[*]
Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Um dos principais problemas que todos enfrentam ao tentar o streaming estruturado pela primeira vez é configurar o ambiente necessário para transmitir seus dados.. Temos alguns tutoriais online sobre como podemos configurar isso. A maioria deles se concentra em pedir que você instale uma máquina virtual e um sistema operacional ubuntu e, em seguida, configure todos os arquivos necessários alterando o arquivo bash. Isso funciona bem, mas não para todos. Uma vez que usamos uma máquina virtual, às vezes podemos ter que esperar muito tempo se tivermos máquinas com menos memória. O processo pode travar devido a problemas de atraso de memória. Então, para uma maneira melhor de fazer isso e fácil operação, Vou mostrar como podemos configurar o streaming estruturado em nosso sistema operacional Windows.
Ferramentas usadas
Para a configuração, usamos as seguintes ferramentas:
1. Kafka (para transmissão de dados, atua como produtor)
2. Funcionário do zoológico
3. Pyspark (para gerar os dados transmitidos, atua como um consumidor)
4. Notebook Jupyter (editor de código)
variáveis ambientais
É importante notar que aqui, Eu adicionei todos os arquivos na unidade C. O que mais, o nome deve ser o mesmo dos arquivos que você instala online.
Tenemos que configurar las variables de entorno a mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que instalamos estos archivos. Consulte essas imagens durante a instalação para uma experiência descomplicada.
A última imagem é o caminho das variáveis do sistema.
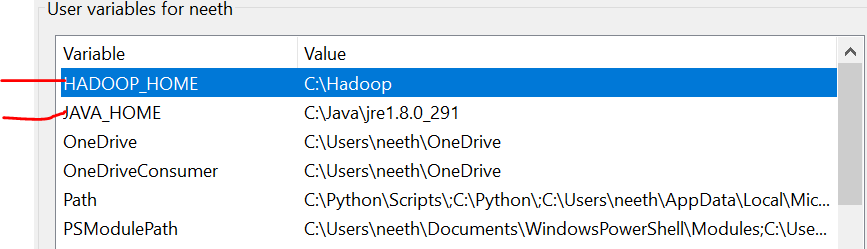
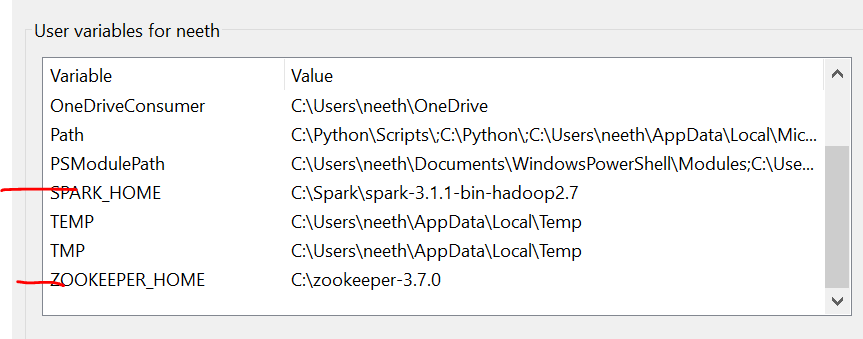
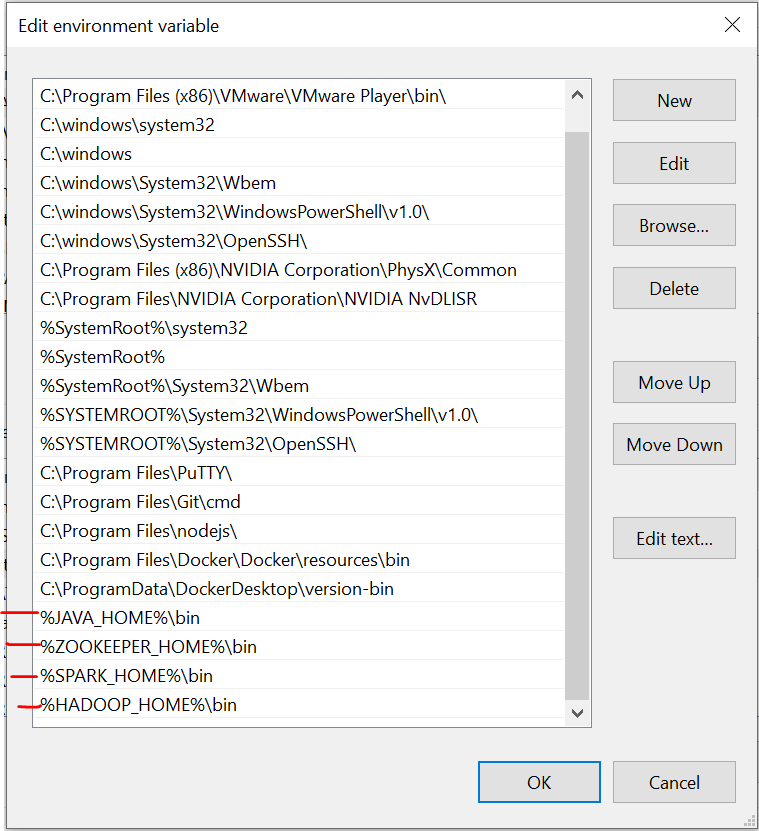
Arquivos necessários
https://drive.google.com/drive/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw?usp = compartilhamento
Instalação Kafka
O primeiro passo é instalar o Kafka em nosso sistema. Para isso temos que ir a este link:
https://dzone.com/articles/running-apache-kafka-on-windows-os
Precisamos instalar o Java 8 inicialmente e definir variáveis de ambiente. Você pode obter todas as instruções no link.
Assim que terminarmos com o Java, devemos instalar um zelador. Eu adicionei arquivos de guardiões do zoológico no Google Drive. Sinta-se livre para usá-lo ou apenas siga todas as instruções dadas no link. Si instaló zookeeper"Funcionário do zoológico" é um videogame de simulação lançado em 2001, onde os jogadores assumem o papel de um tratador. A principal missão é gerenciar e cuidar de várias espécies de animais, garantindo o seu bem-estar e a satisfação dos visitantes. Ao longo do jogo, Os usuários podem projetar e personalizar seu zoológico, enfrentando desafios, incluindo alimentos, o habitat e a saúde dos animais.... correctamente y configuró la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de entorno, você pode ver este resultado quando você executar zkserver como um administrador no prompt de comando.
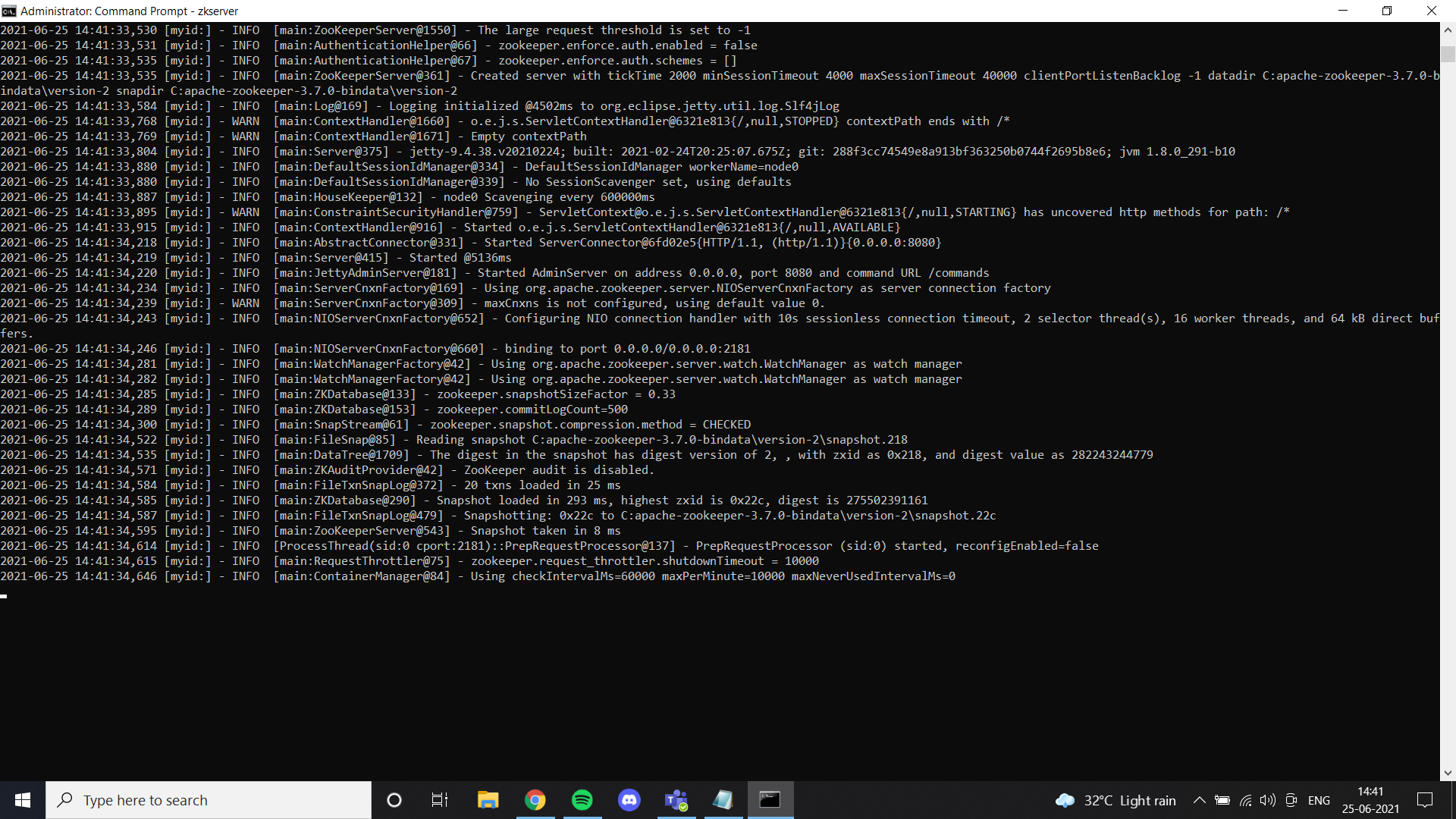
A seguir, instalar Kafka de acordo com as instruções de link e executá-lo com o comando especificado.
.binwindowskafka-server-start.bat .configserver.properties
Uma vez que tudo esteja configurado, tente criar um tema e verifique se funciona corretamente. Sim é assim, você terá completado a instalação do Kafka.
Instalação do Spark
Nesta etapa, instalamos Spark. Basicamente, você pode seguir este link para configurar o Spark em sua máquina Windows.
https://phoenixnap.com/kb/install-spark-on-windows-10
Durante uma das etapas, irá pedir para o arquivo winutils ser configurado. Para seu conforto, Eu adicionei o arquivo no link do drive que compartilhei. Em uma pasta chamada Hadoop. Basta colocar essa pasta em seu drive C e definir a variável de ambiente como mostrado nas imagens. Recomendo enfaticamente que você use o arquivo Spark que adicionei ao Google Drive. Um dos principais motivos é a transmissão de dados de que precisamos para configurar manualmente um ambiente de transmissão estruturado. No nosso caso, Eu configurei todas as coisas necessárias e modifiquei os arquivos depois de tentar muito. Caso queira fazer uma nova configuração, sinta-se livre para fazer isso. Se a configuração não funcionar corretamente, acabamos com um erro como este ao transmitir dados no pyspark:
Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;Uma vez que somos um com o Spark, agora podemos transmitir os dados necessários de um arquivo CSV em um produtor e obtê-los em um consumidor usando o tema Kafka. Eu trabalho principalmente com o notebook Júpiter e, portanto, Eu usei um notebook para este tutorial.
Em seu caderno primeiro, você deve instalar algumas bibliotecas:
1. pip instala o pyspark
2. instalador pip Kafka
3. pip install py4j
Como funciona o streaming estruturado com Pyspark?
Temos um arquivo CSV que contém dados que queremos transmitir. Vamos prosseguir com o conjunto de dados Iris clássico. Agora, se quisermos transmitir os dados da íris, devemos usar Kafka como produtor. Kafka, criamos um tópico para o qual transmitimos os dados da íris e o consumidor pode recuperar o quadro de dados deste tópico.
A seguir está o código do produtor para transmitir os dados da íris:
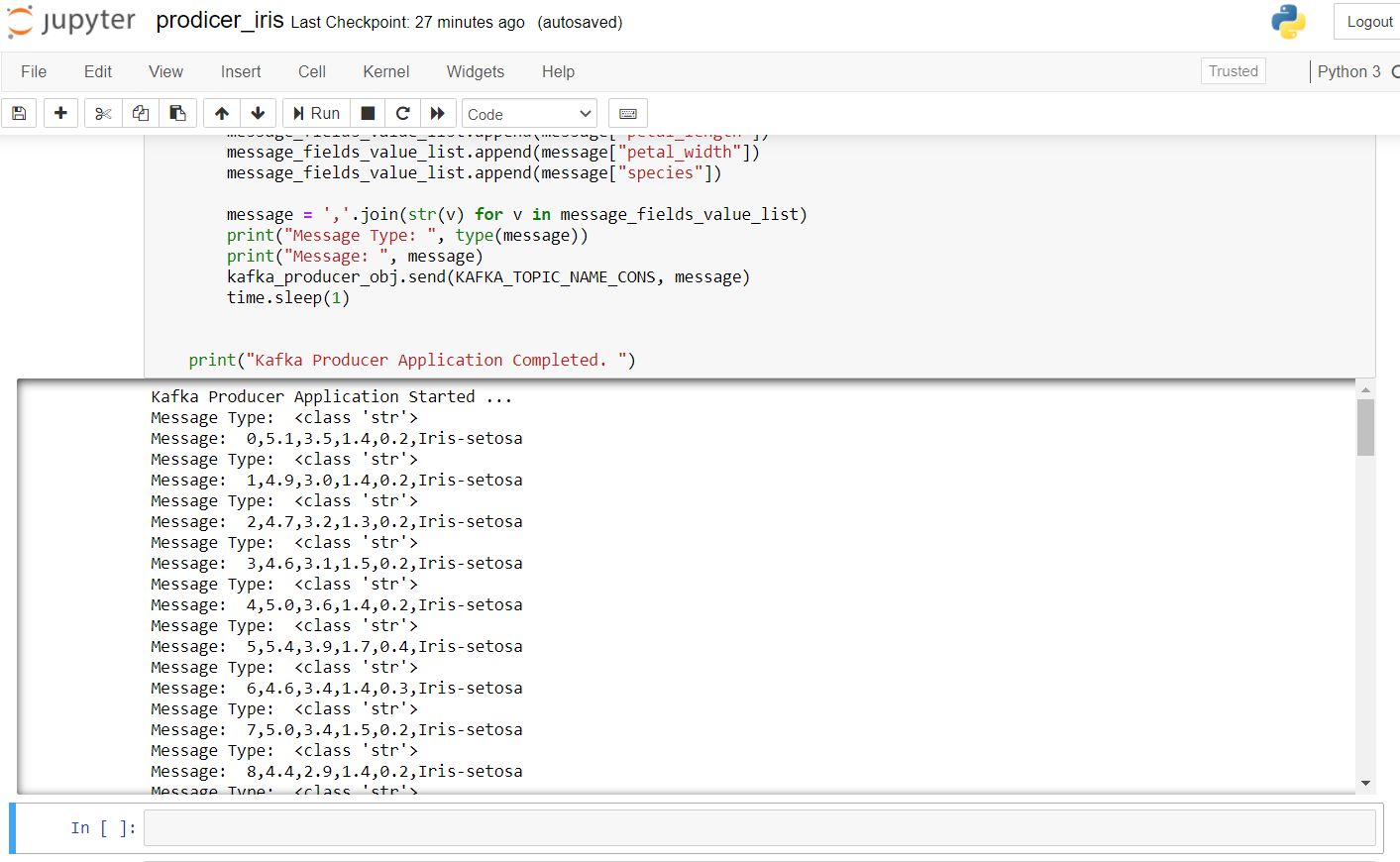
Para iniciar o produtor, temos que executar zkserver como administrador no prompt de comando do Windows e, em seguida, iniciar Kafka usando: .binwindowskafka-server-start.bat .configserver.properties from the command prompt in the Kafka directory. Se você obter um erro de “nenhum corretor”, significa que Kafka não está funcionando corretamente.
o resultado depois de executar este código no fichário jupyter se parece com este:
Agora, vamos rever o consumidor. Execute o código a seguir para ver se ele funciona bem em um novo laptop.
Una vez que ejecute esto, debería obtener un resultado como este:
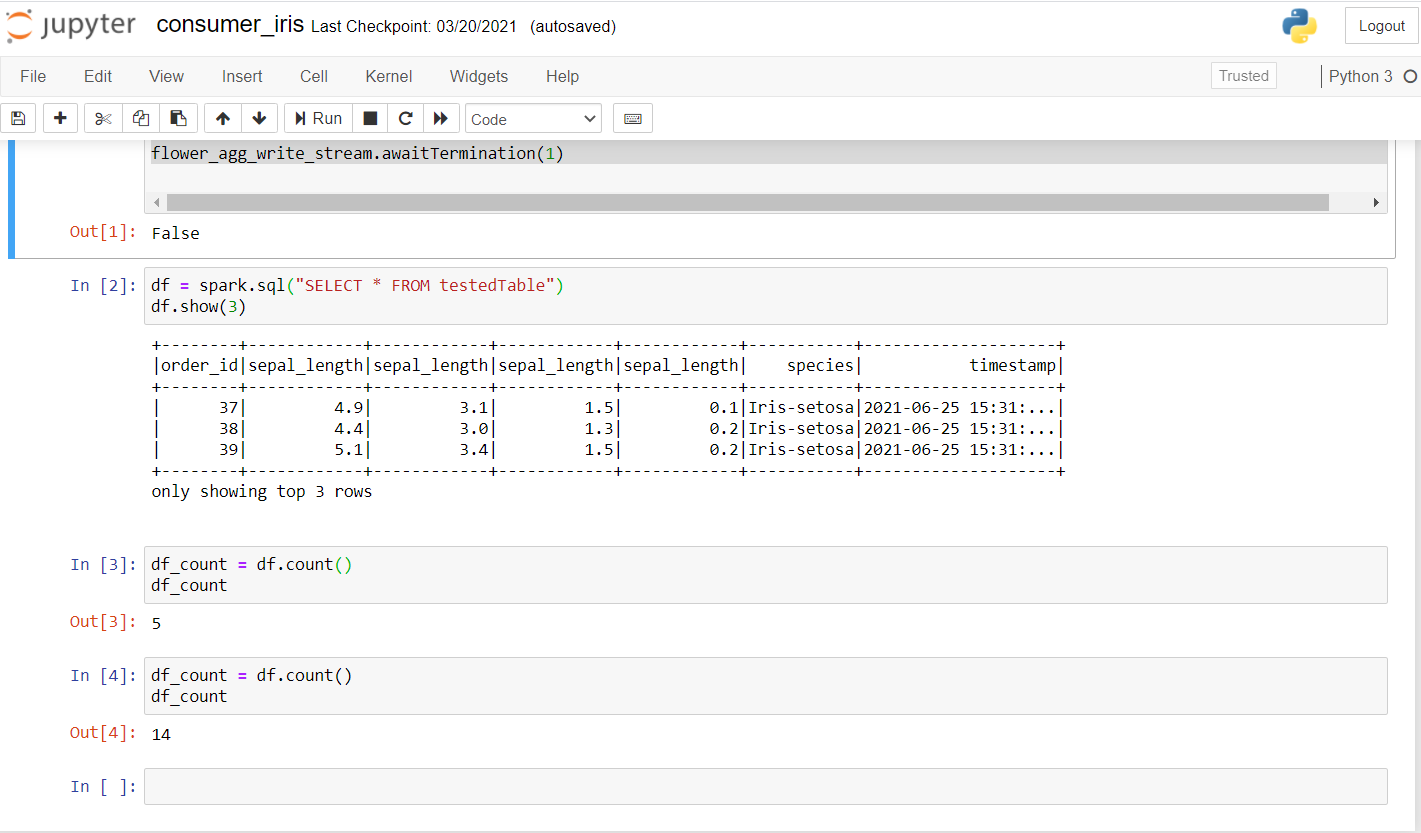
Como você pode ver, fiz algumas investigações e verificou se os dados estavam sendo transmitidos. A primeira conta foi 5 e, depois de alguns segundos, a conta aumentou para 14, confirmando que os dados estão sendo transmitidos.
Aqui, basicamente, a ideia é criar um contexto de faísca. Obtemos os dados transmitindo Kafka sobre nosso assunto na porta especificada. Se puede crear una sessãoo "Sessão" É um conceito-chave no campo da psicologia e da terapia. Refere-se a uma reunião agendada entre um terapeuta e um cliente, onde os pensamentos são explorados, Emoções e comportamentos. Essas sessões podem variar em duração e frequência, e seu principal objetivo é facilitar o crescimento pessoal e a resolução de problemas. A eficácia das sessões depende da relação entre o terapeuta e o terapeuta.. de chispa usando getOrCreate () como mostrado no código. A próxima etapa inclui a leitura do fluxo Kafka e os dados podem ser carregados usando load (). Uma vez que os dados estão sendo transmitidos, seria útil ter um carimbo de data / hora em que cada um dos registros chegou. Especificamos o esquema como fazemos em nosso SQL e, finalmente, criamos um quadro de dados com os valores dos dados transmitidos com seu carimbo de data / hora. Finalmente, com um tempo de processamento de 5 segundos, podemos receber dados em lotes. Usamos o SQL View para armazenar dados temporariamente na memória no modo anexado e podemos realizar todas as operações nele usando nosso quadro de dados Spark.
Veja o código completo aqui:
https://github.com/Siddharth1698/Structured-Streaming-Tutorial
Este é um dos meus projetos de streaming do Spark, você pode consultá-lo para consultas mais detalhadas e uso de aprendizado de máquina no Spark:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
Referências
1. https://github.com/Siddharth1698/Structured-Streaming-Tutorial
2. https://dzone.com/articles/running-apache-kafka-on-windows-os
3. https://phoenixnap.com/kb/install-spark-on-windows-10
4. https://drive.google.com/drive/u/0/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw
5. https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
6. Imagem em miniatura -> https://unsplash.com/photos/ImcUkZ72oUs
conclusão
Se você seguir essas etapas, você pode configurar facilmente todos os ambientes e executar seu primeiro programa de streaming estruturado com Spark e Kafka. Em caso de dificuldade em configurá-lo, Não hesite em contactar-me:
[e-mail protegido]
https://www.linkedin.com/in/siddharth-m-426a9614a/





