Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
VGG- Network es un modelo de convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. propuesto por K. Simonyan e A. Zisserman nell'articolo “Reti convoluzionali molto profonde per il riconoscimento di immagini su larga scala” [1]. Questa architettura ha raggiunto la precisione del test tra i 5 il meglio di 92,7% su ImageNet, che ha più di 14 milioni di immagini appartenenti a 1000 Lezioni.
Es una de las arquitecturas famosas en el campo del apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute.... Sostituisci i filtri di grandi dimensioni del kernel con 11 e 5 nel primo e nel secondo strato, rispettivamente, ha mostrato miglioramenti rispetto all'architettura AlexNet, con più filtri per la dimensione del kernel da 3 × 3 uno dopo l'altro. È stato addestrato per settimane e utilizzava la GPU NVIDIA Titan Black.
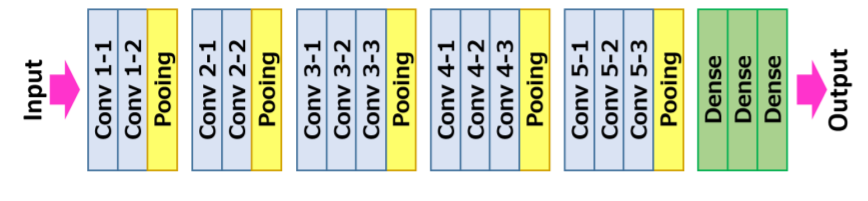
Architettura VGG16
La entrada a la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. de convolución es una imagen RGB de tamaño fijo 224 × 224. L'unica pre-elaborazione che fa è sottrarre i valori RGB medi, que se calculan en el conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., di ogni pixel.
Dopo, l'immagine attraversa una pila di strati convolutivi (conv.), Dove ci sono filtri con un campo recettivo molto piccolo cioè 3 × 3, qual è la dimensione più piccola per catturare la nozione di sinistra / Giusto, sopra / fuori uso, e parte centrale.
In una delle configurazioni, utilizza anche filtri di convoluzione 1 × 1, che può essere osservata come una trasformazione lineare dei canali di ingresso seguita da non linearità. I passi convolutivi sono fissati a 1 pixel; el relleno espacial de la entrada de la copertina convolutivaIl livello convoluzionale, Fondamentale nelle reti neurali convoluzionali (CNN), Viene utilizzato principalmente per l'elaborazione dei dati con strutture a griglia, come immagini. Questo livello applica filtri che estraggono le caratteristiche rilevanti, come bordi e trame, Consentire al modello di riconoscere modelli complessi. La sua capacità di ridurre la dimensionalità dei dati e di mantenere le informazioni essenziali lo rende uno strumento chiave nelle attività di visione artificiale.. es tal que la risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero.... espacial se mantiene después de la convolución, vale a dire, il ripieno è 1 pixel per 3 × 3 Conv. copertine.
Dopo, il clustering spaziale è effettuato da cinque strati di clustering massimo, 16 che seguono alcuni dei Conv. copertine, ma non tutti Conv. i livelli sono seguiti dal raggruppamento massimo. Questo raggruppamento massimo viene eseguito in una finestra di 2 × 2 pixel, con passo 2.
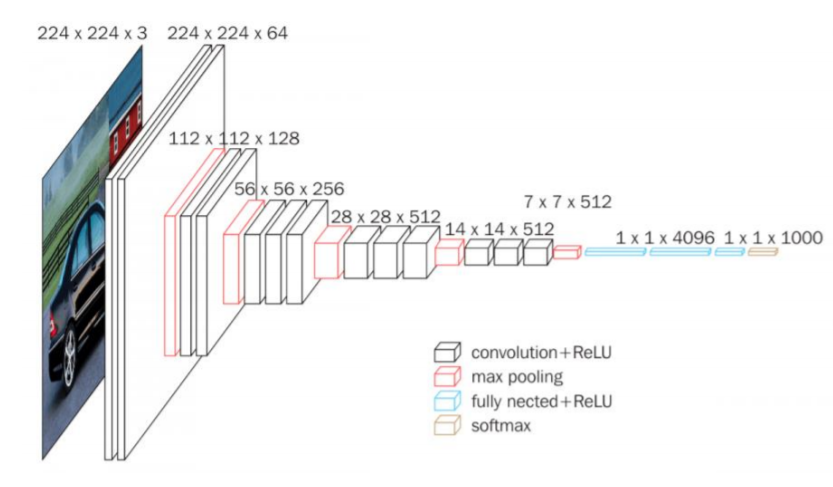
L'architettura contiene una pila di livelli convoluzionali che hanno una profondità diversa in diverse architetture, seguiti da tre livelli completamente connessi (FC): i primi due FC hanno 4096 canali ciascuno e il terzo FC esegue una classificazione di 1000 percorsi e quindi contiene 1000 canali che è uno per ogni classe.
L'ultimo strato è il livello soft-max. La configurazione dei livelli completamente connessi è simile in tutte le reti.
Tutti i livelli nascosti sono dotati di rettifica (riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione..) non lineare. Cosa c'è di più, aquí una de las redes contiene NormalizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... de respuesta local (LRN), tale normalizzazione non migliora le prestazioni sul set di dati addestrato, ma il suo utilizzo comporta un maggiore consumo di memoria e tempi di calcolo.
Riepilogo dell'architettura:
• L'input al modello è un'immagine RGB a dimensione fissa 224 × 224224 × 224
• La preelaborazione consiste nel sottrarre la media del valore RGB del training set da ciascun pixel
• Strati convoluzionali 17
– passo fisso a 1 pixel
– il ripieno è 1 pixel per 3 × 33 × 3
• Livelli di raggruppamento spaziale
– Questo strato non conta per la profondità del web per convenzione
– Il raggruppamento spaziale viene eseguito utilizzando i livelli di raggruppamento massimi
– la dimensione della finestra è 2 × 22 × 2
– Andata impostata su 2
– Convnet utilizzati 5 livelli massimi di raggruppamento
• Livelli completamente connessi:
• 1º: 4096 (riprendere).
▪ 2: 4096 (riprendere).
▪ 3º: 1000 (Softmax).
Configurazione dell'architettura
Quanto segue figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... contiene la configuración de la red neuronal de convolución de la red VGG con el
strati successivi:
• VGG-11
• VGG-11 (LRN)
• VGG-13
• VGG-16 (Conv1)
• VGG-16
• VGG-19
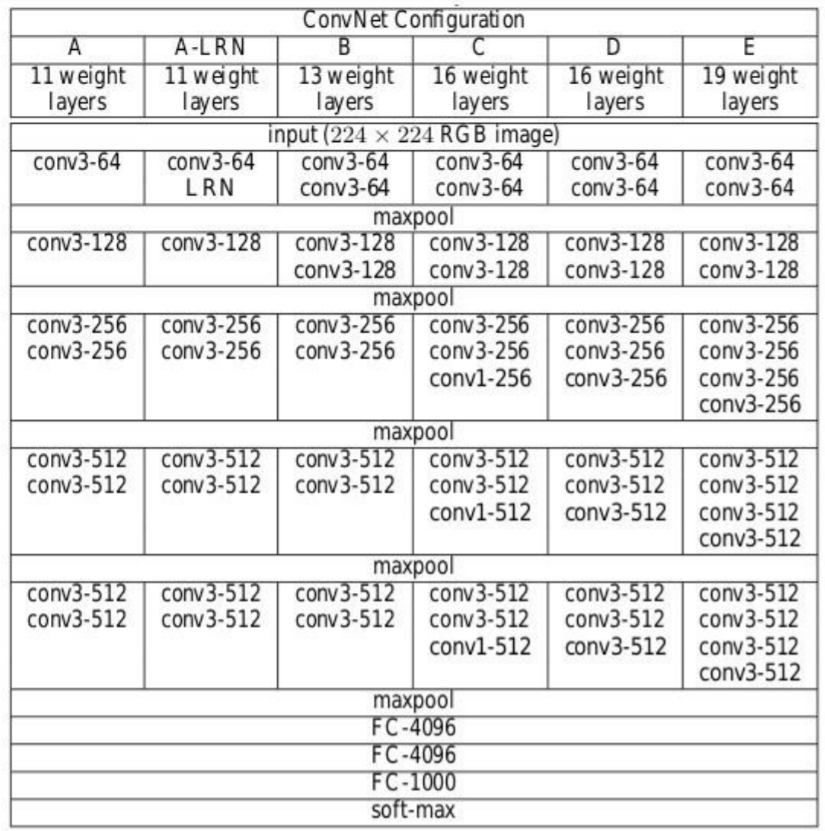
Fonte: “Reti convoluzionali molto profonde per il riconoscimento di immagini su larga scala”
Le configurazioni della rete neurale convoluzionale sono menzionate sopra una per colonna.
Prossimo, le reti sono indicate con i loro nomi (A – E). Tutte le configurazioni seguono il design tradizionale e differiscono solo in profondità: a partire dal 11 strati di peso nella rete A che sono 8 Conv. e 3 strati FC a 19 strati di peso nella rete E che è 16 Conv. e 3 Strati FC. La larghezza di ogni conv. layer è il numero di canali è piuttosto piccolo, che inizia da 64 nel primo strato e poi continua ad aumentare di un fattore 2 dopo ogni strato di raggruppamento massimo fino a raggiungere 512.
El número de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... para cada configuración se describe a continuación. Anche se ha una grande profondità, il numero di pesi nelle reti non è maggiore del numero di pesi in una rete meno profonda con maggiore conv. larghezze dei livelli e campi ricettivi

Addestramento
• La Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... es una regresión logística multinomial
• El algoritmo de aprendizaje es un descenso de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... Stocastico (SGD) mini-batch basato sul backspread momentum.
· La dimensione del lotto era 256
· L'impulso è stato 0,9
• regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni....
· Decadimento del peso L2 (il moltiplicatore di penalità era 0,0005)
· Il dropout per i primi due livelli completamente connessi è impostato su 0.5
• Tasso di apprendimento
· iniziale: 0.01
· Quando l'accuratezza del set di convalida ha smesso di migliorare, se ridurre a 10.
• Nonostante abbia un maggior numero di parametri e anche profondità rispetto ad Alexnet, La CNN ha richiesto meno volte per la convergenza della funzione di perdita a causa di
· Piccoli grani convolutivi e maggiore regolarizzazione grazie alla grande profondità.
· Pre-inizializzazione di alcuni livelli.
• Dimensione dell'immagine di allenamento
· S è il lato più piccolo dell'immagine riscalata isotopica
· Due approcci per stabilire S
▪ Correggi S, noto come allenamento su scala singola
▪ Qui S = 256 yS = 384
▪ Varia S, noto come formazione multi-scala
▪ S de [Smin, Smax] dove Smin = 256, Smax = 512
– Dopo 224 × 224224 × 224
L'immagine è stata ritagliata casualmente dall'immagine ridimensionata dell'iterazione SGD.
Caratteristiche principali
• VGG16 ha un totale di 16 strati che hanno dei pesi.
• Vengono utilizzati solo i livelli di convoluzione e raggruppamento.
• Utilizzare sempre un nucleo di 3 X 3 per convoluzione. 20
• Taglia 2 × 2 piscina massima.
• 138 milioni di parametri.
• Formazione sui dati ImageNet.
• Ha una precisione di 92,7%.
• Un'altra versione che è VGG 19, ha un totale di 19 strati con pesi.
• È un'ottima architettura di deep learning per il benchmarking su qualsiasi compito particolare.
• Le reti pre-addestrate per VGG sono open source, quindi possono essere comunemente usati per vari tipi di applicazioni.
Implementa la rete VGG
Primo, creiamo la mappatura dei filtri per ogni versione della rete VGG. Fare riferimento all'immagine di configurazione sopra per il numero di filtri. Vale a dire, creare un dizionario per la versione con una chiave denominata VGG11, VGG13, VGG16, VGG19 e creare un elenco in base al numero di filtri in ciascuna versione rispettivamente. Qui “m” Nell'elenco è nota come Operazione MaxPool.
import torch
import torch.nn as nn
VGG_types = {
"VGG11 ·": [64, "m", 128, "m", 256, 256, "m", 512, 512, "m", 512, 512, "m"],
"VGG13": [64, 64, "m", 128, 128, "m", 256, 256, "m", 512, 512, "m", 512, 512, "m"],
"VGG16": [64,64,"m",128,128,"m",256,256,256,"m",512,512,512,"m",512,512,512,"m",],
"VGG19 ·": [64,64,"m",128,128,"m",256,256,256,256,"m",512,512,512,512,
"m",512,512,512,512,"m",],}
Cree una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... global para mencionar la versión de la arquitectura. Quindi crea una classe chiamata VGG_net con input come in_channels e num_classes. Accetta input come un numero di canali di immagine e il numero di classi di output.
Inizializzare i livelli sequenziali, vale a dire, nella sequenza, Strato lineare–> ReLU–> Omettere.
Quindi creare una funzione denominata create_conv_layers che accetta la configurazione dell'architettura VGGnet come input, che è l'elenco che abbiamo creato sopra per le diverse versioni. Quando incontri la lettera “m” dall'elenco sopra, esegue l'operazione MaxPool2d.
VGGType = "VGG16"
classe VGGnet(nn.Modulo):
def __init__(se stesso, in_channels=3, num_classes=1000):
super(VGGnet, se stesso).__dentro__()
self.in_channels = in_channels
self.conv_layers = self.create_conv_layers(VGG_types[VGGType])
self.fcs = nn. Sequenziale( nn. Lineare(512 * 7 * 7, 4096), nn. ReLU(), nn. Abbandono degli studi(p=0,5), nn. Lineare(4096, 4096), nn. ReLU(), nn. Abbandono degli studi(p=0,5), nn. Lineare(4096, num_classi), ) def avanti(se stesso, X): x = self.conv_layers(X) x = x.reshape(x.shape[0], -1) x = self.fcs(X) return x def create_conv_layers(se stesso, architettura): livelli = [] in_channels = self.in_channels for x in architecture: se digitare(X) == int: out_channels = x layers += [ nn. Conv2d( in_channels=in_channels, out_channels=out_channels, kernel_size=(3, 3), falcata=(1, 1), imbottitura=(1, 1), ), nn. BatchNorm2d(X), nn. ReLU(), ] in_channels = x elif x == "m": livelli += [nn. MaxPool2d(kernel_size=(2, 2), falcata=(2, 2))] ritorno nn. Sequenziale(*strati)
Una volta fatto questo, escriba un pequeño código de prueba para verificar si nuestra implementación está funcionando bien.
En el siguiente código de prueba, el número de clases dadas es 500.
se __nome__ == "__principale__":
dispositivo = "miracoli" se torcia.cuda.è_disponibile() altro "processore"
modello = VGGnet(in_channels=3, num_classes=500).a(dispositivo)
# Stampa(modello)
x = torcia.randn(1, 3, 224, 224).a(dispositivo)
Stampa(modello(X).forma)
L'output dovrebbe essere così:
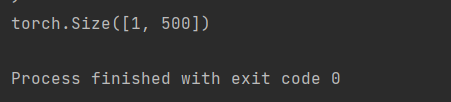
Se vuoi vedere l'architettura di rete, puoi decommentare il stampare (modello) sopra la dichiarazione del codice. Puoi anche provare versioni diverse modificando le versioni VGG nella variabile VGGType.
Il codice completo è accessibile qui:
https://github.com/BakingBrains/Deep_Learning_models_implementation_from-scratch_using_pytorch_/blob/main/VGG.py
[1]. K. Simonyan e A. Zisserman: Reti convoluzionali molto profonde per il riconoscimento di immagini su larga scala, aprile di 2015, DOI: https://arxiv.org/pdf/1409.1556.pdf
Grazie
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





