Este artigo foi publicado como parte do Data Science Blogathon
Introdução
A ciência de dados é um campo emergente com inúmeras oportunidades de trabalho. Todos nós já devemos ter ouvido falar das melhores habilidades em ciência de dados. Para começar, a habilidade mais fácil e essencial que todo aspirante a cientista de dados deve adquirir é SQL.
Hoje em dia, A maioria das empresas é orientada por dados. Esses dados são armazenados em um banco de dados e gerenciados e processados por meio de um sistema de gerenciamento de banco de dados. DBMS torna nosso trabalho tão fácil e organizado. Portanto, é essencial integrar a linguagem de programação mais popular com a incrível ferramenta DBMS.
SQL é a linguagem de programação mais utilizada quando se trabalha com bancos de dados e é compatível com vários sistemas de banco de dados relacionais, como MySQL, SQL Server e Oracle. Porém, O padrão SQL tem alguns recursos que são implementados de forma diferente em diferentes sistemas de banco de dados. Por tanto, SQL se torna um dos conceitos mais importantes para aprender neste campo da ciência de dados.
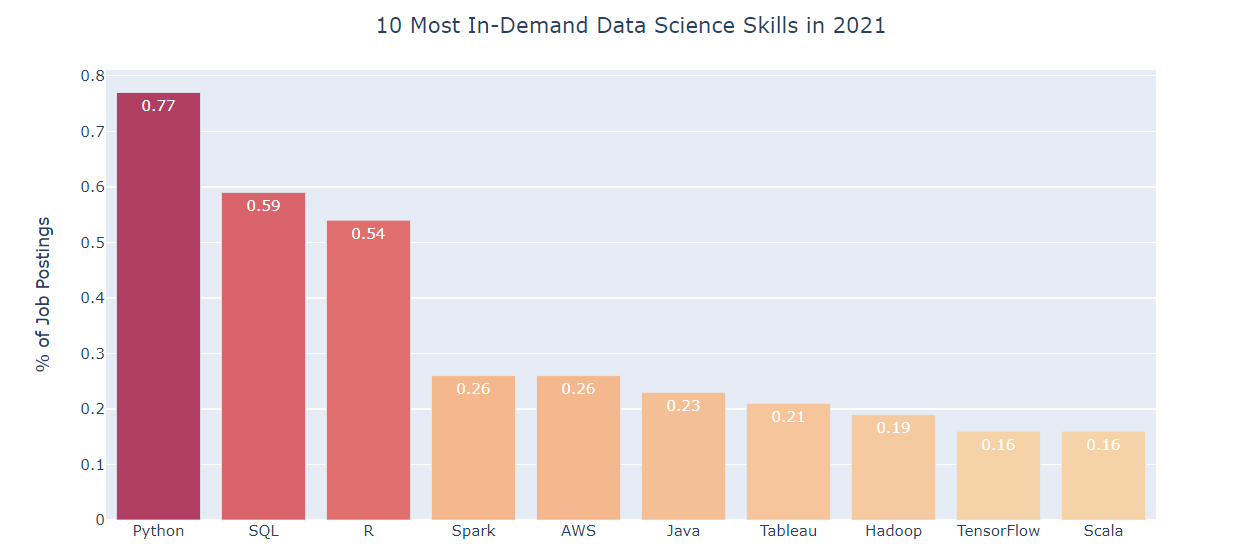
Fonte da imagem: KDnuggets
Necessidade de SQL em Ciência de Dados
SQL (Linguagem de consulta estruturada) Ele é usado para executar várias operações nos dados armazenados nos bancos de dados, Como atualizar registros, Excluir registros, Criar e modificar tabelas, Modos de exibição, etc. O SQL também é o padrão para as plataformas de big data atuais que usam SQL como sua API chave para seus bancos de dados relacionais.
Ciência de dados é o estudo abrangente de dados. Para trabalhar com dados, precisamos extraí-los do banco de dados. É aqui que o SQL entra em cena. O gerenciamento de banco de dados relacional é uma parte crucial da ciência de dados. Um cientista de dados pode controlar, definir, manipular, criar e consultar o banco de dados usando comandos SQL.
Muitas indústrias modernas equiparam o gerenciamento de dados de seus produtos com a tecnologia NoSQL, mas o SQL ainda é a escolha ideal para muitas ferramentas de business intelligence e operações de escritório.
Muitas das plataformas de banco de dados são baseadas em SQL. É por isso que se tornou um padrão para muitos sistemas de banco de dados. Sistemas modernos de big data como o Hadoop, O Spark também usa SQL apenas para manter sistemas de banco de dados relacionais e processar dados estruturados.
Podemos dizer que:
1. Um cientista de dados precisa de SQL para lidar com dados estruturados. Como os dados estruturados são armazenados em bancos de dados relacionais. Portanto, Para consultar essas bases de dados, um cientista de dados deve ter uma boa compreensão dos comandos SQL.
Plataformas de big data como Hadoop e Spark fornecem uma extensão para consulta usando comandos SQL para manipular.
3.SQL é a ferramenta padrão para experimentar dados criando ambientes de teste.
4. Para executar operações analíticas em dados armazenados em bancos de dados relacionais, como Oracle, Microsoft SQL, MySQL, precisamos de SQL.
5. O SQL também é uma ferramenta essencial para a preparação e processamento de dados. Portanto, ao lidar com várias ferramentas de Big Data, usamos SQL.
Principais elementos do SQL para ciência de dados
Abaixo estão os principais aspectos do SQL que são mais úteis para a ciência de dados. Todos os aspirantes a cientistas de dados devem estar cientes dessas habilidades e recursos SQL necessários.
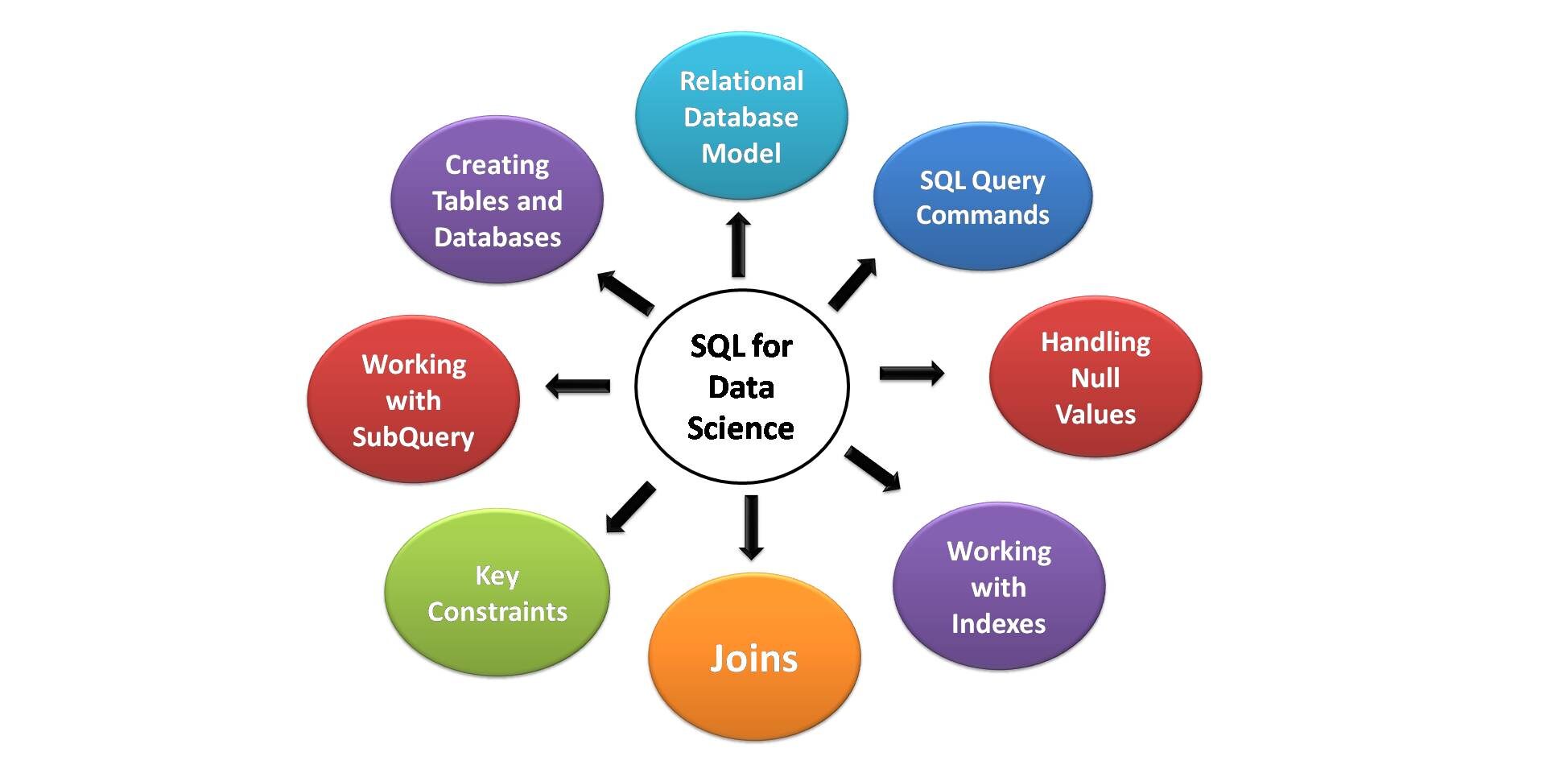
Fonte da imagem: Para mim
Introdução ao SQL com Python
Como todos sabemos, SQL é a ferramenta de administração de banco de dados mais amplamente utilizada e Python é a linguagem de ciência de dados mais popular por causa de sua flexibilidade e ampla gama de bibliotecas. Há várias maneiras de usar o SQL com Python. Python fornece várias bibliotecas que são desenvolvidas e podem ser usadas para este fim. SQLite, PostgreSQL, e MySQL são exemplos dessas bibliotecas.
Por que usar SQL com Python
Há muitos casos de uso em que os cientistas de dados desejam conectar o Python ao SQL. Os cientistas de dados precisam conectar um banco de dados SQL para armazenar os dados provenientes do aplicativo Web. Ele também ajuda a se comunicar entre diferentes fontes de dados.
Não há necessidade de alternar entre diferentes linguagens de programação para gerenciamento de dados. Torna o trabalho dos cientistas de dados mais conveniente. Eles poderão usar suas habilidades em Python para manipular dados armazenados em um banco de dados SQL. Eles não precisam de um arquivo CSV.
MySQL com Python
MySQL é um sistema de gerenciamento de banco de dados baseado em servidor. Um servidor MySQL pode ter vários bancos de dados. Um banco de dados MySQL consiste em um processo de duas etapas para criar um banco de dados:
1. Estabelecer uma conexão com um servidor MySQL.
2. Execute consultas separadas para criar o banco de dados e processar os dados.
Vamos começar com o MySQL com Python
Primeiro, criaremos uma conexão entre o servidor MySQL e o banco de dados MySQL. Para isso, definiremos uma função que estabelecerá uma conexão com o servidor de banco de dados MySQL e retornará o objeto de conexão:
!pip instalar mysql-connector-python
import mysql.connector
from mysql.connector import Error
create_connection def(host_name, user_name, user_password):
connection = None
try:
conexão = mysql.connector.connect(
host=host_name,
usuário=user_name,
passwd=user_password
)
imprimir("Conexão com o banco de dados MySQL bem-sucedida")
exceto Erro como e:
imprimir(f"O erro'{e}' ocorreu")
return connection
connection = create_connection("localhost", "raiz", "")
No código acima, Definimos uma função create_connection () que aceita os três parâmetros a seguir:
1. nombre_host
2. nome de usuário
3. Senha do usuário
Mysql.connector é um módulo SQL Python que contém um método .connect () que é usado para se conectar a um servidor de banco de dados MySQL. Quando a conexão é estabelecida, O objeto de conexão criado será retornado à função de chamada.
Até agora, A conexão foi estabelecida com êxito, Agora vamos criar um banco de dados.
#we have created a function to create database that contions two parameters #connection and query defcreate_database(conexão,consulta): #agora estamos criando um cursor de objeto para executar o cursor de consultas SQL=conexão.cursor() Experimente: #A consulta a ser executada será passada no cursor.execute() no formato de cadeia de caracteres cursor.execute(consulta) imprimir("Banco de dados criado com êxito") excetoErroComoe: imprimir(f"O erro'{e}' ocorreu")
#now we are creating a database named example_app create_database_query="CRIAR example_app DE BANCO DE DADOS" create_database(conexão,create_database_query)
#now will create database example_app on database server #and also cretae connection between database and server defcreate_connection(host_name,user_name,user_password,db_name): conexão=Nenhuma tentativa: conexão=mysql.connector.connect( host=host_name, usuário=user_name, passwd=user_password, banco de dados=db_name ) imprimir("Conexão com o banco de dados MySQL bem-sucedida") excetoErroComoe: imprimir(f"O erro'{e}' ocorreu") Retornaconexão
#chamando ocreate_connection()e se conecta aoexample_appBase de dados. conexão=create_connection("localhost","raiz","","example_app")
SQLite
SQLite é provavelmente o banco de dados mais simples que podemos conectar a um aplicativo Python, por ser um módulo integrado, não precisamos instalar nenhum módulo SQL Python externo. Por padrão, a instalação do Python contém uma biblioteca SQL Python chamada sqlite3 que pode ser usada para interagir com um banco de dados SQLite.
SQLite é um banco de dados sem servidor. Lê e grava dados em um arquivo. Isso significa que nem precisamos instalar e executar um servidor SQLite para executar operações de banco de dados como MySQL e PostgreSQL!
Vamos usar sqlite3 para se conectar a um banco de dados SQLite em Python:
importarsqlite3 deSQLite3importarErro
defcreate_connection(caminho): conexão=Nenhuma tentativa: conexão=sqlite3.connect(caminho) imprimir("Conexão com o banco de dados SQLite bem-sucedida")
excetoErroComoe: imprimir(f"O erro'{e}' ocorreu") Retornaconexão
No código acima, importamos sqlite3 e a classe Module Error. Em seguida, defina uma função chamada .create_connection () que aceitará o caminho para o banco de dados SQLite. Então .connect () do módulo sqlite3 tomará o caminho do banco de dados SQLite como um parâmetro. Se o banco de dados existe no caminho especificado em .connect, Uma conexão com o banco de dados será estabelecida. Pelo contrário, Um novo banco de dados é criado no caminho especificado e, em seguida, uma conexão é estabelecida.
sqlite3.connect (rota) retornará um objeto de conexão, que também foi devolvido por create_connection (). Esse objeto de conexão será usado para executar consultas SQL em um banco de dados SQLite. A próxima linha de código criará uma conexão com o banco de dados SQLite:
conexão=create_connection("E:example_app.sqlite")
Uma vez que a conexão é estabelecida, podemos ver que o arquivo de banco de dados é criado no diretório raiz e se quisermos, Também podemos alterar a localização do arquivo.
Neste artigo, discutimos como o SQL é essencial para a ciência de dados e também como podemos trabalhar com SQL usando Python. Obrigado pela leitura. Deixe-me saber seus comentários e sugestões na seção de comentários.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





