Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Ci sono molti modi per confrontare il testo in Python. tuttavia, spesso cerchiamo un modo semplice per confrontare il testo. Il confronto del testo è necessario per vari scopi di analisi del testo e di elaborazione del linguaggio naturale.
Uno dei modi più semplici per confrontare il testo in Python è usare la libreria fuzzy-wuzzy. Qui, otteniamo un punteggio di 100, secondo la somiglianza delle catene. Fondamentalmente, se nos da el indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... de similitud. La libreria utilizza la distanza di Levenshtein per calcolare la differenza tra due stringhe.

distanza di Levenshtein
La distanza di Levenshtein è una metrica di stringa per calcolare la differenza tra due diverse stringhe. Il matematico sovietico Vladimir Levenshtein ha formulato questo metodo e da lui prende il nome..
La distanza di Levenshtein tra due corde un, B (di lunghezza {| un | e | B | rispettivamente) È dato da lev (un, B) dove
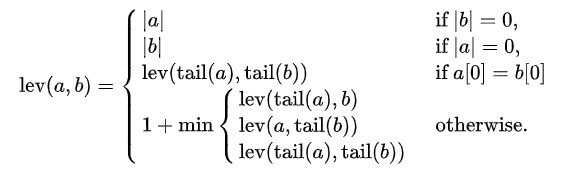
dove lui Coca Cola di qualche corda X è una stringa di tutti tranne il primo carattere di X, e X[n] è lui Nordns carattere stringa X a cominciare dal personaggio 0.
(Fonte: https://en.wikipedia.org/wiki/Levenshtein_distance)
FuzzyWuzzy
Fuzzy Wuzzy è una libreria open source sviluppata e rilasciata da SeatGeek. Puoi leggere il suo blog originale qui. Implementazione semplice e punteggio unico (su 100) metic rendono interessante l'uso di FuzzyWuzzy per il confronto del testo e ha numerose applicazioni.
Installazione:
pip install fuzzywuzzy
pip install python-Levenshtein
Questi sono i requisiti che devono essere installati.
Ora iniziamo con il codice importando le librerie necessarie.
dall'importazione fuzzywuzzy fuzz dall'importazione fuzzywuzzy processi
Vengono effettuate le importazioni necessarie.
#confronto di stringhe #esattamente lo stesso testo fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto("Londra è una grande città.", "Londra è una grande città.")
Partenza: 100
Dato che le due stringhe sono esattamente le stesse qui, otteniamo il risultato 100, indicando stringhe identiche.
#confronto di stringhe #non è lo stesso testo fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto("Londra è una grande città.", "Londra è una città molto grande.")
Partenza: 89
Come sono diverse le corde adesso?, il punteggio è 89. Quindi, guardiamo il lavoro fuzzy wuzzy.
#ora facciamo la conversione dei casi a1 = "Programma Python" a2 = "PROGRAMMA PITONE" Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto(a1.inferiore(),a2.inferiore()) Stampa(Rapporto)
Partenza: 100
Qui, in questo caso, sebbene le due diverse catene avessero casi diversi, entrambi sono stati convertiti in minuscolo e il punteggio è stato 100.
Corrispondenza sottostringa
Ora, spesso possono verificarsi più casi di corrispondenza del testo in cui è necessario confrontare due stringhe diverse in cui una potrebbe essere una sottostringa dell'altra. Ad esempio, stiamo testando un riepilogo di testo e dobbiamo verificare il suo rendimento. Quindi, il testo riassunto sarà una sottostringa della stringa originale. FuzzyWuzzy ha potenti funzioni per affrontare questi casi.
#funzioni fuzzywuzzy per lavorare con la corrispondenza di sottostringhe b1 = "Il gruppo Samsung è un conglomerato multinazionale sudcoreano con sede a Samsung Town, Seul." b2 = "Samsung Group è una società sudcoreana con sede a Seoul" Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto(b1.inferiore(),b2.inferiore()) Parziale_Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapporto_parziale(b1.inferiore(),b2.inferiore()) Stampa("Rapporto:",Rapporto) Stampa("Parziale_Rapporto:",Parziale_Rapporto)
Produzione:
Rapporto: 64 Parziale_Rapporto: 74
Qui, possiamo vedere che il punteggio per la funzione Motivo parziale è più alto. Ciò indica che è in grado di riconoscere il fatto che la stringa b2 ha parole di b1.
Rapporto di classificazione dei token
Ma il metodo di confronto delle sottostringhe sopra non è infallibile. Spesso, le parole si mescolano e non seguono un ordine. Allo stesso modo, nel caso di frasi simili, l'ordine delle parole è diverso o misto. In questo caso, usiamo una funzione diversa.
c1 = "Smartphone Samsung Galaxy" c2 = "Smartphone Samsung Galaxy" Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto(c1.inferiore(),c2.inferiore()) Parziale_Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapporto_parziale(c1.inferiore(),c2.inferiore()) Token_Sort_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(c1.inferiore(),c2.inferiore()) Stampa("Rapporto:",Rapporto) Stampa("Parziale_Rapporto:",Parziale_Rapporto) Stampa("Token_Sort_Ratio:",Token_Sort_Ratio)
Produzione:
Rapporto: 56 Parziale_Rapporto: 60 Token_Sort_Ratio: 100
Quindi, qui, in questo caso, possiamo vedere che le stringhe sono solo versioni miste l'una dell'altra. E le due stringhe mostrano lo stesso sentimento e menzionano anche la stessa entità. La funzione fuzz standard mostra che il punteggio tra di loro è 56. E la funzione Token Sort Ratio mostra che la somiglianza è 100.
Quindi, è chiaro che in alcune situazioni o applicazioni, l'indice di classificazione dei token sarà più utile.
Rapporto gettone impostato
Ma, ora se le due corde hanno lunghezze diverse. Le funzioni di relazione di classificazione dei token potrebbero non funzionare bene in questa situazione. Per questo, abbiamo la funzione Token Set Ratio.
d1 = "Windows è costruito da Microsoft Corporation" d2 = "Microsoft Windows" Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto(d1.inferiore(),d2.inferiore()) Parziale_Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapporto_parziale(d1.inferiore(),d2.inferiore()) Token_Sort_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.inferiore(),d2.inferiore()) Token_Set_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.inferiore(),d2.inferiore()) Stampa("Rapporto:",Rapporto) Stampa("Parziale_Rapporto:",Parziale_Rapporto) Stampa("Token_Sort_Ratio:",Token_Sort_Ratio) Stampa("Token_Set_Ratio:",Token_Set_Ratio)
Produzione:
Rapporto: 41 Parziale_Rapporto: 65 Token_Sort_Ratio: 59 Token_Set_Ratio: 100
¡Ah! Il punteggio di 100. Bene, il motivo è che la catena d2 i componenti sono completamente presenti nella catena d1.
Ora, modifichiamo leggermente la stringa d2.
d1 = "Windows è costruito da Microsoft Corporation" d2 = "Microsoft Windows 10" Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto(d1.inferiore(),d2.inferiore()) Parziale_Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapporto_parziale(d1.inferiore(),d2.inferiore()) Token_Sort_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.inferiore(),d2.inferiore()) Token_Set_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.inferiore(),d2.inferiore()) Stampa("Rapporto:",Rapporto) Stampa("Parziale_Rapporto:",Parziale_Rapporto) Stampa("Token_Sort_Ratio:",Token_Sort_Ratio) Stampa("Token_Set_Ratio:",Token_Set_Ratio)
Di, modificando leggermente il testo d2 possiamo vedere che il punteggio si riduce a 92. Questo perché il testo "10“Non presente nella catena d1.
WRatio ()
Questa funzione aiuta a gestire le maiuscole, minúsculas y algunos otros parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.....
#fuzz.WRatio() Stampa("Leggero cambio di casi:",fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio("Ferrari La Ferrari", 'Ferrari LAFerrari'))
Produzione:
Leggero cambio di casi: 100
Proviamo a rimuovere uno spazio.
#fuzz.WRatio() Stampa("Un leggero cambio di custodia e uno spazio rimosso:",fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio("Ferrari La Ferrari", 'FerrarILAFerrari'))
Produzione:
Un leggero cambio di custodia e uno spazio rimosso: 97
Proviamo con alcuni segni di punteggiatura.
#gestire alcune punteggiature casuali g1='Microsoft Windows va bene, ma prende lof di ram!!!' g2='Microsoft Windows è buono ma occupa molta RAM?' Stampa(fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio(g1,g2 ))
Partenza: 99
Perciò, possiamo vedere che FuzzyWuzzy ha molte funzioni interessanti che possono essere utilizzate per eseguire attività di confronto del testo interessanti.
Alcune applicazioni adatte:
FuzzyWuzzy potrebbe avere alcune applicazioni interessanti.
Può essere utilizzato per valutare riepiloghi di testo più lunghi e giudicare la loro somiglianza. Questo può essere usato per misurare le prestazioni dei riepiloghi di testo.
Secondo la somiglianza dei testi, può essere utilizzato anche per identificare l'autenticità di un testo, Articolo, Notizia, prenotare, eccetera. Spesso, troviamo diversi testi / dati errati. Spesso, non è possibile verificare ogni singolo dato di testo. Usando la somiglianza del testo, è possibile eseguire il controllo incrociato di più testi.
FuzzyWuzzy può anche essere utile per selezionare il miglior testo simile tra più testi. Quindi, Le applicazioni di FuzzyWuzzy sono numerose.
La somiglianza del testo è una metrica importante che può essere utilizzata per vari scopi di PNL e analisi del testo.. La cosa interessante di FuzzyWuzzy è che le somiglianze sono date come punteggio di 100. Ciò consente un punteggio relativo e genera anche una nuova caratteristica / dati che possono essere utilizzati a fini analitici / ML.
Somiglianza sommaria:
#usi di fuzzy wuzzy #somiglianza sommaria testo di input="L'analisi del testo prevede l'uso di dati di testo non strutturati, elaborarli in dati strutturati utilizzabili. Text Analytics è un'interessante applicazione di Natural Language Processing. Text Analytics ha vari processi tra cui la pulizia del testo, rimuovere le stopword, calcolo della frequenza delle parole, e altro ancora. L'analisi del testo ha acquisito molta importanza in questi giorni. Mentre milioni di persone si impegnano in piattaforme online e comunicano tra loro, viene generata una grande quantità di dati di testo. I dati di testo possono essere blog, post sui social media, tweet, Recensioni dei prodotti, sondaggi, discussioni del forum, e altro ancora. Tali enormi quantità di dati creano enormi dati di testo che le organizzazioni possono utilizzare. La maggior parte dei dati di testo disponibili sono non strutturati e sparsi. L'analisi del testo viene utilizzata per raccogliere ed elaborare questa grande quantità di informazioni per ottenere approfondimenti. L'analisi del testo funge da base per molte attività NLP avanzate come la classificazione, categorizzazione, Analisi del sentimento, e altro ancora. L'analisi del testo viene utilizzata per comprendere modelli e tendenze nei dati di testo. Parole chiave, temi, e le caratteristiche importanti di Text si trovano utilizzando Text Analytics. Ci sono molti altri aspetti interessanti dell'analisi del testo, ora procediamo con il nostro set di dati di curriculum. Il set di dati contiene testo di vari tipi di curriculum e può essere utilizzato per capire cosa le persone usano principalmente nei curriculum. L'analisi del testo del curriculum viene spesso utilizzata dai reclutatori per comprendere il profilo dei candidati e filtrare le domande. Reclutare per posti di lavoro è diventato un compito difficile in questi giorni, con un gran numero di candidati per posti di lavoro. I dirigenti delle risorse umane utilizzano spesso vari strumenti di elaborazione del testo e lettura di file per comprendere i curriculum inviati. Qui, lavoriamo con un set di dati di curriculum di esempio, che contiene il testo del curriculum e la categoria del curriculum. Leggeremo i dati, puliscilo e prova a ottenere alcune informazioni dai dati."
Quello sopra è il testo originale.
output_text="L'analisi del testo prevede l'uso di dati di testo non strutturati, elaborarli in dati strutturati utilizzabili. Text Analytics è un'interessante applicazione di Natural Language Processing. Text Analytics ha vari processi tra cui la pulizia del testo, rimuovere le stopword, calcolo della frequenza delle parole, e altro ancora. L'analisi del testo viene utilizzata per comprendere modelli e tendenze nei dati di testo. Parole chiave, temi, e le caratteristiche importanti di Text si trovano utilizzando Text Analytics. Ci sono molti altri aspetti interessanti dell'analisi del testo, ora procediamo con il nostro set di dati di curriculum. Il set di dati contiene testo di vari tipi di curriculum e può essere utilizzato per capire cosa le persone usano principalmente nei curriculum."
Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.ratio'}, '*')">rapporto(testo di input.inferiore(),output_text.inferiore()) Parziale_Rapporto = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">rapporto_parziale(testo di input.inferiore(),output_text.inferiore()) Token_Sort_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(testo di input.inferiore(),output_text.inferiore()) Token_Set_Ratio = fuzz.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(testo di input.inferiore(),output_text.inferiore()) Stampa("Rapporto:",Rapporto) Stampa("Parziale_Rapporto:",Parziale_Rapporto) Stampa("Token_Sort_Ratio:",Token_Sort_Ratio) Stampa("Token_Set_Ratio:",Token_Set_Ratio)
Produzione:
Rapporto: 54 Parziale_Rapporto: 79 Token_Sort_Ratio: 54 Token_Set_Ratio: 100
Possiamo vedere i diversi punteggi. La relazione parziale mostra che sono abbastanza simili, come dovrebbe essere?. Cosa c'è di più, la proporzione del set di token è 100, il che è evidente in quanto l'abstract è completamente tratto dal testo originale.
La migliore corrispondenza di stringhe possibile:
Usiamo la libreria dei processi per trovare la migliore corrispondenza di stringhe possibile tra un elenco di stringhe.
#scegliendo la possibile corrispondenza della stringa #usando la libreria dei processi interrogazione = 'Pila in eccesso' scelte = ["Spese generali di magazzino", 'Pila traboccante', 'S. straripamento',"Troppo pieno di scorte"] Stampa("Elenco dei rapporti: ") Stampa(processi.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.process.extract'}, '*')">estratto(interrogazione, scelte)) Stampa("Scelta migliore: ",processi.<un clic="parent.postMessage({'referente':'.fuzzywuzzy.process.extractOne'}, '*')">estrattoUno(interrogazione, scelte))
Produzione:
Elenco dei rapporti:
[('Stoack Overflow', 97), ('Pila traboccante', 90), ('S. straripamento', 85), ("Spese generali di magazzino", 64)]
Scelta migliore: ('Stoack Overflow', 97)
Perciò, vengono forniti i punteggi di somiglianza e la migliore corrispondenza.
Ultime parole
La libreria FuzzyWuzzy si basa sulla libreria difflib. E Python-Levenshtein utilizzato per ottimizzare la velocità. Quindi possiamo capire che FuzzyWuzzy è uno dei modi migliori per confrontare le stringhe in Python.
Controlla il codice in Kaggle qui.
A proposito di me:
Prateek Majumder
Scienza dei dati e analisi | Specialista in marketing digitale | SEO | Creazione di contenuti
Connettiti con me su Linkedin.
I miei altri articoli su DataPeaker: Collegamento.
Grazie.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





