“Proprio come gli atleti non possono vincere senza una sofisticata combinazione di strategia, forma, atteggiamento, tattica e velocità, l'ingegneria delle prestazioni richiede una buona raccolta di metriche e strumenti per fornire i risultati aziendali desiderati”.– Todd De Capua
introduzione:
Negli anni, l'adozione del machine learning per guidare le decisioni aziendali è aumentata in modo esponenziale. Secondo Forbes, ML è destinato a crescere fino a $ 30.6 miliardi per 2024 e non sorprende vedere la miriade di soluzioni ML personalizzate invadere il mercato che rispondono a esigenze aziendali specifiche. La facilità di disponibilità delle potenze di calcolo, l'infrastruttura cloud e l'automazione lo hanno ulteriormente accelerato.
L'attuale tendenza a sfruttare i poteri del machine learning negli affari ha portato data scientist e ingegneri a progettare soluzioni / servizi innovativi e uno di questi servizi è stato Model As A Service (MaaS). Abbiamo utilizzato molti di questi servizi senza sapere come sono stati costruiti o serviti sul web, alcuni esempi includono la visualizzazione dei dati, riconoscimento facciale, elaborazione del linguaggio naturale, analisi predittiva e altro. In sintesi, MaaS incapsula tutti i dati complessi, formazione e valutazione del modello, implementazione, eccetera., e consente ai clienti di consumarli per il loro scopo.
Per quanto semplice possa sembrare utilizzare questi servizi, ci sono molte sfide nella creazione di un tale servizio, ad esempio: Come manteniamo il servizio?? Come garantiamo che l'accuratezza del nostro modello non diminuisca nel tempo?? eccetera. Come con qualsiasi servizio o applicazione, un fattore importante da considerare è il carico o il traffico che un servizio / L'API può gestire per garantire il tuo tempo di attività. La migliore caratteristica dell'API è quella di avere grandi prestazioni e l'unico modo per testarlo è premere l'API per vedere come risponde. Questo è il test di carico.
In questo blog, non vedremo solo come è costruito questo servizio, ma anche come testare il carico del servizio per pianificare i requisiti hardware / infrastruttura nell'ambiente di produzione. Cercheremo di raggiungerlo nel seguente ordine:
- Crea una semplice API con FastAPI
- Costruisci un modello di classificazione in Python
- Avvolgi il modello con FastAPI
- Testa l'API con il client Postman
- Prova di carico con Locust
Cominciamo !!
Creazione di una semplice API Web utilizzando FastAPI:
Il codice seguente mostra l'implementazione FastAPI di base. Il codice viene utilizzato per creare una semplice API Web che, dopo aver ricevuto un biglietto particolare, produce un output specifico. Ecco la divisione del codice:
- Carica le librerie
- Crea un oggetto applicazione
- Crea una ruta con @ app.get ()
- Scrivere una funzione del controller che abbia un host e un numero di porta definiti
da fastapi import FastAPI, Richiesta
dalla digitazione import Dict
da pydantic import BaseModel
importare uvicorn
importa numpy come np
importare sottaceti
importa panda come pd
import json
app = FastAPI()
@app.get("/")
radice asincrona def():
Restituzione {"Messaggio": "Costruito con FastAPI"}
if __name__ == '__main__':
uvicorn.run(app, ospite="127.0.0.1", porta=8000)
Una volta eseguito, puoi navigare nel browser con l'url: http: // localhost: 8000 e osservare il risultato che in questo caso sarà ‘ Costruito con FastAPI ‘
Creazione di un'API da un modello ML utilizzando FastAPI:
Ora che hai le idee chiare su FastAPI, vediamo come puoi avvolgere un modello di apprendimento automatico (sviluppato in Python) in un'API in Python. Userò il set di dati (diagnosi) Cancro al seno del Wisconsin. L'obiettivo di questo progetto di ML è prevedere se una persona ha un tumore benigno o maligno. userò VSCode come mio editore e nota che testeremo il nostro servizio con Postino Cliente. Questi sono i passaggi che seguiremo.
- Per prima cosa costruiremo il nostro modello di classificazione: KNeighborsClassifier ()
- Costruisci il nostro file del server che avrà la logica per l'API nel FlastAPI struttura.
- Finalmente, testeremo il nostro servizio con Postino
passo 1: Modello di classificazione
Un semplice modello di classificazione con il processo standard di caricamento dei dati, dividere i dati in treno / prova, seguito costruendo il modello e salvando il modello nel formato pickle nell'unità. Non entrerò nei dettagli della costruzione del modello, poiché l'articolo riguarda i test di carico.
importa panda come pd
importa numpy come np
da sklearn.model_selection import train_test_split
da sklearn.neighbors import KNeighborsClassifier
importa joblib, salamoia
importare il sistema operativo
import yaml
# cartella per caricare il file di configurazione
CONFIG_PATH = "../Configurazioni"
# Funzione per caricare il file di configurazione di yaml
def load_config(nome_config):
"""[La funzione prende il file di configurazione di yaml come input e carica il file di configurazione]
Argomenti:
nome_config ([igname]): [La funzione accetta la configurazione di yaml come input]
ritorna:
[corda]: [Restituisce la configurazione]
"""
con aperto(os.path.join(CONFIG_PATH, nome_config)) come file:
config = yaml.safe_load(file)
ritorna la configurazione
config = load_config("config.yaml")
#percorso del set di dati
nome file = "../../Dati/cancro-seno-wisconsin.csv"
#caricare dati
data = pd.read_csv(nome del file)
#sostituire "?" insieme a -99999
data = data.replace('?', -99999)
# drop id colonna
data = data.drop(config["drop_columns"], asse=1)
# Definisci X (variabili indipendenti) e si (variabile di destinazione)
X = np.array(data.drop(config["nome_obiettivo"], 1))
y = np.array(dati[config["nome_obiettivo"]])
X_treno, X_test, y_train, y_test = train_test_split(
X, e, test_size=config["test_size"], random_state= config["stato_casuale"]
)
# chiama il nostro classificatore e adatta ai nostri dati
classificatore = KNeighborsClassifier(
n_neighbors=config["n_vicini"],
pesi=config["pesi"],
algoritmo=config["algoritmo"],
leaf_size=config["leaf_size"],
p=config["P"],
metrica=config["metrica"],
n_jobs=config["n_jobs"],
)
# addestrare il classificatore
classificatore.fit(X_treno, y_train)
# prova il nostro classificatore
risultato = classificatore.punteggio(X_test, y_test)
Stampa("Il punteggio di precisione è. {:.1F}".formato(risultato))
# Salvataggio del modello su disco
sottaceto.discarica(classificatore, aprire('../../FastAPI//Models/KNN_model.pkl','wb'))
Puoi accedere al codice completo da Github
passo 2: compila la API con FastAPI:
Ci baseremo sull'esempio di base che abbiamo fatto in una sezione precedente.
Carica le librerie:
da fastapi import FastAPI, Richiesta dalla digitazione import Dict da pydantic import BaseModel importare uvicorn importa numpy come np importare sottaceti importa panda come pd import json
Cargue el modelo KNN guardado y escriba una función de enrutamiento para devolver el JsonJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software..:
app = FastAPI()
@app.get("/")
radice asincrona def():
Restituzione {"Messaggio": "Ciao mondo"}
# Carica il modello
# modello = pickle.load(aprire('../Modelli/KNN_model.pkl','rb'))
modello = pickle.load(aprire('../Modelli/KNN_model.pkl','rb'))
@app.post('/prevedi')
def pred(corpo: detto):
"""[riepilogo]
Argomenti:
corpo (detto): [Il metodo pred accetta Response come input che è nel formato Json e restituisce il valore previsto dal modello salvato.]
ritorna:
[Json]: [La funzione pred restituisce il valore previsto]
"""
# Ottieni i dati dalla richiesta POST.
dati = corpo
Listavar = []
for val in data.values():
varList.append(valore)
# Fai una previsione dal modello salvato
predizione = modello.predizione([varList])
# Estrai il valore
uscita = previsione[0]
#restituisce l'output in formato json
Restituzione {'La previsione è': produzione}
# 5. Esegui l'API con uvicorn
# Funzionerà su http://127.0.0.1:8000
if __name__ == '__main__':
"""[L'API verrà eseguita sul localhost sulla porta 8000]
"""
uvicorn.run(app, ospite="127.0.0.1", porta=8000)
Puoi accedere al codice completo da Github.
Utilizzo del client postino:
Nella nostra sezione precedente, creiamo una semplice API in cui premendo il tasto http: // localhost: 8000 nel browser abbiamo ricevuto un messaggio di output “Costruito con FastAPI”. Questo va bene fintanto che l'output è più semplice e ci si aspetta un input dell'utente o del sistema. Ma stiamo costruendo un modello come servizio in cui inviamo i dati come input per la previsione del modello.. In quel caso, avremo bisogno di un modo migliore e più semplice per testarlo. noi useremo postino per testare la nostra API.
- Esegui il file server.py
- Apri il client Postman e inserisci i dettagli rilevanti evidenziati di seguito e premi il pulsante di invio.
- Guarda il risultato nella sezione delle risposte qui sotto.
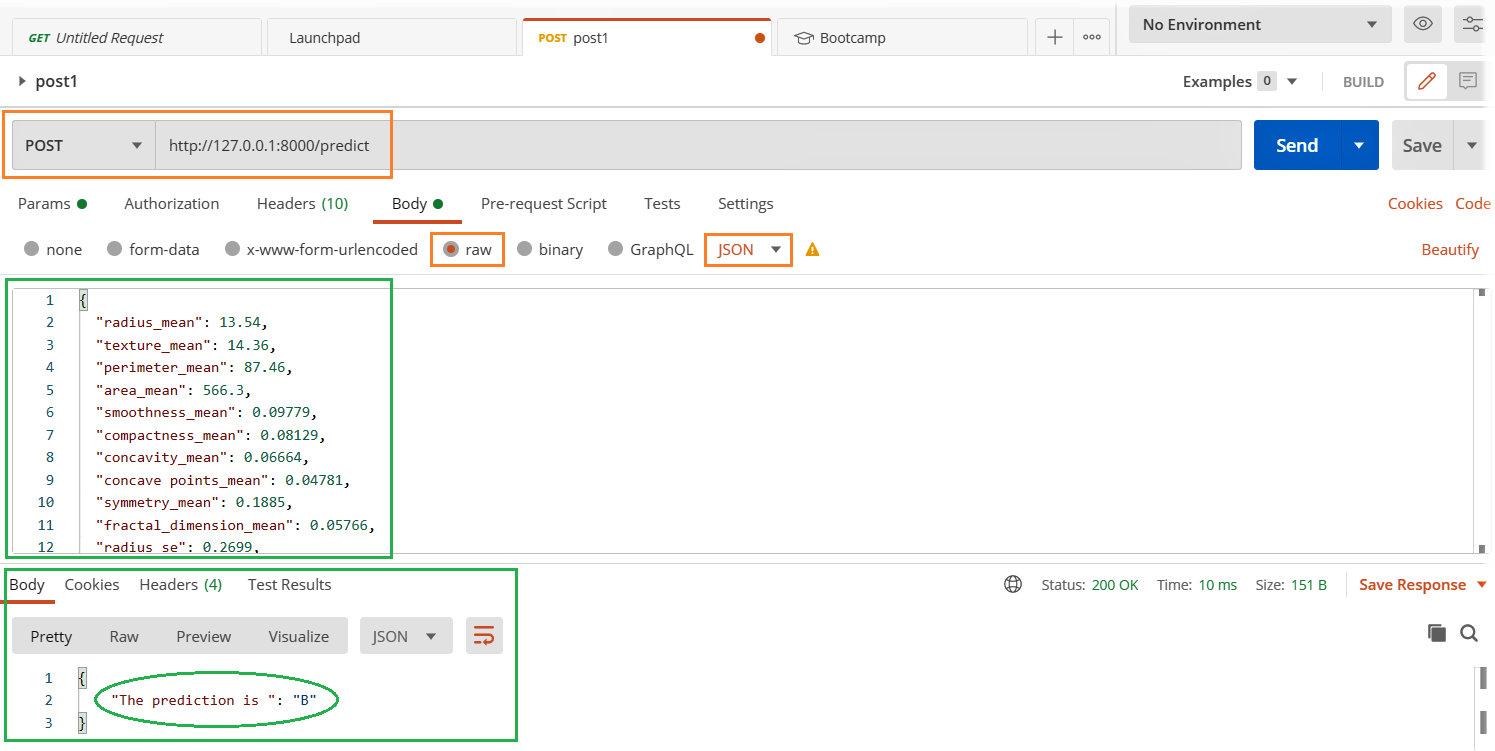
Le tue applicazioni e i tuoi servizi sono stabili sotto carico massimo??
È ora di caricare il test:
Esploreremo la libreria Locust per i test di carico e il modo più semplice per installare Langosta è
pip installa locusta
Creiamo un perf.py file con il seguente codice. Ho fatto riferimento al codice Avvio veloce pagina di aragosta
tempo di importazione
import json
da locust import HttpUser, compito, tra
class QuickstartUser(HttpUser):
wait_time = tra(1, 3)
@compito(1)
def testFlask(se stesso):
carico = {
"raggio_mean": 13.54,
"texture_mean": 14.36,
......
......
"fractal_dimension_worst": 0.07259}
le mie intestazioni = {'Tipo di contenuto': 'applicazione/json', 'Accettare': 'applicazione/json'}
self.client.post("/prevedere", data= json.dumps(carico), headers=myheaders)
Accedi al file di codice completo da Github
Inizia l'aragosta: Vai alla directory perfetto.pi ed esegui il seguente codice.
locust -f perf.py
Interfaz web Locust:
Una volta avviato Locust con il comando sopra, vai a un browser e puntalo su http: // localhost: 8089. Dovresti vedere la pagina seguente:
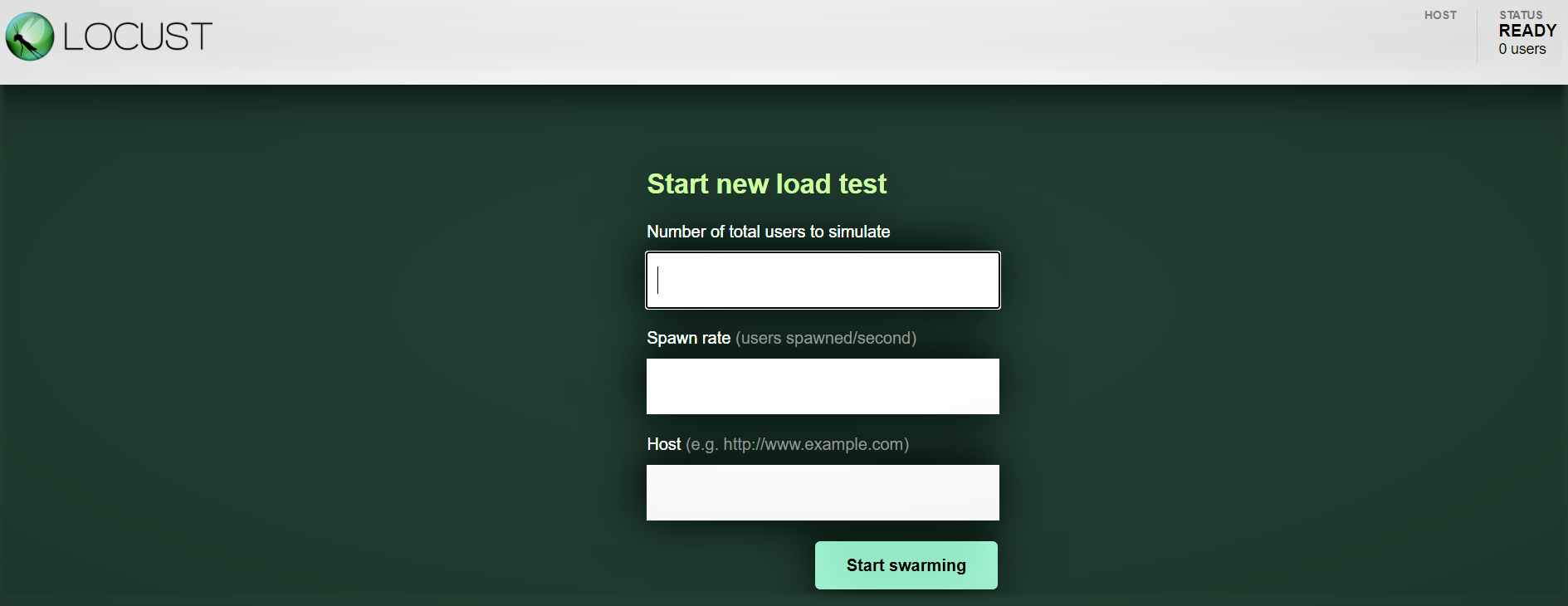
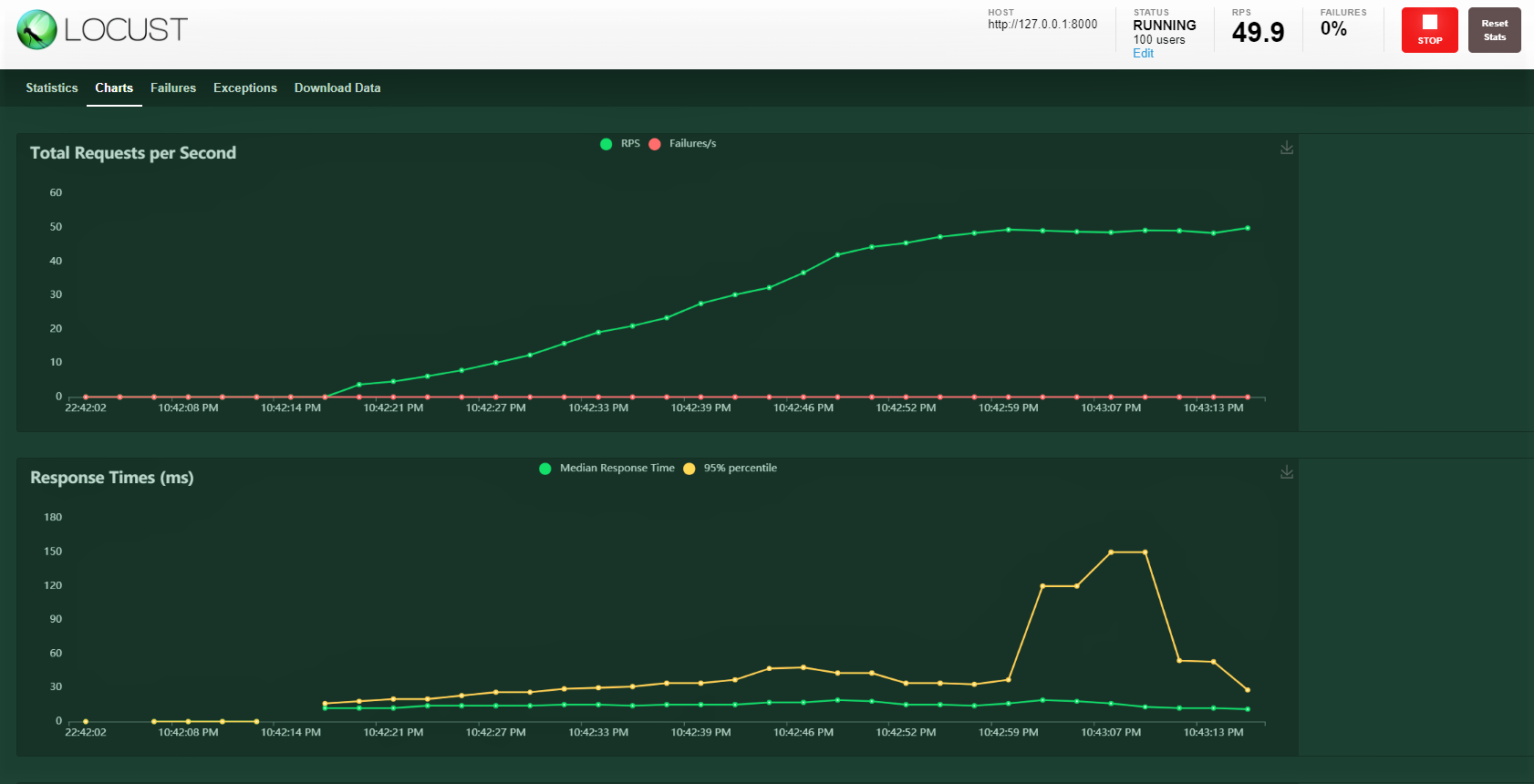
Proviamo con 100 utenti, rapporto di generazione 3 il tuo ospite: http: 127.0.0.1: 8000 dove è in esecuzione la nostra API. Puoi vedere la seguente schermata. Puoi vedere l'aumento del carico nel tempo e nei tempi di risposta, una rappresentazione grafica mostra il tempo medio e altre metriche.
Nota: assicurati che server.py sia in esecuzione.

conclusione:
Copriamo molto su questo blog, dalla costruzione di un modello, chiusura con FastAPI, la prova di servizio con il postino e infine la realizzazione di una prova di carico con 100 utenti simulati che accedono al nostro servizio con un carico gradualmente crescente. Siamo stati in grado di monitorare la risposta del servizio.
La maggior parte delle volte ci sono SLA a livello aziendale che devono essere soddisfatti, vale a dire, mantieni una certa soglia per un tempo di risposta come 30 ms o 20 ms. Se gli SLA non sono soddisfatti, ci sono potenziali implicazioni finanziarie a seconda del contratto o della perdita di clienti, poiché non hanno ricevuto il servizio abbastanza rapidamente.
Un test di carico ci aiuta a capire i punti massimi e potenziali di guasto. Dopo, possiamo pianificare azioni proattive aumentando la nostra capacità hardware e, se il servizio è distribuito nel tipo di configurazione Kubernetes, configuralo per aumentare il numero di pod con l'aumento del carico.
Buon apprendimento !!!!
Puoi connetterti con me – Linkedin
Puoi trovare il codice di riferimento: Github
Riferimenti
https://docs.locust.io/en/stable/quickstart.html
https://fastapi.tiangolo.com/
https://unsplash.com/
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





