introduzione
Ogni appassionato di machine learning ha un sogno da costruire / lavorare su un progetto interessante, Non è così? La semplice comprensione della teoria non è sufficiente, è necessario lavorare su progetti, prova ad implementarli e impara da loro. Cosa c'è di più, lavorare in domini specifici come la PNL ti offre ampie opportunità e dichiarazioni di problemi da esplorare. Attraverso questo articolo, Voglio presentarvi un progetto fantastico, il modello di rilevamento della lingua utilizzando l'elaborazione del linguaggio naturale. Questo ti porterà attraverso un esempio del mondo reale di ML (app per dire). Quindi, non aspettiamo più.
Informazioni sul set di dati
Stiamo usando il Set di dati di rilevamento della lingua, contenente i dettagli del testo per 17 lingue differenti.
Le lingue sono:
* inglese
* portoghese
* francese
* greco
* olandese
* Español
* giapponese
* russo
* danese
* Italiano
* Turco
* svedese
* Arabica
* Malayalam
* hindi
* Tamil
* Telugu
Usando il testo dobbiamo creare un modello che sarà in grado di prevedere la lingua data. Questa è una soluzione per molte applicazioni di intelligenza artificiale e linguisti computazionali.. Questo tipo di sistemi di previsione sono ampiamente utilizzati nei dispositivi elettronici come i cellulari, computer portatili, eccetera. per la traduzione automatica e anche nei robot. Aiuta anche a tracciare e identificare documenti multilingue. Il dominio della PNL rimane un'area attiva per i ricercatori.
Implementazione
Importazione di librerie e set di dati
Allora cominciamo. Primo, importeremo tutte le librerie necessarie.
import pandas as pd
import numpy as np
import re
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter("ignorare")
Ahora importemos el conjunto de datos de detección de idioma
data = pd.read_csv("Language Detection.csv")
data.head(10)
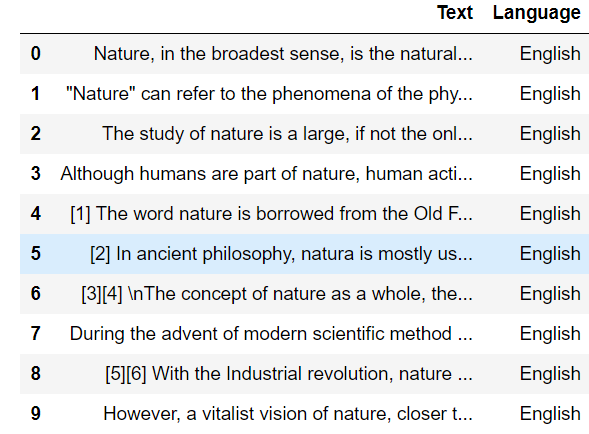
Como les dije anteriormente, este conjunto de datos contiene detalles de texto para 17 lingue differenti. Así que contemos el recuento de valores para cada idioma.
dati["Language"].value_counts()
Produzione :
English 1385 French 1014 Spanish 819 Portugeese 739 Italian 698 Russian 692 Sweedish 676 Malayalam 594 Dutch 546 Arabic 536 Turkish 474 German 470 Tamil 469 Danish 428 Kannada 369 Greek 365 hindi 63 Nome: Language, dtype: int64
Separazione di caratteristiche indipendenti e dipendenti
Ora possiamo separare le variabili dipendenti e indipendenti, aquí los datos de texto son la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... independiente y el nombre del idioma es la variable dependiente.
X = dati["Testo"]
y = dati["Language"]
Codifica etichetta
La nostra variabile di output, il nome delle lingue, è una variabile categoriale. Per addestrare il modello, dovremmo convertirlo in una forma numerica, quindi stiamo eseguendo la codifica dell'etichetta su quella variabile di output. Para este proceso, estamos importando LabelEncoder de sklearn.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() y = le.fit_transform(e)
Pre-elaborazione del testo
Este es un conjunto de datos creado usando el raspado de Wikipedia, por lo que contiene muchos símbolos no deseados, números que afectarán la calidad de nuestro modelo. Entonces deberíamos realizar técnicas de preprocesamiento de texto.
# creating a list for appending the preprocessed text data_list = [] # iterating through all the text for text in X: # removing the symbols and numbers text = re.sub(R'[[e-mail protetta]#$(),n"%^*?:;~`0-9]', ' ', testo) testo = re.sub(R'[[]]', ' ', testo) # converting the text to lower case text = text.lower() # appending to data_list data_list.append(testo)
Borsa di parole
Come sappiamo tutti, no solo la función de salida, sino también la función de entrada deben ser de forma numérica. Quindi, estamos convirtiendo texto en forma numérica creando un modelo de Bolsa de palabras usando CountVectorizer.
da sklearn.feature_extraction.text import CountVectorizer
cv = ContaVectorizer()
X = cv.fit_transform(data_list).toarray()
X.forma # (10337, 39419)
División de prueba de tren
Preprocesamos nuestra variable de entrada y salida. El siguiente paso es crear el conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., para entrenar el modelo y el conjunto de prueba, para evaluar el conjunto de prueba. Para este proceso, estamos usando una división de prueba de tren.
da sklearn.model_selection import train_test_split x_treno, x_test, y_train, y_test = train_test_split(X, e, test_size = 0.20)
Entrenamiento y predicción de modelos
Y ya casi llegamos, la parte de creación del modelo. Estamos utilizando el algoritmo naive_bayes para la creación de nuestro modelo. Posteriormente estamos entrenando el modelo usando el conjunto de entrenamiento.
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(x_treno, y_train)
Perché, hemos entrenado nuestro modelo con el conjunto de entrenamiento. Ahora vamos a predecir la salida del conjunto de prueba.
y_pred = model.predict(x_test)
Evaluación del modelo
Ahora podemos evaluar nuestro modelo
from sklearn.metrics import accuracy_score, confusione_matrice, classification_report ac = accuracy_score(y_test, y_pred) cm = confusion_matrix(y_test, y_pred) Stampa("Accuracy is :",ac) # Accuracy is : 0.9772727272727273
La precisión del modelo es 0,97, lo cual es muy bueno y nuestro modelo está funcionando bien. Ahora tracemos la matriz de confusión usando el mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... de seaborn.
plt.figure(figsize=(15,10)) sns.heatmap(cm, annot = Vero) plt.mostra()
El gráfico se verá así:

Al analizar cada idioma, casi todas las predicciones son correctas. Y si !! ya casi has llegado !!
Predecir con más datos
Ahora probemos la predicción del modelo usando texto en diferentes idiomas.
def predire(testo):
x = cv.transform([testo]).toarray() # converting text to bag of words model (Vector)
lang = model.predict(X) # predicting the language
lang = le.inverse_transform(lang) # finding the language corresponding the the predicted value
print("The langauge is in",lang[0]) # printing the language
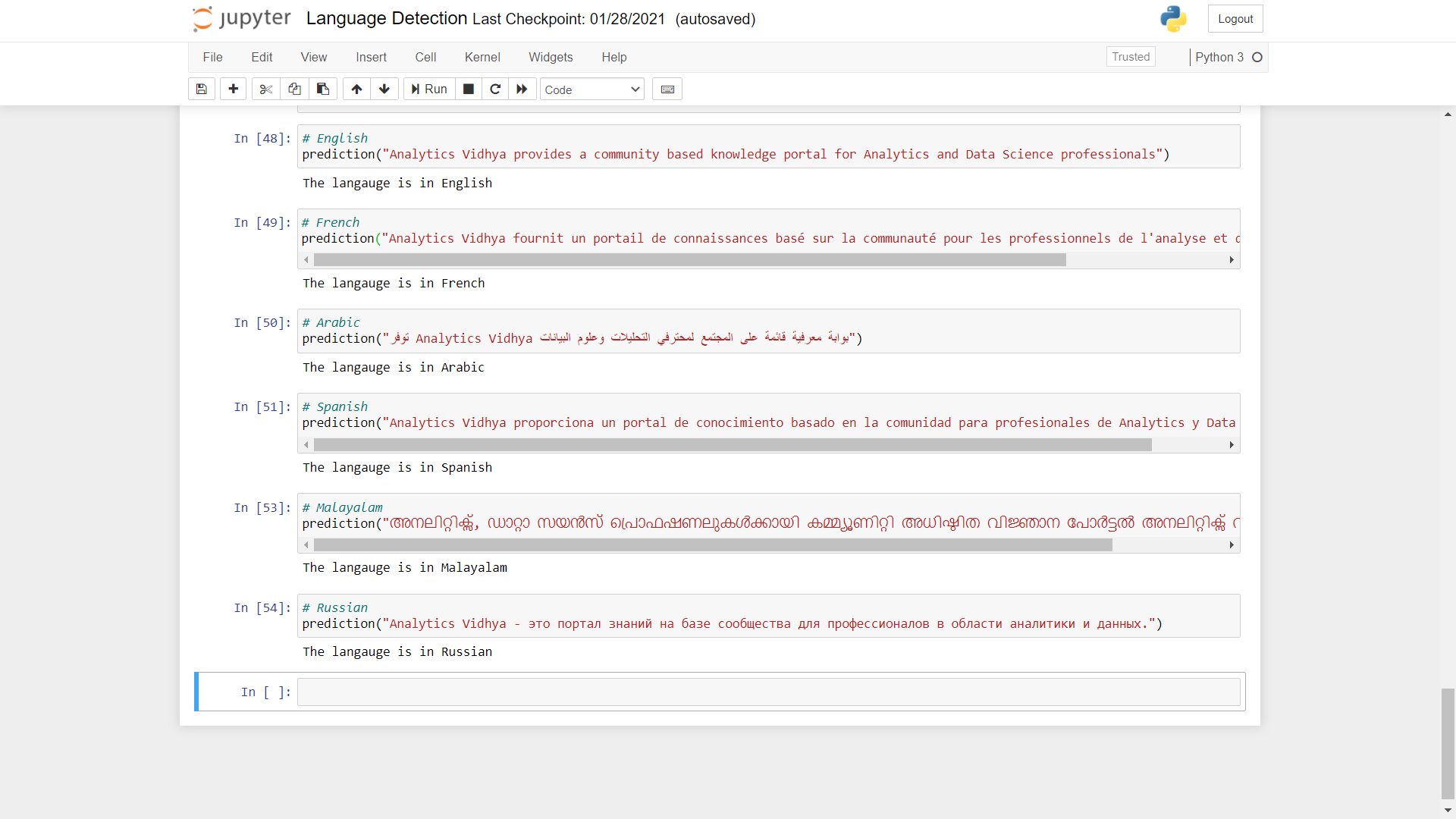
Come potete vedere, las predicciones realizadas por el modelo son muy precisas. Puede realizar la prueba utilizando otros idiomas diferentes.
Codice completo
import pandas as pd import numpy as np import re import seaborn as sns import matplotlib.pyplot as plt import warnings warnings.simplefilter("ignorare") # Loading the dataset data = pd.read_csv("Language Detection.csv") # value count for each language data["Language"].value_counts() # separating the independent and dependant features X = data["Testo"] y = dati["Language"] # converting categorical variables to numerical from sklearn.preprocessing import LabelEncoder le = LabelEncoder() y = le.fit_transform(e) # creating a list for appending the preprocessed text data_list = [] # iterating through all the text for text in X: # removing the symbols and numbers text = re.sub(R'[[e-mail protetta]#$(),n"%^*?:;~`0-9]', ' ', testo) testo = re.sub(R'[[]]', ' ', testo) # converting the text to lower case text = text.lower() # appending to data_list data_list.append(testo) # creating bag of words using countvectorizer from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() X = cv.fit_transform(data_list).toarray() #train test splitting from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(X, e, test_size = 0.20) #model creation and prediction from sklearn.naive_bayes import MultinomialNB model = MultinomialNB() model.fit(x_treno, y_train) # prediction y_pred = model.predict(x_test) # model evaluation from sklearn.metrics import accuracy_score, confusion_matrix ac = accuracy_score(y_test, y_pred) cm = confusion_matrix(y_test, y_pred) # visualising the confusion matrix plt.figure(figsize=(15,10)) sns.heatmap(cm, annot = Vero) plt.mostra() # function for predicting language def predict(testo): x = cv.transform([testo]).toarray() lang = model.predict(X) lang = le.inverse_transform(lang) Stampa("The langauge is in",lang[0]) # English prediction("DataPeaker provides a community based knowledge portal for Analytics and Data Science professionals") # French prediction("DataPeaker fournit un portail de connaissances basé sur la communauté pour les professionnels de l'analyse et de la science des données") # Arabic prediction("توفر DataPeaker بوابة معرفية قائمة على المجتمع لمحترفي التحليلات وعلوم البيانات") # Spanish prediction("DataPeaker proporciona un portal de conocimiento basado en la comunidad para profesionales de Analytics y Data Science.") # Malayalam prediction("അനലിറ്റിക്സ്, ഡാറ്റാ സയൻസ് പ്രൊഫഷണലുകൾക്കായി കമ്മ്യൂണിറ്റി അധിഷ്ഠിത വിജ്ഞാന പോർട്ടൽ അനലിറ്റിക്സ് വിദ്യ നൽകുന്നു") # Russian prediction("DataPeaker - это портал знаний на базе сообщества для профессионалов в области аналитики и данных.")
conclusione
Ese fue un proyecto interesante, verità? Espero que haya tenido una intuición sobre cómo se resuelven estos proyectos. Questo ti avrebbe sicuramente fornito un diagramma dei programmi di base di PNL. È necessario analizzare i dati e preelaborarli di conseguenza. Un modello di borsa di parole diventa un modo per rappresentare i tuoi dati di testo. L'estrazione e la vettorizzazione del testo sono passaggi importanti per fare buone previsioni in PNL. Naive Bayes si dimostra sempre un modello migliore in tali problemi di classificazione del testo, così otteniamo risultati più accurati.
Puoi anche trovare il progetto completo dall'inizio alla fine per il modello di rilevamento della lingua sopra in my Github
Grazie per aver mostrato interesse per il progetto., spero che tu continui con progetti più sorprendenti e conosci le affermazioni dei problemi della vita reale. Sentiti libero di connetterti con me su LinkedIn.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





