[*]
Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Uno dei problemi principali che tutti devono affrontare quando si prova per la prima volta lo streaming strutturato è la configurazione dell'ambiente necessario per lo streaming dei propri dati.. Abbiamo alcuni tutorial online su come possiamo configurarlo. La maggior parte di loro si concentra sulla richiesta di installare una macchina virtuale e un sistema operativo Ubuntu e quindi configurare tutti i file richiesti modificando il file bash. Funziona bene, ma non per tutti. Una volta che usiamo una macchina virtuale, a volte potremmo dover aspettare molto tempo se abbiamo macchine con meno memoria. Il processo potrebbe bloccarsi a causa di problemi di ritardo di memoria. Quindi, per un modo migliore per farlo e un funzionamento facile, Ti mostrerò come possiamo configurare lo streaming strutturato nel nostro sistema operativo Windows.
Strumenti usati
Per la configurazione utilizziamo i seguenti strumenti:
1. Kafka (per la trasmissione dei dati, funge da produttore)
2. guardiano dello zoo
3. Pyspark (per generare i dati trasmessi, agisce come un consumatore)
4. Taccuino Jupyter (editor di codice)
variabili ambientali
È importante notare che qui, Ho aggiunto tutti i file nell'unità C. Cosa c'è di più, il nome deve essere lo stesso dei file che installi online.
Tenemos que configurar las variables de entorno a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que instalamos estos archivos. Fare riferimento a queste immagini durante l'installazione per un'esperienza senza problemi.
L'ultima immagine è il percorso delle variabili di sistema.
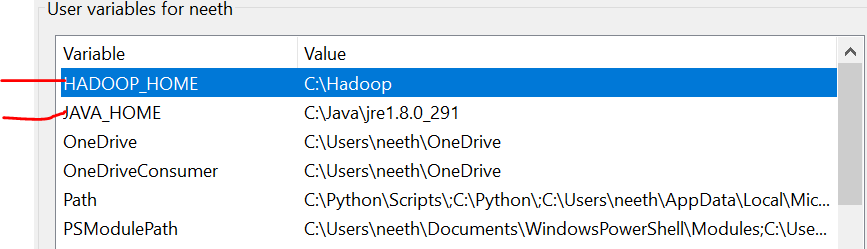
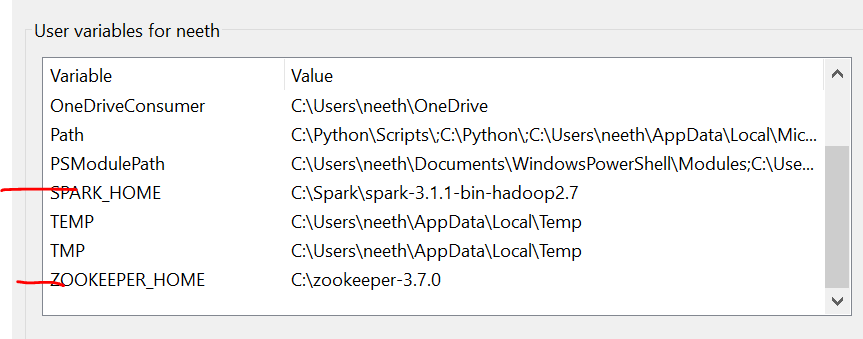
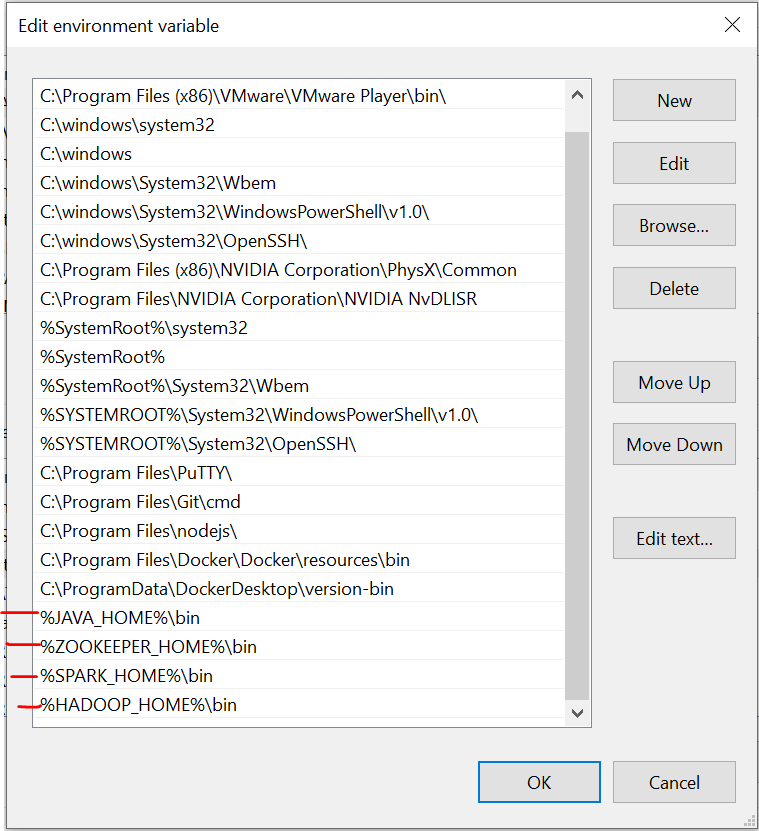
File richiesti
https://drive.google.com/drive/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw?usp=condivisione
Installazione di Kafka
Il primo passo è installare Kafka sul nostro sistema. Per questo dobbiamo andare a questo link:
https://dzone.com/articles/running-apache-kafka-on-windows-os
Dobbiamo installare Java 8 inizialmente e imposta le variabili di ambiente. Puoi ottenere tutte le istruzioni dal link.
Una volta che abbiamo finito con Java, dobbiamo installare un guardiano dello zoo. Ho aggiunto i file dei guardiani dello zoo in Google Drive. Sentiti libero di usarlo o semplicemente seguire tutte le istruzioni fornite nel link. Si instaló zookeeper"guardiano dello zoo" es un videojuego de simulación lanzado en 2001, donde los jugadores asumen el rol de un cuidador de zoológico. La misión principal consiste en gestionar y cuidar diversas especies de animales, asegurando su bienestar y la satisfacción de los visitantes. A lo largo del juego, los usuarios pueden diseñar y personalizar su zoológico, enfrentando desafíos que incluyen la alimentación, el hábitat y la salud de los animales.... correctamente y configuró la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dell'ambiente, Questo risultato è possibile visualizzarlo quando si esegue ZkServer come amministratore al prompt dei comandi.
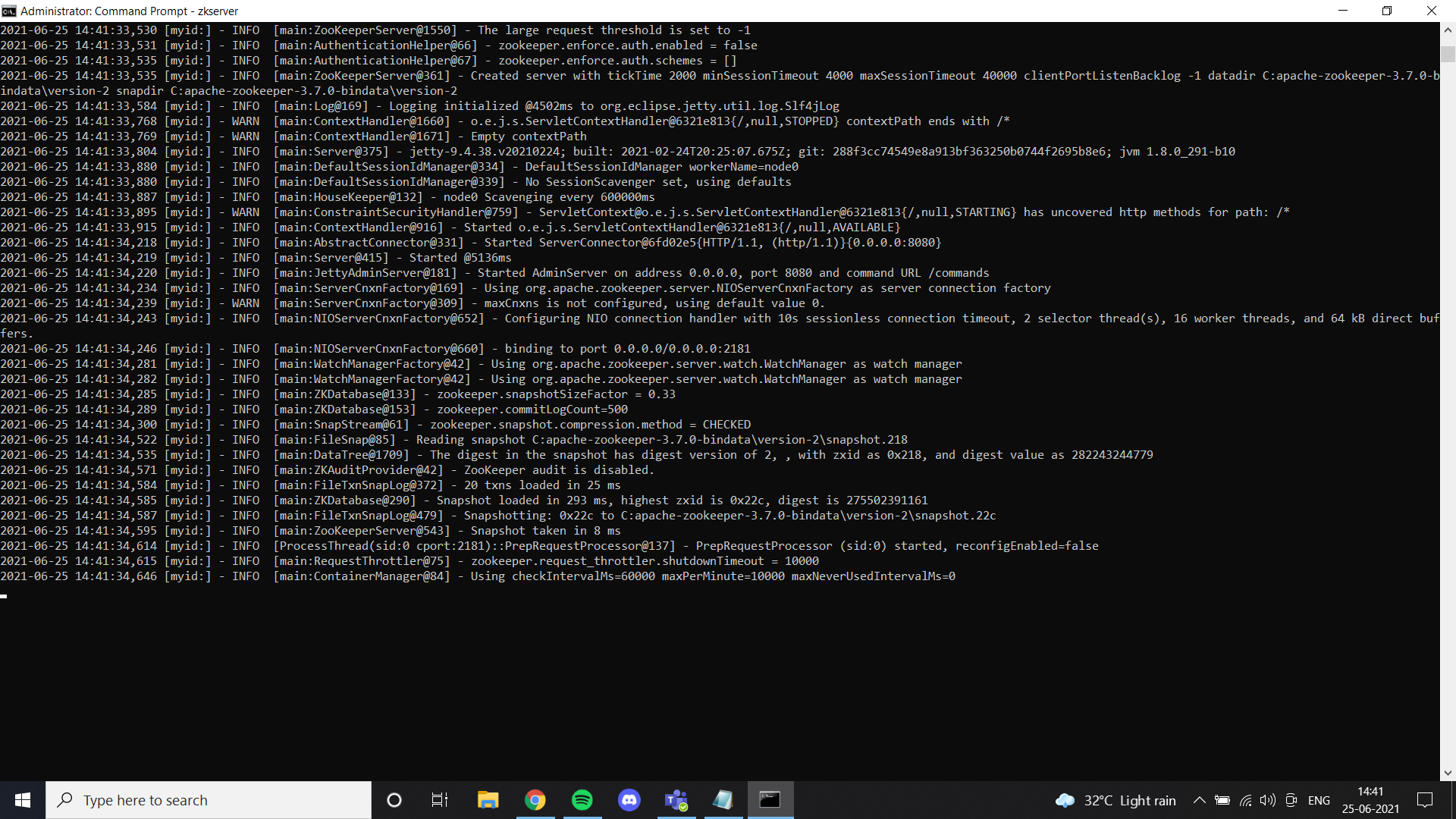
Prossimo, installare Kafka secondo le istruzioni del collegamento ed eseguirlo con il comando specificato.
.binwindowskafka-server-start.bat .configserver.properties
Una volta che tutto è impostato, prova a creare un tema e controlla se funziona correttamente. Se è così, avrai completato l'installazione di Kafka.
Installazione della scintilla
In questo passaggio, Installiamo Spark. Fondamentalmente, puoi seguire questo link per configurare Spark sul tuo computer Windows.
https://phoenixnap.com/kb/install-spark-on-windows-10
Durante uno dei passaggi, chiederà di configurare il file winutils. Per il tuo comfort, ho aggiunto il file nel link dell'unità che ho condiviso. In una cartella chiamata Hadoop. Metti quella cartella sull'unità C e imposta la variabile d'ambiente come mostrato nelle immagini. Consiglio vivamente di utilizzare il file Spark che ho aggiunto a Google Drive. Uno dei motivi principali è la trasmissione dei dati di cui abbiamo bisogno per impostare manualmente un ambiente di trasmissione strutturato. Nel nostro caso, Ho configurato tutte le cose necessarie e modificato i file dopo aver provato molto. Nel caso volessi fare una nuova configurazione, sentiti libero di farlo. Se la configurazione non funziona correttamente, finiamo con un errore come questo durante la trasmissione dei dati in pyspark:
Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;Una volta che siamo uno con Spark, ora possiamo trasmettere i dati richiesti da un file CSV in un produttore e ottenerli in un consumatore utilizzando il tema Kafka. Lavoro principalmente con il taccuino Jupiter e, così, Ho usato un notebook per questo tutorial.
Prima sul tuo taccuino, devi installare alcune librerie:
1. pip installa pyspark
2. pip installatore Kafka
3. pip install py4j
Come funziona lo streaming strutturato con Pyspark?
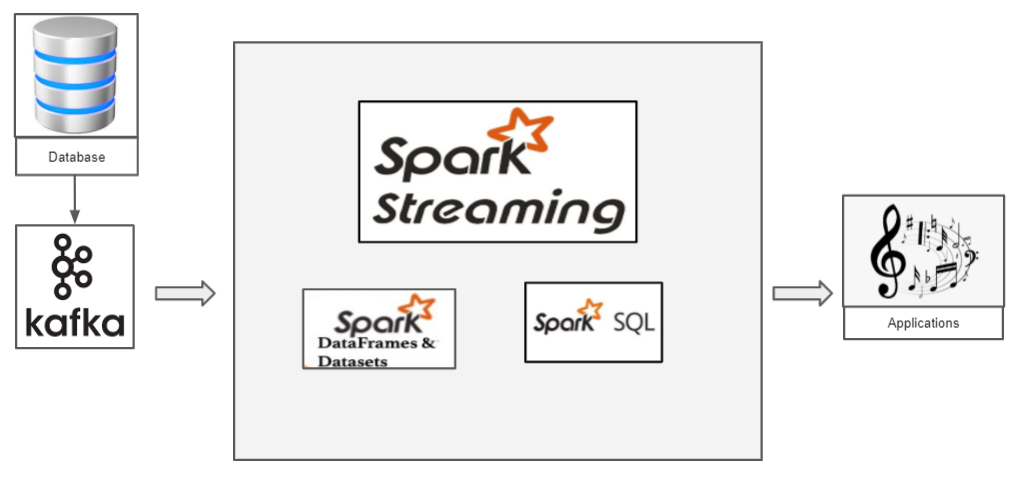
Abbiamo un file CSV con i dati che vogliamo trasmettere. Procediamo con il classico dataset Iris. Ora, se vogliamo trasmettere i dati dell'iride, dobbiamo usare Kafka come produttore. Kafka, creiamo un argomento a cui trasmettiamo i dati dell'iride e il consumatore può recuperare il frame di dati di questo argomento.
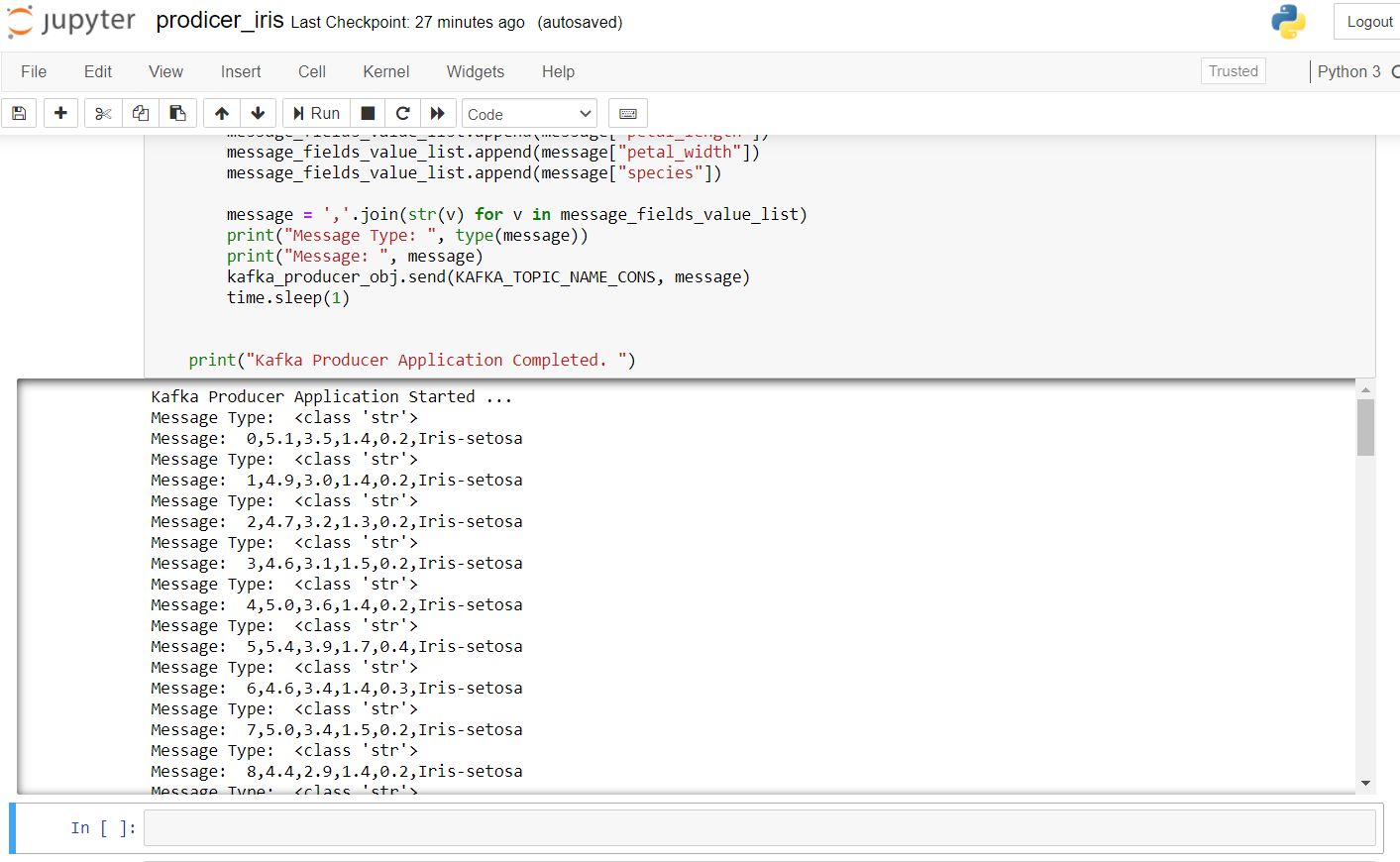
Di seguito è riportato il codice produttore per trasmettere i dati dell'iride:
Per avviare il produttore, Dobbiamo eseguire ZkServer come amministratore al prompt dei comandi di Windows e quindi avviare Kafka usando: .binwindowskafka-server-start.bat .configserver.properties dal prompt dei comandi nella directory Kafka. Se ricevi un errore da “nessun broker”, significa che Kafka non funziona correttamente.
Il risultato dopo l'esecuzione di questo codice nel Raccoglitore Jupyter è simile al seguente:
Ora, esaminiamo il consumatore. Eseguire il codice riportato di seguito per verificare se funziona bene su un nuovo laptop.
Una vez que ejecute esto, debería obtener un resultado como este:
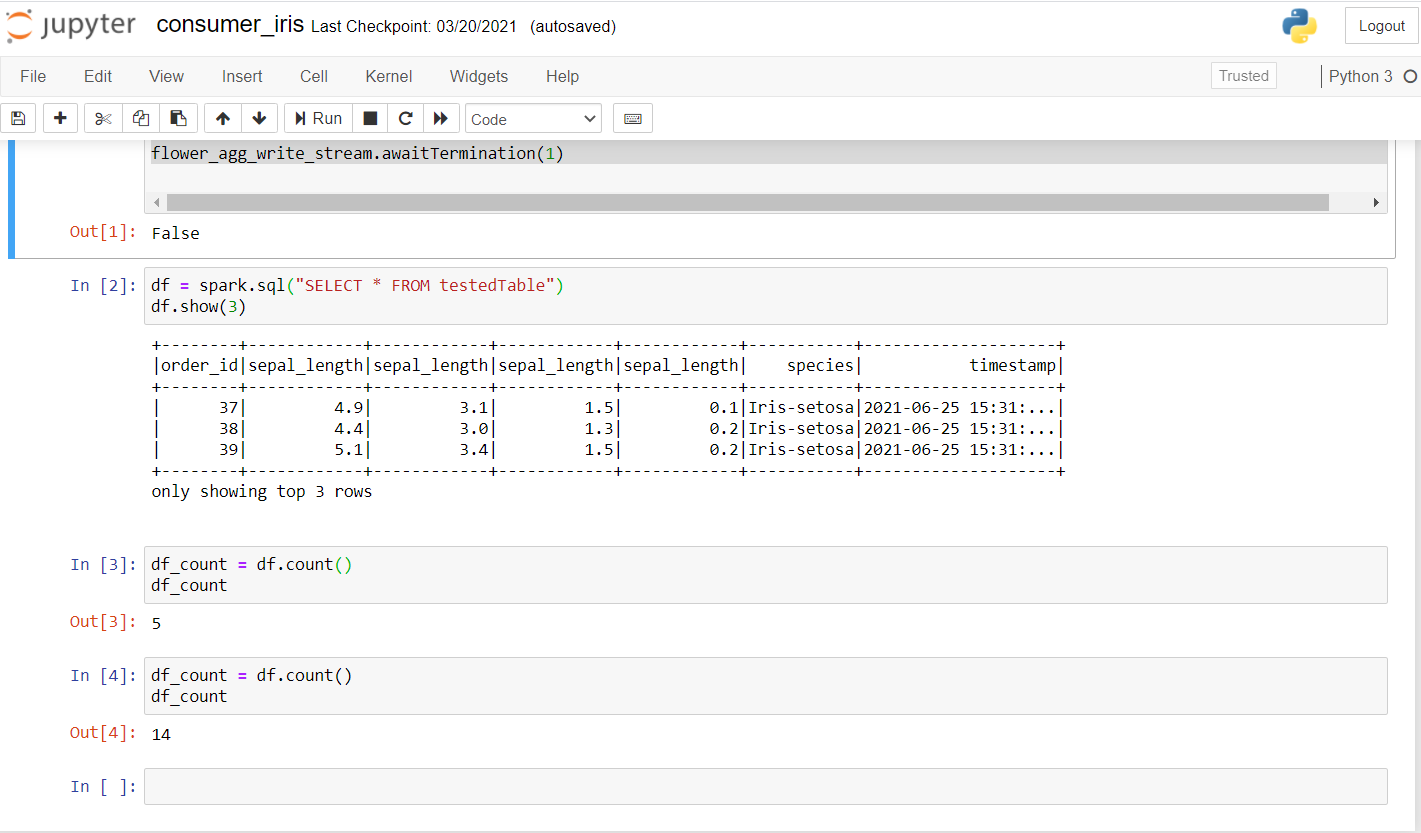
Come potete vedere, ha eseguito alcune ricerche e verificato se i dati venivano trasmessi. Il primo account è stato 5 e, dopo pochi secondi, il conto è aumentato a 14, confermare che i dati vengono trasmessi.
Qui, fondamentalmente, l'idea è quella di creare un contesto scintillante. Otteniamo i dati trasmettendo Kafka sul nostro argomento sulla porta specificata. Se puede crear una sessioneIl "Sessione" È un concetto chiave nel campo della psicologia e della terapia. Si riferisce a un incontro programmato tra un terapeuta e un cliente, dove si esplorano i pensieri, Emozioni e comportamenti. Queste sessioni possono variare in durata e frequenza, e il suo scopo principale è quello di facilitare la crescita personale e la risoluzione dei problemi. L'efficacia delle sessioni dipende dalla relazione tra il terapeuta e il terapeuta.. de chispa usando getOrCreate () come mostrato nel codice. Il passaggio successivo include la lettura del flusso Kafka e i dati possono essere caricati utilizzando load (). Poiché i dati vengono trasmessi, sarebbe utile avere un timestamp in cui ciascuno dei record è arrivato. Specifichiamo lo schema come facciamo nel nostro SQL e infine creiamo un data frame con i valori dei dati trasmessi con relativo timestamp. Finalmente, con un tempo di elaborazione di 5 secondi, possiamo ricevere dati in batch. Utilizziamo SQL View per archiviare temporaneamente i dati in memoria in modalità collegata e possiamo eseguire tutte le operazioni su di esso utilizzando il nostro frame di dati Spark.
Vedi il codice completo qui:
https://github.com/Siddharth1698/Structured-Streaming-Tutorial
Questo è uno dei miei progetti di streaming Spark, puoi fare riferimento ad esso per query più dettagliate e l'uso dell'apprendimento automatico in Spark:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
Riferimenti
1. https://github.com/Siddharth1698/Structured-Streaming-Tutorial
2. https://dzone.com/articles/running-apache-kafka-on-windows-os
3. https://phoenixnap.com/kb/install-spark-on-windows-10
4. https://drive.google.com/drive/u/0/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw
5. https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
6. Immagine in miniatura -> https://unsplash.com/photos/ImcUkZ72oUs
conclusione
Se segui questi passaggi, puoi configurare facilmente tutti gli ambienti ed eseguire il tuo primo programma di streaming strutturato con Spark e Kafka. In caso di difficoltà a configurarlo, Non esitare a contattarmi:
[e-mail protetta]
https://www.linkedin.com/in/siddharth-m-426a9614a/





