Esta postagem foi lançada como parte do Data Science Blogathon
Introdução
Como cientista de dados, web scraping é uma das habilidades vitais que você precisa para dominar, e você deve procurar dados úteis, coletar e pré-processar dados para que seus resultados sejam significativos e precisos.
Antes de mergulharmos nas ferramentas que podem ajudar nas atividades de mineração de dados, vamos confirmar que essa atividade é legal, visto que web scraping tem sido uma área jurídica cinzenta. O tribunal de EE. UU. Web scraping totalmente legalizado de dados publicamente disponíveis em 2020. Isso significa que se você encontrou informações online (como posts de Wiki), então é legal raspar os dados.
Ainda assim, Quando você faz, tenha certeza de:
- Não reutilizar ou republicar dados de uma maneira que viole os direitos autorais.
- Que você cumpra os termos de serviço do portal da web que está copiando.
- Que você tem uma taxa de rastreamento justa.
- Não tente extrair partes privadas do portal da web.
Contanto que não viole os termos acima, sua atividade de web scraping estará no lado legal.
Acho que alguns de vocês podem ter usado BeautifulSoup e solicitações para coletar os dados e pandas para analisá-los para seus projetos. Esta postagem apresentará cinco ferramentas de web scraping que não incluem o BeautifulSoup; é gratuito para usar e coleta os dados para seu próximo projeto.
O criador do Rastreamento comum criou essa ferramenta porque pressupõe que todos devem ter a capacidade de explorar e realizar análises dos dados ao seu redor e descobrir informações úteis.. Eles contribuem com dados de alta qualidade que só estavam abertos a grandes instituições e institutos de pesquisa para qualquer mente curiosa, sem nenhum custo para encorajar suas crenças de código aberto..
Você pode usar esta ferramenta sem se preocupar com taxas ou quaisquer outras dificuldades financeiras. Se você é um estudante, um novato mergulhando na ciência de dados ou apenas uma pessoa ávida que adora explorar o conhecimento e descobrir novas tendências, esta ferramenta seria útil. Disponibilizar dados brutos de páginas da web e extratos de palavras como conjuntos de dados abertos. Ele também oferece recursos para instrutores que ensinam análise de dados e suporte para casos de uso não baseados em código..
Ir através site web para obter mais informações sobre o uso de conjuntos de dados e alternativas para extrair os dados.
Crawly é outra alternativa, especialmente se você só precisa extrair dados simples de um portal da web ou se deseja extrair dados em formato CSV para que possa examiná-los sem escrever nenhum código. O usuário deve inserir um URL, um e-mail de identificação para enviar os dados extraídos, o formato dos dados necessários (escolha entre CSV ou JSON) e pronto, os dados extraídos estão em sua caixa de entrada para uso.
Pode-se usar dados JSON e analisá-los usando Pandas e Matplotlib, ou qualquer outra linguagem de programação. Se você é um novato em ciência de dados e web scraping, não um programador, isso é bom e tem suas limitações. Um conjunto limitado de tags HTML, incluindo o título, pode ser extraído, Autor, URL e editor da imagem.
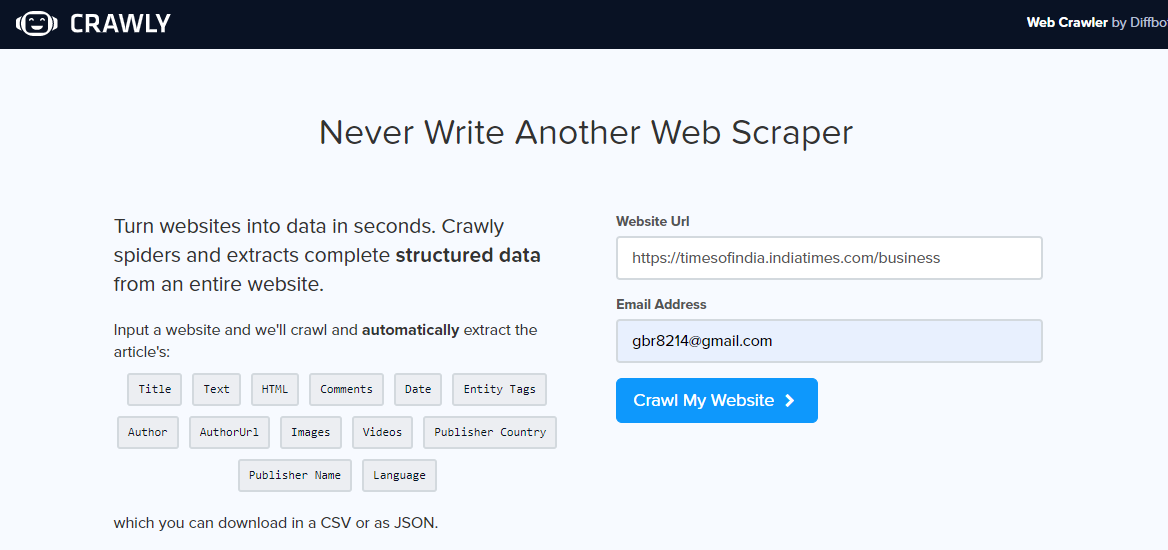
Depois de abrir o portal da web de rastreamento, insira url para raspar, selecione o formato dos dados e seu ID de e-mail para receber os dados. Verifique sua caixa de entrada para ver os dados.
O capturador de conteúdo é uma ferramenta flexível se você gosta de arranhar uma página da web e não deseja especificar outros parâmetros, o usuário pode fazer isso usando sua interface de usuário simples. Ainda assim, oferece a opção de controle total dos parâmetros de extração para personalizar.
O usuário pode agendar a coleta de informações da web automaticamente, é uma de suas vantagens. Na atualidade, todos nós sabemos que as páginas da web são atualizadas regularmente, então a extração frequente de conteúdo seria útil.
Oferece vários formatos de dados extraídos como CSV, JSON a SQL Server ou MySQL.
Um exemplo rápido para raspar os dados
Você pode usar essa ferramenta para navegar visualmente no portal da web e clicar nos itens de dados na ordem em que deseja coletá-los.. Ele detectará automaticamente o tipo correto de ação e fornecerá nomes padrão para cada comando à medida que constrói o agente com base nos itens de conteúdo especificados.
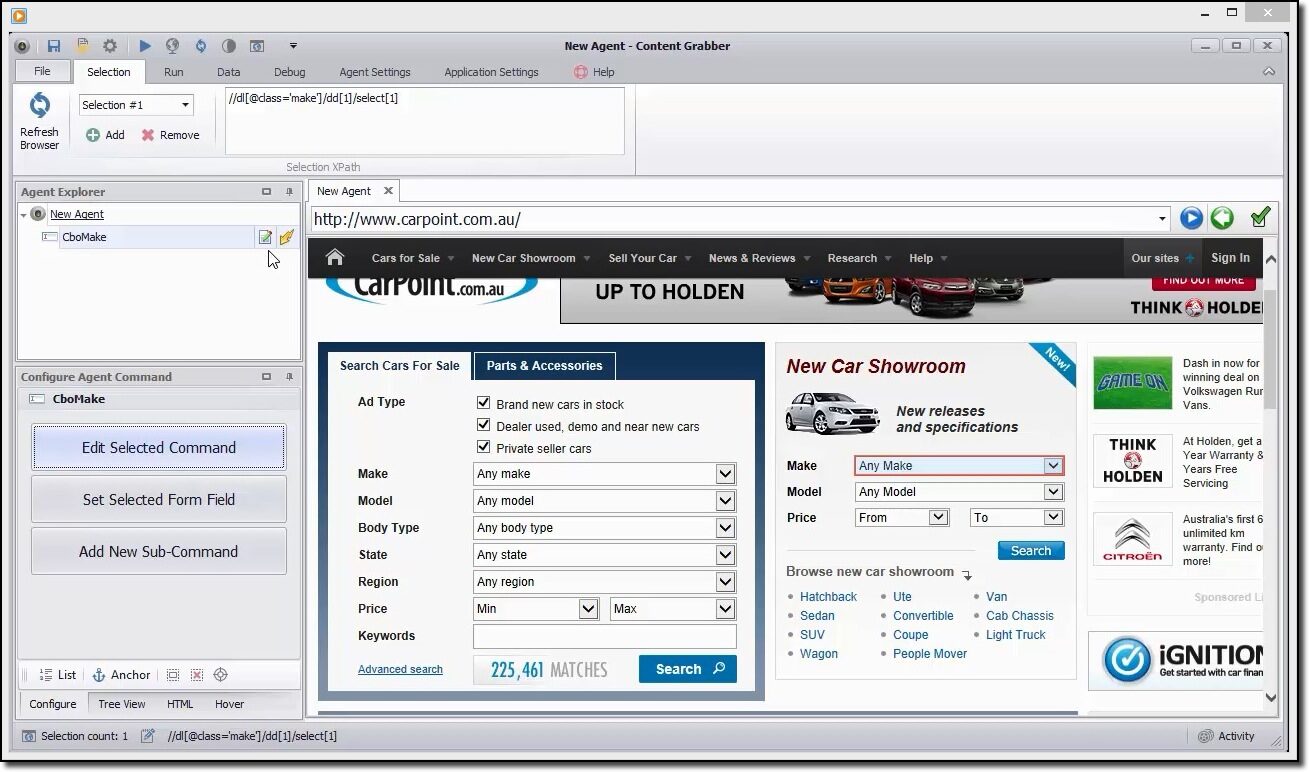
Esta ferramenta é uma coleção de comandos que são executados em ordem até serem concluídos. A ordem de execução é atualizada no painel Agent Explorer. Você pode usar o painel de comando do agente de configuração para personalizar o comando com base em seus requisitos de dados específicos.. Os usuários também podem adicionar novos comandos.
ParseHub é uma ferramenta poderosa de web scraping que qualquer pessoa pode usar gratuitamente. Oferece extração de dados segura e precisa com a facilidade de um clique. Os usuários também podem determinar os tempos de extração para manter a relevância de seus restos mortais..
Um de seus pontos fortes é que ele pode apagar até mesmo as páginas da web mais complicadas sem problemas.. O usuário pode especificar instruções, como formulários de pesquisa, faça login em sites e clique em mapas ou imagens para coleta de dados posterior.
Os usuários também podem entrar com muitos links e palavras-chave, onde podem extrair informações relevantes em segundos. Para terminar, você pode usar a API REST para baixar os dados extraídos para análise nos formatos CSV ou JSON. Os usuários também podem exportar as informações coletadas como uma planilha do Google ou Tableau..
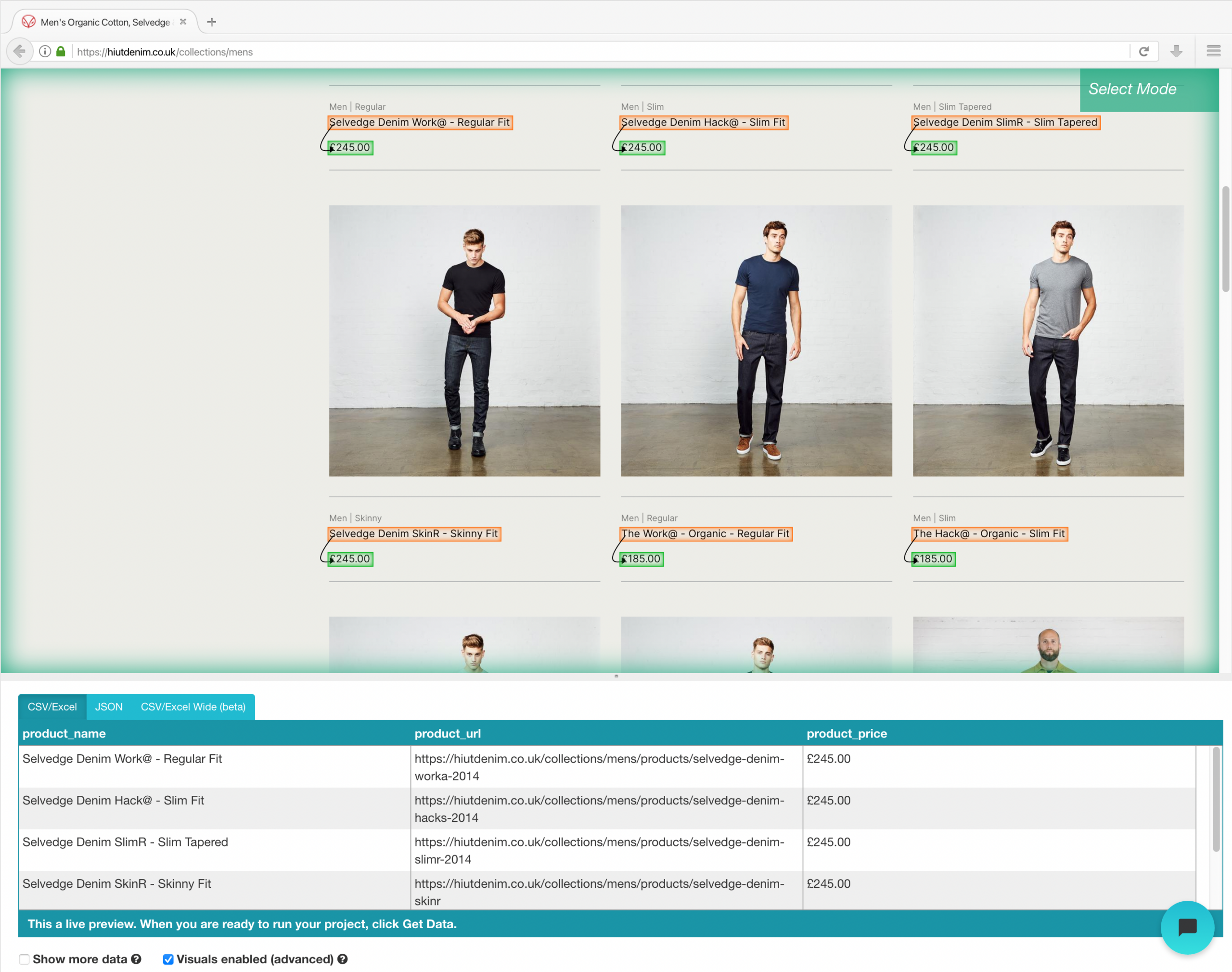
Exemplo de portal da web de scraping de comércio eletrônico
Assim que a instalação estiver concluída, abra um novo projeto no ParseHub, use o url de comércio eletrônico e a página será processada no aplicativo.
- Clique no nome do produto do primeiro resultado na página depois que o site for carregado. Quando você seleciona o produto, fica verde para indicar que foi escolhido.
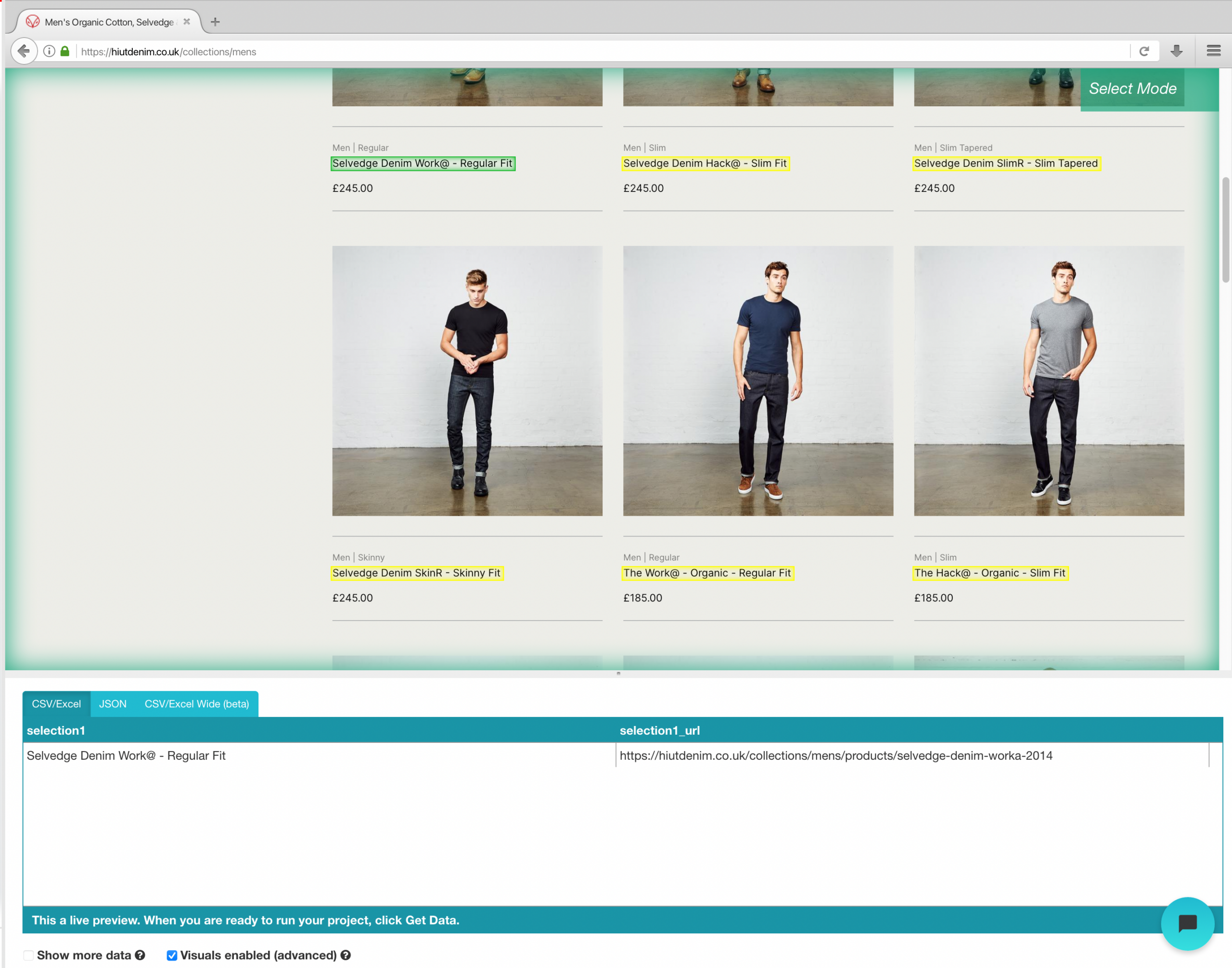
- Amarelo será usado para destacar o resto dos nomes de produtos. Selecione a segunda opção da lista. Verde agora será usado para destacar todos os objetos.
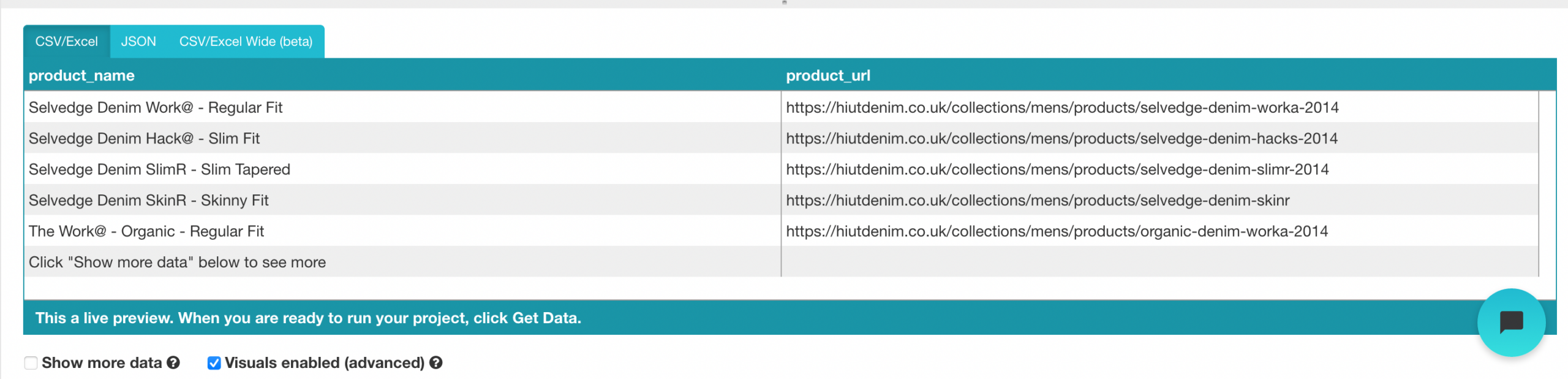
- Mude o nome de sua escolha para “produtos” na barra lateral esquerda. Agora você pode ver o nome do produto e o url obtido pelo ParseHub.
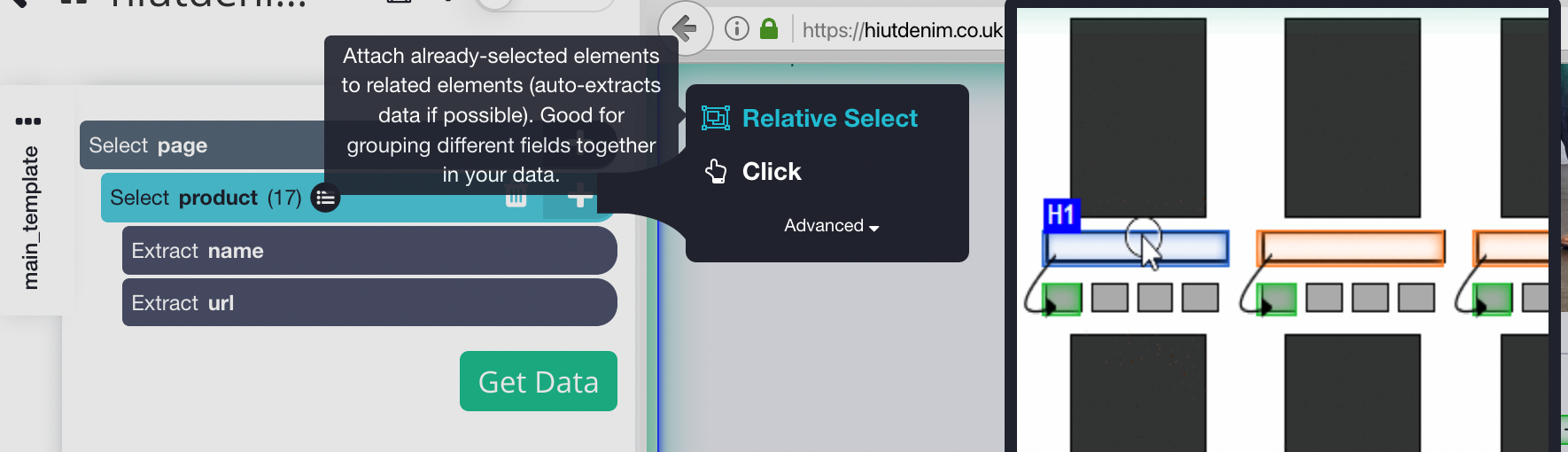
- Clique no sinal MAIS (+) próximo à seleção de produto na barra lateral esquerda e selecione o comando Seleção relativa.
- Clique no primeiro nome do produto na página, seguido pelo preço do produto, usando o comando Seleção Relativa. Uma seta aparecerá conectando as duas opções. Esta etapa precisa ser repetida várias vezes para treinar o Parsehub no que você deseja extrair.
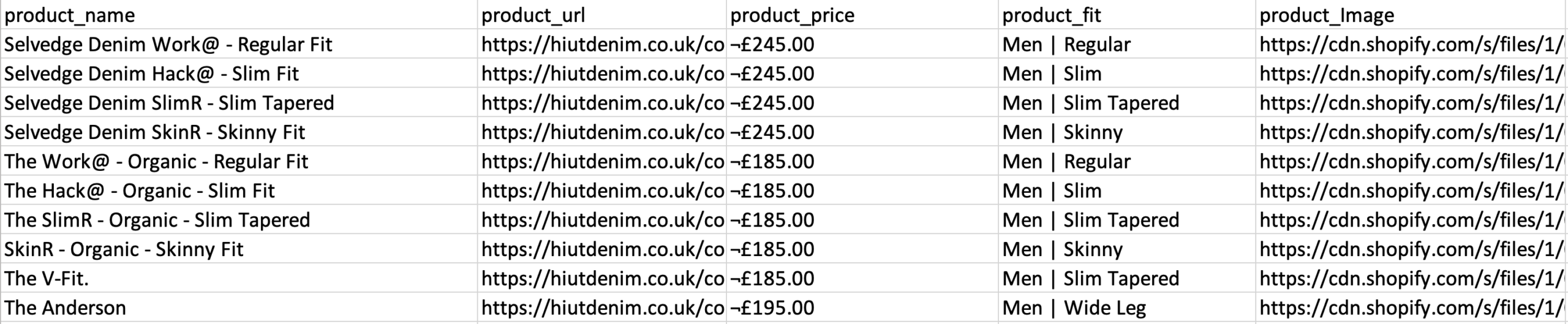
- Repita a etapa anterior para extrair também o estilo de ajuste e a imagem do produto. Certifique-se de renomear suas novas opções de forma adequada.
Execução e exportação do seu projeto
Agora que terminamos de configurar o projeto, é hora de executar nosso trabalho de raspagem.
Para executar sua raspagem, clique no botão Obter dados na barra lateral esquerda e, em seguida, clique no botão Executar. Para projetos maiores, sugerimos executar um teste para verificar se seus dados estão no formato correto.
É a última ferramenta de raspagem da lista. Ele tem uma API de web scraping que pode manipular até mesmo as páginas Javascript mais complexas e convertê-las em HTML bruto para uso dos usuários.. Também oferece uma API específica para raspar sites por meio de pesquisa do Google..
Podemos usar essa ferramenta de três maneiras:
- Web Scraping geral, como um exemplo, extração de avaliações de clientes ou preços de ações.
- Página de resultados do mecanismo de pesquisa usada para rastreamento de palavras-chave ou SEO.
- A extração de informações de contato ou dados de redes sociais inclui Growth Hacking.
Esta ferramenta oferece um plano gratuito que inclui 1000 créditos e planos pagos para uso ilimitado.
Tutorial sobre como usar a API Scrapingbee
Inscreva-se para um plano gratuito no portal da web ScrapingBee e você obterá 1000 pedidos de API grátis, que deve ser o suficiente para aprender e testar esta API.
Agora vá para o painel de controle e copie a chave de API de que precisaremos posteriormente neste guia. ScrapingBee agora oferece suporte multilíngue, permitindo que você use a chave API diretamente em seus aplicativos.
Como o Scaping Bee suporta APIs REST, é adequado para qualquer linguagem de programação, incluindo CURL, Pitão, Nodejs, Java, PHP e Go. Para mais informações sobre raspagem, usaremos Python e a estrutura de solicitação, bem como BeautifulSoup. Instale-os usando PIP o mais rápido possível:
# Para instalar a biblioteca Python Requests: pedidos de instalação de pip # Módulos adicionais que precisávamos: pip instalar BeautifulSoup
Use o seguinte código para iniciar a API da Web ScrapingBee. Estamos fazendo uma chamada de solicitação com os parâmetros-chave de URL e API, e a API responderá com o conteúdo HTML da URL de destino.
import requests def get_data(): resposta = solicitações.get( url="https://app.scrapingbee.com/api/v1/", params={ "Chave API": "INSERA-SUA-API-KEY", "url": "https://example.com/", #site para raspar }, ) imprimir('código de status http: ', response.status_code) imprimir('http corpo de resposta: ', response.content) Obter dados()
Ao adicionar um código de embelezamento, podemos tornar esta saída mais legível usando BeautifulSoup.
Codificação
você também pode usar urllib.parse para criptografar a url que você deseja raspar, como é mostrado a seguir:
import urllib.parse
encoded_url = urllib.parse.quote("URL para raspar")
conclusão
Coletar dados para seus projetos é a etapa mais entediante e menos divertida. Esta tarefa pode levar muito tempo, e se você trabalha em uma empresa ou como freelancer, Eu sabia que tempo é dinheiro, e se existe uma maneira mais importante de fazer uma tarefa, é melhor você usar isso. A boa notícia é que web scraping não precisa ser entediante, já que usar a ferramenta correta pode ajudá-lo a economizar muito tempo, dinheiro e esforço. Essas ferramentas podem ser benéficas para analistas ou pessoas sem habilidades de codificação.. Antes de escolher uma ferramenta de raspagem, existem alguns fatores a considerar, como integração de API e extensibilidade de scraping em grande escala. Esta postagem apresentou algumas ferramentas úteis para diferentes tarefas de coleta de dados., onde você pode selecionar aquele que facilita a coleta de dados.
Espero que este artigo seja útil. Obrigado.
A mídia mostrada nesta postagem não é propriedade da DataPeaker e é usada a critério do autor.





