Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Comprender esta red nos ayuda a obtener información sobre las razones subyacentes en los modelos avanzados de Deep Learning. El perceptrón multicapa se usa comúnmente en problemas de regresión simple. tuttavia, los MLP no son ideales para procesar patrones con datos secuenciales y multidimensionales.
🙄 Un perceptrón multicapa se esfuerza por recordar patrones en datos secuenciales, A causa di ciò, requiere una “gran” cantidad de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... para procesar datos multidimensionales.
MLP, CNN y RNN no hacen todo …
Gran parte de su éxito proviene de identificar su objetivo y la buena elección de algunos parámetros, Che cosa Funzione di perdita, Ottimizzatore, e Regularizador.
También disponemos de datos ajenos al entorno de formación. El papel del regularizador es garantizar que el modelo entrenado se generalice a nuevos datos.
Set di dati MNIST
Supongamos que nuestro objetivo es crear una red para identificar números basados en dígitos escritos a mano. Ad esempio, cuando la entrada a la red es una imagen de un número 8, la previsión correspondiente también debe ser 8.
🤷🏻♂️ Este es un trabajo básico de clasificación con redes neuronales.
Antes de analizar el modelo MLP, es esencial comprender el conjunto de datos del MNIST. Se utiliza para explicar y validar muchas teorías de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... porque las 70.000 imágenes que contiene son pequeñas pero suficientemente ricas en información;

MNIST es una colección de dígitos que van del 0 al 9. Tiene un conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... a partire dal 60.000 imágenes y 10.000 pruebas clasificadas en categorías.
Usar el conjunto de datos MNIST en TensorFlow es simple.
importare insensibile come per esempio a partire dal tensorflow.keras.datasets importare mnist (x_treno, y_train), (x_test, y_test) = mnist.load_data()
il mnist.load_data () El método es conveniente, ya que no es necesario cargar las 70.000 imágenes y sus etiquetas.
Antes de entrar en el clasificador de Perceptrón Multicapa, es fundamental tener en cuenta que, si bien los datos del MNIST constan de tensores bidimensionales, se deben remodelar, según el tipo de livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche.....
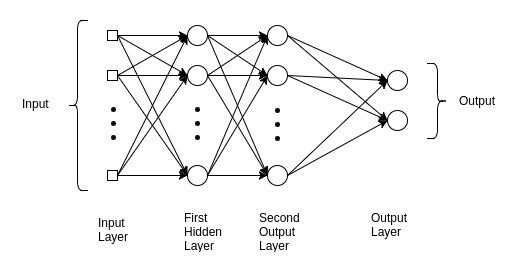
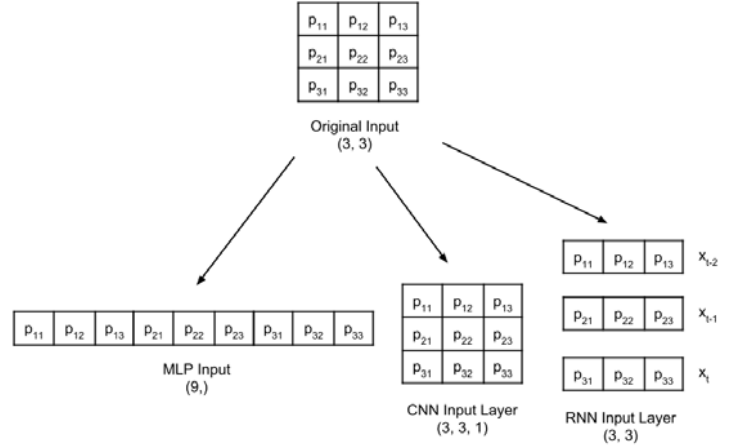
Se cambia la forma de una imagen en escala de grises de 3 × 3 para las capas de entrada MLP, CNN y RNN:
Las etiquetas tienen forma de dígitos, del 0 al 9.
num_labels = len(np.unique(y_train)) Stampa("total de labels:T{}".formato(num_labels)) Stampa("etichette:ttt{0}".formato(np.unique(y_train)))
⚠️ Esta representación no es adecuada para la capa de pronóstico que genera probabilidad por clase. El formato más adecuado es one-hot, un vector de 10 dimensiones como todos los valores 0, excepto el indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... de clase. Ad esempio, si la etiqueta es 4, el vector equivalente es [0,0,0,0, 1, 0,0,0,0,0].
En Deep Learning, los datos se almacenan en un tensoreI tensori sono strutture matematiche che generalizzano concetti come scalari e vettori. Sono utilizzati in varie discipline, compresa la fisica, Ingegneria e Machine Learning, per rappresentare dati multidimensionali. Un tensore può essere visualizzato come una matrice multidimensionale, che consente di modellare relazioni complesse tra variabili diverse. La loro versatilità e capacità di gestire grandi volumi di informazioni li rendono strumenti fondamentali nell'analisi e nell'elaborazione dei dati..... El término tensor se aplica a un tensor escalar (tensor 0D), vector (tensor 1D), Sede centrale (tensor bidimensional) e tensor multidimensionalLos tensores multidimensionales son estructuras matemáticas que generalizan la noción de escalares, vectores y matrices a dimensiones superiores. Se utilizan ampliamente en campos como la física, la ingeniería y el aprendizaje automático, permitiendo representar y manipular datos complejos de manera eficiente. Su capacidad para almacenar información en múltiples dimensiones facilita el análisis y la modelización de fenómenos reales, contribuyendo a avances en diversas disciplinas científicas y tecnológicas.....
#converter em one-hot from tensorflow.keras.utils import to_categorical y_train = to_categorical(y_train) y_test = to_categorical(y_test)
Nuestro modelo es un MLP, por lo que sus entradas deben ser un tensor 1D. come tale, x_train y x_test deben transformarse en [60,000, 2828] e [10,000, 2828],
possono fare poco, el tamaño de -1 significa permitir que la biblioteca calcule la dimensión correcta. En el caso de x_train, è 60.000.
image_size = x_train.shape[1] input_size = image_size * image_size print("x_treno:T{}".formato(x_train.shape)) Stampa("x_test:tt{}n".formato(x_test.shape)) x_train = np.reshape(x_treno, [-1, input_size]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, input_size]) x_test = x_test.astype('float32') / 255 Stampa("x_treno:T{}".formato(x_train.shape)) Stampa("x_test:tt{}".formato(x_test.shape))
OUTPUT:
x_treno: (60000, 28, 28) x_test: (10000, 28, 28) x_treno: (60000, 784) x_test: (10000, 784)
Costruzione del modello
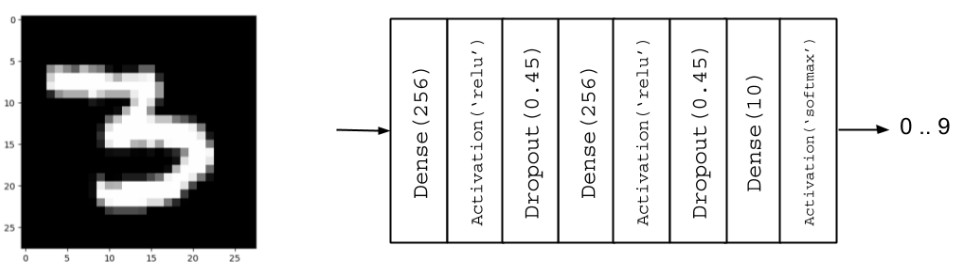
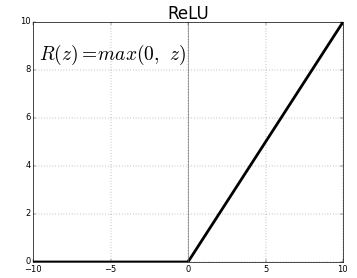
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Attivazione, Ritirarsi # Parameters batch_size = 128 # It is the sample size of inputs to be processed at each training stage. hidden_units = 256 abbandono = 0.45 # Nossa MLP com ReLU e Dropout model = Sequential() modello.aggiungi(Denso(hidden_units, input_dim=input_size)) modello.aggiungi(Attivazione('relu')) modello.aggiungi(Ritirarsi(ritirarsi)) modello.aggiungi(Denso(hidden_units)) modello.aggiungi(Attivazione('relu')) modello.aggiungi(Ritirarsi(ritirarsi)) modello.aggiungi(Denso(num_labels))
regolarizzazione
Una red neuronal tiende a memorizar sus datos de entrenamiento, especialmente si contiene capacidad más que suficiente. In questo caso, la red falla catastróficamente cuando se somete a los datos de prueba.
Este es el caso clásico en el que la red no logra generalizar (AllestimentoEl sobreajuste, o overfitting, es un fenómeno en el aprendizaje automático donde un modelo se ajusta demasiado a los datos de entrenamiento, capturando ruido y patrones irrelevantes. Esto resulta en un rendimiento deficiente en datos no vistos, ya que el modelo pierde capacidad de generalización. Para mitigar el sobreajuste, se pueden emplear técnicas como la regularización, la validación cruzada y la reducción de la complejidad del modelo.... / AllestimentoEl underfitting es un problema común en el aprendizaje automático que ocurre cuando un modelo es demasiado simple para capturar la complejidad de los datos. Esto se traduce en un rendimiento deficiente tanto en el conjunto de entrenamiento como en el de prueba. Las causas del underfitting pueden incluir un modelo inadecuado, características irrelevantes o insuficientes datos. Per risolverlo, se puede optar por modelos más complejos o mejorar la calidad...). Para evitar esta tendencia, el modelo utiliza una capa reguladora. Abandonar.
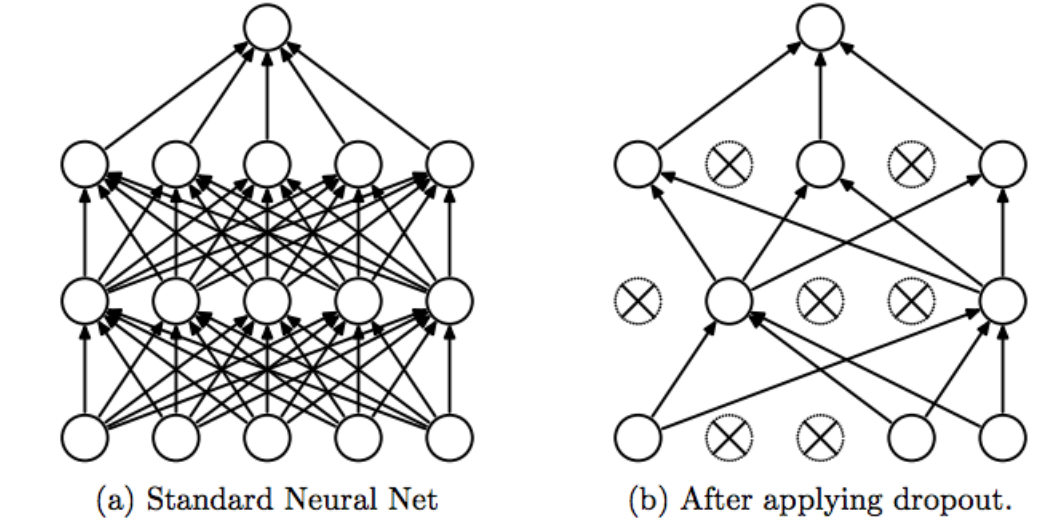
La idea de Dropout es simple. Dada una tasa de descarte (en nuestro modelo, establecemos = 0,45), la capa elimina aleatoriamente esta fracción de unidades.
Ad esempio, si la primera capa tiene 256 unità, después de que se aplica el abandono (0.45), assolo (1 – 0.45) * 255 = 140 unidades participarán en la siguiente capa
La deserción hace que las redes neuronales sean más robustas para los datos de entrada imprevistos, porque la red está entrenada para predecir correctamente, incluso si algunas unidades están ausentes.
⚠️ El abandono solo participa en “giocare a” 🤷🏻♂️ durante el entrenamiento.
Attivazione
Il Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati.... avere 10 unità, seguidas de una función de activación softmax. Il 10 unidades corresponden a las 10 posibles etiquetas, clases o categorías.
La activación de softmax se puede expresar matemáticamente, de acuerdo con la siguiente ecuación:
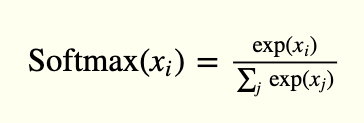
modello.aggiungi(Attivazione('softmax'))
modello.riepilogo()
OUTPUT:
Modello: "sequenziale" _________________________________________________________________ Strato (genere) Parametro forma di output # ================================================================= dense (Denso) (Nessuno, 256) 200960 _________________________________________________________________ activation (Attivazione) (Nessuno, 256) 0 _________________________________________________________________ dropout (Ritirarsi) (Nessuno, 256) 0 _________________________________________________________________ dense_1 (Denso) (Nessuno, 256) 65792 _________________________________________________________________ activation_1 (Attivazione) (Nessuno, 256) 0 _________________________________________________________________ dropout_1 (Ritirarsi) (Nessuno, 256) 0 _________________________________________________________________ densa_2 (Denso) (Nessuno, 10) 2570 _________________________________________________________________ activation_2 (Attivazione) (Nessuno, 10) 0 ================================================== =============== Parametri totali: 269,322 Parametri addestrabili: 269,322 Parametri non addestrabili: 0 _________________________________________________________________
Visualización de modelos
Miglioramento
El propósito de la Optimización es minimizar la función de pérdida. La idea es que si la pérdida se reduce a un nivel aceptable, el modelo aprendió indirectamente la función que asigna las entradas a las salidas. Las métricas de rendimiento se utilizan para determinar si su modelo ha aprendido.
modello.compila(perdita="categorical_crossentropy", ottimizzatore="Adamo", metriche=['precisione'])
-
- Categorical_crossentropy, se utiliza para one-hot
- La precisión es una buena métrica para las tareas de clasificación.
- Adam es un Algoritmo di ottimizzazioneUn algoritmo di ottimizzazione è un insieme di regole e procedure progettate per trovare la migliore soluzione a un problema specifico, Massimizzazione o minimizzazione di una funzione di destinazione. Questi algoritmi sono fondamentali in vari ambiti, come l'ingegneria, L'economia e l'intelligenza artificiale, in cui cerca di migliorare l'efficienza e ridurre i costi. Esistono diversi approcci, compresi gli algoritmi genetici, Programmazione lineare e metodi di ottimizzazione combinatoria.... que se puede utilizar en lugar del procedimiento clásico de descenso de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... Stocastico
📌 Dado nuestro conjunto de entrenamiento, la elección de la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e..., el optimizador y el regularizador, podemos comenzar a entrenar nuestro modelo.
model.fit(x_treno, y_train, epochs=20, batch_size=batch_size)
OUTPUT:
Epoca 1/20
469/469 [==============================] - 1s 3ms/step - perdita: 0.4230 - precisione: 0.8690
....
Epoca 20/20 469/469 [==============================] - 2s 4ms/passo - perdita: 0.0515 - precisione: 0.9835
Valutazione
A questo punto, nuestro modelo de clasificador de dígitos MNIST está completo. Su evaluación de desempeño será el siguiente paso para determinar si el modelo entrenado presentará una solución subóptima
_, acc = model.evaluate(x_test, y_test, batch_size=batch_size, verboso=0) Stampa("nAccuracy: %.1f%%n" % (100.0 * acc))
OUTPUT:
Precisione: 98.4%
continuará…





