Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati

In questo articolo, Risponderemo a queste domande di base e costruiremo un neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. Base per eseguire la regressione lineare.
Cos'è una rete neurale?
L'unità di base del cervello è nota come neurone, ci sono circa 86 miliardi di neuroni nel nostro sistema nervoso che sono collegati a 10 ^ 14-10 ^ 15 sinapsi. meOgni neurone riceve un segnale dalle sinapsi e lo emette dopo aver elaborato il segnale.. Questa idea viene estratta dal cervello per costruire una rete neurale.
Ogni neurone realizza un prodotto scalare tra gli input e i pesi, aggiungere pregiudizi, applica un funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... ed emette i risultati. Quando un gran numero di neuroni sono presenti insieme per dare un gran numero di uscite, si forma uno strato neurale. Finalmente, più livelli si combinano per formare una rete neurale.
Architettura dei neuroni rossi
Le reti neurali si formano quando più strati neurali si combinano tra loro per dare una rete, oppure possiamo dire che ci sono dei layer i cui output sono input per altri layer.
Il tipo più comune di livello per costruire una rete neurale di base è il livello completamente connesso, in cui gli strati adiacenti sono completamente accoppiati e i neuroni a strato singolo non sono collegati tra loro.

Nel figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... anteriore, le reti neurali vengono utilizzate per classificare i punti dati in tre categorie.
Convenzioni di denominazione. Quando la rete neurale a strati N, Non contiamo il livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche..... Perciò, una rete neurale a strato singolo descrive una rete senza strati nascosti (l'input è mappato direttamente sull'output). Nel caso del nostro codice, useremo una rete neurale a strato singolo, vale a dire, non abbiamo un livello nascosto.
Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati..... A differenza di tutti i livelli in una rete neurale, i neuroni nello strato di output comunemente non hanno una funzione di scarica (oppure puoi pensare che abbiano una funzione di attivazione dell'identità lineare). Questo perché l'ultimo livello di output viene solitamente utilizzato per rappresentare i punteggi della classe (ad esempio, in classifica), che sono numeri arbitrari di valore reale o qualche tipo di obiettivo di valore reale (ad esempio, in regressione). Poiché stiamo eseguendo la regressione utilizzando un singolo livello, non abbiamo alcuna funzione di attivazione.
Dimensionamento della rete neurale. Le due metriche che le persone usano comunemente per misurare la dimensione delle reti neurali sono il numero di neuroni o, più comunemente, Il numero di parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.....
Biblioteche
Useremo tre librerie di base per questo modello, insensibile, matplotlib e TensorFlow.
- Numpy: questo aggiunge il supporto per array e array di grandi dimensioni e multidimensionali, insieme a una vasta collezione di funzioni matematiche di alto livello. Nel nostro caso, genereremo dati con l'aiuto di Numpy.
- Matplotlib: questa è una libreria di plottaggio per Python, visualizzeremo i risultati finali utilizzando grafici in Matplotlib.
- Tensorflow: Questa biblioteca si concentra in particolare sul addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e inferenza profonda della rete neurale. Possiamo importare direttamente i livelli e addestrare, funzioni di test senza dover scrivere l'intero programma.
importa numpy come np importa matplotlib.pyplot come plt import tensorflow come tf
Generazione di dati
Possiamo generare i nostri dati numerici per questo processo usando la funzione np.unifrom () che genera dati uniformi. Qui, stiamo usando due variabili di input xs e zs, aggiungendo un po' di rumore per randomizzare i punti dati e, Finalmente, il variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... L'obiettivo è definito come y = 2 * xs-3 * zs + 5 + rumore. La dimensione del set di dati è 1000.
osservazioni=1000 xs=np.random.uniform(-10,10,(osservazioni,1)) zs=np.random.uniform(-10,10,(osservazioni,1)) generate_inputs=np.column_stack((xs,zs)) noise=np.random.uniform(-10,10,(osservazioni,1)) target_generato=2*xs-3*zs+5+rumore
Dopo aver generato i dati, salvali in un file .npz, in modo che possano essere utilizzati per l'allenamento.
np. so('TF_intro',input=generated_inputs,target=bersaglio_generato)
training_data=np.load('TF_intro.npz')
Il nostro obiettivo è ottenere i pesi finali il più vicino possibile ai pesi effettivi., vale a dire [2,-3].
Definire il modello
Qui, Useremo il strato densoLo strato denso è una formazione geologica che si caratterizza per la sua elevata compattezza e resistenza. Si trova comunemente sottoterra, dove funge da barriera al flusso dell'acqua e di altri fluidi. La sua composizione varia, ma di solito include minerali pesanti, che gli conferisce proprietà uniche. Questo strato è fondamentale nell'ingegneria geologica e negli studi sulle risorse idriche, poiché influenza la disponibilità e la qualità dell'acqua.. per creare il modello e importare la goccia del gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... Keras Optimizer Stocastico.
Un gradiente è la pendenza di una funzione. Misura il grado di variazione di una variabile al variare di un'altra variabile. Matematicamente, la discesa del gradiente è una funzione convessa il cui output è la parziale derivazione di un insieme di parametri dai suoi input. Più alta è la pendenza, più ripida è la pendenza.
Partendo da un valore iniziale, Gradient Descent viene eseguito iterativamente per trovare i valori ottimali dei parametri per trovare il valore minimo possibile per la data funzione di costo. La parola “Stocastico” si riferisce a un sistema o processo di probabilità casuale. Perciò, en Discesa gradiente stocastico, alcuni campioni sono selezionati casualmente, invece del set di dati per ogni iterazione.
dato che, l'ingresso ha 2 variabili, dimensione dell'ingresso = 2 e dimensione di uscita = 1.
Impostiamo il tasso di apprendimento a 0.02, che non è né troppo alto né troppo basso, e il valore dell'epoca = 100.
input_size=2
output_size=1
modelli = tf.keras.Sequential([
tf.strati.duri.Densi(output_size)
])
custom_optimizer=tf.keras.optimizers.SGD(tasso_di apprendimento=0.02)
modelli.compila(ottimizzatore=ottimizzatore_personalizzato,perdita="mean_squared_error")
modelli.fit(training_data['ingresso'],training_data['obiettivi'],epoche=100,verbose=1)
Ottieni pesi e pregiudizi
Possiamo stampare i valori previsti di pesi e distorsioni e anche memorizzarli.
modelli.strati[0].get_pesi()
[Vettore([[ 1.3665189],
[-3.1609795]], dtype=float32), Vettore([4.9344487], dtype=float32)]
Qui, la prima matrice rappresenta i pesi e la seconda matrice rappresenta i pregiudizi. Possiamo vedere chiaramente che i valori previsti dei pesi sono molto vicini al valore effettivo dei pesi..
pesi=modelli.strati[0].get_pesi()[0] bias=modelli.strati[0].get_pesi()[1]
Previsione e precisione
Dopo la previsione utilizzando i pesi e i pregiudizi dati, un punteggio RMSE finale di 0.02866, che è piuttosto basso.
RMSE è definito come la radice dell'errore quadratico medio. La radice dell'errore quadratico medio prende la differenza per ogni valore osservato e previsto. La formula per l'errore RMSE è data come:
https://www.google.com/search?q=rmse+formula&oq=RMSE+forma&aqs=cromo.0.0i433j0j69i57j0l7.4779j0j7&sourceid=chrome&cioè=UTF-8
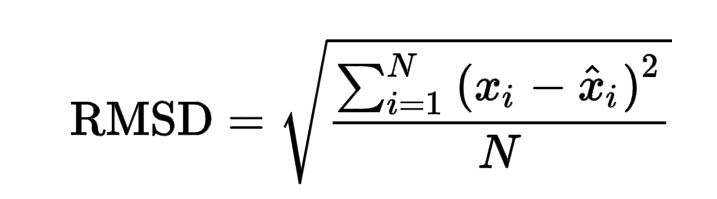
 |
|
|
|
 |
|
|
|
 |
|
|
|
 |
|
|
out=training_data['obiettivi'].il giro(1) da sklearn.metrics import mean_squared_error mean_squared_error(generato_target, fuori, quadrato=Falso)
Se tracciamo i dati previsti in un Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate...., otteniamo un grafico come questo:
plt.scatter(np.squeeze(models.predict_on_batch(training_data['ingresso'])),np.squeeze(training_data['obiettivi']),c="#88c999")
plt.xlabel('Ingresso')
plt.ylabel('Uscita prevista')
plt.mostra()
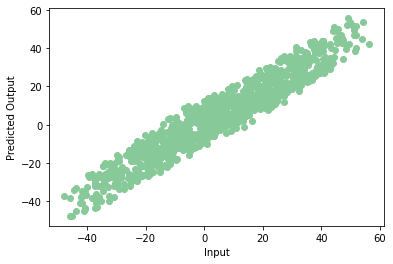
evviva! Il nostro modello è addestrato correttamente con pochissimi errori. Questa è la fine della tua prima rete neurale. Nota che ogni volta che addestriamo il modello possiamo ottenere un valore di precisione diverso, ma non differiranno molto.
Grazie per aver letto! Puoi contattarmi a [e-mail protetta]
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





