Classificação da árvore de decisão | Guia de classificação de árvore de decisão
Conteúdo
Visão geral
O que é o algoritmo da árvore de classificação de decisão?
Como construir uma árvore de decisão do zero
Terminologias de árvore de decisão
Diferença entre floresta aleatória e árvore de decisão
Implementação de código Python de árvores de decisão
Existem vários algoritmos em aprendizado de máquina para problemas de regressão e classificação, mas optando por O melhor e mais eficiente algoritmo para o conjunto de dados fornecido é o ponto principal a ser feito ao desenvolver um bom modelo de aprendizado de máquina..
Um desses algoritmos é bom para problemas de classificação / categórica e regressão é a árvore de decisão
As árvores de decisão geralmente implementam exatamente a capacidade de pensamento humana ao tomar uma decisão, então é fácil de entender.
A lógica por trás da árvore de decisão pode ser facilmente compreendida porque mostra uma estrutura do tipo fluxograma / estrutura em forma de árvore que facilita a visualização e a extração de informações do processo em segundo plano.
Tabela de conteúdo
O que é uma árvore de decisão?
Elementos da árvore de decisão
Como tomar uma decisão do zero
Como funciona o algoritmo da árvore de decisão?
Conhecimento de EDA (Análise exploratória de dados)
Árvores de decisão e florestas aleatórias
Vantagens da Floresta de Decisão
Desvantagens da Floresta de Decisão
Implementação de código Python
1. O que é uma árvore de decisão?
Uma árvore de decisão é um algoritmo de aprendizado de máquina supervisionado. Usado em algoritmos de classificação e regressão.. A árvore de decisão é como uma árvore com nós. Os ramos dependem de vários fatores. Divide os dados em ramificações como essas até atingir um valor limite. Uma árvore de decisão consiste nos nós raiz, nós filhos e nós folha.
Vamos entender os métodos da árvore de decisão tomando um cenário da vida real
Imagine que você joga futebol todos os domingos e sempre convida seu amigo para jogar com você. As vezes, seu amigo vem e outros não.
O fator de vir ou não depende de inúmeras coisas, como o tempo, a temperatura, vento e fadiga. Começamos a levar todos esses recursos em consideração e começamos a rastreá-los junto com a decisão do seu amigo de jogar ou não..
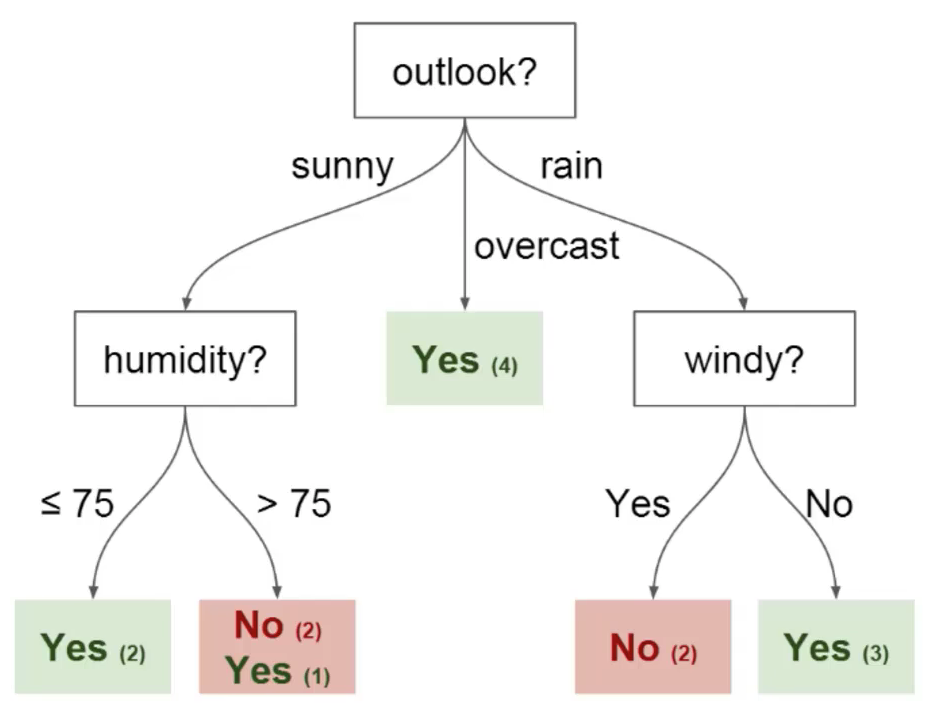
Você pode usar esses dados para prever se seu amigo virá jogar futebol ou não. A técnica que você pode usar é uma árvore de decisão. É assim que a árvore de decisão ficaria após a implantação:
2. Elementos de uma árvore de decisão
Cada árvore de decisão consiste na seguinte lista de elementos:
um nó
b Edges
c Root
d Folhas
uma) Nós: É o ponto onde a árvore é dividida de acordo com o valor de algum atributo / característica do conjunto de dados.
b) Arestas: Direciona o resultado de uma divisão para o próximo nó que podemos ver na figura anterior que existem nós para recursos como perspectiva, umidade e vento. Há uma vantagem para cada valor potencial de cada um desses atributos / caracteristicas.
c) Raiz: Este é o nó onde ocorre a primeira divisão.
d) Sai: Estes são os nós terminais que prevêem o resultado da árvore de decisão.
3. Como construir árvores de decisão do zero?
Ao criar uma árvore de decisão, o principal é selecionar o melhor atributo da lista de características totais do conjunto de dados para o nó raiz e para os subnós. A seleção dos melhores atributos é realizada com o auxílio de uma técnica conhecida como medida de seleção de atributos. (ASM).
Com a ajuda de ASM, podemos selecionar facilmente as melhores características para os respectivos nós da árvore de decisão.
Existem duas técnicas para ASM:
uma) Ganho de informação
b) Índice de Gini
uma) Ganho de informação:
1O ganho de informação é a medição das mudanças no valor da entropia após a divisão / segmentação do conjunto de dados com base em um atributo.
2 Indica quanta informação um recurso nos fornece / atributo.
3 Seguindo o valor do ganho de informação, a divisão de nós e a construção da árvore de decisão estão em andamento.
A árvore de decisão 4 sempre tente maximizar o valor do ganho de informação, e um nó / atributo que tem o maior valor de ganho de informação é dividido primeiro. O ganho de informação pode ser calculado usando a seguinte fórmula:
Ganho de informação = entropia (S) – [(Média Ponderada) *Entropia(cada característica)
Entropia: Entropia significa aleatoriedade no conjunto de dados. Está sendo definido como uma métrica para medir a impureza. A entropia pode ser calculada como:
O índice de Gini também está sendo definido como uma medida de impureza / pureza usada durante a criação de uma árvore de decisão no CART(conhecido como árvore de classificação e regressão) algoritmo.
Um atributo com um valor de índice Gini baixo deve ser preferido em contraste com o valor de índice Gini alto.
Ele apenas cria divisões binárias, e o algoritmo CART usa o índice Gini para criar divisões binárias.
O índice de Gini pode ser calculado usando a fórmula abaixo:
Índice de Gini = 1- ∑jPj2
Onde pj representa a probabilidade
4. Como funciona o algoritmo da árvore de decisão?
A ideia básica por trás de qualquer algoritmo de árvore de decisão é a seguinte:
1. Selecione o melhor recurso usando medidas de seleção de atributo(ASM) para dividir os registros.
2. Faça desse atributo / característica um nó de decisão e divida o conjunto de dados em subconjuntos menores.
3 Comece o processo de construção da árvore repetindo este processo recursivamente para cada criança até que uma das seguintes condições seja alcançada :
uma) Todas as tuplas pertencentes ao mesmo valor de atributo.
b) Não há mais atributos restantes.
c ) Não há mais instâncias restantes.
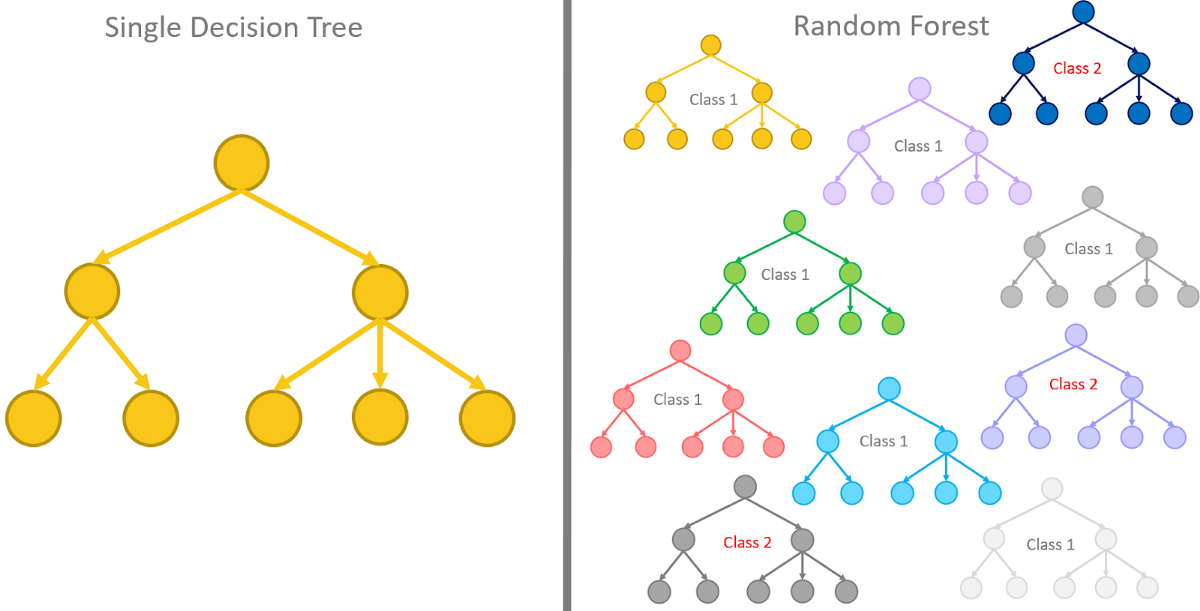
5. Árvores de decisão e florestas aleatórias
Árvores de decisão e floresta aleatória são os métodos de árvore usados no aprendizado de máquina.
Árvores de decisão são os modelos de aprendizado de máquina usados para fazer previsões, passando por cada um dos recursos do conjunto de dados, um por um.
As florestas aleatórias, por outro lado, são uma coleção de árvores de decisão agrupadas e treinadas em conjunto que usam ordens aleatórias dos recursos nos conjuntos de dados fornecidos.
Em vez de depender de apenas uma árvore de decisão, a floresta aleatória obtém a previsão de cada árvore e com base na maioria dos votos das previsões, e dá o resultado final. Em outras palavras, a floresta aleatória pode ser definida como uma coleção de múltiplas árvores de decisão.
6. Vantagens da árvore de decisão
1 É simples de implementar e segue uma estrutura do tipo fluxograma que se assemelha à tomada de decisão humana.
2 É muito útil para problemas relacionados à decisão.
3 Ajuda a encontrar todos os resultados possíveis para um determinado problema.
4 Há muito pouca necessidade de limpeza de dados em árvores de decisão em comparação com outros algoritmos de aprendizado de máquina.
5 Lida com valores numéricos e categóricos
7. Desvantagens da Árvore de Decisão
1 Muitas camadas da árvore de decisão as tornam extremamente complexas, às vezes.
2 Isso pode resultar em sobreajuste ( que pode ser resolvido usando o Algoritmo de floresta aleatória)
3 Para o maior número de rótulos de classe, a complexidade computacional da árvore de decisão aumenta.
8. Implementação de código python
#Bibliotecas numéricas de computação
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
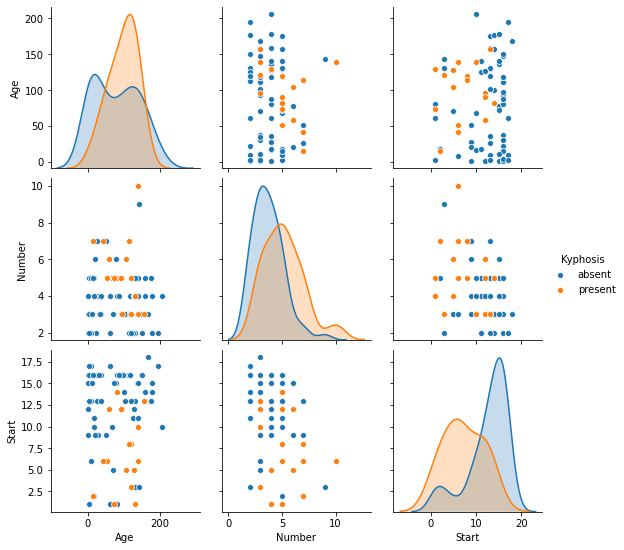
raw_data.info()
sns.pairplot(dados não tratados, matiz ="Cifose")
# Divida o conjunto de dados em dados de treinamento e dados de teste
from sklearn.model_selection import train_test_split
x = raw_data.drop('Kyphosis', eixo = 1)
y = raw_data['Kyphosis']
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, e, test_size = 0.3)
#Entrenar el modelo de árbol de decisões
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(x_training_data, y_training_data)
predictions = model.predict(x_test_data)
# Medir el rendimiento del modelo de árbol de decisões
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(classificação_report(y_test_data, previsões))
imprimir(confusão_matriz(y_test_data, previsões))
Com isso eu termino este blog. Olá a todos, Namaste Chamo-me Pranshu Sharma e eu sou um entusiasta da ciência de dados
Muito obrigado por dedicar seu valioso tempo para ler este blog.. Sinta-se à vontade para apontar quaisquer erros (depois de tudo, eu sou um aprendiz) e fornecer os comentários correspondentes ou deixar um comentário.