Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
di
INTRODUZIONE
Raccogliere informazioni attraverso il web è web scraping, anche conosciuto come Estrazione dati web e raccolta web. Oggi, i dati sono come l'ossigeno per startup e liberi professionisti che vogliono avviare un'attività o un progetto in qualsiasi campo. Supponiamo di voler trovare il prezzo di un prodotto su un sito di e-commerce. Facile da trovare, ma ora diciamo che devi fare questo esercizio per migliaia di prodotti su vari siti di e-commerce. Farlo manualmente; non è affatto una buona opzione.
Conosci lo strumento
JavaScript è un linguaggio di programmazione popolare e funziona in qualsiasi browser web.
NodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... JS è un interprete e fornisce un ambiente per JavaScript con alcune utili librerie specifiche.
In sintesi, Node JS aggiunge varie funzionalità e caratteristiche a JavaScript in termini di librerie e lo rende più potente.

SessioneIl "Sessione" È un concetto chiave nel campo della psicologia e della terapia. Si riferisce a un incontro programmato tra un terapeuta e un cliente, dove si esplorano i pensieri, Emozioni e comportamenti. Queste sessioni possono variare in durata e frequenza, e il suo scopo principale è quello di facilitare la crescita personale e la risoluzione dei problemi. L'efficacia delle sessioni dipende dalla relazione tra il terapeuta e il terapeuta.. práctica
Comprendiamo il web scraping usando Node JS con un esempio. Supponiamo di voler analizzare le fluttuazioni di prezzo di alcuni prodotti su un sito di e-commerce. Ora, dovresti elencare tutti i possibili fattori della causa e controllarli con ciascun prodotto. Allo stesso modo, quando vuoi estrarre i dati, devi elencare i tag HTML padre e controllare il rispettivo tag HTML figlio per estrarre i dati ripetendo questa attività.
Passaggi necessari per il web scraping
- Creazione del file package.json
- Installa e chiama le librerie necessarie
- Seleziona il sito web e i dati necessari per lo scraping
- Imposta l'URL e controlla il codice di risposta
- Ispeziona e trova i tag HTML giusti
- Includi tag HTML nel nostro codice
- Controlla i dati estratti
Sto usando Visual Studio per eseguire questa attività.
passo 1- Creazione del file package.json
Per creare un pacchetto.json archivio, ho bisogno di correre npm inizia e fornisci alcuni dettagli secondo necessità nello screenshot seguente.
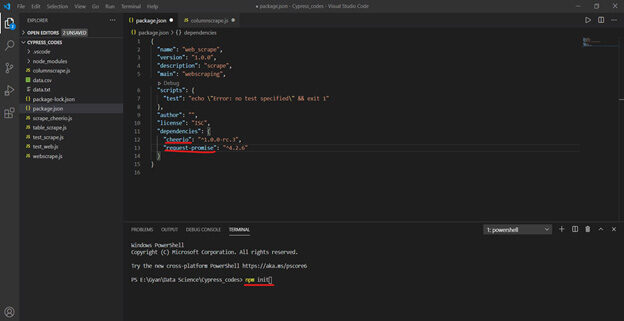
Crea pacchetto.json
passo 2- Installa e chiama le librerie necessarie
È necessario eseguire i seguenti codici per installare queste librerie.

Installa librerie
Una volta che le biblioteche adeguatamente installato, vedrai che vengono visualizzati questi messaggi.

log dopo l'installazione dei pacchetti
Chiama le biblioteche richieste:

Chiama in biblioteca
passo 3- Seleziona il sito web e i dati necessari per lo scraping.
Ho scelto questo sito “https://www.bullion-rates.com/gold/INR/2007-1-history.htm”E vuoi estrarre i dati dei tassi d'oro insieme alle date.
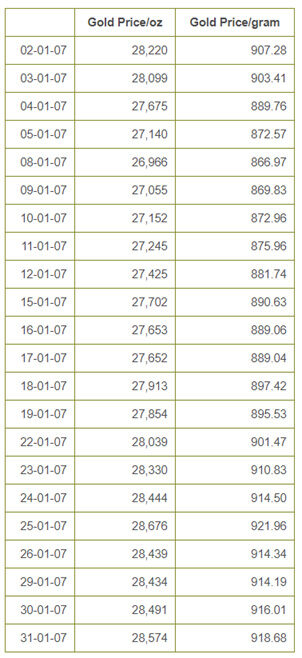
Dati che vogliamo raschiare
passo 4- Imposta l'URL e controlla il codice di risposta
Il codice del nodo JS assomiglia a questo per passare l'URL e controllare il codice di risposta.

Passa l'URL e ottieni il codice di risposta
passo 5- Ispeziona e trova i tag HTML giusti
È abbastanza facile trovare i tag HTML corretti in cui sono presenti i tuoi dati.
Per visualizzare i tag HTML; fare clic con il tasto destro e selezionare l'opzione di ispezione.
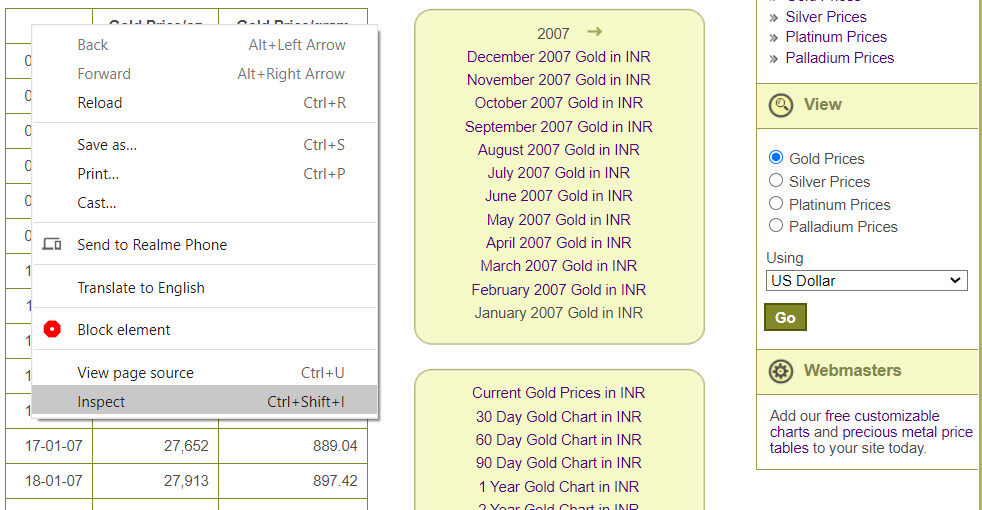
Ispeziona i tag HTML
Seleziona i tag HTML appropriati: –
Se hai notato è così Tre colonne nella nostra tabella, quindi il nostro tag HTML per la riga della tabella sarebbe “Riga di intestazione” & tutti i nomi delle colonne sono presenti con l'etichetta "T" (intestazione della tabella).
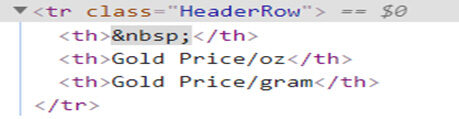
E per ognuno riga della tabella (“vero”) i nostri dati risiedono in “Riga dati " tag HTML
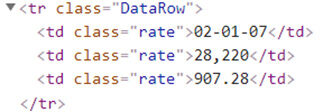
Ora, Ho bisogno che tutti i tag HTML risiedano in “Riga di intestazione“E ho bisogno di trovare tutto il”ns“Tag HTML e infine iterare”DataRow"Tag HTML per ottenere tutti i dati che contiene.
passo 6- Includi tag HTML nel nostro codice
Dopo aver incluso i tag HTML, il nostro codice sarà: –
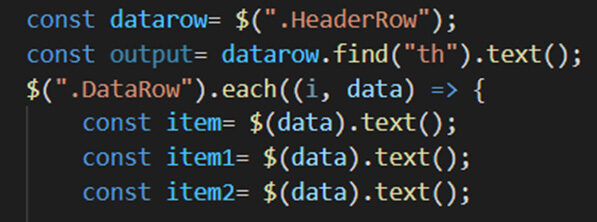
Frammento di codice
passo 7- Controlla i dati raschiati
Stampa i dati, quindi il codice per questo è come: –

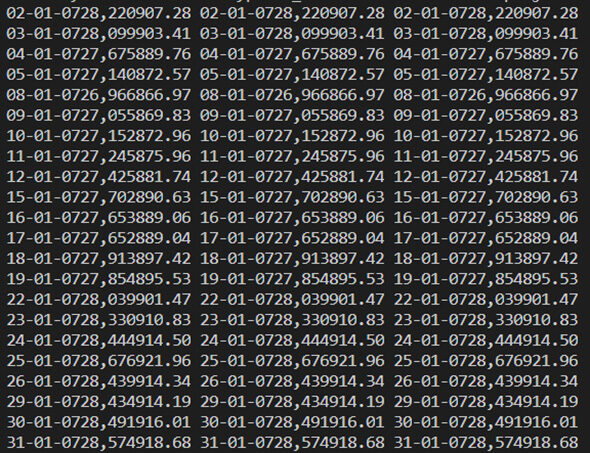
I nostri dati raschiati
Se passi a un livello più granulare di tag HTML e li ripeti di conseguenza, ottenere dati più accurati.
Si tratta di web scraping e come ottenere dati di qualità rara come l'oro.
conclusione
Ho provato a spiegare in modo preciso il Web Scraping utilizzando Node JS. spero che questo aiuti.
Trova il codice completo su
Se hai domande sul codice o sul web scraping in generale, contattami a
Vgyaan's – Linkedin
Ci rivedremo con qualcosa di nuovo.
Fino ad allora,
Codifica felice ..!





