Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Nel mondo guidato dalla tecnologia di oggi, ogni secondo viene generata una grande quantità di dati. Il monitoraggio costante e la corretta analisi di tali dati sono necessari per ottenere informazioni significative e utili..
Tempo reale Dati del sensore, Dispositivi IoT, log files, social networks, eccetera. devono essere attentamente monitorati ed elaborati immediatamente. Perciò, per l'analisi dei dati in tempo reale, abbiamo bisogno di un motore di trasmissione dati altamente scalabile, affidabile e tollerante ai guasti.
Trasmissione dati
Lo streaming di dati è un modo per raccogliere continuamente dati in tempo reale da più fonti di dati sotto forma di flussi di dati.. Puoi pensare a Datastream come a una tabella continuamente aggregata.
La trasmissione dei dati è essenziale per gestire enormi quantità di dati in tempo reale. Tali dati possono provenire da una varietà di fonti come le transazioni online, log files, sensori, attività del giocatore nel gioco, eccetera.
Esistono diverse tecniche per trasmettere dati in tempo reale, Che cosa Apache KafkaApache Kafka è una piattaforma di messaggistica distribuita progettata per gestire flussi di dati in tempo reale. Originariamente sviluppato da LinkedIn, Offre elevata disponibilità e scalabilità, il che lo rende una scelta popolare per le applicazioni che richiedono l'elaborazione di grandi volumi di dati. Kafka consente agli sviluppatori di pubblicare, Sottoscrivere e archiviare i registri eventi, Facilitare l'integrazione dei sistemi e l'analisi in tempo reale...., Spark in streaming, Apache FlumeFlume es un software de código abierto diseñado para la recolección y transporte de datos. Utiliza un enfoque basado en flujos, lo que permite mover datos de diversas fuentes hacia sistemas de almacenamiento como Hadoop. Su arquitectura modular y escalable facilita la integración con múltiples orígenes de datos, lo que lo convierte en una herramienta valiosa para el procesamiento y análisis de grandes volúmenes de información en tiempo real.... eccetera. In questo post, discuteremo la trasmissione dei dati utilizzando Spark in streaming.
Spark in streaming
Spark Streaming è parte integrante di API centrale di Spark per eseguire analisi dei dati in tempo reale. Ci consente di creare un'applicazione di live streaming scalabile, alte prestazioni e tolleranza ai guasti.
Spark Streaming supporta l'elaborazione dei dati in tempo reale da varie sorgenti di input e la memorizzazione dei dati elaborati su vari ricevitori di output.
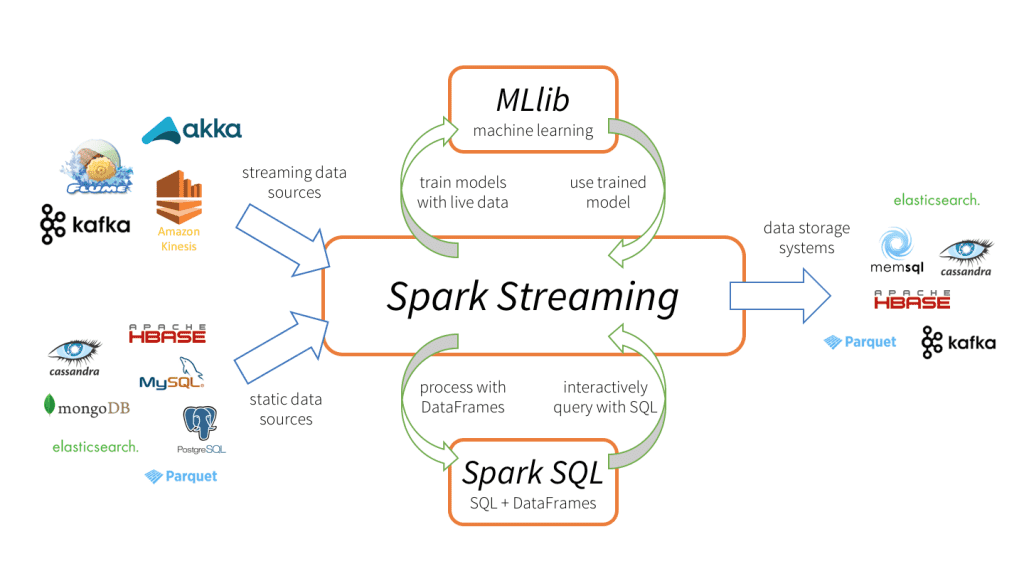
Spark Streaming tiene 3 componenti principali, come mostrato nell'immagine sopra.
-
Origini dati di input: Sorgenti di dati in streaming (nel ruolo di Kafka, Flume, Kinesis, eccetera.), fonti di dati statici (come MySQL, MongoDB, Cassandra, eccetera.), socket TCP, Twitter, eccetera.
-
Streaming della scintilla del motore: Per elaborare i dati in entrata utilizzando varie funzioni integrate, algoritmi complessi. Cosa c'è di più, possiamo controllare le trasmissioni in diretta, applicare l'apprendimento automatico utilizzando rispettivamente Spark SQL e MLlib.
-
Lavelli con uscita: I dati elaborati possono essere archiviati in file system, banche dati (relazionale e NoSQL), pannelli dal vivo, eccetera.
Tali capacità di elaborazione dei dati uniche, formato di input e output do Spark in streaming più attraente, portando a una rapida adozione.
Vantaggi dello streaming Spark
-
Framework di trasmissione unificato per tutte le attività di elaborazione dei dati (compreso l'apprendimento automatico, elaborazione grafica, Operazioni SQL) nei flussi di dati in tempo reale.
-
Bilanciamento dinamico del carico e migliore gestione delle risorse bilanciando in modo efficiente il carico di lavoro tra i lavoratori e avviando l'attività in parallelo.
-
Profondamente integrato con librerie di elaborazione avanzate come Spark SQL, MLlib, GraficoX.
-
Ripristino più rapido dagli errori riavviando le attività non riuscite in parallelo su altri nodi liberi.
Nozioni di base sullo streaming di Spark
Spark Streaming divide i flussi di dati di input live in batch che vengono quindi elaborati da Motore a scintilla.

DStream (flusso discretizzato)
DStream è un'astrazione di alto livello fornita da Spark Streaming, fondamentalmente, significa il flusso continuo di dati. Può essere creato da fonti di dati in streaming (nel ruolo di Kafka, Flume, Kinesis, eccetera.) o eseguire operazioni di alto livello su altri DStream.
Internamente, DStream è un flusso RDD e questo fenomeno consente a Spark Streaming di integrarsi con altri componenti Spark come MLlib, GraficoX, eccetera.

Quando si crea un'app di streaming, dobbiamo anche specificare la durata del batch per creare nuovi batch a intervalli di tempo regolari. Normalmente, la durata del lotto varia da 500 ms a diversi secondi. Ad esempio, figlio 3 secondi, quindi i dati di input vengono raccolti ogni 3 secondi.
Spark Streaming ti consente di scrivere codice in linguaggi di programmazione popolari come Python, Scala e Java. Diamo un'occhiata a un'app di streaming di esempio che utilizza PySpark.
Applicazione di esempio
Come abbiamo discusso in precedenza, Spark in streaming permette anche di ricevere flussi di dati tramite socket TCP. Quindi scriviamo un semplice programma di streaming per ricevere flussi di testo su una porta particolare, eseguire la pulizia di base del testo (come rimuovere gli spazi bianchi, ferma la rimozione delle parole, lematizzazione, eccetera.) e stampa il testo pulito sullo schermo.
Ora iniziamo a implementarlo seguendo i passaggi seguenti.
1. Creare un contesto per trasmettere e ricevere flussi di dati
StreamingContext è il principale punto di ingresso per qualsiasi applicazione di streaming. Può essere creato istanziando StreamingContext tipo pyspark.streaming modulo.
da pyspark import SparkContext da pyspark.streaming import StreamingContext
Durante la creazione StreamingContext possiamo specificare la durata del lotto, ad esempio, qui la durata del batch è 3 secondi.
sc = SparkContext(nomeapp = "Pulizia del testo") strc = StreamingContext(ns, 3)
una volta che StreamingContext è stato creato, possiamo iniziare a ricevere dati sotto forma di DStream tramite protocollo TCP su una porta specifica. Ad esempio, qui il nome host è specificato come “localhost” e la porta utilizzata è 8084.
text_data = strc.socketTextStream("localhost", 8084)
2. Esecuzione di operazioni su flussi di dati
Dopo aver creato un DStream oggetto, possiamo eseguire operazioni su di esso secondo il requisito. Qui, abbiamo scritto una funzione di pulizia del testo personalizzata.
Questa funzione converte prima il testo di input in minuscolo, quindi rimuovi gli spazi extra, caratteri non alfanumerici, link / URL, stopword e poi derivare ulteriormente il testo usando la libreria NLTK.
importare re
da nltk.corpus importa parole non significative
stop_words = set(stopwords.parole('inglese'))
da nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def clean_text(frase):
frase = frase.inferiore()
frase = re.sub("s+"," ", frase)
frase = re.sub("W"," ", frase)
frase = re.sub(R"httpS+", "", frase)
frase=" ".aderire(parola per parola nella frase.split() se la parola non è in stop_words)
frase = [lemmatizer.lemmatize(gettone, "v") for token nella frase.split()]
frase = " ".aderire(frase)
ritorna frase.strip()
3. Avvia il servizio di streaming
Il servizio di streaming non è ancora iniziato. Utilizzare il cominciare() funzione nella parte superiore del StreamingContext oggetto per avviarlo e continuare a ricevere i dati di trasmissione fino al comando di terminazione (Ctrl + C o Ctrl + INSIEME A) non essere ricevuto da attendere la fine () funzione.
strc.start() strc.awaitTermination()
NOTA – Il codice completo può essere scaricato da qui.
Ora prima dobbiamo eseguire il ‘Carolina del Nord‘comando (Netcat Utilità) per inviare i dati di testo dal server di dati al server di streaming Spark. Netcat è una piccola utility disponibile su sistemi simili a Unix per leggere e scrivere su connessioni di rete tramite porte TCP o UDP. Le tue due opzioni principali sono:
-
-io: Permettere Carolina del Nord per ascoltare una connessione in entrata invece di avviare una connessione a un host remoto.
-
-K: Contanti Carolina del Nord per rimanere sintonizzati per un'altra connessione dopo che la connessione corrente è stata completata.
Quindi esegui quanto segue Carolina del Nord comando nel terminale.
nc -lk 8083
Allo stesso modo, esegui lo script pyspark in un terminale diverso usando il seguente comando per eseguire la pulizia del testo sui dati ricevuti.
spark-submit streaming.py localhost 8083
Secondo questa dimostrazione, qualsiasi testo digitato nel terminale (in esecuzione netcat server) verranno ripuliti e il testo ripulito verrà stampato su un altro terminale ogni 3 secondi (durata del lotto).


Note finali
In questo articolo, abbiamo discusso Spark in streaming, i tuoi vantaggi nella trasmissione dei dati in tempo reale e un'applicazione di esempio (utilizzando socket TCP) per ricevere flussi di dati in tempo reale ed elaborarli secondo i requisiti.
I contenuti multimediali mostrati in questo articolo sull'implementazione di modelli di apprendimento automatico che sfruttano CherryPy e Docker non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





