Panoramica
- Conoscere il modello all'avanguardia che è Transformers.
- Per favore, comprendi come possiamo implementare Transformers nel problema della didascalia dell'immagine già visto usando Tensorflow
- Confrontando i risultati di Transformers vs Modelli di attenzione.
introduzione
Abbiamo visto che i meccanismi dell'attenzione (nell'articolo precedente) sono diventati parte integrante di convincenti modelli di sequenza e modelli di trasduzione in vari compiti (come didascalia delle immagini), consentendo la modellazione delle dipendenze indipendentemente dalla loro distanza nelle sequenze di input o output.
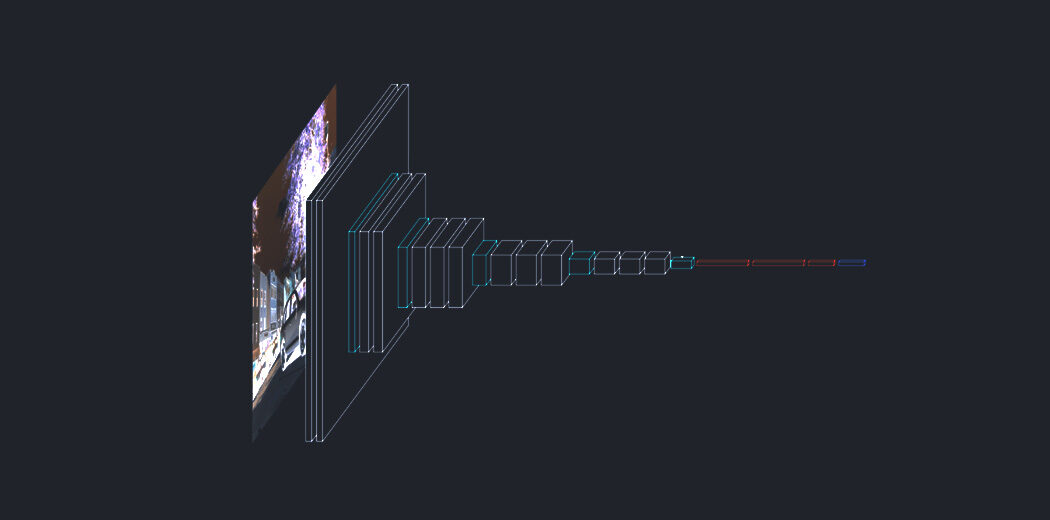
Il trasformatore, un'architettura modello che evita la ricorrenza e, Invece, si basa interamente su un meccanismo di cura per stabilire le dipendenze globali tra input e output. L'architettura Transformer consente una parallelizzazione significativamente maggiore e può ottenere nuovi risultati all'avanguardia nella qualità della traduzione.
In questo articolo, vediamo come si può Implementa il meccanismo di attenzione per la generazione di sottotitoli con Transformers utilizzando TensorFlow.
Prerequisiti prima di iniziare: –
Ti consiglio di leggere questo articolo prima di iniziare:
Sommario
- Architettura del trasformatore
- Implementazione del meccanismo di attenzione per la generazione di sottotitoli con Transformers utilizzando Tensorflow
- Importa le librerie richieste
- Caricamento e pre-elaborazione dei dati
- Definizione di modello
- Codifica posizionale
- Cura multi-testa
- Strato codificatore-decodificatore
- Trasformatore
- Iperparametri del modello
- FormazioneLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... di modelli
- Valutazione BLEU
- Confronto
- Qual è il prossimo?
- Note finali
Architettura del trasformatore
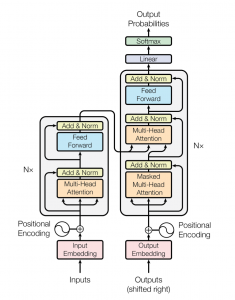
La rete del trasformatore utilizza un'architettura encoder-decodificatore simile a quella di un RNN. La differenza principale è che i trasformatori possono ricevere la preghiera / sequenza ingresso parallelo, vale a dire, non c'è un passo temporale associato all'input e tutte le parole nella frase possono essere passate contemporaneamente.
Iniziamo capendo l'ingresso al trasformatore.
Considera una traduzione dall'inglese al tedesco. Inseriamo l'intera frase in inglese nell'inserto di input. Un livello di inserimento di input può essere pensato come un punto nello spazio in cui parole di significato simile sono fisicamente più vicine l'una all'altra., vale a dire, ogni parola è assegnata a un vettore con valori continui per rappresentare quella parola.
Ora, un problema con questo è che la stessa parola in frasi diverse può avere significati diversi, è qui che entra in gioco la codifica della posizione. Poiché i trasformatori non contengono ricorrenza o convoluzione, affinché il modello utilizzi l'ordine della sequenza, deve utilizzare alcune informazioni sulla posizione relativa o assoluta delle parole in una sequenza. L'idea è di utilizzare pesi fissi o appresi che codificano informazioni relative a una posizione specifica di un token in una frase.
Allo stesso modo, la parola tedesca di destinazione viene inviata alla codifica di output e il suo vettore di codifica posizionale viene passato al blocco del decodificatore.
Il blocco encoder ha due sottolivelli. Il primo è un meccanismo di autocura multi-testa, e il secondo è una semplice rete di feed forward, completamente connesso a seconda della posizione. Per ogni parola, possiamo generare un vettore di attenzione che cattura le relazioni contestuali tra le parole in una frase. L'attenzione a più teste sull'encoder applica uno specifico meccanismo di attenzione chiamato auto-attenzione. L'auto-attenzione consente ai modelli di associare ogni parola nella voce con altre parole.
Oltre ai due sottolivelli in ogni livello dell'encoder, il decoder inserisce un terzo sottolivello, che esegue l'attenzione multi-testa sull'uscita dello stack dell'encoder. Simile all'encoder, usiamo connessioni residue attorno a ciascuno dei sottostrati, seguito dalla normalizzazione del livello. I vettori di attenzione delle parole tedesche e i vettori di attenzione delle frasi inglesi dell'encoder vengono passati alla seconda attenzione a più teste.
Questo blocco di attenzione determinerà quanto strettamente ogni vettore di parole è correlato tra loro.. Qui è dove viene eseguita la mappatura delle parole dall'inglese al tedesco. Il decoder è sormontato da uno strato lineare che funge da classificatore e da un softmax per ottenere le probabilità della parola.
Ora che hai una panoramica di base su come funzionano i trasformatori, vediamo come possiamo implementarlo per l'attività di didascalia delle immagini utilizzando Tensorflow e confrontare i nostri risultati con altri metodi.
Implementazione del meccanismo di attenzione per la generazione di sottotitoli con Transformers utilizzando TensorFlow
Puoi trovare il codice sorgente completo in my Github profilo.
passo 1: – Importa le librerie richieste
Qui useremo Tensorflow per creare il nostro modello e addestrarlo. La maggior parte del credito del codice va a TensorFlow tutorial. Puoi utilizzare i taccuini Google Colab o Kaggle se desideri che una GPU ti alleni.
stringa di importazione importa numpy come np importa panda come pd da numpy import array da PIL import Immagine importare sottaceti importa matplotlib.pyplot come plt sistema di importazione, tempo, tu, avvisi warnings.filterwarnings("ignorare") importare re importazione difficile import tensorflow come tf da tqdm import tqdm da nltk.translate.bleu_score import phrase_bleu da keras.preprocessing.sequence import pad_sequences da keras.utils import to_categorical da keras.utils import plot_model da keras.models import Model da keras.layers import Input da keras.layers import Dense, Normalizzazione batch da keras.layers import LSTM da keras.layers import Incorporamento da keras.layers import Dropout da keras.layers.merge import add da keras.callbacks import ModelCheckpoint da keras.preprocessing.image import load_img, img_to_array da keras.preprocessing.text import Tokenizer da sklearn.utils import shuffle da sklearn.model_selection import train_test_split
passo 2: – Caricamento e pre-elaborazione dei dati
Definisci la nostra immagine e il percorso della didascalia e controlla quante immagini in totale sono presenti nel set di dati.
percorso_immagine = "/content/gdrive/Il mio Drive/FLICKR8K/Flicker8k_Dataset" dir_Flickr_text = "/content/gdrive/Il mio Drive/FLICKR8K/Flickr8k_text/Flickr8k.token.txt" jpgs = os.listdir(percorso_immagine) Stampa("Immagini totali nel set di dati = {}".formato(len(jpg)))
Produzione:
![]()
Creiamo un data frame per memorizzare l'id dell'immagine e le didascalie per facilità d'uso.
file = aperto(dir_Flickr_text,'R') testo = file.leggi() file.chiudi() datatxt = [] per la riga in text.split('n'): col = line.split('T') se len(col) == 1: Continua w = col[0].diviso("#") datatxt.append(w + [col[1].inferiore()]) data = pd.DataFrame(datatxt,colonne=["nome del file","indice","didascalia"]) data = data.reindex(colonne =['indice','nome del file','didascalia']) dati = dati[dati.nomefile != '2258277193_586949ec62.jpg.1'] uni_filenames = np.unique(dati.nomefile.valori) data.head()
Produzione:
Prossimo, Visualizziamo alcune immagini e la loro 5 leggende:
npic = 5 npix = 224 target_size = (npix,npix,3) conteggio = 1 fig = plt.figure(figsize=(10,20)) per jpgfnm in uni_filenames[10:14]: nome file = image_path + '/' + jpgfnm didascalie = elenco(dati["didascalia"].luogo[dati["nome del file"]== jpgfnm].valori) image_load = load_img(nome del file, target_size=target_size) ax = fig.add_subplot(npic,2,contare,xtick=[],yticks=[]) ax.imshow(image_load) conteggio += 1 ax = fig.add_subplot(npic,2,contare) asse.plt('spento') ax.plot() ax.set_xlim(0,1) ax.set_ylim(0,len(didascalie)) per me, didascalia in enumerare(didascalie): ax.text(0,io,didascalia,dimensione del carattere=20) conteggio += 1 plt.mostra()
Produzione:

Prossimo, vediamo qual è la dimensione attuale del nostro vocabolario: –
vocabolario = [] per txt in data.caption.values: vocabolario.estendere(txt.split()) Stampa("Dimensione del vocabolario": %D' % len(set(vocabolario)))
Produzione:
![]() Prossimo, eseguire una pulizia del testo, come rimuovere la punteggiatura, singoli caratteri e valori numerici:
Prossimo, eseguire una pulizia del testo, come rimuovere la punteggiatura, singoli caratteri e valori numerici:
def remove_punctuation(text_original): text_no_punctuation = text_original.translate(stringa.punteggiatura) Restituzione(text_no_punctuation) def remove_single_character(testo): text_len_more_than1 = "" per Word in Text.split(): se len(parola) > 1: text_len_more_than1 += " " + parola Restituzione(text_len_more_than1) def remove_numeric(testo): text_no_numeric = "" per Word in Text.split(): isalpha = word.isalpha() se isalpha: text_no_numeric += " " + parola Restituzione(text_no_numeric) def text_clean(text_original): testo = remove_punctuation(text_original) testo = remove_single_character(testo) testo = remove_numeric(testo) Restituzione(testo) per me, didascalia in enumerare(data.caption.values): newcaption = text_clean(didascalia) dati["didascalia"].iloca[io] = nuova didascalia
Ora diamo un'occhiata alla dimensione del nostro vocabolario dopo la pulizia.
clean_vocabulary = [] per txt in data.caption.values: clean_vocabulary.extend(txt.split()) Stampa("Dimensione del vocabolario pulito": %D' % len(set(vocabolario_pulito)))
Produzione:
![]() Prossimo, salviamo tutti i titoli e i percorsi delle immagini in due liste in modo da poter caricare le immagini contemporaneamente utilizzando il percorso stabilito. Aggiungiamo anche tag ” e ” ad ogni titolo in modo che il modello capisca l'inizio e la fine di ogni titolo.
Prossimo, salviamo tutti i titoli e i percorsi delle immagini in due liste in modo da poter caricare le immagini contemporaneamente utilizzando il percorso stabilito. Aggiungiamo anche tag ” e ” ad ogni titolo in modo che il modello capisca l'inizio e la fine di ogni titolo.
PERCORSO = "/content/gdrive/Il mio Drive/FLICKR8K/Flicker8k_Dataset/" all_captions = [] per la didascalia nei dati["didascalia"].come tipo(str): didascalia = '<cominciare> ' + didascalia+ ' <fine>' all_captions.append(didascalia) all_captions[:10]
Produzione:

all_img_name_vector = [] per annotare nei dati["nome del file"]: full_image_path = PERCORSO + annota all_img_name_vector.append(percorso_immagine_completa) all_img_name_vector[:10]
Produzione:
Ora puoi vedere che abbiamo 40455 percorsi e didascalie delle immagini.
Stampa(F"len(all_img_name_vector) : {len(all_img_name_vector)}") Stampa(F"len(all_captions) : {len(all_captions)}")
Produzione:
![]()
Prenderemo da soli 40000 di ciascuno in modo da poter selezionare correttamente la dimensione del lotto, vale a dire, 625 lotti se dimensione del lotto = 64. Per fare questo, definiamo una funzione per limitare il set di dati a 40000 immagini e didascalie.
def data_limiter(nessuno,didascalie_totali,all_img_name_vector): train_captions, img_name_vector = casuale(didascalie_totali,all_img_name_vector,random_state=1) train_captions = train_captions[:nessuno] img_name_vector = img_name_vector[:nessuno] train_captions di ritorno,img_name_vector train_captions,img_name_vector = data_limiter(40000,didascalie_totali,all_img_name_vector)
passo 3: – Definizione del modello
Definiamo il modello di estrazione delle caratteristiche dell'immagine usando InceptionV3. Dobbiamo ricordare che non abbiamo bisogno di classificare le immagini qui, dobbiamo solo estrarre un vettore immagine per le nostre immagini. Perciò, rimuoviamo lo strato softmax dal modello. Dobbiamo preelaborare tutte le immagini alla stessa dimensione, vale a dire, 299 × 299 prima di inserirli nel modello, e la forma di output di questo livello è 8x8x2048.
def load_image(percorso_immagine): img = tf.io.read_file(percorso_immagine) img = tf.image.decode_jpeg(img, canali=3) img = tf.image.resize(img, (299, 299)) img = tf.keras.applications.inception_v3.preprocess_input(img) restituire img, image_path image_model = tf.keras.applications.InceptionV3(include_top=Falso, pesi="imagenet") new_input = image_model.input hidden_layer = image_model.layers[-1].output image_features_extract_model = tf.keras.Model(nuovo_input, hidden_layer)
Prossimo, assegniamo il nome di ogni immagine alla funzione per caricare l'immagine. Elaboreremo in anticipo ogni immagine con InceptionV3 e metteremo in cache l'output su disco e le caratteristiche dell'immagine verranno riformattate in 64 × 2048.
encode_train = ordinato(set(img_name_vector)) image_dataset = tf.data.Dataset.from_tensor_slices(encode_train) image_dataset = image_dataset.map(load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE).lotto(64)
Estraiamo le caratteristiche e le memorizziamo nelle rispettive .npy file e quindi passare quelle caratteristiche attraverso l'encoder.I file NPY memorizzano tutte le informazioni necessarie per ricostruire un array su qualsiasi computer, comprese le informazioni sul tipo e sulla forma.
per img, percorso in tqdm(image_dataset): batch_features = image_features_extract_model(img) batch_features = tf.reshape(batch_features, (batch_features.shape[0], -1, batch_features.shape[3])) per bf, p in zip(batch_features, il percorso): path_of_feature = p.numpy().decodificare("utf-8") np.save(path_of_feature, bf.numpy())
Prossimo, convertiamo i sottotitoli in token e creiamo un vocabolario di tutte le parole uniche nei dati. Limiteremo anche la dimensione del vocabolario a 5000 parole principali per risparmiare memoria. Sostituiremo le parole non presenti nel vocabolario con il token
top_k = 5000 tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k, oov_token="<unk>", filtri="!"#$%&()*+.,-/:;[e-mail protetta][]^_`{|}~ ") tokenizer.fit_on_texts(train_captions) train_seqs = tokenizer.texts_to_sequences(train_captions) tokenizer.word_index['<pad>'] = 0 tokenizer.index_word[0] = '<pad>' train_seqs = tokenizer.texts_to_sequences(train_captions) cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')
Prossimo, creare set di addestramento e convalida utilizzando una suddivisione 80-20:
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,cap_vector, test_size=0.2, stato_casuale=0)
Prossimo, creiamo un set di dati tf.data da utilizzare nell'addestramento del nostro modello.
BATCH_SIZE = 64 BUFFER_SIZE = 1000 num_steps = len(img_name_train) // DIMENSIONE DEL LOTTO def map_func(nome_img, berretto): img_tensor = np.load(img_name.decode('utf-8')+'.npy') Restituzione img_tensore, berretto dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train)) set di dati = set di dati.carta geografica(lambda articolo1, articolo2: tf.numpy_function(map_func, [articolo1, articolo2], [tf.float32, tf.int32]),num_parallel_calls=tf.data.experimental.AUTOTUNE) dataset = dataset.shuffle(DIMENSIONE BUFFER).lotto(DIMENSIONE DEL LOTTO) dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
passo 4: – Codifica posizionale
La codifica posizionale utilizza funzioni seno e coseno di diverse frequenze. Per ogni indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... dispari nel vettore di input, creare un vettore usando la funzione cos, per ogni indice pari, crea un vettore usando la funzione sin. Dopo, aggiungi quei vettori ai loro incorporamenti di input corrispondenti, che fornisce alla rete informazioni sulla posizione di ciascun vettore.
def get_angles(posizione, io, d_model): angle_rates = 1 / np.power(10000, (2 * (io//2)) / ad esempio float32(d_model)) Restituzione posizione * angolo_tassi def codifica_posizionale_1d(posizione, d_model): angle_rads = get_angles(np.arange(posizione)[:, ad esempio newaxis], np.arange(d_model)[ad esempio newaxis, :], d_model) angolo_rads[:, 0::2] = np.sin(angolo_rads[:, 0::2]) angolo_rads[:, 1::2] = es. cos(angolo_rads[:, 1::2]) pos_encoding = angle_rads[ad esempio newaxis, ...] Restituzione tf.cast(pos_encoding, dtype=tf.float32) def codifica_posizionale_2d(riga,col,d_model): affermare d_model % 2 == 0 row_pos = np.repeat(np.arange(riga),col)[:,ad esempio newaxis] col_pos = np.repeat(np.expand_dims(np.arange(col),0),riga,asse=0).rimodellare(-1,1) angle_rads_row = get_angles(riga_pos,np.arange(d_model//2)[ad esempio newaxis,:],d_model//2) angle_rads_col = get_angles(col_pos,np.arange(d_model//2)[ad esempio newaxis,:],d_model//2) angolo_rads_row[:, 0::2] = np.sin(angolo_rads_row[:, 0::2]) angolo_rads_row[:, 1::2] = es. cos(angolo_rads_row[:, 1::2]) angle_rads_col[:, 0::2] = np.sin(angle_rads_col[:, 0::2]) angle_rads_col[:, 1::2] = es. cos(angle_rads_col[:, 1::2]) pos_encoding = np.concatenate([angolo_rads_row,angle_rads_col],asse=1)[ad esempio newaxis, ...] Restituzione tf.cast(pos_encoding, dtype=tf.float32)
passo 5: – Cura multi-testa
Calcola i pesi di attenzione. Q, K, v deve avere dimensioni principali corrispondenti. K, v deve avere la corrispondente penultima dimensione, vale a dire: seq_len_k = seq_len_v. La maschera ha forme diverse a seconda del tipo (imbottito o guardare avanti) ma deve essere trasmissibile per l'addizione.
def create_padding_mask(seguito): seq = tf.cast(tf.math.uguale(seguito, 0), tf.float32) Restituzione seguito[:, tf.newaxis, tf.newaxis, :] # (dimensione del lotto, 1, 1, seq_len) def create_look_ahead_mask(dimensione): maschera = 1 - tf.linalg.band_part(tf.ones((dimensione, dimensione)), -1, 0) Restituzione maschera # (seq_len, seq_len) def scaled_dot_product_attention(Q, K, v, maschera): matmul_qk = tf.matmul(Q, K, transpose_b=Vero) # (..., seq_len_q, seq_len_k) dk = tf.cast(forma.tf(K)[-1], tf.float32) scaled_attention_logits = matmul_qk / tf.math.sqrt(dk) . Se la maschera non è Nessuno: scaled_attention_logits += (maschera * -1e9) attention_weights = tf.nn.softmax(scaled_attention_logits, asse=-1) output = tf.matmul(pesi_attenzione, v) # (..., seq_len_q, profondità_v) Restituzione produzione, pesi_attenzione classe MultiHeadAttenzione(tf.duro.strati.Strato): def __dentro__(se stesso, d_model, num_heads): super(MultiHeadAttenzione, se stesso).__dentro__() se stesso.num_heads = num_heads se stesso.d_model = d_model affermare d_model % se stesso.num_heads == 0 se stesso.profondità = d_model // se stesso.num_heads se stesso.wq = tf.keras.layers.Dense(d_model) se stesso.wk = tf.keras.layers.Dense(d_model) se stesso.wv = tf.keras.layers.Dense(d_model) se stesso.denso = tf.keras.layers.Dense(d_model) def split_heads(se stesso, X, dimensione del lotto): x = tf.reshape(X, (dimensione del lotto, -1, se stesso.num_heads, se stesso.profondità)) Restituzione tf.transpose(X, permanente=[0, 2, 1, 3]) def chiamata(se stesso, v, K, Q, maschera=Nessuno): batch_size = tf.shape(Q)[0] q = se stesso.wq(Q) # (dimensione del lotto, seq_len, d_model) k = se stesso.sett(K) # (dimensione del lotto, seq_len, d_model) v = se stesso.wv(v) # (dimensione del lotto, seq_len, d_model) q = se stesso.split_heads(Q, dimensione del lotto) # (dimensione del lotto, num_heads, seq_len_q, profondità) k = se stesso.split_heads(K, dimensione del lotto) # (dimensione del lotto, num_heads, seq_len_k, profondità) v = se stesso.split_heads(v, dimensione del lotto) # (dimensione del lotto, num_heads, seq_len_v, profondità) scaled_attention, pesi_attenzione = scaled_dot_product_attention(Q, K, v, maschera) scaled_attention = tf.transpose(scaled_attention, permanente=[0, 2, 1, 3]) # (dimensione del lotto, seq_len_q, num_heads, profondità) concat_attention = tf.reshape(scaled_attention, (dimensione del lotto, -1, se stesso.d_model)) # (dimensione del lotto, seq_len_q, d_model) output = se stesso.denso(concat_attention) # (dimensione del lotto, seq_len_q, d_model) Restituzione produzione, pesi_attenzione def point_wise_feed_forward_network(d_model, dff): Restituzione tf.keras.Sequential([ tf.strati.duri.Densi(dff, attivazione='relu'), # (dimensione del lotto, seq_len, dff) tf.strati.duri.Densi(d_model) # (dimensione del lotto, seq_len, d_model)])
passo 6: – Strato codificatore-decodificatore
classe EncoderLayer(tf.duro.strati.Strato): def __dentro__(se stesso, d_model, num_heads, dff, Vota=0.1): super(EncoderLayer, se stesso).__dentro__() se stesso.mha = MultiHeadAttenzione(d_model, num_heads) se stesso.ffn = point_wise_feed_forward_network(d_model, dff) se stesso.layernorm1 = tf.hard.layers.LayerNormalization(epsilon=1e-6) se stesso.layernorm2 = tf.hard.layers.LayerNormalization(epsilon=1e-6) se stesso.dropout1 = tf.keras.layers.Dropout(Vota) se stesso.dropout2 = tf.keras.layers.Dropout(Vota) def chiamata(se stesso, X, addestramento, maschera=Nessuno): attn_output, _ = se stesso.mha(X, X, X, maschera) # (dimensione del lotto, input_seq_len, d_model) attn_output = se stesso.abbandono1(attn_output, allenamento=allenamento) out1 = se stesso.norma livello1(X + attn_output) # (dimensione del lotto, input_seq_len, d_model) ffn_output = se stesso.ffn(out1) # (dimensione del lotto, input_seq_len, d_model) ffn_output = se stesso.abbandono2(ffn_output, allenamento=allenamento) out2 = se stesso.layerernorm2(out1 + ffn_output) # (dimensione del lotto, input_seq_len, d_model) Restituzione out2
classe DecoderLayer(tf.duro.strati.Strato): def __dentro__(se stesso, d_model, num_heads, dff, Vota=0.1): super(DecoderLayer, se stesso).__dentro__() se stesso.mha1 = MultiHeadAttenzione(d_model, num_heads) se stesso.mha2 = MultiHeadAttenzione(d_model, num_heads) se stesso.ffn = point_wise_feed_forward_network(d_model, dff) se stesso.layernorm1 = tf.hard.layers.LayerNormalization(epsilon=1e-6) se stesso.layernorm2 = tf.hard.layers.LayerNormalization(epsilon=1e-6) se stesso.layernorm3 = tf.hard.layers.LayerNormalization(epsilon=1e-6) se stesso.dropout1 = tf.keras.layers.Dropout(Vota) se stesso.dropout2 = tf.keras.layers.Dropout(Vota) se stesso.dropout3 = tf.keras.layers.Dropout(Vota) def chiamata(se stesso, X, enc_output, addestramento,look_ahead_mask=Nessuno, padding_mask=Nessuno): attenzione1, attn_weights_block1 = se stesso.mha1(X, X, X, look_ahead_mask) # (dimensione del lotto, target_seq_len, d_model) attn1 = se stesso.abbandono1(attenzione1, allenamento=allenamento) out1 = se stesso.norma livello1(attenzione1 + X) attn2, attn_weights_block2 = se stesso.mha2(enc_output, enc_output, out1, padding_mask) attn2 = se stesso.abbandono2(attn2, allenamento=allenamento) out2 = se stesso.layerernorm2(attn2 + out1) # (dimensione del lotto, target_seq_len, d_model) ffn_output = se stesso.ffn(out2) # (dimensione del lotto, target_seq_len, d_model) ffn_output = se stesso.abbandono3(ffn_output, allenamento=allenamento) out3 = se stesso.layerernorm3(ffn_output + out2) # (dimensione del lotto, target_seq_len, d_model) Restituzione fuori3, attn_weights_block1, attn_weights_block2
classe Codificatore(tf.duro.strati.Strato): def __dentro__(se stesso, num_layers, d_model, num_heads, dff, dimensione_riga,col_size,Vota=0.1): super(Codificatore, se stesso).__dentro__() se stesso.d_model = d_model se stesso.num_layers = num_layers se stesso.embedding = tf.keras.layers.Dense(se stesso.d_model,attivazione='relu') se stesso.pos_encoding = positional_encoding_2d(dimensione_riga,col_size,se stesso.d_model) se stesso.enc_layers = [EncoderLayer(d_model, num_heads, dff, Vota) per _ in gamma(num_layers)] se stesso.dropout = tf.keras.layers.Dropout(Vota) def chiamata(se stesso, X, addestramento, maschera=Nessuno): seq_len = tf.shape(X)[1] x = se stesso.incorporamento(X) # (dimensione del lotto, input_seq_len(H*W), d_model) x += se stesso.pos_encoding[:, :seq_len, :] x = se stesso.ritirarsi(X, allenamento=allenamento) per io in gamma(se stesso.num_layers): x = se stesso.enc_layers[io](X, addestramento, maschera) Restituzione X # (dimensione del lotto, input_seq_len, d_model)
classe decodificatore(tf.duro.strati.Strato): def __dentro__(se stesso, num_layers,d_model,num_heads,dff, target_vocab_size, codifica_posizione_massima, Vota=0.1): super(decodificatore, se stesso).__dentro__() se stesso.d_model = d_model se stesso.num_layers = num_layers se stesso.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model) se stesso.pos_encoding = positional_encoding_1d(codifica_posizione_massima, d_model) se stesso.dec_layers = [DecoderLayer(d_model, num_heads, dff, Vota) per _ in gamma(num_layers)] se stesso.dropout = tf.keras.layers.Dropout(Vota) def chiamata(se stesso, X, enc_output, addestramento,look_ahead_mask=Nessuno, padding_mask=Nessuno): seq_len = tf.shape(X)[1] pesi_attenzione = {} x = se stesso.incorporamento(X) # (dimensione del lotto, target_seq_len, d_model) x *= tf.math.sqrt(tf.cast(se stesso.d_model, tf.float32)) x += se stesso.pos_encoding[:, :seq_len, :] x = se stesso.ritirarsi(X, allenamento=allenamento) per io in gamma(se stesso.num_layers): X, blocco1, blocco2 = se stesso.dec_layers[io](X, enc_output, addestramento, look_ahead_mask, padding_mask) pesi_attenzione['decoder_layer{}_blocco1'.formato(io+1)] = blocco1 pesi_attenzione['decoder_layer{}_blocco2'.formato(io+1)] = blocco2 Restituzione X, pesi_attenzione
passo 7: – Trasformatore
classe Trasformatore(tf.duro.Modello): def __dentro__(se stesso, num_layers, d_model, num_heads, dff,dimensione_riga,col_size, target_vocab_size,max_pos_encoding, Vota=0.1): super(Trasformatore, se stesso).__dentro__() se stesso.codificatore = codificatore(num_layers, d_model, num_heads, dff,dimensione_riga,col_size, Vota) se stesso.decodificatore = decodificatore(num_layers, d_model, num_heads, dff, target_vocab_size,max_pos_encoding, Vota) se stesso.final_layer = tf.keras.layers.Dense(target_vocab_size) def chiamata(se stesso, inp, catrame, addestramento,look_ahead_mask=Nessuno,dec_padding_mask=Nessuno,enc_padding_mask=Nessuno ): enc_output = se stesso.codificatore(inp, addestramento, enc_padding_mask) # (dimensione del lotto, inp_seq_len, d_model ) dec_output, pesi_attenzione = se stesso.decodificatore( catrame, enc_output, addestramento, look_ahead_mask, dec_padding_mask) final_output = se stesso.final_layer(dec_output) # (dimensione del lotto, tar_seq_len, target_vocab_size) Restituzione output_finale, pesi_attenzione
passo 8: – Modello di iperparametro
Definire i parametri per l'allenamento:
num_layer = 4 d_model = 512 dff = 2048 num_heads = 8 dimensione_riga = 8 col_size = 8 target_vocab_size = top_k + 1 dropout_rate = 0.1
classe Programma personalizzato(tf.duro.ottimizzatori.orari.Programma della velocità di apprendimento): def __dentro__(se stesso, d_model, warmup_steps=4000): super(Programma personalizzato, se stesso).__dentro__() se stesso.d_model = d_model se stesso.d_model = tf.cast(se stesso.d_model, tf.float32) se stesso.warmup_steps = warmup_steps def __chiamata__(se stesso, fare un passo): arg1 = tf.math.rsqrt(fare un passo) arg2 = passo * (se stesso.warmup_steps ** -1.5) Restituzione tf.math.rsqrt(se stesso.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model) ottimizzatore = tf.hard.optimizers.Adam(tasso_di_apprendimento, beta_1=0.9, beta_2=0.98, epsilon=1e-9) loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=Vero, riduzione='nessuno') def loss_function(vero, pred): maschera = tf.math.logical_not(tf.math.uguale(vero, 0)) perdita_ = perdita_oggetto(vero, pred) maschera = tf.cast(maschera, dtype=loss_.dtype) perdita_ *= maschera Restituzione tf.reduce_sum(perdita_)/tf.reduce_sum(maschera)
train_loss = tf.keras.metrics.Mean(nome="train_loss") train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(nome="train_accuracy") trasformatore = trasformatore(num_layer,d_model,num_heads,dff,dimensione_riga,col_size,target_vocab_size, max_pos_encoding=target_vocab_size,rate=dropout_rate)
passo 9: – Formazione modello
def create_masks_decoder(catrame): look_ahead_mask = create_look_ahead_mask(forma.tf(catrame)[1]) dec_target_padding_mask = create_padding_mask(catrame) maschera_combinata = tf.maximum(dec_target_padding_mask, look_ahead_mask) Restituzione maschera_combinata
@tf.funzione def train_step(img_tensore, catrame): tar_inp = tar[:, :-1] tar_real = tar[:, 1:] dec_mask = create_masks_decoder(tar_inp) insieme a tf.GradientTape() come nastro: predizioni, _ = trasformatore(img_tensore, tar_inp,Vero, maschera_dec) perdita = funzione_perdita(tar_real, predizioni) gradients = tape.gradient(perdita, trasformatore.trainable_variables) ottimizzatore.apply_gradients(cerniera lampo(gradienti, trasformatore.trainable_variables)) train_loss(perdita) train_accuracy(tar_real, predizioni)
per epoca in gamma(30): inizio = ora.ora() train_loss.reset_states() train_accuracy.reset_states() per (lotto, (img_tensore, catrame)) in enumerare(set di dati): train_step(img_tensore, catrame) Se lotto % 50 == 0: Stampa ('Epoca {} Lotto {} Perdita {:.4F} Precisione {:.4F}'.formato( epoca + 1, lotto, train_loss.result(), train_accuracy.result())) Stampa ('Epoca {} Perdita {:.4F} Precisione {:.4F}'.formato(epoca + 1, train_loss.result(), train_accuracy.result())) Stampa ('Tempo impiegato per 1 epoca: {} secn'.formato(tempo.tempo() - cominciare))
passo 10: – Valutazione BLEU
def valutare(Immagine): temp_input = tf.expand_dims(load_image(Immagine)[0], 0) img_tensor_val = image_features_extract_model(input_temp) img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3])) start_token = tokenizer.word_index['<cominciare>'] end_token = tokenizer.word_index['<fine>'] decoder_input = [start_token] output = tf.expand_dims(ingresso_decodificatore, 0) #gettoni risultato = [] #lista di parole Fo io in gamma(100): dec_mask = create_masks_decoder(produzione) predizioni, pesi_attenti = trasformatore(img_tensor_val,produzione,falso,maschera_dec) previsioni = previsioni[: ,-1:, :] # (dimensione del lotto, 1, vocab_size) id_predetto = tf.cast(tf.argmax(predizioni, asse=-1), tf.int32) Se id_predetto == token_finale: Restituzione risultato,tf.squeeze(produzione, asse=0), pesi_attenzione risultato.append(tokenizer.index_word[int(id_predetto)]) output = tf.concat([produzione, id_predetto], asse=-1) Restituzione risultato,tf.squeeze(produzione, asse=0), pesi_attenzione
rid = np.random.randint(0, len(img_name_val)) immagine = img_name_val[sbarazzarsi] didascalia_reale = ' '.aderire([tokenizer.index_word[io] per io in cap_val[sbarazzarsi] Se io non in [0]]) didascalia,risultato,pesi_attenzione = valutare(Immagine) primo = real_caption.split(' ', 1)[1] real_caption = first.rsplit(' ', 1)[0] per io in didascalia: Se io=="<unk>": didascalia.rimuovi(io) per io in didascalia_reale: Se io=="<unk>": real_caption.remove(io) risultato_unione = ' '.aderire(didascalia) result_final = result_join.rsplit(' ', 1)[0] real_appn = [] real_appn.append(real_caption.split()) riferimento = real_appn candidato = didascalia punteggio = frase_bleu(riferimento, candidato, pesi=(1.0,0,0,0)) Stampa(F"BLU-1 punteggio: {punteggio*100}") punteggio = frase_bleu(riferimento, candidato, pesi=(0.5,0.5,0,0)) Stampa(F"BLU-2 punteggio: {punteggio*100}") punteggio = frase_bleu(riferimento, candidato, pesi=(0.3,0.3,0.3,0)) Stampa(F"BLU-3 punteggio: {punteggio*100}") punteggio = frase_bleu(riferimento, candidato, pesi=(0.25,0.25,0.25,0.25)) Stampa(F"BLU-4 punteggio: {punteggio*100}") Stampa ("Didascalia reale":', didascalia_reale) Stampa ("Didascalia prevista":', ' '.aderire(didascalia)) temp_image = np.array(Immagine.aprire(Immagine)) plt.imshow(temp_image)
Produzione:

rid = np.random.randint(0, len(img_name_val)) immagine = img_name_val[sbarazzarsi] didascalia_reale = ' '.aderire([tokenizer.index_word[io] per io in cap_val[sbarazzarsi] Se io non in [0]]) didascalia,risultato,pesi_attenzione = valutare(Immagine) primo = real_caption.split(' ', 1)[1] real_caption = first.rsplit(' ', 1)[0] per io in didascalia: Se io=="<unk>": didascalia.rimuovi(io) per io in didascalia_reale: Se io=="<unk>": real_caption.remove(io) risultato_unione = ' '.aderire(didascalia) result_final = result_join.rsplit(' ', 1)[0] real_appn = [] real_appn.append(real_caption.split()) riferimento = real_appn candidato = didascalia punteggio = frase_bleu(riferimento, candidato, pesi=(1.0,0,0,0)) Stampa(F"BLU-1 punteggio: {punteggio*100}") punteggio = frase_bleu(riferimento, candidato, pesi=(0.5,0.5,0,0)) Stampa(F"BLU-2 punteggio: {punteggio*100}") punteggio = frase_bleu(riferimento, candidato, pesi=(0.3,0.3,0.3,0)) Stampa(F"BLU-3 punteggio: {punteggio*100}") punteggio = frase_bleu(riferimento, candidato, pesi=(0.25,0.25,0.25,0.25)) Stampa(F"BLU-4 punteggio: {punteggio*100}") Stampa ("Didascalia reale":', didascalia_reale) Stampa ("Didascalia prevista":', ' '.aderire(didascalia)) temp_image = np.array(Immagine.aprire(Immagine)) plt.imshow(temp_image)
Produzione:

passo 11: – Confronto
Confrontiamo i punteggi BLEU ottenuti nell'articolo precedente utilizzando l'Attenzione di Bahdanau rispetto ai nostri Transformers.

I punteggi BLEU a sinistra usano l'attenzione di Bahdanau e i punteggi BLEU a destra usano Transformers. Come possiamo vedere, Il trasformatore funziona molto meglio di un semplice modello di cura.


Ed eccolo! Abbiamo implementato con successo i trasformatori utilizzando Tensorflow e abbiamo visto come può produrre risultati all'avanguardia..
Note finali
In sintesi, I trasformatori sono migliori di tutte le altre architetture che abbiamo visto prima perché evitano totalmente la ricorsione, elaborando le frasi nel loro insieme e imparando le relazioni tra le parole grazie a meccanismi di attenzione a più teste e incorporamenti posizionali. Va inoltre notato che i trasformatori che utilizzano Tensorflow possono acquisire solo dipendenze all'interno della dimensione di ingresso fissa utilizzata per addestrarli.
Ci sono molti trasformatori nuovi e potenti come Transformer-XL, Trasformatore aggrovigliato, Trasformatore di memoria mesh che può essere implementato anche per applicazioni come Image Captions per ottenere risultati ancora migliori.
Trovi utile questo articolo? Condividi il tuo prezioso feedback nella sezione commenti qui sotto.. Sentiti libero di condividere anche i tuoi libri di codici completi, che sarà utile ai membri della nostra comunità.





