Introdução
Se eu tivesse que escolher uma plataforma que me mantivesse atualizado com os últimos desenvolvimentos em Ciência de dados e aprendizado de máquina – seria o GitHub. A grande escala do GitHub, combinado com o poder dos cientistas de superdados em todo o mundo, torna-se uma plataforma obrigatória para qualquer pessoa interessada neste campo..
Você pode imaginar um mundo onde bibliotecas e estruturas de aprendizado de máquina como o BERT, StanfordNLP, TensorFlow, PyTorch, etc. não eram de código aberto? É impensável!! O GitHub democratizou o aprendizado de máquina para as massas, exatamente em linha com o que acreditamos em DataPeaker.
Essa foi uma das principais razões pelas quais começamos esta série do GitHub, cobrindo as bibliotecas e pacotes de aprendizado de máquina mais úteis em janeiro. 2018.

Junto com isso, Também cobrimos discussões no Reddit que achamos relevantes para todos os profissionais de ciência de dados.. Este mês não é diferente. Seleccionei os cinco principais debates de Maio, que se concentram em duas coisas: Técnicas de aprendizado de máquina e conselhos profissionais de cientistas de dados especializados.
Você também pode conferir os repositórios do GitHub e as discussões do Reddit que abordamos ao longo deste ano.:
Principais repositórios do GitHub (Maio 2019)


A interpretabilidade é uma coisa ENORME no aprendizado de máquina agora. Ser capaz de entender como um modelo produziu o resultado que produziu, Um aspecto fundamental de qualquer projeto de aprendizado de máquina. De fato, nós até fizemos um podcast com Christoph Molar sobre ML interpretável que você deve verificar.
InterpretML é um pacote de código aberto da Microsoft para treinar modelos interpretáveis e explicar sistemas de caixa preta. A Microsoft colocou isso melhor quando explicou por que a interpretabilidade é essencial.:
- Modelos de depuração: Por que meu modelo cometeu esse erro??
- Detectando viés: O meu modelo discrimina?
- Cooperação humano-IA: Como posso entender e confiar nas decisões do modelo??
- Conformidade: O meu modelo cumpre os requisitos legais??
- Aplicações de alto risco: Sanitário, financeiro, judicial, etc.
Interpretar el funcionamiento interno de un modelo de aprendizaje automático se vuelve más difícil a mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que aumenta la complejidad. Você já tentou desmontar e entender um conjunto de vários modelos?? Leva muito tempo e esforço para fazê-lo.
Não podemos simplesmente ir ao nosso cliente ou liderança com um modelo complexo sem poder explicar como ele produziu uma boa pontuação. / precisão. Esse é um bilhete de ida de volta à prancheta de desenho para nós..
O pessoal da Microsoft Research desenvolveu o algoritmo Explainable Boosting Machine. (EBM) para ajudar na interpretação. Esta técnica de EBM tem alta precisão e inteligibilidade: O Santo Graal.
A interpretação do ML não se limita ao uso do EBM. Ele também suporta algoritmos como o LIME, Modelos lineares, Árvores de decisão, entre outros. Comparar modelos e escolher o melhor para o nosso projeto nunca foi tão fácil!!
Você pode instalar o InterpretML usando o código a seguir:
pip install numpy scipy pyscaffold
pip install -U interpret
Google Research faz outra aparição em nossa série mensal do Github. Sem surpresas: Eles têm o maior poder computacional no negócio e estão usando-o no aprendizado de máquina.

Sua versão mais recente de código aberto, chamado Tensor2Robot (T2R) É bastante impressionante. T2R es una biblioteca para TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina...., Avaliação e inferência de redes neurais profundas em larga escala. Mas espere, foi desenvolvido com um objetivo específico em mente. Ele é projetado para redes neurais relacionadas à percepção e controle robótico.
No hay premios por adivinar el marco de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... en el que se construye Tensor2Robot. Assim é, TensorFlow. Tensor2Robot é usado dentro do Alphabet, A organização-mãe do Google.
Aqui estão alguns projetos implementados com o Tensor2Robot:
TensorFlow 2.0, a versão do TensorFlow (TF) mais esperado este ano, Foi lançado oficialmente no mês passado. E eu mal podia esperar para colocar minhas mãos nele!!

Este repositório contém implementações TF de vários modelos generativos, Incluindo:
- Redes adversárias generativas (GAN)
- Autocodificador
- Autocodificador variacional (Ai de mim)
- VAE-GAN, entre outros.
Todos esses modelos são implementados em dois conjuntos de dados com os quais você estará bastante familiarizado.: Moda MNIST e NSYNTH.
A melhor parte? Todas essas implementações estão disponíveis em um Jupyter Notebook!! Então você pode fazer o download e executá-lo em sua própria máquina ou exportá-lo para o Google Colab. A escolha é sua e TensorFlow 2.0 Está aqui para você entender e usar.
![]()
Um repositório de séries temporais! No me he encontrado con un nuevo desarrollo de Série temporalUma série temporal é um conjunto de dados coletados ou medidos em momentos sucessivos, geralmente em intervalos de tempo regulares. Esse tipo de análise permite identificar padrões, Tendências e ciclos nos dados ao longo do tempo. Sua aplicação é ampla, abrangendo áreas como economia, Meteorologia e saúde pública, facilitando a previsão e a tomada de decisões com base em informações históricas.... en bastante tiempo.
STUMPY é uma biblioteca poderosa e escalável que nos ajuda a executar tarefas de mineração de dados de séries temporais. STUMPY é projetado para calcular um perfil de matriz. Eu posso vê-lo se perguntando: O que diabos é um perfil de matriz? Nós vamos, Este perfil matricial é um vetor que armazena a distância euclidiana normalizada z entre qualquer subsequência dentro de uma série temporal e seu vizinho mais próximo..
Abaixo estão algumas tarefas de mineração de dados de séries temporais que esse perfil de matriz nos ajuda a executar:
- Descoberta de anomalias
- SegmentaçãoA segmentação é uma técnica de marketing chave que envolve a divisão de um mercado amplo em grupos menores e mais homogêneos. Essa prática permite que as empresas adaptem suas estratégias e mensagens às características específicas de cada segmento, melhorando assim a eficácia de suas campanhas. A segmentação pode ser baseada em critérios demográficos, psicográfico, geográfico ou comportamental, facilitando uma comunicação mais relevante e personalizada com o público-alvo.... semántica
- Estimativa de densidade
- Cadeias de caracteres de séries temporais (Conjunto temporalmente ordenado de padrões de subsequência)
- Descoberta de padrões / razão (subsequências aproximadamente repetidas dentro de uma série temporal mais longa)
Use o código a seguir para instalá-lo diretamente através de semente:
pip instalar stumpy
MeshCNN es una neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. profunda de uso general para mallas triangulares 3D. Essas malhas podem ser usadas para tarefas como classificar ou segmentar formas 3D.. Um ótimo aplicativo de visão mecânica.
A estrutura MeshCNN inclui camadas de convolução, agrupamento e desaparecimento que são aplicados diretamente nas bordas da malha:
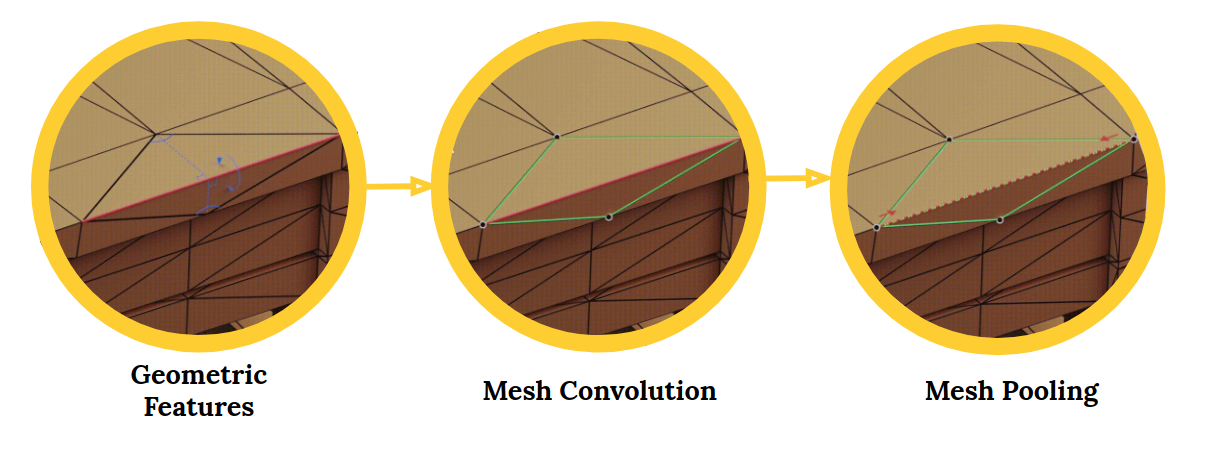
Redes Neurais Convolucionais (CNN) são perfeitos para trabalhar com imagens e dados visuais. As CNNs tornaram-se moda nos últimos tempos com um boom de tarefas relacionadas à imagem decorrentes delas.. Detecção de objetos, segmentação de imagem, Classificação das imagens, etc., tudo isso é possível graças ao avanço da CNN.
O aprendizado profundo 3D está atraindo o interesse do setor, incluindo áreas como robótica e condução autônoma. O problema com as formas 3D é que elas são inerentemente irregulares.. Isso torna operações como convoluções difíceis e desafiadoras..
É aqui que entra o MeshCNN.. Do repositório:
Malhas são uma lista de vértices, Bordas e faces, que juntos definem a forma do objeto 3D. O problema é que cada vértice tem um número diferente de vizinhos e não há ordem..
Se você é um fã de visão computacional e está interessado em aprender ou aplicar CNNs, Este é o repositório perfeito para você. Você pode aprender mais sobre CNNs através de nossos artigos:

Os algoritmos de árvore de decisão estão entre as primeiras técnicas avançadas que aprendemos no aprendizado de máquina. Honestamente, Eu realmente aprecio esta técnica após a regressão logística. Você pode usá-lo em conjuntos de dados maiores, entenda como funcionava, Como ocorreram as divisões, etc.
Pessoalmente, Eu amo este repositório. É um tesouro para os cientistas de dados. O repositório contém uma coleção de artigos sobre algoritmos baseados em árvore, incluindo árvores de decisão, Regressão e classificação. O repositório também contém a implementação de cada artigo. O que mais poderíamos pedir??
Você já se perguntou como funciona o processo de treinamento do seu algoritmo de aprendizado de máquina?? Nós escrevemos o código, Algumas complicações ocorrem nos bastidores (O prazer de programar!), E obtemos os resultados.
A Microsoft Research criou uma ferramenta chamada TensorWatch que nos permite ver visualizações em tempo real do processo de treinamento do nosso modelo de aprendizado de máquina. Surpreendente! Veja um trecho de como o TensorWatch funciona:

TensorWatch, em termos simples, é uma ferramenta de depuração e visualização para aprendizagem profunda e aprendizagem por reforço. Ele funciona em cadernos Jupyter e nos permite fazer muitas outras visualizações personalizadas de nossos dados e nossos modelos.
Discussões do Reddit
![]()
Vamos dar alguns momentos para analisar as discussões mais incríveis do Reddit relacionadas à ciência de dados e ao aprendizado de máquina em maio. 2019. Aqui está algo para todos, Se você é um entusiasta ou praticante da ciência de dados. Então, vamos nos aprofundar!!
Esta é uma noz difícil de quebrar. A primeira questão é se você deve optar por um PhD antes de assumir uma posição na indústria.. E logo, Se você optou por um, Quais habilidades você deve adquirir para facilitar a transição do seu setor??
Acho que essa discussão pode ser útil para decifrar um dos maiores enigmas da nossa carreira.: Como fazemos a transição de um campo ou linha de trabalho para outro?? Não olhe para isso apenas do ponto de vista de um estudante de doutorado. Isso é muito relevante para a maioria de nós que queremos dar o primeiro salto no aprendizado de máquina..
Eu recomendo que você siga este tópico, como muitos cientistas de dados experientes compartilharam suas experiências pessoais e aprendizado.
Recentemente, Um artigo de pesquisa foi publicado expandindo o título deste tópico. O jornal explicou a hipótese do bilhete de loteria em que uma sub-rede menor, Também conhecido como bilhete premiado, poderia treinar mais rápido em comparação com uma rede maior.
Esta discussão centra-se neste documento. Leia mais sobre a hipótese do bilhete de loteria e como ela funciona, Você pode conferir meu artigo onde analiso esse conceito para que até mesmo os iniciantes o entendam:
Decodificando os melhores artigos da ICLR 2019: As redes neurais estão aqui para governar
Escolhi essa discussão porque posso me relacionar totalmente com ela.. Eu costumava pensar: Aprendi muito e, porém, Resta muito mais. Será que algum dia vou me tornar um especialista?? Eu cometi o erro de olhar apenas para a quantidade e não para a qualidade do que eu estava aprendendo..
Com tecnologia contínua e de avanço rápido, sempre haverá MUITO a aprender. Este tópico tem algumas dicas sólidas sobre como você pode definir prioridades., atenha-se a eles e concentre-se na tarefa em questão, em vez de tentar se tornar um especialista em todos os negócios..
Notas finais
Eu me diverti muito! (e eu aprendi) montando a coleção GitHub de aprendizado de máquina deste mês! Eu recomendo marcar ambas as plataformas e verificá-las regularmente. É uma ótima maneira de se manter atualizado com todos os novos recursos do aprendizado de máquina.
Ou você sempre pode voltar todos os meses e ver nossas melhores escolhas. 🙂
Se você acha que eu perdi um repositório ou discussão, Comente abaixo e ficarei feliz em ter uma discussão sobre isso..





