Il mondo del rilevamento di oggetti
Adoro lavorare nello spazio del deep learning. Francamente, è un vasto campo con una pletora di tecniche e strutture da analizzare e apprendere. E la vera emozione di modellare la visione artificiale e il deep learning arriva quando vedo applicazioni del mondo reale come il riconoscimento facciale e il tracciamento della palla nel cricket., tra l'altro.
E uno dei miei concetti preferiti di visione artificiale e deep learning è il rilevamento degli oggetti.. La capacità di costruire un modello che possa passare attraverso le immagini e dirmi quali oggetti sono presenti, È una sensazione impagabile!

Quando gli umani guardano un'immagine, riconosciamo l'oggetto di interesse in pochi secondi. Questo non è il caso delle macchine. Perciò, il rilevamento di oggetti è un problema di visione artificiale per individuare istanze di oggetti in un'immagine.
Questa è la buona notizia: le applicazioni di rilevamento degli oggetti sono più facili che mai da sviluppare. Gli attuali approcci odierni si concentrano sulla pipeline end-to-end che ha notevolmente migliorato le prestazioni e ha anche aiutato a sviluppare casi d'uso in tempo reale.
In questo articolo, Ti illustrerò come creare un modello di rilevamento di oggetti utilizzando la popolare API TensorFlow. Se sei un principiante del deep learning, computer vision e il mondo del rilevamento degli oggetti, Ti consiglio di consultare le seguenti risorse:
Sommario
- Un quadro generale per il rilevamento degli oggetti
- Che cos'è un'API? Perché abbiamo bisogno di un'API?
- API di rilevamento oggetti TensorFlow
Un quadro generale per il rilevamento degli oggetti
Normalmente, seguiamo tre passaggi durante la creazione di un framework di rilevamento degli oggetti:
- Primo, un algoritmo o modello di deep learning viene utilizzato per generare un ampio set di riquadri di delimitazione che coprono l'intera immagine (vale a dire, un componente di ricerca oggetto)

- Prossimo, le caratteristiche visive vengono estratte per ciascuno dei riquadri di delimitazione. Si valutano e si determina se e quali oggetti sono presenti nelle scatole in base alle caratteristiche visive (vale a dire, un componente di classificazione degli oggetti)

- Nell'ultimo passaggio di post-elaborazione, i riquadri sovrapposti vengono combinati in un unico riquadro di delimitazione (vale a dire, soppressione non massima)




Questo è tutto, Sei pronto con il tuo primo framework di rilevamento di oggetti!
Che cos'è un'API? Perché abbiamo bisogno di un'API?
API sta per Application Programming Interface. Un'API fornisce agli sviluppatori una serie di operazioni comuni in modo che non debbano scrivere codice da zero.
Pensa a un'API come un menu di un ristorante che fornisce un elenco di piatti insieme a una descrizione di ogni piatto. Quando specifichiamo quale piatto vogliamo, il ristorante fa il lavoro e ci fornisce i piatti finiti. Non sappiamo esattamente come il ristorante prepara quel cibo, e davvero non è necessario.
In qualche modo, Le API fanno risparmiare molto tempo. Offrono anche comodità agli utenti in molti casi. Pensaci: Utenti di Facebook (incluso me!) Apprezzano la possibilità di accedere a molte app e siti utilizzando il loro ID Facebook. Come pensi che funzioni?? Utilizzo delle API di Facebook, Certo!
Quindi, in questo articolo, vedremo l'API TensorFlow sviluppata per l'attività di rilevamento degli oggetti.
API di rilevamento oggetti TensorFlow
L'API TensorFlow Object Detection è il framework per la creazione di una rete di deep learning che risolve i problemi di rilevamento degli oggetti.
Ci sono già modelli precedentemente addestrati nel loro framework che sono indicati come Model Zoo. Ciò include una raccolta di modelli precedentemente addestrati addestrati sul set di dati COCO., il set di dati KITTI e il set di dati dell'immagine aperta. Questi modelli possono essere utilizzati per le inferenze se siamo interessati alle categorie solo in questo set di dati.
Sono anche utili per inizializzare i modelli durante l'addestramento sul nuovo set di dati. Le varie architetture utilizzate nel modello preaddestrato sono descritte in questa tabella:

MobileNet-SSD
L'architettura SSD è una rete di convoluzione unica che impara a prevedere le posizioni dei riquadri di delimitazione e a classificare queste posizioni in un unico passaggio. Perciò, SSD può essere addestrato end-to-end. La rete SSD è costituita da un'architettura di base (MobileNet in questo caso) seguito da diversi strati di convoluzione:

SSD opera su mappe di funzionalità per rilevare la posizione dei riquadri di delimitazione. Ricordare: una feature map ha la dimensione Df * Df * m. Per ogni posizione sulla mappa delle caratteristiche, sono previsti k riquadri di delimitazione. Ogni riquadro di delimitazione porta con sé le seguenti informazioni:
- Rettangolo di selezione 4 angoli rimediare posizioni (cx, cy, w, h)
- Probabilità di classe C (c1, c2,… cp)
SSD no prevedere la forma della scatola, piuttosto dov'è la scatola?. I k riquadri di delimitazione hanno ciascuno una forma predefinita. I moduli vengono impostati prima dell'allenamento effettivo. Ad esempio, nella figura precedente, ci sono 4 casillas, che significa k = 4.
Perdita su MobileNet-SSD
Con il set finale di quadrati accoppiati, possiamo calcolare la perdita in questo modo:
L = 1/N (classe L + scatola L)
Qui, N è il numero totale di scatole accoppiate. La classe L è la perdita softmax per la classificazione e la 'scatola L'’ è la soft loss L1 che rappresenta l'errore delle caselle appaiate. La soft loss L1 è una modifica della perdita L1 che è più robusta rispetto ai valori anomali. Nel caso in cui N sia 0, anche la perdita è impostata su 0.
MobileNet
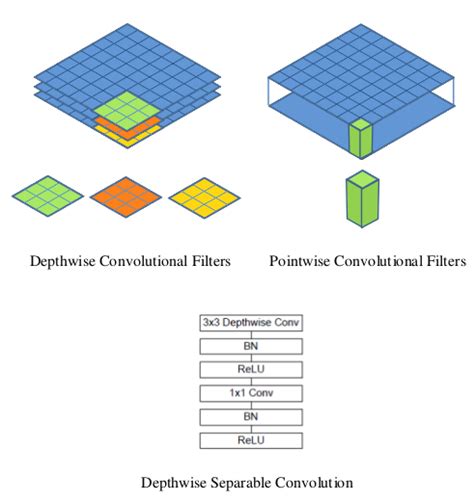
Il modello MobileNet si basa su convoluzioni separabili in profondità che sono una forma di convoluzioni fattorizzate. Questi fattorizzano una convoluzione standard in una convoluzione di profondità e una convoluzione di 1 × 1 chiamato punto convoluzione.
Per MobileNets, la convoluzione di profondità applica un singolo filtro a ciascun canale di ingresso. La convoluzione puntuale applica quindi una convoluzione 1 × 1 combinare gli output della convoluzione in profondità.
Una convoluzione standard filtra e combina gli input in un nuovo set di output in un unico passaggio. La convoluzione separabile in profondità la divide in due strati: uno strato separato da filtrare e uno strato separato da combinare. Questa fattorizzazione ha l'effetto di ridurre drasticamente il calcolo e la dimensione del modello..
Come caricare il modello?
Di seguito è riportato il processo passo passo da seguire in Google Colab in modo da poter visualizzare facilmente il rilevamento degli oggetti. Puoi anche seguire il codice.
Installa il modello
Assicurati di avere pycocotools installato:
Ottenere tensorflow/models oh cd alla directory principale del repository:
Costruisci protobuf e installa il oggetto_rilevamento pacchetto:
Importa le librerie richieste
Importa il modulo di rilevamento degli oggetti:
Preparazione del modello
Caricabatterie
Caricamento della mappa dell'etichetta
Etichetta le mappe dell'indice della mappa con i nomi delle categorie in modo che quando la nostra rete di convoluzione prevede 5, facci sapere che corrisponde a un aeroplano:
Per amore della semplicità, proveremo in 2 immagini:
Modello di rilevamento degli oggetti utilizzando l'API TensorFlow
Carica un modello di rilevamento di oggetti:
Controlla la firma di input del modello (aspettati una serie di immagini da 3 colori di tipo int8):
Aggiungi una funzione wrapper per chiamare il modello e pulire gli output:
Eseguilo su ogni immagine di prova e visualizza i risultati:
Di seguito è riportata l'immagine di esempio testata su ssd_mobilenet_v1_coco (MobileNet-SSD abilitato sul set di dati COCO):

Home-SSD
L'architettura del modello Inception-SSD è simile a quella del precedente MobileNet-SSD. La differenza è che l'architettura di base qui è il modello Inception. Per saperne di più sulla rete domestica, Andare qui: Comprendere la rete di avvio da zero.
Come caricare il modello?
Basta cambiare il nome del modello nella parte Discovery dell'API:
Dopo, fai la previsione seguendo i passaggi che abbiamo seguito sopra. Ecco!
RCNN più veloce
Le reti di rilevamento di oggetti all'avanguardia si basano su algoritmi di proposta regionale per formulare ipotesi sulla posizione degli oggetti. I progressi come SPPnet e Fast R-CNN hanno ridotto i tempi di esecuzione di queste reti di rilevamento, esporre il calcolo della proposta regionale come un collo di bottiglia.
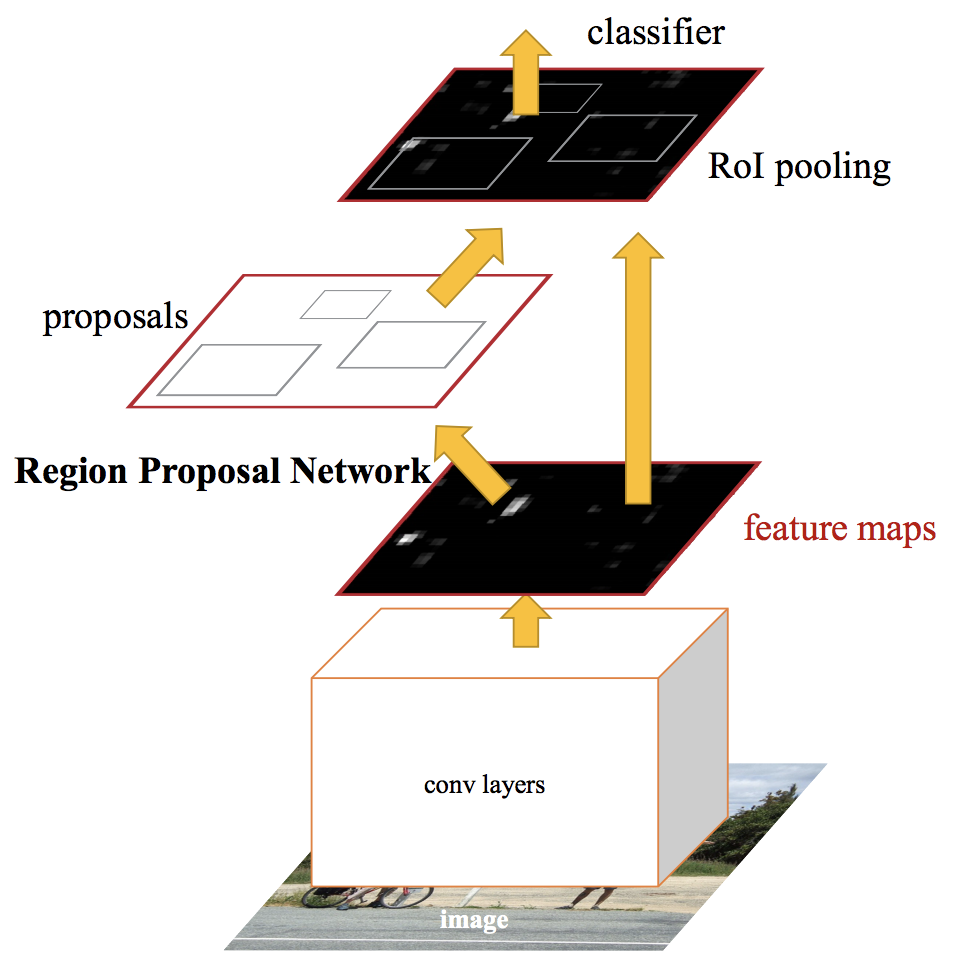
Un RCNN più veloce, inviamo l'immagine in ingresso alla rete neurale convoluzionale per generare una mappa delle caratteristiche convoluzionali. Dalla mappa delle caratteristiche convoluzionali, identifichiamo la regione delle proposte e le deformiamo in quadrati. E quando si utilizza un livello di raggruppamento di RoI (strato regione di interesse), li rimodelliamo in una dimensione fissa in modo che possa adattarsi a un livello completamente connesso.
Dal vettore di feature RoI, usiamo un livello softmax per prevedere la classe della regione proposta e anche i valori di offset per il riquadro di delimitazione.
Per saperne di più su Faster RCNN, leggi questo fantastico articolo – Un'implementazione pratica dell'algoritmo Faster R-CNN per il rilevamento di oggetti (Parte 2 – con codici Python).
Come caricare il modello?
Basta cambiare di nuovo il nome del modello nella parte Discovery dell'API:
Dopo, fai la previsione seguendo gli stessi passaggi che abbiamo seguito in precedenza. Di seguito è riportata l'immagine di esempio quando fornita a un modello RCNN più veloce:

Come potete vedere, questo è molto meglio del modello SSD-Mobilenet. Ma arriva con un compromesso: è molto più lento del modello precedente. Questi sono i tipi di decisioni che dovrai prendere quando scegli il modello di rilevamento degli oggetti giusto per il tuo progetto di deep learning e visione artificiale..
Quale modello di rilevamento oggetti dovrei scegliere?
A seconda delle vostre esigenze specifiche, puoi scegliere il modello corretto dall'API TensorFlow. Se vogliamo un modello ad alta velocità che possa lavorare nel rilevamento della trasmissione video ad alti fps, la rete di rilevamento del colpo singolo (SSD) funziona meglio. Come suggerisce il nome, La rete SSD determina tutte le probabilità del riquadro di delimitazione contemporaneamente; perciò, è un modello molto più veloce.
tuttavia, con rilevamento colpo singolo, guadagnare velocità a scapito della precisione. Con FasterRCNN, otterremo alta precisione ma bassa velocità. Quindi esplora e nel processo, ti renderai conto di quanto potente possa essere questa API TensorFlow.





