en la característica 'Età’(variable de entrada) y usamos diferentes colores para la stato di sopravvivenza(variable de salida) puesto que es la clase a predecir.
- Existe una gran área de superposición entre los PDF para diferentes combinaciones.
- In questo grafico, las estructuras afiladas en forma de bloque se denominan istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... y la curva suavizada se conoce como función de densidad de probabilidad (PDF).
NOTA:
La funzione di densità di probabilità (PDF) de una curva puede ayudarnos a capturar la distribución subyacente de esa característica, que es una de las principales conclusiones de la visualización de datos o el análisis exploratorio de datos (EDA).
2. Diagrama de caja y bigotes
- Este gráfico se puede usar para obtener más detalles estadísticos sobre los datos.
- Las rectas en el máximo y mínimo además se denominan bigotes.
- Los puntos que se encuentran fuera de los bigotes se considerarán un valor atípico.
- El diagrama de caja además nos da una descripción de la quartili 25, 50, 75.
- Con la ayuda de un diagrama de caja, además podemos determinar el Intervallo interquartile (IQR) donde estarán presentes los máximos detalles de los datos. Perché, además puede darnos una idea clara sobre los valores atípicos en el conjunto de datos.
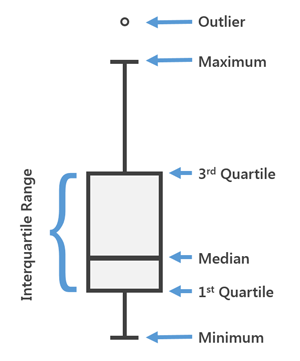
Fig. Diagrama general para un diagrama de caja
Implementazione:
- Boxplot está habilitada en Seaborn Biblioteca.
- Aquí x se considera como la variable dependiente e y se considera como la variable independiente. Queste box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati.... vienen debajo análisis univariado, lo que significa que estamos explorando datos solo con una variable.
- Aquí estamos tratando de verificar el impacto de una característica llamada “Axil_nodes” en la clase nombrada “stato di sopravvivenza” y no entre dos características independientes.
El fragmento de código es el siguiente:
sns.boxplot(x='SurvStat',y='axil_nodes',data=hb)
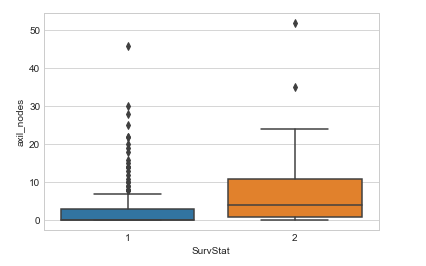
Algunas conclusiones inferidas del diagrama de caja anterior:
Del diagrama de caja y bigotes anterior podemos concluir las siguientes observaciones:
- Cuántos datos están presentes en el primer cuartil y cuántos puntos son valores atípicos, eccetera.
- Per la classe 1, podemos ver que hay muy pocos o ningún dato presente entre la medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... y el primer cuartil.
- Hay más valores atípicos para la clase 1 en la característica denominada axil_nodes.
NOTA:
Podemos obtener detalles sobre los valores atípicos que nos ayudarán a preparar bien los datos antes de enviarlos a un modelo, puesto que los valores atípicos influyen en muchos modelos de aprendizaje automático.
3. Cornice per violino
- Las parcelas de violín se pueden considerar como una combinación de parcelas de caja en el medio y parcelas de distribución(Estimación de la densidad del grano) en ambos lados de los datos.
- Esto puede darnos la descripción de la distribución del conjunto de datos como si la distribución es multimodal, Obliquitàeccetera.
- Además nos brinda información útil como Intervalo de confianza del 95%.
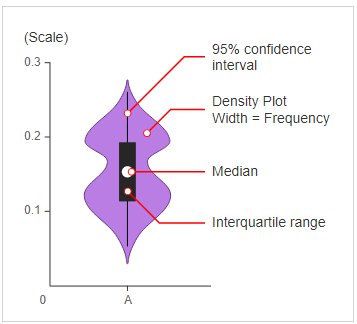
Fig. Diagrama general para una trama de violín
Implementazione:
- La trama del violín está presente en el Seaborn pacchetto.
El fragmento de código es el siguiente:
sns.violinplot(x='SurvStat',y='op_yr',data=hb,size=6)
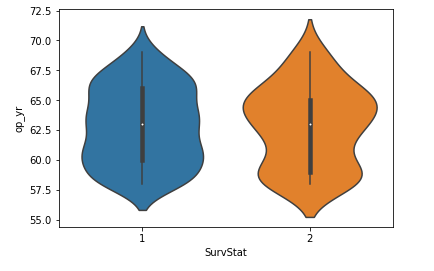
Algunas conclusiones inferidas de la trama de violín anterior:
De la trama de violín anterior podemos concluir las siguientes observaciones:
- La mediana de ambas clases se acerca a 63.
- El número máximo de personas con clase 2 avere un op_yr valor de 65 mentre, para las personas de la clase 1, el valor máximo es de alrededor de 60.
- Allo stesso tempo, el tercer cuartil a la mediana tiene un número menor de puntos de datos que la mediana al primer cuartil.
Técnicas de análisis bivariado para la visualización de datos
1. Grafico a linee
- Esta es la gráfica que se puede ver en los rincones de cualquier tipo de análisis entre 2 variabili.
- Los gráficos de líneas no son más que los valores de una serie de puntos de datos que se conectarán con líneas rectas.
- La trama puede parecer muy simple pero tiene más aplicaciones no solo en el aprendizaje automático sino en muchas otras áreas.
Implementazione:
- La gráfica de línea está presente en el Matplotlib pacchetto.
El fragmento de código es el siguiente:
plt.trama(X,e)
Algunas conclusiones inferidas del diagrama de líneas anterior:
Rinomina le colonne nella tabella Codice Hack 'M grafico a lineeIl grafico a linee è uno strumento visivo utilizzato per rappresentare i dati nel tempo. È costituito da una serie di punti collegati da linee, che permette di osservare le tendenze, Fluttuazioni e modelli nei dati. Questo tipo di grafico è particolarmente utile in aree come l'economia, Meteorologia e ricerca scientifica, semplificando il confronto di diversi set di dati e l'identificazione dei comportamenti su tutta la linea.. anterior podemos concluir las siguientes observaciones:
- Estos se usan de forma directa desde la realización de la comparación de distribución usando Parcelas QQ para sintonizar CV usando el metodo del gomito.
- Se utiliza para analizar el rendimiento de un modelo usando el curva ROC- AUC.
2. Grafico a barre
- Este es uno de los gráficos más utilizados, que hubiéramos visto varias veces no solo en el análisis de datos, sino que además usamos este gráfico siempre que haya un análisis de tendencias en muchos campos.
- Aún cuando parezca simple, es poderoso para analizar datos como cifras de ventas cada semana, ingresos de un producto, Número de visitantes de un sitio cada día de la semanaeccetera.
Implementazione:
- El gráfico de barras está presente en el Matplotlib pacchetto.
El fragmento de código es el siguiente:
plt.bar(X,e)
Algunas conclusiones inferidas del diagrama de barras anterior:
Del gráfico de barras anterior podemos concluir las siguientes observaciones:
- Podemos visualizar los datos en una trama genial y podemos transmitir los detalles de forma directa a los demás.
- Esta gráfica puede ser simple y clara, pero no se utiliza con mucha frecuencia en aplicaciones de ciencia de datos.
3. Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate....
- Es uno de los gráficos más utilizados para visualizar datos simples en el aprendizaje automático y la ciencia de datos.
- Esta gráfica nos describe como una representación, donde cada punto en el conjunto de datos completo está presente con respecto a 2 oh 3 caratteristiche (colonne).
- Los diagramas de dispersión están disponibles tanto en 2-D como en 3-D. El gráfico de dispersión 2-D es el más común, donde principalmente trataremos de hallar los patrones, grupos y separabilidad de los datos.
Implementazione:
- El diagrama de dispersión está presente en el Matplotlib pacchetto.
El fragmento de código es el siguiente:
plt.scatter(X,e)
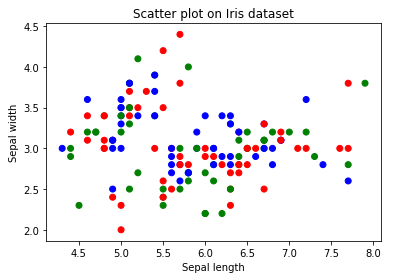
Algunas conclusiones inferidas del diagrama de dispersión anterior:
Del diagrama de dispersión anterior podemos concluir las siguientes observaciones:
- Los colores se asignan a diferentes puntos de datos en función de cómo estaban presentes en el conjunto de datos. In altre parole, representación de la columna de destino.
- Podemos colorear los puntos de datos según su etiqueta de clase dada en el conjunto de datos.
Questo completa la discussione di oggi!!
Note finali
Grazie per aver letto!
Espero que haya disfrutado del post y haya aumentado sus conocimientos sobre las técnicas de visualización de datos.
Per favore sentiti libero di contattarmi su E-mail
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Para los posts restantes, Chiedi a Collegamento.
Circa l'autore
Aashi Goyal
A quest'ora, Sto perseguendo il mio Bachelor of Technology (B.Tech) in Ingegneria Elettronica e delle Comunicazioni da Universidad Guru Jambheshwar (GJU), Hisar. Sono molto entusiasta delle statistiche, apprendimento automatico e apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
I vostri suggerimenti e dubbi sono i benvenuti qui nella sezione commenti. Grazie per aver letto il mio post!!





