introduzione
Quando si crea un modello di apprendimento automatico nella vita reale, è quasi raro che tutte le variabili nel set di dati siano utili per creare un modello. L'aggiunta di variabili ridondanti riduce la generalizzabilità del modello e può anche ridurre l'accuratezza complessiva di un classificatore.. Cosa c'è di più, l'aggiunta di sempre più variabili a un modello aumenta la complessità complessiva del modello.
Secondo lui legge di parsimonia a partire dal ‘rasoio di Occam’, La migliore spiegazione di un problema è quella che implica il minor numero di ipotesi possibili.. Perciò, la selezione delle funzionalità diventa una parte indispensabile della creazione di modelli di apprendimento automatico.
obbiettivo
L'obiettivo della selezione delle funzionalità nel machine learning è quello di trovare il miglior set di funzionalità che consenta di costruire modelli utili dei fenomeni studiati..
Le tecniche per la selezione delle funzionalità nell'apprendimento automatico possono generalmente essere classificate nelle seguenti categorie::
Tecniche supervisionate: Queste tecniche possono essere utilizzate per i dati etichettati e vengono utilizzate per identificare le caratteristiche rilevanti per aumentare l'efficienza dei modelli supervisionati come la classificazione e la regressione..
Tecniche non supervisionate: Queste tecniche possono essere utilizzate per i dati senza etichetta.
Da un punto di vista tassonomico, Queste tecniche sono classificate in:
UN. Metodi di filtraggio
B. Metodi di confezionamento
C. Metodi integrati
D. Metodi ibridi
In questo articolo, discuteremo alcune tecniche popolari di selezione delle funzionalità nell'apprendimento automatico.
UN. Metodi di filtraggio
I metodi di filtro raccolgono le proprietà intrinseche delle caratteristiche misurate attraverso statistiche univariate anziché prestazioni di convalida incrociata. Questi metodi sono più veloci e meno costosi dal punto di vista computazionale rispetto ai metodi wrapper.. Cuando se trata de datos de alta dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e..., è computazionalmente più economico usare metodi di filtraggio.
Diamo un'occhiata ad alcune di queste tecniche.:
Guadagno di informazioni
Il guadagno di informazioni calcola la riduzione di entropia dalla trasformazione di un set di dati. Se puede utilizar para la selección de características evaluando la ganancia de información de cada variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... en el contexto de la variable de destino.
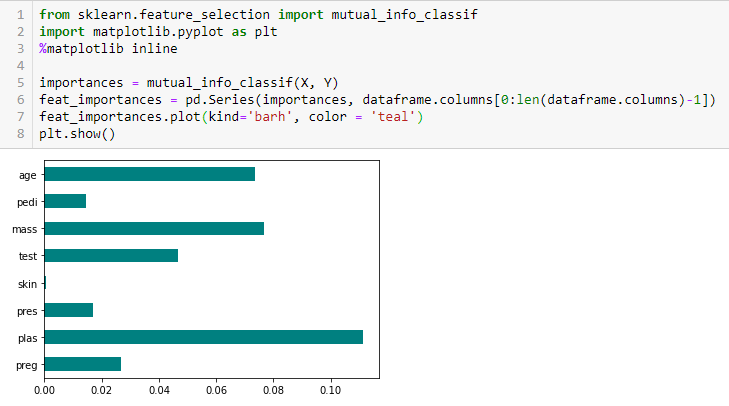
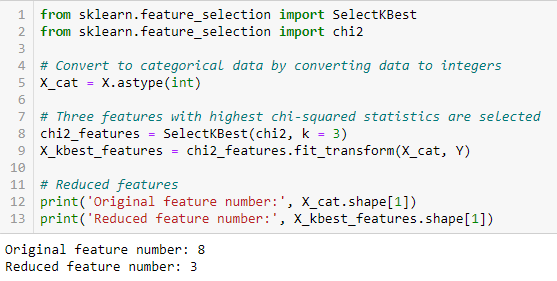
Test del chi quadrato
Il test del chi quadrato viene utilizzato per le caratteristiche categoriche in un set di dati. Calcoliamo chi-quadrato tra ogni caratteristica e il target e selezioniamo il numero desiderato di feature con i migliori punteggi Chi-square. Per applicare correttamente il chi-quadrato per testare la relazione tra le varie funzionalità del set di dati e la variabile di destinazione, Devono essere soddisfatte le seguenti condizioni: Le variabili devono essere categorico, Campionati indipendentemente e i valori devono avere un frequenza prevista maggiore di 5.
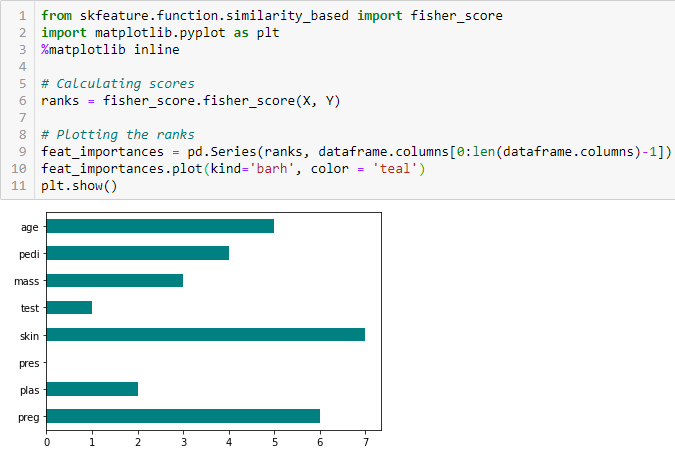
Valutazione degli utenti per Fisher
Il punteggio Fisher è uno dei metodi di selezione delle funzioni supervisionate più utilizzati.. L'algoritmo che useremo restituisce i ranghi delle variabili in base al punteggio del pescatore in ordine decrescente. Quindi possiamo selezionare le variabili a seconda del caso.
Coefficiente di correlazione
La correlación es una misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de la relación lineal de 2 o più variabili. Attraverso la correlazione, possiamo prevedere una variabile dall'altra. La logica alla base dell'utilizzo della correlazione per la selezione delle caratteristiche è che le variabili valide sono altamente correlate con l'obiettivo.. Cosa c'è di più, le variabili devono essere correlate con l'obiettivo, ma non dovrebbero essere correlati tra loro.
Se due variabili sono correlate, possiamo prevedere l'uno dall'altro. Perciò, se due caratteristiche sono correlate, il modello ha davvero bisogno solo di uno di loro, Poiché il secondo non aggiunge ulteriori informazioni. Useremo la correlazione di Pearson qui.
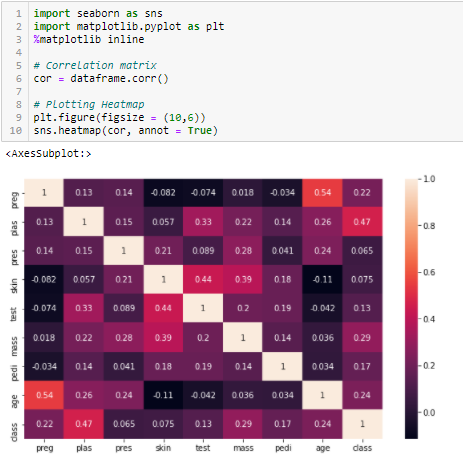
Dobbiamo stabilire un valore assoluto, Diciamo 0.5 come soglia per la selezione delle variabili. Se scopriamo che le variabili predittive sono correlate tra loro, Possiamo scartare la variabile che ha un valore di coefficiente di correlazione inferiore con la variabile target. Possiamo anche calcolare più coefficienti di correlazione per verificare se più di due variabili sono correlate tra loro.. Questo fenomeno è noto come multicollinearità.
Soglia di varianza
La soglia di varianza è un semplice approccio di base alla selezione delle caratteristiche. Elimina tutte le funzionalità la cui variazione non raggiunge una certa soglia. Per impostazione predefinita, rimuove tutte le funzioni di varianza zero, vale a dire, caratteristiche che hanno lo stesso valore in tutti i campioni. Partiamo dal presupposto che le funzioni con varianza maggiore possano contenere informazioni più utili., ma si noti che non stiamo considerando la relazione tra le variabili della caratteristica o la caratteristica e le variabili di destinazione, che è uno degli svantaggi dei metodi di filtraggio.

get_support restituisce un array booleano dove True significa che la variabile non ha varianza zero.
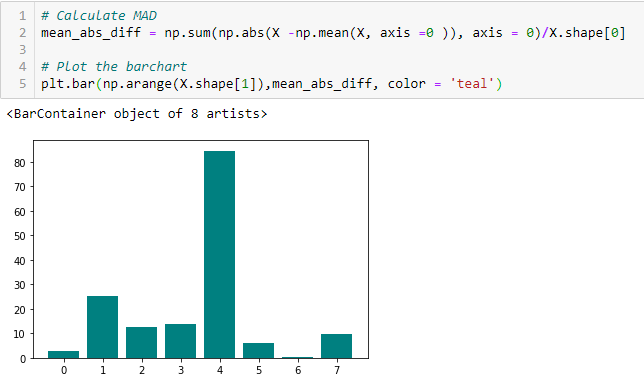
Significa differenza assoluta (PAZZO)
«La differenza assoluta media (PAZZO) calcola la differenza assoluta del valore medio. La principale differenza tra le misure di varianza e MAD è l'assenza del quadrato in quest'ultima. il pazzo, come la varianza, è anche una variante di scala ». [1] Ciò significa che il DMA più alto, maggiore potere discriminatorio.
Rapporto di dispersione
«Un'altra misura di dispersione applica la media aritmetica (SONO) e la media geometrica (GM). Per una determinata caratteristica (positivo) Xio in n modelli, AM e GM sono dati da
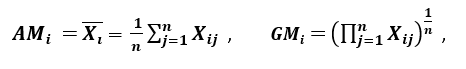
rispettivamente; che consente a chiunque di lavorare con Python in Jupyter Notebook o JupyterLab SOIAio ≥ GMio, con uguaglianza se e solo se Xi1 = Xi2 =…. = XSu, poi il rapporto
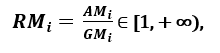
può essere utilizzato come misura della dispersione. Una maggiore dispersione implica un valore maggiore di Ri, quindi una caratteristica più rilevante. al contrario, Quando tutti gli esempi di funzionalità dispongono di (circa) lo stesso valore, Ri è vicino a 1, che indica una caratteristica di scarsa rilevanza '. [1]

 ‘
‘
B. Metodi di confezionamento:
I wrapper richiedono un metodo di ricerca dello spazio per tutti i possibili sottoinsiemi di feature, valutarne la qualità imparando e valutando un classificatore con quel sottoinsieme di caratteristiche. Il processo di selezione delle funzionalità si basa su uno specifico algoritmo di apprendimento automatico che cerchiamo di inserire in un determinato set di dati.. Segui un approccio di ricerca avido valutando tutte le possibili combinazioni di funzionalità rispetto al criterio di valutazione. I metodi di avvolgimento generalmente si traducono in una migliore precisione predittiva rispetto ai metodi di filtro.
Diamo un'occhiata ad alcune di queste tecniche.:
Selezione di funzionalità avanzate
Questo è un metodo iterativo in cui iniziamo con la variabile più performante rispetto al target.. Prossimo, selezioniamo un'altra variabile che offre le migliori prestazioni in combinazione con la prima variabile selezionata. Questo processo continua fino al raggiungimento dei criteri prestabiliti..
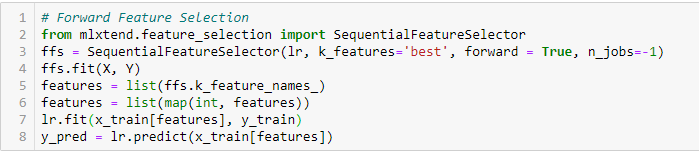
Rimozione di feature all'indietro
Questo metodo funziona esattamente all'opposto del metodo di selezione delle feature in avanti.. Qui, iniziamo con tutte le funzionalità disponibili e costruiamo un modello. Prossimo, prendiamo la variabile del modello che fornisce il miglior valore di misurazione di valutazione. Questo processo continua fino al raggiungimento dei criteri prestabiliti..
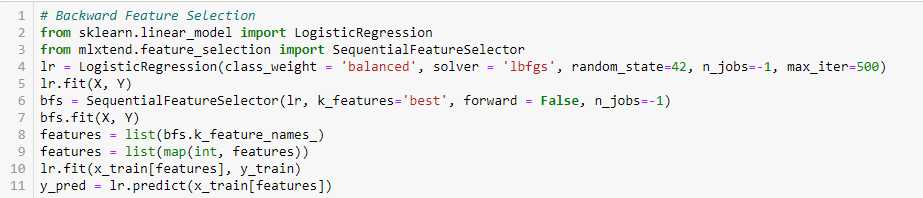
Questo metodo, insieme a quanto discusso in precedenza, noto anche come metodo di selezione delle funzioni sequenziale.
Selezione completa delle funzioni
Questo è il metodo di selezione delle funzionalità più efficace trattato finora. Questa è una valutazione della forza bruta di ogni sottoinsieme di funzionalità. Ciò significa che prova tutte le possibili combinazioni delle variabili e restituisce il sottoinsieme con le migliori prestazioni.
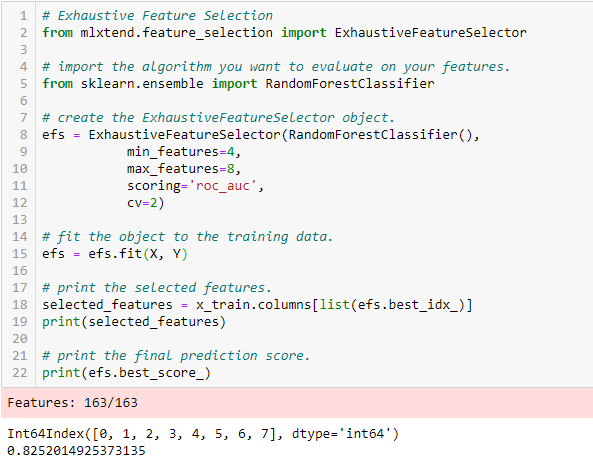
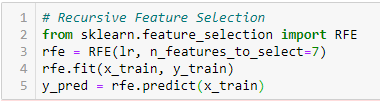
Eliminazione delle caratteristiche ricorsive
‘Dado un stimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati.... externo que asigna pesos a las características (ad esempio, i coefficienti di un modello lineare), l'obiettivo di eliminare le caratteristiche ricorsive (RFE) consiste nel selezionare le feature considerando in modo ricorsivo set di feature sempre più piccoli. Primo, lo stimatore viene addestrato sul set iniziale di feature e l'importanza di ciascuna feature è ottenuta da un attributo coef_ o da un attributo feature_importances_.
Dopo, Le funzionalità meno importanti vengono rimosse dal set di funzionalità corrente. Questa procedura viene ripetuta in modo ricorsivo nell'assieme potato fino a raggiungere il numero desiderato di caratteristiche da selezionare.. ‘[2]
C. Metodi integrati:
Questi metodi comprendono i vantaggi dei metodi di avvolgimento e filtraggio, includendo le interazioni tra le funzionalità, ma anche mantenendo un costo computazionale ragionevole. Los métodos integrados son iterativos en el sentido de que se encargan de cada iteración del proceso de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... del modelo y extraen cuidadosamente las características que más contribuyen al entrenamiento para una iteración en particular.
Diamo un'occhiata ad alcune di queste tecniche., Clicca qui:
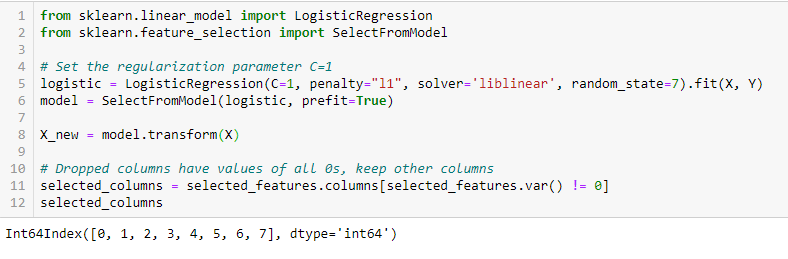
regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni.... LASSO (L1)
La regularización consiste en agregar una penalización a los diferentes parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... del modelo de aprendizaje automático para reducir la libertad del modelo, vale a dire, per evitare un serraggio eccessivo. Sulla regolarizzazione dei modelli lineari, la penalità si applica ai coefficienti che moltiplicano ciascuno dei pronostici. Dei diversi tipi di regolarizzazione, Lazo o L1 ha la proprietà di ridurre a zero alcuni coefficienti. Perciò, tale caratteristica può essere rimossa dal modello.
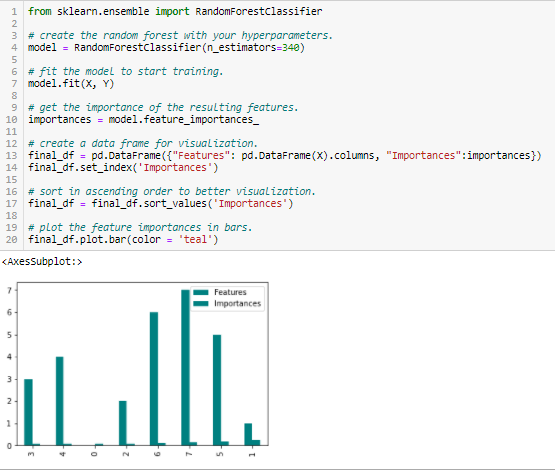
Importanza della foresta casuale
Random Forests è una sorta di algoritmo di bagging che aggrega un numero specificato di alberi decisionali. Las estrategias basadas en árboles utilizadas por los bosques aleatorios se clasifican naturalmente según lo bien que mejoran la pureza del nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi...., o in altre parole, una diminuzione delle impurità (Impurità Gini) soprattutto gli alberi. I nodi con la maggiore diminuzione delle impurità si verificano all'inizio degli alberi., mentre le note con la minor diminuzione di impurità si verificano alla fine degli alberi. Perciò, quando si tagliano gli alberi al di sotto di un nodo particolare, possiamo creare un sottoinsieme delle caratteristiche più importanti.
conclusione
Abbiamo discusso alcune tecniche per la selezione delle funzionalità. Abbiamo volutamente lasciato tecniche di estrazione delle feature come l'analisi dei componenti principali, Decomposizione del valore singolare, Analisi discriminante lineare, eccetera. questi metodi aiutano a ridurre la dimensionalità dei dati o a ridurre il numero di variabili preservando la varianza dei dati..
Oltre ai metodi discussi sopra, Esistono molti altri metodi di selezione delle funzionalità. Esistono anche metodi ibridi che utilizzano tecniche di filtraggio e avvolgimento.. Se vuoi saperne di più sulle tecniche di selezione delle funzionalità, secondo me, un ottimo materiale di lettura completo sarebbe ‘Selezione delle funzioni per il riconoscimento di modelli e dati«Vedi Urszula Stańczyk y Lakhmi C.. giainista.
Riferimenti
Documento denominato "Filtri di selezione delle funzioni efficienti per dati di grandi dimensioni".’ di Arturo J. Ferreira, Mario AT Figueiredo [1]
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html%20%5b2%5d [2]





