introduzione
Il formato PDF o file di documento portatile è uno dei formati di file più comuni oggi. È ampiamente utilizzato in tutti i settori, come negli uffici governativi, cure mediche e anche lavoro personale. Dovuto, Esiste una grande quantità di dati non strutturati in formato PDF e l'estrazione di questi dati per generare informazioni significative è un lavoro comune tra gli scienziati dei dati.
Esistono diverse librerie Python dedicate a lavorare con documenti PDF come PYPDF2, eccetera. In questo tutorial, indosserà Camelot.

Perché Camelot??
- Hai il controllo: a differenza di altre librerie e strumenti che danno buoni risultati o falliscono miseramente (senza intermediari), Camelot ti dà il potere di modificare l'estrazione della tabella. (Questo è essenziale poiché tutto nel mondo reale, inclusa l'estrazione di tabelle PDF, è confusionario).
- Un po le tabelle possono essere eliminate in base a metriche come precisione e spazi bianchi, senza dover guardare manualmente ogni tabella.
- Ogni tabella è un DataFrame panda, che si integra perfettamente in Analisi dei dati e flussi di lavoro ETL.
- Esporta in più formati, incluso JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.., Eccellere, HTML e Sqlite.
Iniziamo
Prima di installare le librerie Camelot dobbiamo installare sceneggiatura fantasma , una volta installato lo script fantasma, installiamo camelot-py.
Esegui sotto i comandi :
pip install "camelot-py[CV]"
Una volta installata la libreria camelot-py, saremo pronti per iniziare. Stiamo cercando di estrarre da questo una tabella del reddito GST a livello statale documento pdf.
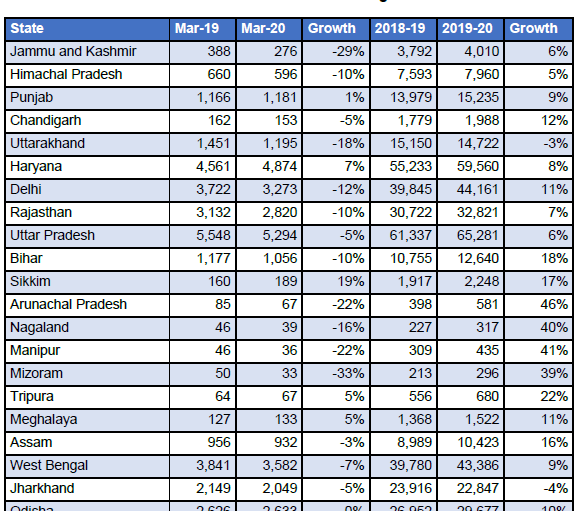
Tabella pdf
importare camelot
Se hai camelot, Python non stamperà un messaggio di errore, altrimenti, vedrai un ImportError.
# Sintassi della funzione camelot.read_pdf
camelot.read_pdf(
percorso del file,
pagine='1',
parola d'ordine=Nessuno,
gusto='reticolo',
sopprimere_stdout= Falso,
layout_kwargs={},
**kwargs,
)
Se devi estrarre una tabella da pagine diverse, devi dare il numero di pagina.
table2=camelot.read_pdf('gst-revenue-raccolta-marzo2020.pdf', sapore="flusso", pagine="0-3")
tabelle2
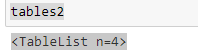
Questo ti darà un elenco totale della Tabella che è lì in un documento pdf. Possiamo scegliere una tabella passando il indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.....
tabelle2[2] # 2 è l'indice
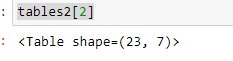
tabelle2[2].parsing_report

Il codice sopra ti fornirà dettagli come precisione e numero di pagina. Si prega di notare che ci sono 2 pagine.
Il seguente codice estrarrà la tabella dal documento pdf.
df2=tabelle2[2].df
df2
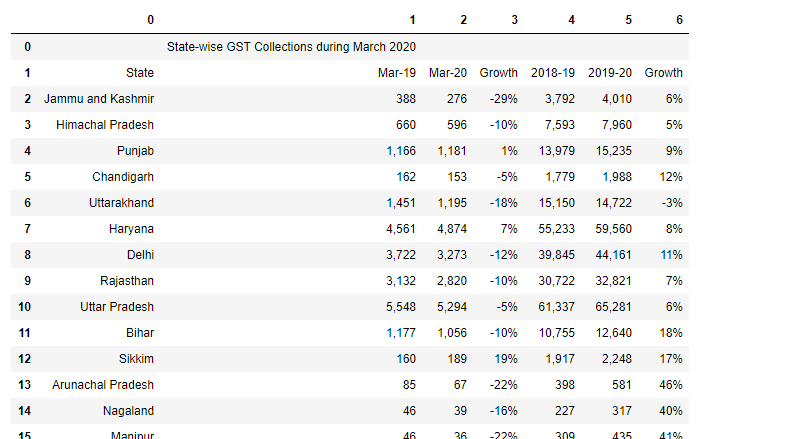
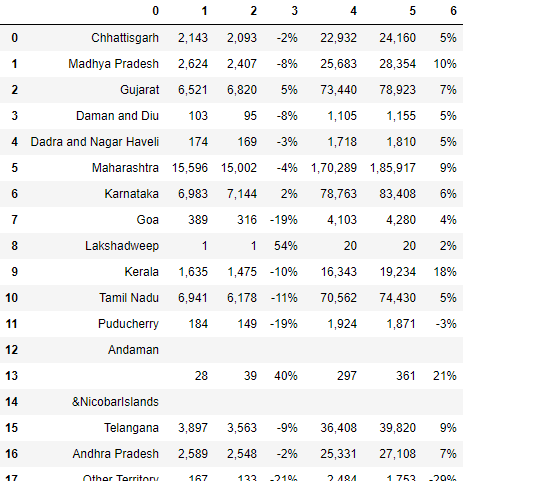
In questa circostanza, perché la tabella è divisa in due pagine diverse. Allora possiamo trovare una soluzione.
tabelle2[3]
tabelle2[3].parsing_report

Qui puoi notare, estraiamo la tabella dalla pagina no 3.
df3=tabelle2[3].df
df3
Quello che segue è il codice per aggiungere df2 e df3.
df4=df2.append(df3)
df4
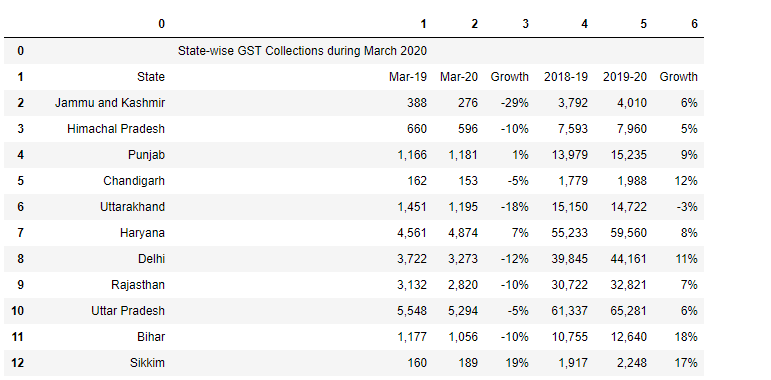
df5 = df4[1:] df5.testa() new_header = df5.iloc[0]df5 = df5[1:]df5.columns = new_header
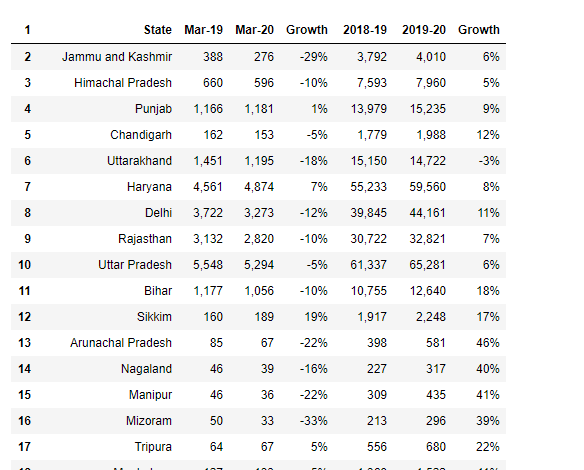
qui hai, abbiamo estratto una tabella da pdf, ora possiamo esportare questi dati in qualsiasi formato nel sistema locale.
conclusione
Estrarre dati tabulari da pdf con l'aiuto della libreria camelot è davvero facile. Allo stesso tempo, sappiamo che ci sono molti dati non strutturati in formato pdf e, dopo aver estratto le tabelle, possiamo fare molte analisi e visualizzazioni in base alle tue esigenze aziendali.
Spero che questo post ti aiuti e ti faccia risparmiare una buona quantità di tempo. Fatemi sapere se avete suggerimenti.
FELICE CODIFICA.
Circa l'autore

Prabhat Kumar – Analista associato
Sono un ingegnere che oggi lavora nelle principali multinazionali come analista associato e appassionato di innovazione, Mi piace imparare cose nuove, Credo che ogni informazione abbia una storia e adoro leggere le storie.
Prabhat Pathak (Profilo LinkedIn) è Associate Analyst.





