Introdução
Repositórios do GitHub e discussões do Reddit: ambas as plataformas têm desempenhado um papel fundamental na minha aprendizado de máquina viagem. Eles me ajudaram a desenvolver meu conhecimento e compreensão das técnicas de aprendizado de máquina e minha visão de negócios.
Tanto o GitHub quanto o Reddit também me mantêm atualizado sobre os desenvolvimentos mais recentes em aprendizado de máquina, Imprescindível para quem trabalha nesta área!!
E se você é um programador, Nós vamos, GitHub é como um templo para você. Você pode facilmente baixar o código e replicá-lo em sua máquina. Isso torna ainda mais fácil aprender novas ideias e construir um conjunto diversificado de habilidades..

Estou muito feliz em escolher os principais repositórios do GitHub e as discussões do Reddit deste mês. Os tópicos do Reddit que apresentei são sobre o lado técnico do aprendizado de máquina bem como o relacionado com a corrida. Essa capacidade de combinar os dois é o que separa os especialistas em aprendizado de máquina dos amadores..
Abaixo estão os artigos mensais que cobrimos até agora nesta série:
Assim que, Vamos trabalhar em março!
Repositórios GitHub

Se eu tivesse que escolher uma das razões do meu fascínio por visão de computador, seriam GANs (Redes Adversariais Generativas). Eles foram inventados por Ian Goodfellow apenas alguns anos atrás e cresceram em um corpo inteiro de pesquisas.. Arte de IA recente que você viu nas notícias? Tudo funciona com GAN.

DeepMind surgiu com o conceito BigGAN no ano passado, mas esperamos um pouco por uma implementação PyTorch. Este repositório também inclui modelos previamente treinados (128 × 128, 256 × 256 e 512 × 512). Você pode instalar isso em apenas uma linha de código:
pip instalar pytorch-pré-treinado-biggan
E se você estiver interessado em ler o artigo de pesquisa completo do BigGAN, Visita aqui.
A capacidade de trabalhar com dados de imagem está se tornando uma característica definidora para qualquer pessoa interessada em aprendizado profundo. O advento e o rápido desenvolvimento dos algoritmos de visão computacional desempenharam um papel importante nessa transformação.. Você não ficará surpreso ao saber que a NVIDIA é um dos principais líderes nessa área..
Basta dar uma olhada em seus desenvolvimentos de 2018:
E agora, o pessoal da NVIDIA criou outro lançamento incrível: a capacidade de sintetizar imagens fotorrealísticas com um design semântico de entrada. Que bom que isso? A comparação a seguir fornece uma boa ilustração:

O SPADE superou os métodos existentes no popular conjunto de dados COCO. O repositório que vinculamos acima abrigará a implementação do PyTorch e os modelos previamente treinados para esta técnica (certifique-se de marcá-lo).
Este vídeo mostra como o SPADE funciona bem em 40.000 imagens tiradas do Flickr:
Este repositório é baseado no ‘Rastreamento e segmentação rápida de objetos online: uma abordagem unificadora‘ papel. Aqui está um resultado de amostra usando esta técnica:

Impressionante! A técnica, chamado SiamMask, é bastante simples, versátil e extremamente rápido. Oh, Eu mencionei que o rastreamento de objetos é feito em tempo real? Isso certamente chamou minha atenção. Este repositório também contém modelos pré-treinados para que você possa começar.
O trabalho será apresentado na prestigiosa conferência CVPR 2019 (Visão computacional e reconhecimento de padrões) em junho. Os autores demonstraram sua abordagem no vídeo a seguir:
Você já trabalhou em um projeto de detecção de pose? Eu fiz isso e deixe-me dizer que é excelente. É uma prova do progresso que fizemos como comunidade no aprendizado profundo.. Quem teria pensado atrás 10 anos que seríamos capazes de prever o próximo movimento corporal de uma pessoa?
Este repositório GitHub é um PyTorch implementação de ‘Aprendizagem autossupervisionada da pose humana em 3D usando geometria multivisualização‘ papel. Os autores foram os pioneiros em uma nova técnica chamada EpipolarPose, um método de aprendizagem auto-supervisionado para estimar a pose de um ser humano em 3D.

A técnica EpipolarPose estima poses 2D a partir de imagens de visualização múltipla durante a fase de treinamento. Em seguida, use a geometria epipolar para gerar uma pose 3D. Esse, na sua vez, usado para treinar o estimador de pose 3D. Este processo é ilustrado na imagem acima.
Este artigo também foi aceito na conferência CVPR 2019. Preparando-se para ser uma excelente escalação!!
Este é um repositório único de várias maneiras. É um modelo de aprendizado profundo de código aberto para proteger sua privacidade. Todo o conceito da DeepCamera é baseado em aprendizado de máquina automatizado (AutoML). Portanto, você nem precisa de experiência em programação para treinar um novo modelo.

DeepCamera funciona em dispositivos Android. Você também pode integrar o código com câmeras de vigilância. Há MUITO que você pode fazer com o código DeepCamera, que inclui:
- Reconhecimento facial
- Detecção de rosto
- Controle de aplicativo móvel
- Detecção de objetos
- Detector de movimento
E muitas outras coisas. Construir seu próprio modelo com IA nunca foi tão fácil!!
Discussões do Reddit

Eu dividi as discussões do Reddit deste mês em duas categorias:
- O lado técnico do aprendizado de máquina
- Discussões relacionadas à carreira de aprendizado de máquina (papéis e empregos)
Vamos começar com o aspecto técnico.
Os cientistas de dados são fascinados pelo trabalho de pesquisa. Nós queremos lê-los, codifique-os e talvez até mesmo escreva um do zero. Seria muito legal apresentar seu próprio artigo de pesquisa em uma conferência de ML de alto nível??

Eu certamente pertenço à categoria de “Eu quero escrever um artigo de pesquisa”. Esta discussão, iniciado por um pesquisador veterano, investiga as melhores práticas que devemos seguir ao escrever um artigo de pesquisa. Aqui estão muitas informações e experiência, Uma leitura obrigatória para todos nós!
Aqui está o Repositório GitHub com as melhores dicas, dicas e ideias em um só lugar. Trate essas dicas como um conjunto de diretrizes e não como regras imutáveis.
Como colocar seus modelos de aprendizado de máquina treinados em produção? Como você os implementa? Essas são perguntas MUITO comuns que você enfrentará em sua entrevista de ciência de dados (e o trabalho, claro). Se você não tem certeza do que é isso, Eu sugiro que você leia AGORA.
Este tópico de discussão é sobre uma biblioteca de código aberto que converte seus modelos de aprendizado de máquina em código nativo (C, Pitão, Java) sem dependências. Deve rolar pelo tópico, pois existem algumas questões comuns que o autor abordou em detalhes.
Você pode encontrar o código completo em este repositório GitHub. Abaixo está a lista de modelos que esta biblioteca suporta atualmente:
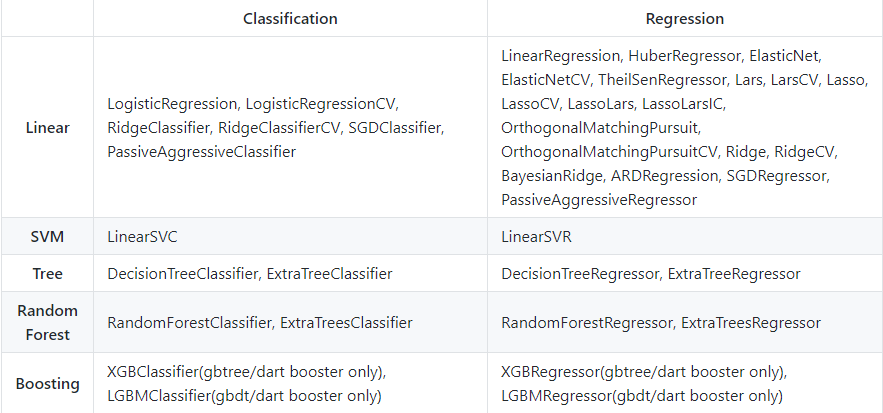
Vamos mudar o foco agora e ver algumas discussões sobre a carreira de aprendizado de máquina. Eles se aplicam a TODOS os profissionais de aprendizado de máquina, aspirante e estabelecido.
O surgimento do aprendizado de máquina automatizado será uma desvantagem para o próprio campo?? Essa é uma questão sobre a qual a maioria de nós tem se perguntado.. A maioria dos artigos que encontro predizem todo o pessimismo. Alguns até afirmam que os cientistas de dados não serão necessários em 5 anos!

Fonte: Temocracia
O autor deste tópico apresenta um argumento maravilhoso contra o consenso geral. É altamente improvável que a ciência de dados desapareça devido à automação.
A discussão argumenta com razão que a ciência de dados não se trata apenas de modelagem de dados. Isso é apenas o 10% de todo o processo. Uma parte importante do ciclo de vida da ciência de dados é a intuição humana por trás dos modelos. Limpeza de dados, a visualização de dados e um toque de lógica são o que impulsiona todo este processo.
Aqui está uma joia e um argumento sólido que chamou minha atenção:
Desenvolvemos todos os tipos de software estatístico no século passado e, porém, não substituiu estatísticos.
Você quer chegar à sua primeira posição em ciência de dados? Você acha que é um processo opressor? Eu estive lá. É um dos maiores obstáculos a superar em nossas respectivas jornadas de ciência de dados..
Então, eu queria destacar este tópico em particular. É uma discussão realmente reveladora, onde profissionais de ciência de dados e iniciantes discutem como entrar neste campo. O autor da postagem oferece algumas reflexões aprofundadas sobre o processo de busca de empregos em ciência de dados, juntamente com dicas para limpar cada rodada de entrevistas..

Uma frase que realmente se destacou nesta discussão:
Lembrar, o aumento nos pedidos de entrevista e o aumento do conhecimento não é apenas uma correlação, é uma causalidade. Durante a aplicação, Aprenda algo novo todos os dias.
Um DataPeaker, nosso objetivo é ajudá-lo a alcançar sua primeira posição em ciência de dados. Confira os recursos incríveis abaixo para ajudá-lo a começar:
Conhecimento de domínio: aquele ingrediente chave na receita geral do cientista de dados. Frequentemente, aspirantes a cientistas de dados ignoram ou interpretam mal. E isso geralmente resulta em rejeições nas entrevistas.. Então, Como você pode desenvolver sua visão de negócios para complementar suas habilidades existentes em ciência de dados técnicos?
Esta discussão do Reddit oferece alguns insights úteis. A capacidade de traduzir suas ideias e resultados em termos comerciais é VITAL. A maioria das partes interessadas que você enfrentará em sua carreira não entenderá o jargão técnico..
Aqui está minha escolha favorita da discussão:
Você precisa conhecer melhor seus parceiros de negócios. Descubra o que eles fazem no dia a dia, quais são seus processos, como eles geram os dados que você vai usar. Se você entende como X e Y veem, você será mais capaz de ajudá-los quando eles vierem até você com problemas.
Na DataPeaker, acreditamos fortemente na construção de uma mentalidade de pensamento estruturado. Reunimos nossa experiência e conhecimento neste tópico no curso abrangente abaixo:
Este curso contém vários estudos de caso que também o ajudarão a ter uma ideia de como as empresas trabalham e pensam..
Notas finais
Gostei especialmente das discussões do Reddit do mês passado. Recomendo que você aprenda mais sobre como o ambiente de produção funciona em um projeto de aprendizado de máquina. Agora considerado quase obrigatório para um cientista de dados, então você não pode ficar longe dele.
Você também deve participar dessas discussões do Reddit. A rolagem passiva é boa para adquirir conhecimento, mas adicionar sua própria perspectiva ajudará outros candidatos também. Este é um sentimento intangível, mas você apreciará e apreciará quanto mais experiência tiver.
Qual discussão você achou mais reveladora? E qual repositório GitHub se destacou para você? Me avise na seção de comentários abaixo!!





