introduzione
Ciao a tutti per questa pratica introduzione all'apprendimento automatico che utilizza una semplice regressione lineare.. Allora cominciamo:
Quindi, familiarizziamo con i termini che verranno utilizzati:
Apprendimento automatico (ML): ML è un'applicazione di intelligenza artificiale (LUI) che offre ai sistemi la capacità di apprendere e migliorare automaticamente dall'esperienza senza essere esplicitamente programmati. ML si concentra sullo sviluppo di programmi per computer in grado di accedere ai dati e utilizzarli per apprendere da soli.
Set di dati: Una raccolta di insiemi di informazioni correlate che è composta da elementi separati ma che può essere manipolata come unità da un computer.
Visualizzazione dati: È una rappresentazione di dati o informazioni in un grafico, grafico o altri formati visivi utili per l'analisi, come l'analisi predittiva, che può servire come utile visualizzazione per presentare.
Pulizia dei dati: È il processo di correzione o rimozione di dati errati, corrotto, formattato in modo errato, duplicati o incompleti all'interno di un set di dati.
Apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in...: Il modello viene addestrato utilizzando "dati con tag". Se dice que los conjuntos de datos contienen etiquetas que contienen parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de entrada y salida. Per semplificare: 'I dati sono già contrassegnati con la risposta corretta'.
Regressione lineare semplice: Es un Modelo de Regresión que estima la relación entre la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... independiente y la variable dependiente usando una línea recta [y = mx + C], dove entrambe le variabili devono essere quantitative.
Modelli: I risultati sono ottenuti utilizzando algoritmi e sono composti dai dati del modello e da un algoritmo di previsione..
Modello di addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....: Nell'apprendimento supervisionato, un algoritmo ML crea un modello esaminando molti esempi e cercando di trovare un modello che riduca al minimo la perdita e migliori l'accuratezza della previsione.
Questi sono i pochi termini che vengono utilizzati in questo articolo e con cui familiarizzare. Ora iniziamo con l'analisi e la previsione del modello. In questo tutorial, Userò dati supervisionati e una semplice regressione lineare per l'analisi e la previsione. L'obiettivo finale è prevedere l'altezza di una persona e fornire la sua età utilizzando il modello addestrato nel modo più accurato possibile utilizzando i dati disponibili.. Ho usato il linguaggio di programmazione preferito universale per ML, vale a dire. Chiodo per costruire e addestrare il modello ML e l'ambiente Google Colab.
I passaggi coinvolti sono:
1. Importazione di set di dati.
2. Visualizzazione dati
3. Pulizia dei dati
4. Costruisci il modello e addestralo
5.Fare previsioni su dati invisibili
————————————————————————————————————————————————— ————————
1. Importazione di set di dati:
La prima e più importante cosa da fare è importare il set di dati. Abbiamo diversi siti Web che hanno questi set di dati che possono essere utilizzati da chiunque. Allo stesso modo, iniziamo come importare il set di dati che useremo in questo tutorial.

Questa singola riga di codice ci aiuta a ottenere i dati utilizzati per il tutorial direttamente dall'URL.
Set di dati <- Fare clic sul collegamento per ottenere il set di dati che è l'URL menzionato sopra.
2. Visualizzazione dati:
In questo passaggio, dopo aver importato i dati e averli montati con Colab, diamo una panoramica del set di dati importando un modulo chiamato panda. Poiché il set di dati che abbiamo ha un'estensione di .pkl, lo vediamo solo dalla funzione disponibile nella libreria dei panda.

Importiamo la libreria per leggere il dataset e archiviarlo in una variabile chiamata raw_data. Quindi mostriamo il contenuto di raw_data che è in formato tabulato.
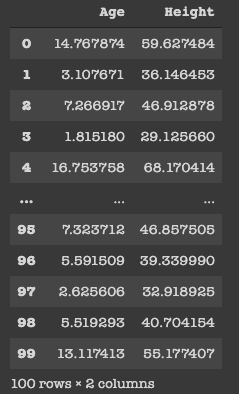
Possiamo vedere solo i dati che abbiamo e contengono 2 colonne, vale a dire, Età (in anni) e altezza (in pollici) e 100 righe, che in realtà è la rappresentazione di una persona.
Questa singola riga di codice ha un enorme impatto sul modo in cui guardiamo il set di dati. Avevamo solo una visualizzazione numerica del set di dati, ma ora possiamo eseguire questa cella per ottenere una visualizzazione dell'istogramma del set di dati, che è molto utile. Rappresenta i dati presenti nelle singole colonne come grafici individuali.
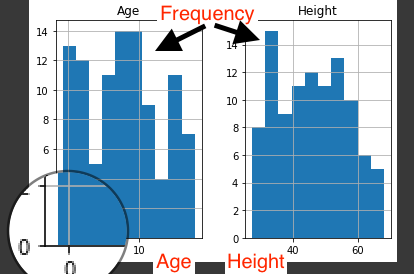
L'asse Y in entrambi i grafici si riferisce alla frequenza e l'asse X rappresenta rispettivamente l'età e l'altezza..
3. Pulizia dei dati:
Dobbiamo costruire il modello utilizzando set di dati validi e pulire i dati che non dovrebbero essere presi in considerazione. Nella foto sopra, possiamo sapere che ci sono alcune voci che hanno un'età inferiore a zero, che non ha senso. Perciò, dobbiamo pulire quei dati per ottenere una maggiore precisione.

io uso variabile data_cleaned per memorizzare valori di età validi e mostrarli all'utente.
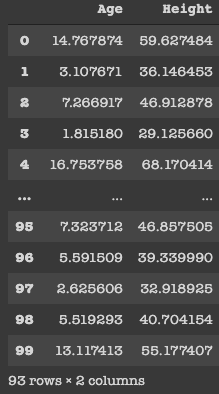
Inizialmente, abbiamo avuto 100 righe, ma dopo aver pulito i dati, è abbastanza chiaro che ci sono sette righe che hanno avuto un'età <0 e li abbiamo rimossi. Da professionista, non dovremmo cancellare i dati, visto che li stiamo riducendo e, così, la precisione del nostro modello è ridotta. Per mantenerlo semplice, li ho appena cancellati.
Visualizza i dati puliti: ora ho usato i dati puliti e li ho visualizzati come un grafico.
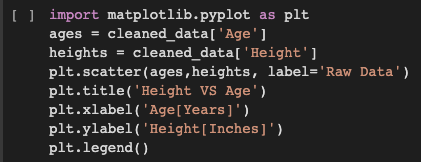
Per tracciare la grafica Python, importo la biblioteca matplotlib.pyplot. Rappresento l'età sull'asse X e l'altezza sull'asse Y. I punti sul grafico si riferiscono ai dati grezzi.
4. Costruisci il modello e addestralo:
È qui che entra in gioco l'algoritmo ML., vale a dire, regressione lineare semplice.
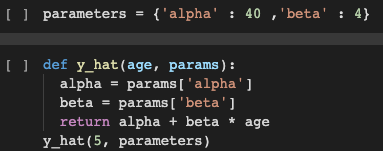
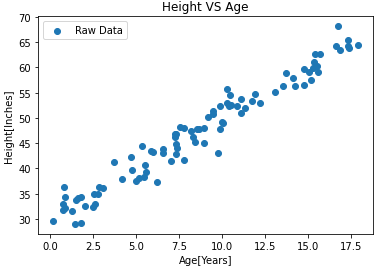
Ho usato un dizionario chiamato parametri che ha alfa e beta come chiave con 40 e 4 come valori rispettivamente. Ho anche definito una funzione y_hat che prende età e parametri come parametri. Questa funzione utilizza l'equazione di base in linea retta e restituisce y, vale a dire, altezza come nel nostro caso. Se passiamo i parametri richiesti ed eseguiamo la funzione, troviamo che l'altezza che otteniamo per l'età come input non corrisponde. Perciò, usiamo la funzione sotto menzionata per far piovere il modello.
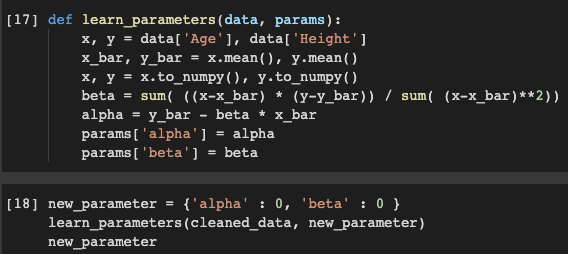
Qui è dove usiamo un metodo per trovare l'alfa e la beta corretti. La funzione impara_parametri accetti data_cleaned e un dizionario fittizio nuovo_parametro che può avere qualsiasi valore per alfa e beta. Quindi, quando li passiamo come argomenti ai parametri e la funzione viene eseguita, possiamo ottenere il valore corretto di alfa e beta che è vicino a 30 e 2 rispettivamente e sostituire i vecchi valori con i nuovi.
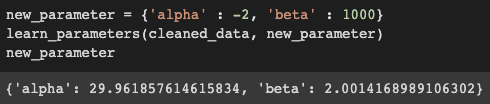
Abbiamo trovato con precisione i valori alfa e beta, e il nostro prossimo obiettivo è addestrare i dati. Ma fammi sapere quanto sono accurati i valori previsti non addestrati.

Uso una lista chiamata età_spaziali che ha valori di 0 un 18 (finale – 1). Poi un altro elenco chiamato spaced_untrained_predictions che ha i valori previsti per l'altezza utilizza il y_hat funzione definita sopra per prevederlo. Questi valori sono tracciati su un grafico e visualizzati.
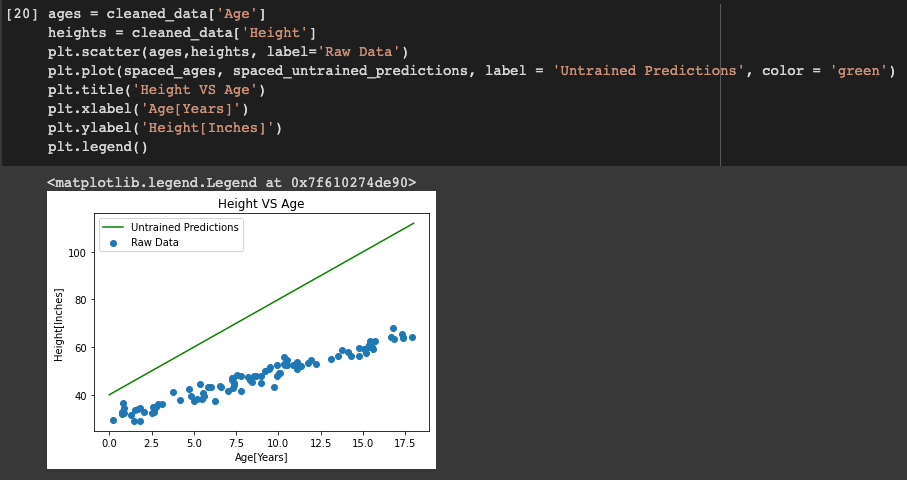
La linea verde mostra che spaced_untrained_predictions se han desviado en gran misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de los valores reales y la precisión es muy pobre. Perciò, è necessario aumentare la precisione per cui dobbiamo addestrare i dati.

Quindi invece di usare parametri noi usiamo nuovi_parametri poiché contiene il valore esatto di alfa e beta e lo memorizza in un elenco chiamato spaced_trained_predictions. Quindi, quando tracciamo un grafico per questo, possiamo vedere una differenza visibile e la precisione è aumentata molto. Perciò, abbiamo costruito e addestrato con successo il modello. Prova ne sono i valori di spaced_trained_predictions e il grafico.
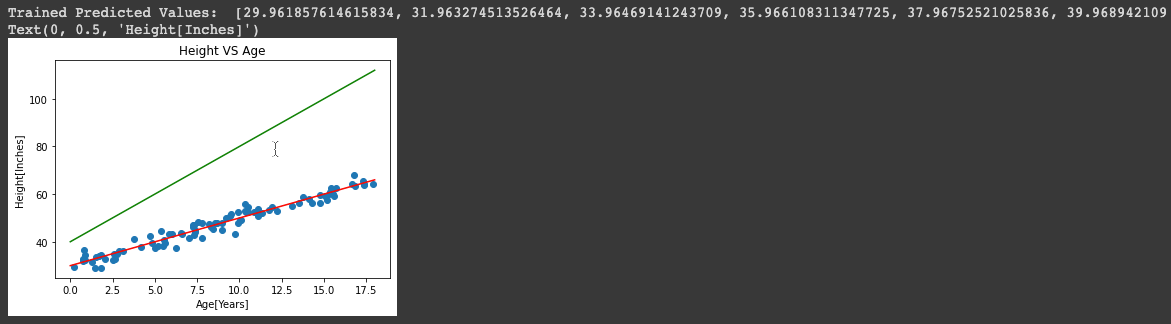
La Greenline si riferisce ai valori di spaced_untrained_predictions e Redline si riferisce ai valori di spaced_trained_predictions.
5.Fare previsioni su dati invisibili:
Con l'aiuto di questo modello addestrato, ora possiamo fare previsioni accurate.

Quindi, possiamo vedere che per ogni data età troviamo l'altezza possibile in pollici. Finalmente, abbiamo addestrato con successo e con precisione il modello, che è l'obiettivo finale di questo tutorial.
Come riferimento, ho incollato il Link al taccuino giochi con lui. Spero di connettermi attraverso LinkedIn anche tu e condividi i tuoi preziosi commenti. Resta sintonizzato per altri blog di questo tipo😊.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





