Este artigo foi publicado como parte do Data Science Blogathon
Introdução
No artigo de hoje, Vou falar sobre o desenvolvimento de uma rede neural convolucional que usa a API TensorFlow funcional. Dispensará capacidade API funcional, permitindo-nos produzir uma arquitetura de modelo híbrido que excede a capacidade de um modelo sequencial primário.
Sobre: TensorFlow
TensorFlow é uma biblioteca popular, algo que você provavelmente ouve perpetuamente na sociedade de Deep Learning e Inteligência Artificial. Existen numerosos paquetes y proyectos de código abierto para el aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde....
- TensorFlow, uma biblioteca de inteligência artificial de código aberto que gerencia fluxogramas de dados, é a biblioteca de aprendizado profundo mais comum. É usado para gerar redes neurais em grande escala com inúmeras camadas.
- O TensorFlow é praticado para situações de aprendizado profundo ou de aprendizado de máquina, como classificação, Percepção, Percepção, Descoberta, Previsão e Produção.
Então, quando interpretamos um problema de classificação, aplicamos un modelo de convolucional neuronal vermelhoRedes Neurais Convolucionais (CNN) são um tipo de arquitetura de rede neural projetada especialmente para processamento de dados com uma estrutura de grade, como fotos. Eles usam camadas de convolução para extrair recursos hierárquicos, o que os torna especialmente eficazes em tarefas de reconhecimento e classificação de padrões. Graças à sua capacidade de aprender com grandes volumes de dados, As CNNs revolucionaram campos como a visão computacional... Ainda assim, a maioria dos desenvolvedores estava familiarizada com a modelagem de modelo sequencial. As camadas são acompanhadas uma a uma.
- API sequencial permite projetar modelos camada por camada para os problemas mais importantes.
- A dificuldade é restrita porque não permite que você produza modelos que compartilhem camadas ou tenham entradas ou saídas adicionadas.
- Devido a isto, podemos praticar a API funcional do Tensorflows como modelo de saída múltipla.
API funcional (tf.Hard)
A API funcional em tf.Hard é uma forma alternativa de construir modelos mais flexíveis, incluindo a formulação de um modelo mais complexo.
- Por exemplo, ao implementar um exemplo insignificantemente mais complicado com aprendizado de máquina, você raramente se depara com o estado em que exige modelos adicionais para os mesmos dados.
- Então precisaríamos produzir duas saídas. A opção mais gerenciável seria construir dois modelos separados com base nos dados correspondentes para fazer previsões..
- Isso seria bom, mas e se, no cenário atual, nós tínhamos que ter 50 resultados? Pode ser um incômodo manter todos esses modelos separados.
- alternativamente, é mais proveitoso construir um único modelo com melhores resultados.
No método de API aberta, os modelos são determinados formando camadas e correlacionando-as diretamente entre si em conjuntos, em seguida, é estabelecido um modelo que define as camadas para funcionar como entrada e saída.
O que é diferente na API Sequencial?
A API sequencial permite que você gere modelos camada por camada para a maioria das consultas principais. É regulamentado porque não permite que você projete modelos que compartilhem camadas ou tenham entradas ou saídas adicionadas.
Vamos entender como criar um objeto de modelo de API sequencial abaixo:
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape =(28, 28)), tf.hard.layers.Dense(128, ativação = "revisar"), tf.keras.layers.Dropout(0.2), tf.hard.layers.Dense(10, ativação = ’softmax’) ])
- Na API funcional, você pode projetar modelos que produzem muito mais versatilidade. Com certeza, pode corrigir modelos nos quais as camadas se relacionam com mais camadas do que antes e depois.
- Pode combinar camadas com várias outras camadas. Como consequência, a produção de redes heterogêneas como redes siamesas e redes residuais torna-se viável.
Vamos começar a desenvolver um modelo CNN praticando uma API funcional
Neste post, utilizamos el conjunto de datos MNIST para construir la neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. convolucional para la clasificación de imágenes. o base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... del MNIST comprende 60,000 imágenes de capacitación y 10,000 imágenes de prueba obtenidas de trabajadores de la Oficina del Censo de Estados Unidos y estudiantes de tercer año de secundaria estadounidenses.
# import libraries import numpy as np import tensorflow as tf from tensorflow.keras.layers import Dense, Cair fora, Input from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten from tensorflow.keras.models import Model from tensorflow.keras.datasets import mnist # dados de carga (x_train, y_train), (x_test, y_test) = mnist.load_data() # convert sparse label to categorical values num_labels = len(np.unique(y_train)) y_train = to_categorical(y_train) y_test = to_categorical(y_test) # preprocess the input images image_size = x_train.shape[1] x_train = np.reshape(x_train,[-1, image_size, image_size, 1]) x_test = np.reshape(x_test,[-1, image_size, image_size, 1]) x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255
En el código de arriba,
- Distribuí estos dos grupos como TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... y prueba y distribuí las etiquetas y las entradas.
- Las variables independientes (x_train y x_test) contienen códigos RGB en escala de grises de 0 uma 255, mientras que las variables dependientes (y_train e y_test) llevan etiquetas de 0 uma 9, que describen qué número son realmente.
- Es una buena práctica normalizar nuestros datos, ya que se requiere constantemente en los modelos de aprendizaje profundo. Podemos lograr esto dividiendo los códigos RGB por 255.
A seguir, inicializamos los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... para las redes.
# parameters for the network input_shape = (image_size, image_size, 1) batch_size = 128 kernel_size = 3 filtros = 64 dropout = 0.3
En el código de arriba,
- input_shape: o variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... representa la necesidad de planificar y diseñar una camada de entradao "camada de entrada" refere-se ao nível inicial em um processo de análise de dados ou em arquiteturas de redes neurais. Sua principal função é receber e processar informações brutas antes de serem transformadas por camadas subsequentes. No contexto do aprendizado de máquina, A configuração adequada da camada de entrada é crucial para garantir a eficácia do modelo e otimizar seu desempenho em tarefas específicas.... independiente que designe los datos de entrada. A camada de entrada aceita um argumento de forma que seja uma tupla que descreve as dimensões dos dados de entrada.
- Tamanho do lote: é um hiperparâmetro que determina o número de amostras a serem executadas antes de atualizar os parâmetros internos do modelo.
- kernel_size: relaciona-se com as dimensões (altura largura x) máscara de filtro. Redes Neurais Convolucionais (CNN) eles são essencialmente uma pilha de camadas marcadas pelas operações de vários filtros na entrada. Esses filtros são comumente chamados de núcleos..
- filtro: é expresso por um vetor de pesos entre os quais convolvemos a entrada.
- Sair: é um processo em que neurônios selecionados aleatoriamente são negligenciados durante o treinamento. Isso implica que sua participação na ativação dos neurônios a jusante está temporariamente excluída na passagem frontal..
Vamos definir um perceptron multicamadas simplista, una red neuronal convolucional:
# utiliaing functional API to build cnn layers inputs = Input(shape=input_shape) y = Conv2D(filters=filters, kernel_size=kernel_size, ativação = 'reler')(inputs) y = MaxPooling2D()(e) y = Conv2D(filters=filters, kernel_size=kernel_size, ativação = 'reler')(e) y = MaxPooling2D()(e) y = Conv2D(filters=filters, kernel_size=kernel_size, ativação = 'reler')(e) # convert image to vector y = Flatten()(e) # dropout regularization y = Dropout(cair fora)(e) outputs = Dense(num_labels, ativação = 'softmax')(e) # model building by supplying inputs/outputs model = Model(inputs=inputs, outputs=outputs)
En el código de arriba,
- Especificamos un modelo de perceptrón multicapa hacia la clasificación binaria.
- El modelo contiene una capa de entrada, 3 capas ocultas junto a 64 neurônios e uma camada de produto com 1 Saída.
- As funções de gatilho linear retificado se aplicam a todas as camadas ocultas, y se adopta una função de despertarA função de ativação é um componente chave em redes neurais, uma vez que determina a saída de um neurônio com base em sua entrada. Seu principal objetivo é introduzir não linearidades no modelo, permitindo que você aprenda padrões complexos em dados. Existem várias funções de ativação, como o sigmóide, ReLU e tanh, cada um com características particulares que afetam o desempenho do modelo em diferentes aplicações.... softmax en la capa de producto para la clasificación binaria.
- E você pode ver que as camadas no modelo são correlacionadas aos pares. Isso é feito estipulando de onde vem a entrada ao determinar cada nova camada.
- Tal como acontece com todas as APIs sequenciais, o modelo é a informação que podemos resumir, ajustar, evaluar y aplicar para ejecutar predicciones.
TensorFlow presenta una clase de modelo que puede practicar para generar un modelo a partir de sus capas desarrolladas. Exige que solo defina las capas de entrada y salida, mapeando la estructura y el gráfico del modelo de la arquitectura de red.
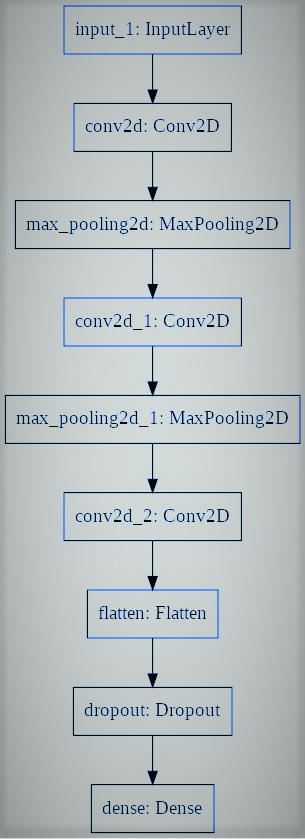
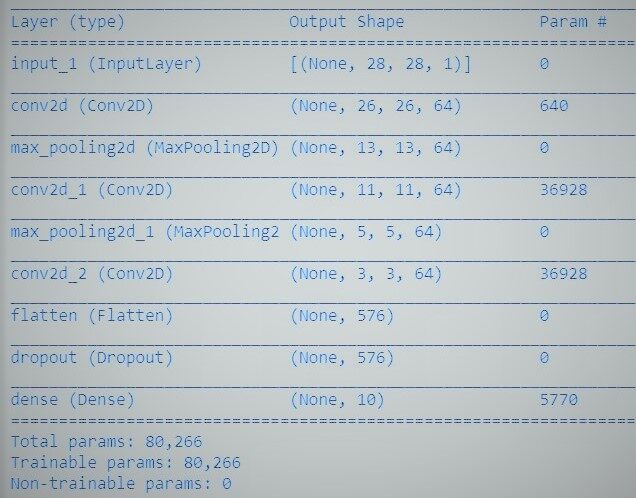
Por último, entrenamos al modelo.
model.compile(perda ="categorical_crossentropy", otimizador ="Adão", metrics =['precisão']) model.fit(x_train, y_train, validação_data =(x_test, y_test), epochs=20, batch_size = batch_size) # accuracy evaluation score = model.evaluate(x_test, y_test, batch_size = batch_size, verbose = 0) imprimir("nTest accuracy: %.1f %%" % (100.0 * pontuação[1]))
Agora desenvolvemos com sucesso uma rede neural convolucional para distinguir dígitos escritos à mão com a API Tensorflow funcional. Obtivemos uma precisão superior a 99% e podemos salvar o modelo e projetar um aplicativo da web de classificação de dígitos.
Referências:
- https://www.tensorflow.org/guide/keras/functional
- https://machinelearningmastery.com/keras-functional-api-deep-learning/
A mídia mostrada neste artigo de reconhecimento de linguagem de sinais não é propriedade da DataPeaker e é usada a critério do autor.





