Questo post è stato pubblicato come parte del Blogathon sulla scienza dei dati
Che cos'è la corrispondenza delle stringhe fuzzy??
La corrispondenza delle stringhe fuzzy è la tecnica per trovare stringhe che corrispondono parzialmente e non esattamente a una determinata stringa. Quando un utente scrive male una parola o inserisce parzialmente una parola, la corrispondenza delle stringhe fuzzy aiuta a trovare la parola corretta, come vediamo nei motori di ricerca.
L'algoritmo alla base della corrispondenza delle stringhe fuzzy non si limita all'osservazione dell'equivalenza di due stringhe, piuttosto quantifica quanto sono vicine due stringhe l'una all'altra. Questo viene generalmente fatto utilizzando una metrica di distanza nota come "modifica distanza". Determina la vicinanza di due stringhe individuando le alterazioni minime necessarie per convertire una stringa in un'altra.. Esistono diversi tipi di distanze di modifica che possono essere utilizzate come la distanza di Levenshtein, Distanza di Hamming, La distanza di Jaro, eccetera.
Illustriamo come viene calcolata la distanza di Levenshtein.
Esempio 1:
Catena 1 = ‘Poner’
Catena 2 = ‘Pat’
La distancia de Levenshtein sería 1, puesto que podemos convertir la cadena 1 Nella catena 2 reemplazando ‘u’ con ‘a’.
Esempio 2:
Catena 1 = ‘Sol’
Catena 2 = ‘Saturno’
La distancia de Levenshtein sería 3, puesto que podemos convertir la cadena 1 Nella catena 2 attraverso 3 inserciones: 'un', 'T’ y ‘r’.
Coincidencia de cadenas difusas en Python:
Comparando cadenas en Python
Para comparar dos cadenas en Python, podemos ejecutar el siguiente código:
Str1 = "Back" Str2 = "Book" Result = Str1 == Str2 print(Risultato)
El código anterior dará un resultado como ‘Falso’ puesto que las dos cadenas no son iguales.
Distancia de Levenshtein en Python
Distancia de Levenshtein en Python usando el paquete de Python ‘Levenshtein’.
import Levenshtein as lev Str1 = "Back" Str2 = "Book" lev.distance(Str1.lower(),Str2.lower())
El código anterior dará una salida de 2, podemos convertir la cadena 1 Nella catena 2 di 2 reemplazos.
FuzzyWuzzy en Python
FuzzyWuzzy es un paquete de Python que se puede usar para la coincidencia de cadenas. Podemos ejecutar el siguiente comando para instalar el paquete:
pip install fuzzywuzzy
Del mismo modo que el paquete Levenshtein, FuzzyWuzzy cuenta con una función de vinculación que calcula la vinculación de similitud de distancia de Levenshtein estándar entre dos secuencias.
from fuzzywuzzy import fuzz Str1 = "Back" Str2 = "Book" Ratio = fuzz.ratio(Str1.lower(),Str2.lower()) Stampa(Rapporto)
La salida del siguiente código da 50, puesto que la vinculación de Levehshtein se calcula dividiendo la distancia de Levenshtein por el máximo de la longitud de la cadena 1 y la cadena 2.
Calculemos el motivo para otro conjunto de cadenas.
from fuzzywuzzy import fuzz Str1 = "My name is Ali" Str2 = "Ali is my name" Ratio = fuzz.ratio(Str1.lower(),Str2.lower()) Stampa(Rapporto)
La salida del código da 50, indicando che anche se le parole sono le stesse, l'ordine delle parole è importante quando si calcola la proporzione.
Collegamento parziale tramite FuzzyWuzzy
Il collegamento parziale ci aiuta ad abbinare le sottostringhe. Questo prende la stringa più corta e la confronta con tutte le sottostringhe della stessa lunghezza.
Str1 = "My name is Ali" Str2 = "Mi chiamo Ali Abdaal" Stampa(fuzz.partial_ratio(Str1.lower(),Str2.lower()))
La salida del código da 100 come rapporto_parziale () controlla solo se una delle stringhe è una sottostringa dell'altra.
Questo collegamento potrebbe essere molto utile se, come esempio, stiamo cercando di abbinare il nome di una persona tra due set di dati. Nel primo set di dati, la stringa ha il nome e il cognome della persona, e nel secondo set di dati, la catena ha il nome, il secondo nome e il cognome della persona. La proporzione sarebbe 100 perché la prima stringa è una sottostringa della seconda stringa.
Rapporto di classificazione dei token utilizzando FuzzyWuzzy
Nel rapporto di classificazione dei token, le stringhe vengono tokenizzate e preelaborate convertendole in minuscolo e rimuovendo la punteggiatura. Successivamente, le stringhe sono disposte e unite in ordine alfabetico. Pubblica questo, viene calcolato il legame di similarità della distanza di Levenshtein tra le stringhe.
Str1 = "My name is Ali" Str2 = "Ali is my name" Stampa(fuzz.token_sort_ratio(Str1, Str2))
La salida del código da 100, poiché il rapporto di ordinamento del token viene trovato dopo aver ordinato le stringhe in ordine alfabetico e, perché, l'ordine originale delle parole non ha importanza.
Rapporto impostato token utilizzando FuzzyWuzzy
La proporzione del pool di token esegue un'operazione di pool che estrae i token comuni invece di tokenizzare semplicemente le stringhe, ordina e poi incolla di nuovo i token. Le stesse parole in più o ripetute non contano.
Str1 = "My name is Ali" Str2 = "Ali è il mio nome nome" Stampa(fuzz.token_sort_ratio(Str1, Str2)) Stampa(fuzz.token_set_ratio(Str1, Str2))
L'output dell'associazione di classificazione dei token diventa 85, mentre quello del binding del set di token raggiunge 100, poiché l'associazione del set di token non tiene conto delle parole ripetute.
Ilustremos otro ejemplo de la vinculación de conjunto de tokens para una explicación más profunda.
Str_A = 'Read the sentence - My name is Ali' Str_B = 'My name is Ali' ratio = fuzz.token_set_ratio(Str_A, Str_B) Stampa(rapporto)
La salida del código anterior nos da 100. Questo è perché, underhood, la vinculación de conjunto de tokens tiene un enfoque más flexible. Después de borrar las cadenas comunes (‘Mi nombre es Ali’), descubre la vinculación de fuzz para los siguientes pares y después devuelve el valor máximo entre los tres:
- cadena común y la cadena común con el resto de la cadena uno
- cadena común y la cadena común con el resto de la cadena dos
- cadena común con el resto de uno y cadena común con el resto de dos
Módulo de procedimiento usando FuzzyWuzzy
Si tenemos una lista de cadenas y queremos hallar la cadena coincidente más cercana de la lista con una cadena dada, podemos aprovechar el módulo ‘procedimiento’.
from fuzzywuzzy import process query = 'My name is Ali' choices = ['My name Ali', 'My name is Ali', 'My Ali'] # Ottieni un elenco di partite ordinate per punteggio, limite predefinito a 5 process.extract(interrogazione, scelte)
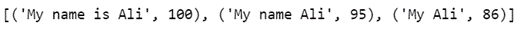
Se vogliamo estrarre la prima corrispondenza, podemos ejecutar el siguiente código:
process.extractOne(interrogazione, scelte)
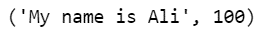
Circa l'autore
Nibedita ha completato il suo Master in Ingegneria Chimica presso l'IIT Kharagpur in 2014 e oggi lavora come consulente senior presso AbsolutData Analytics. Nella tua posizione attuale, lavora alla creazione di soluzioni basate su AI / ML per clienti in una vasta gamma di settori.
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





