Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.
introduzione
Fondamentalmente addestriamo le macchine per includere un qualche tipo di automazione in esse. Nell'apprendimento automatico, utilizziamo vari tipi di algoritmi per consentire alle macchine di apprendere le relazioni all'interno dei dati forniti e fare previsioni con essi. Quindi, Il tipo di previsione del modello in cui abbiamo bisogno dell'output previsto è un valore numerico continuo, si chiama problema di regressione.
L'analisi di regressione ruota attorno a semplici algoritmi, che sono spesso utilizzati in finanza, investimenti e altri, e stabilisce la relazione tra una singola variabile dipendente che dipende da più variabili indipendenti. Ad esempio, prevedere il prezzo dell'alloggio o lo stipendio di un dipendente, eccetera., sono i problemi di regressione più comuni.
Discuteremo prima i tipi di algoritmi di regressione a breve e poi passeremo a un esempio.. Questi algoritmi possono essere sia lineari che non lineari.
Algoritmi ML lineari

Regressione lineare
È un algoritmo comunemente usato e può essere importato dalla classe Linear Regression. Se utiliza una única variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de entrada (il significativo) Per stimare una o più variabili di output, Supponendo che la variabile di input non sia correlata tra loro. È rappresentato come:
y = b * X + C
dove la variabile dipende da e, x indipendente, pendenza b della linea più adatta che potrebbe ottenere un output accurato e c – la sua intersezione. A meno che non ci sia una linea esatta che mette in relazione le variabili dipendenti e indipendenti, Potrebbe esserci una perdita nell'output che viene normalmente presa come il quadrato della differenza tra l'output previsto e l'output effettivo, vale a dire, il Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e....
Quando si utilizza più di una variabile indipendente per ottenere risultati, si chiama Regressione lineare multipla. questo tipo di modello presuppone che esista una relazione lineare tra la caratteristica data e l'output., qual è il tuo limitazione.
Regressione della cresta: lo standard L2
Questo è un tipo di algoritmo che è un'estensione di una regressione lineare che tenta di ridurre al minimo la perdita., Utilizza inoltre dati di regressione multipla. I loro coefficienti non sono stimati dai minimi quadrati ordinari (MCO ·), sino por un stimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati.... llamado cresta, che è distorto e ha una varianza minore rispetto allo stimatore MCO, quindi otteniamo una contrazione dei coefficienti. Con questo tipo di modello, possiamo anche ridurre la complessità del modello.
Sebbene la contrazione del coefficiente si verifichi qui, non sono completamente ridotti a zero. Perciò, il tuo modello finale includerà comunque tutto.
Regressione ad anello: lo standard L1
È l'operatore della selezione e contrazione minima assoluta. Questo penalizza la somma dei valori assoluti dei coefficienti per minimizzare l'errore di previsione. Fa sì che i coefficienti di regressione per alcune delle variabili siano ridotti a zero. Può essere costruito utilizzando la classe LASSO. Uno dei vantaggi del loop è la sua selezione simultanea di funzioni. Questo aiuta a ridurre al minimo la perdita di previsione. In secondo luogo, dobbiamo tenere presente che lasso non può effettuare una selezione di gruppo, Seleziona inoltre le feature prima della saturazione.
Tanto el lazo como la cresta son métodos de regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni.....

fonte: Unsplash
Esaminiamo alcuni esempi:
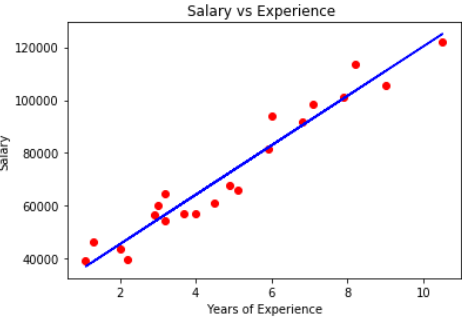
Supponiamo un fatto con anni di esperienza e stipendio di diversi dipendenti. Il nostro obiettivo è quello di creare un modello che prevede lo stipendio del dipendente in base all'anno di esperienza. Poiché contiene una variabile indipendente e una variabile dipendente, possiamo usare la regressione lineare semplice per questo problema.
Algoritmi ML non lineari
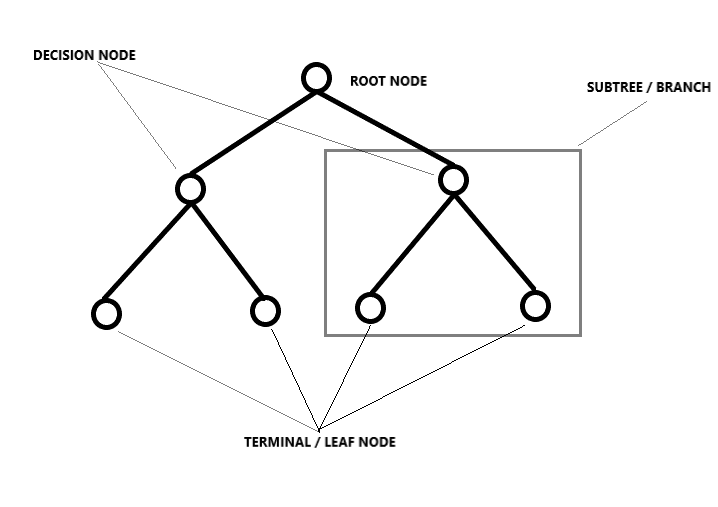
Regressione dell'albero decisionale
Suddivide un set di dati in sottoinsiemi sempre più piccoli dividendolo, risultante in un albero con nodi decisionali e nodi foglia. Qui l'idea è quella di tracciare un valore per qualsiasi nuovo punto dati che collega il problema.. El tipo de forma en que se lleva a cabo la división está determinada por los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... y el algoritmo, e la divisione si interrompe quando raggiunge il numero minimo di informazioni da aggiungere. Gli alberi decisionali spesso danno buoni risultati, ma anche se c'è un leggero cambiamento nei dati, l'intera struttura cambia, il che significa che i modelli diventano instabili.
fonte: unsplash
Prendiamo un caso di previsione del prezzo della casa, dato un insieme di 13 caratteristiche e dintorni 500 righe, qui è necessario prevedere il prezzo delle abitazioni. Dal momento che qui hai una notevole quantità di campioni, È necessario optare per alberi o altri metodi per prevedere i valori.
foresta casuale
L'idea alla base della regressione casuale della foresta è che, per trovare il risultato, utilizza più alberi decisionali. I passaggi coinvolti in esso sono:
– Scegli K punti dati casuali dal set di allenamento.
– Creare un albero decisionale associato a questi punti dati
– Scegli il numero di alberi che dobbiamo costruire e ripeti i passaggi precedenti (fornito come argomento)
– Per un nuovo punto dati, Fare in modo che ciascuna delle strutture preveda i valori della variabile dipendente per l'input specificato.
– Assegnare il valore medio dei valori previsti all'output finale effettivo.
Questo è simile a indovinare il numero di palline in una scatola.. Supponiamo di annotare casualmente i valori di previsione forniti da molte persone e quindi calcolare la media per prendere una decisione sul numero di palline nella scatola.. La foresta casuale è un modello che utilizza più alberi decisionali, che conosciamo, ma dal momento che ha molti alberi, richiede anche molto tempo per l'allenamento e potenza di calcolo, che è ancora un inconveniente.
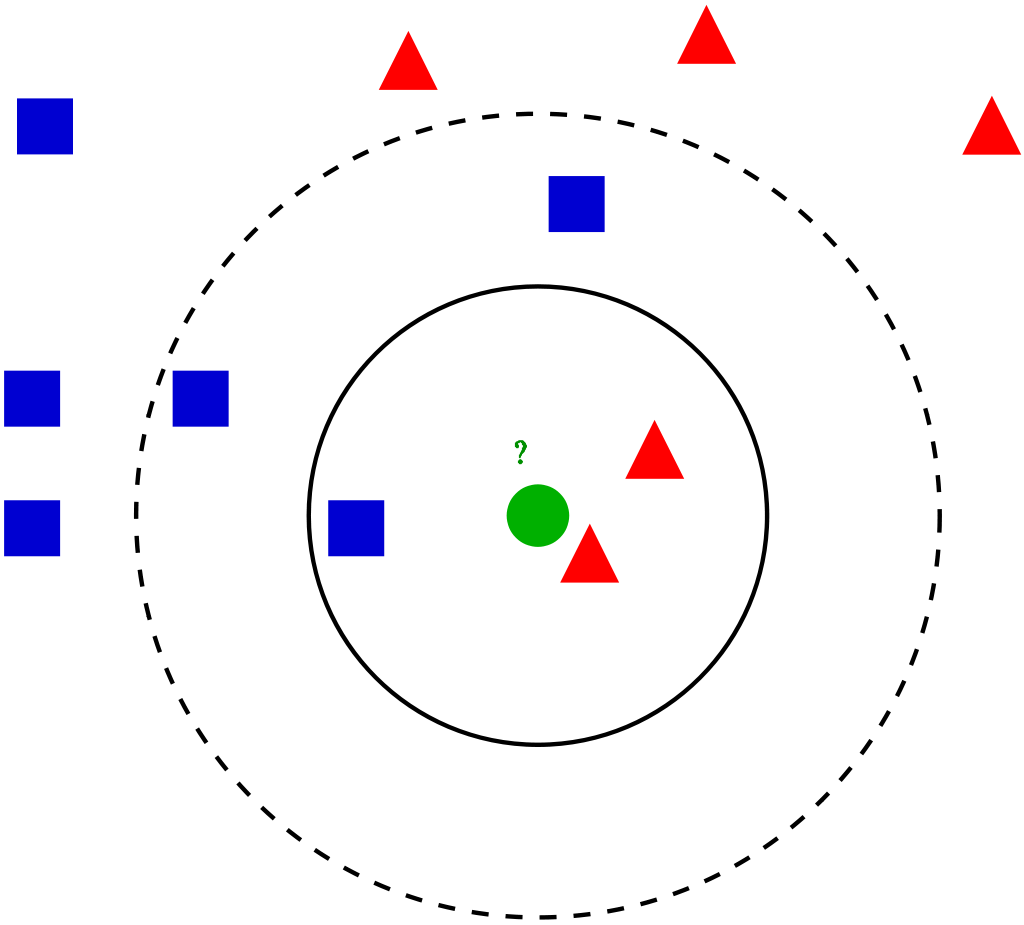
K Vicini più vicini (Modello KNN)
Può essere utilizzato dalla classe KNearestNeighbors. Sono semplici e facili da implementare. Per una voce immessa nel set di dati, los K vecinos más cercanos ayudan a encontrar las k instancias más similares en el conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... Cualquiera de los valores promedio de la medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... de los vecinos se toma como valor para esa entrada.
fonte: unsplash
Il metodo per trovare il valore può essere fornito come argomento, il cui valore predefinito è “Minkowski ·”, una combinazione di distanze “euclideo” e “Manhattan”.
Le previsioni possono essere lente quando i dati sono grandi e di scarsa qualità. Poiché la previsione deve tenere conto di tutti i punti dati, Il modello occuperà più spazio durante l'addestramento.
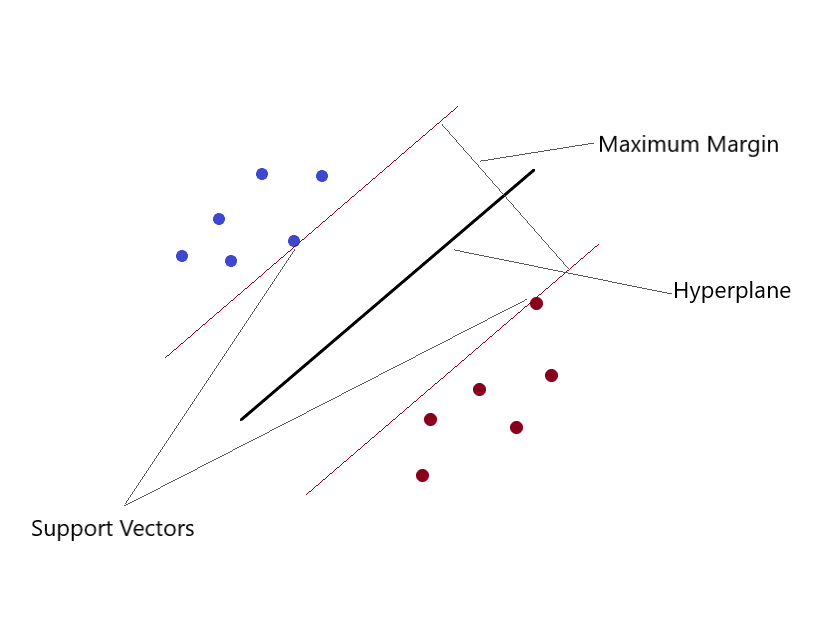
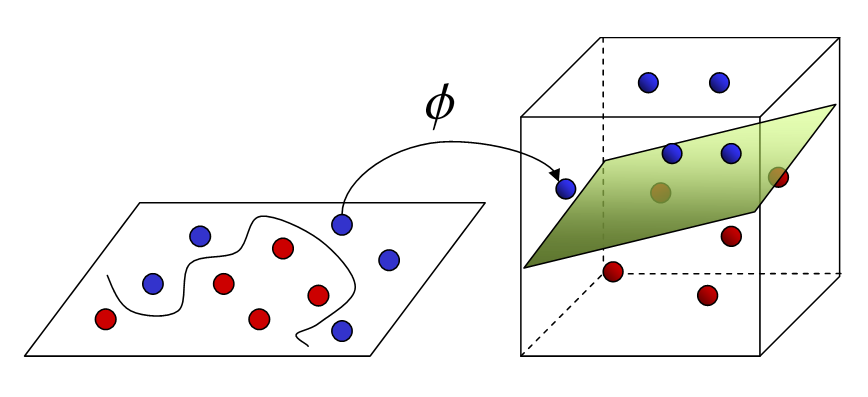
Supporta macchine vettoriali (SVM)
Può risolvere problemi di regressione lineare e non lineare. Creiamo un modello SVM utilizzando la classe SVR. in un spazio multidimensionale, Quando abbiamo più di una variabile per determinare l'output, quindi ciascuno dei punti non è più un punto come in 2D, ma sono vettori. Il tipo più estremo di assegnazione del valore può essere eseguito utilizzando questo metodo. Si separano le classi e si assegnano loro valori. La separazione è dovuta al concetto di Max-Margin (un iperpiano). Ciò che dovresti tenere a mente è che gli SVM non sono adatti per prevedere i valori per i set di allenamento di grandi dimensioni.. SVM fallimento Quando i dati hanno più rumore.
fonte: unsplash
fonte: unsplash
Se i dati di training sono molto più grandi del numero di funzioni, KNN è meglio di SVM. SVM supera KNN quando ci sono funzionalità più grandi e meno dati di addestramento.
Bene, siamo giunti alla fine di questo articolo, abbiamo brevemente discusso i tipi di algoritmi di regressione (teoria). Questo è Surabhi, Ho una laurea in tecnologia. Dai un'occhiata al mio Profilo LinkedIn e connettiti. Spero che ti sia piaciuto leggere questo. Grazie.
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





