Enquanto trabalhava no problema de ajuste do aplicativo Spark, Passei um tempo considerável tentando entender as visualizações da IU da Web do Spark. Spark Web UI é uma ferramenta muito útil para esta tarefa. Para iniciantes, torna-se muito difícil obter insights sobre um problema apenas a partir dessas visualizações. Embora existam recursos muito bons sobre o desempenho do Spark, a informação foi espalhada. Portanto, Senti a necessidade de documentar e compartilhar minhas aprendizagens.
Público-alvo e conclusões
Esta postagem pressupõe que os leitores tenham uma compreensão básica dos conceitos do Spark.. Esta postagem ajudará os iniciantes a identificar possíveis problemas de desempenho em seus aplicativos executados a partir de uma IU da Web do Spark.. O foco está apenas nas informações que não são óbvias na interface do usuário e nas inferências que podem ser extraídas dessas informações não óbvias. Observe que ele não contém uma lista exaustiva de informações para interpretar a partir da interface do usuário do Spark Web, mas apenas aqueles que achei relevantes para o meu projeto e, porém, geral o suficiente para o público saber.
Interface de usuário da web do Spark
A IU da web do Spark só está disponível quando o aplicativo está em execução. Para analisar execuções anteriores, a servidor de história deve ser habilitado para armazenar logs de eventos que podem então ser usados para preencher a IU da web.
Spark Web UI exibe informações úteis sobre seu aplicativo em guias, a saber
- Executores
- Meio Ambiente
- Trabalho
- Etapas
- Armazenar
A postagem restante descreve as intuições de cada uma das guias, na ordem mencionada.
Guia de executores
Dá informações sobre as tarefas executadas por cada executor.
FIG 1: Resumo da guia do executor
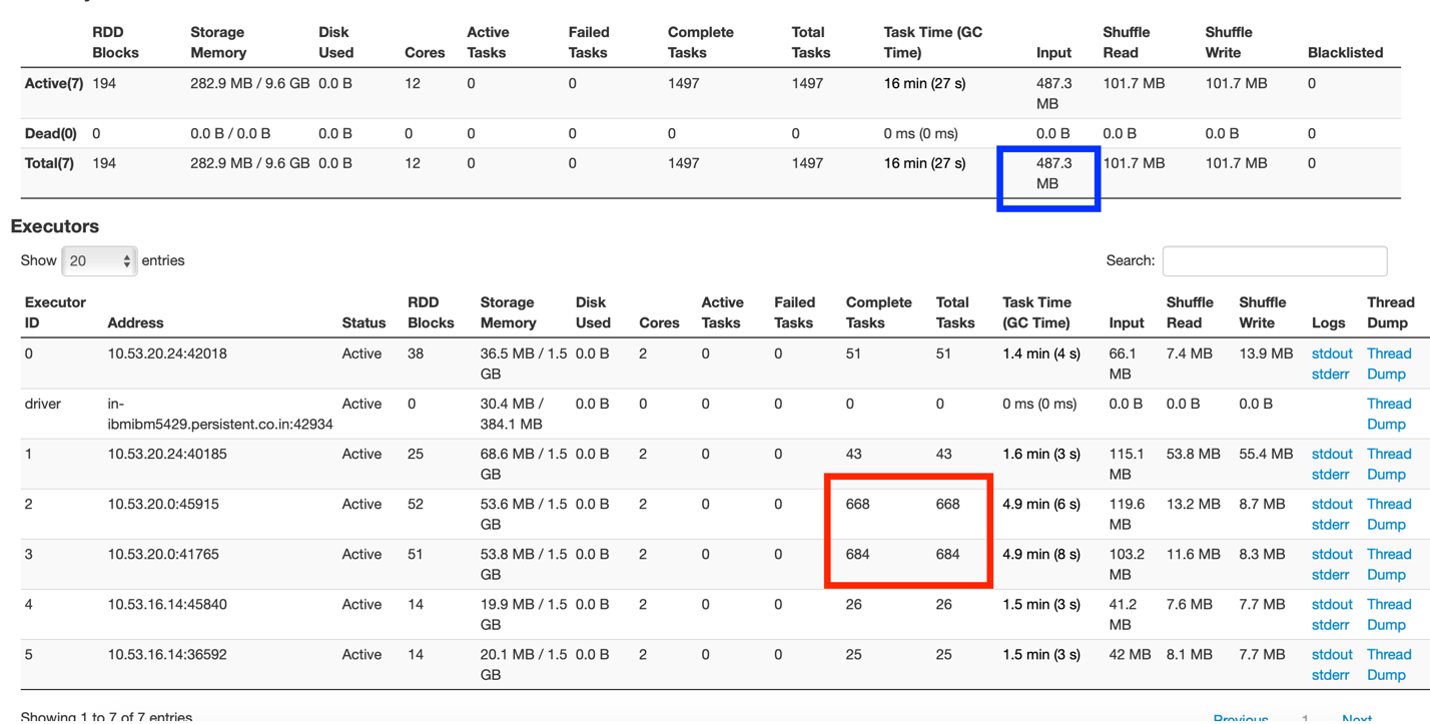
A partir de la figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... 1, pode-se entender que existe um controlador e 5 executores, cada um dos quais funciona com 2 núcleos e 3 GB de memória.
A caixa marcada em vermelho muestra la distribución desigual de las tareas en las que un nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... do cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... está exagerando las tareas, enquanto outros são relativamente inativos.
A caixa marcada em azul mostra que o tamanho dos dados de entrada foi 487,3 MB. Agora, este aplicativo foi executado em um tamanho de conjunto de dados de 83 MB. O tamanho dos dados de entrada compreende a leitura do conjunto de dados original e as transferências aleatórias de dados entre os nós. Isso mostra que muitos dados foram misturados (aproximadamente 400+ MB) no aplicativo.
Aba de ambiente
Existem muitos propriedades de faísca controlar e ajustar o aplicativo. Essas propriedades podem ser definidas ao enviar o trabalho ou ao criar o objeto de contexto. A menos que a propriedade seja explicitamente adicionada, não se aplica. Estamos errados ao supor que as propriedades são aplicadas com seus valores padrão, quando não é explicitamente declarado. Todas as propriedades aplicadas podem ser vistas na guia Ambiente. Se a propriedade não for vista lá, significa que a propriedade não foi aplicada de todo.
Aba Trabalhos
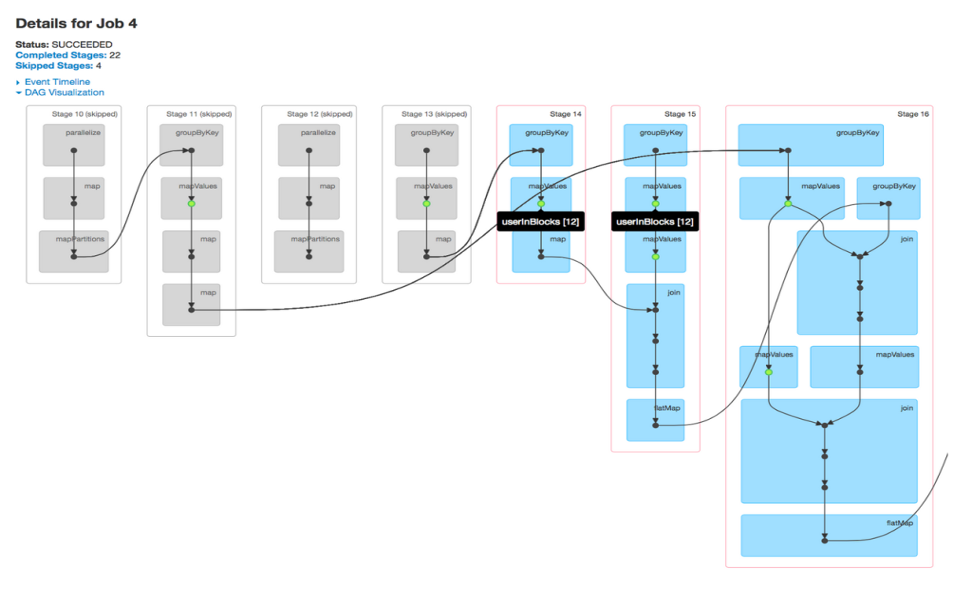
Un trabajo está asociado con una cadena de dependencias Resilient Distributed Conjunto de dadosuma "conjunto de dados" ou conjunto de dados é uma coleção estruturada de informações, que pode ser usado para análise estatística, Aprendizado de máquina ou pesquisa. Os conjuntos de dados podem incluir variáveis numéricas, categórico ou textual, e sua qualidade é crucial para resultados confiáveis. Seu uso se estende a várias disciplinas, como remédio, Economia e Ciências Sociais, facilitando a tomada de decisão informada e o desenvolvimento de modelos preditivos.... organizadas en un gráfico acíclico direto (DIA) que se parece com a Fig. 2. De visualizações DAG, você pode encontrar as etapas executadas e o número de etapas ignoradas. Por padrão, faísca não reutiliza suas etapas calculadas em estágios, a menos que seja persistido ou explicitamente armazenado em cache. Estágios ignorados são estágios em cache marcados em cinza, donde los valores de cálculo se almacenan en la memoria y no se vuelven a calcular después de acceder a HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações... Uma olhada na tela do DAG é suficiente para saber se os cálculos RDD são realizados repetidamente ou se os estágios em cache são usados.
FIG 2: Exibição DAG de um trabalho
Guia Estágios
Fornece uma visão mais profunda do aplicativo em execução no nível da tarefa. Um estágio representa um segmento de trabalho executado em paralelo por tarefas individuais. Existe um mapeamento 1-1 entre tarefas e partições de dados, quer dizer, 1 tarefa por partição de dados. Pode-se mergulhar em um trabalho, em estágios específicos e até cada tarefa em um estágio da IU da web do Spark.
O estágio fornece uma boa visão geral das execuções: DAG exibe, cronogramas de eventos, métricas resumidas / agregação de suas tarefas.
Eu prefiro olhar os cronogramas dos eventos para analisar as tarefas. Eles dão uma representação pictórica dos detalhes do tempo investido na execução do palco. Num relance, poderíamos fazer inferências rápidas sobre o quão bem o estágio foi executado e como poderíamos melhorar ainda mais o tempo de execução.
FIG 3 – Amostra da linha do tempo do evento
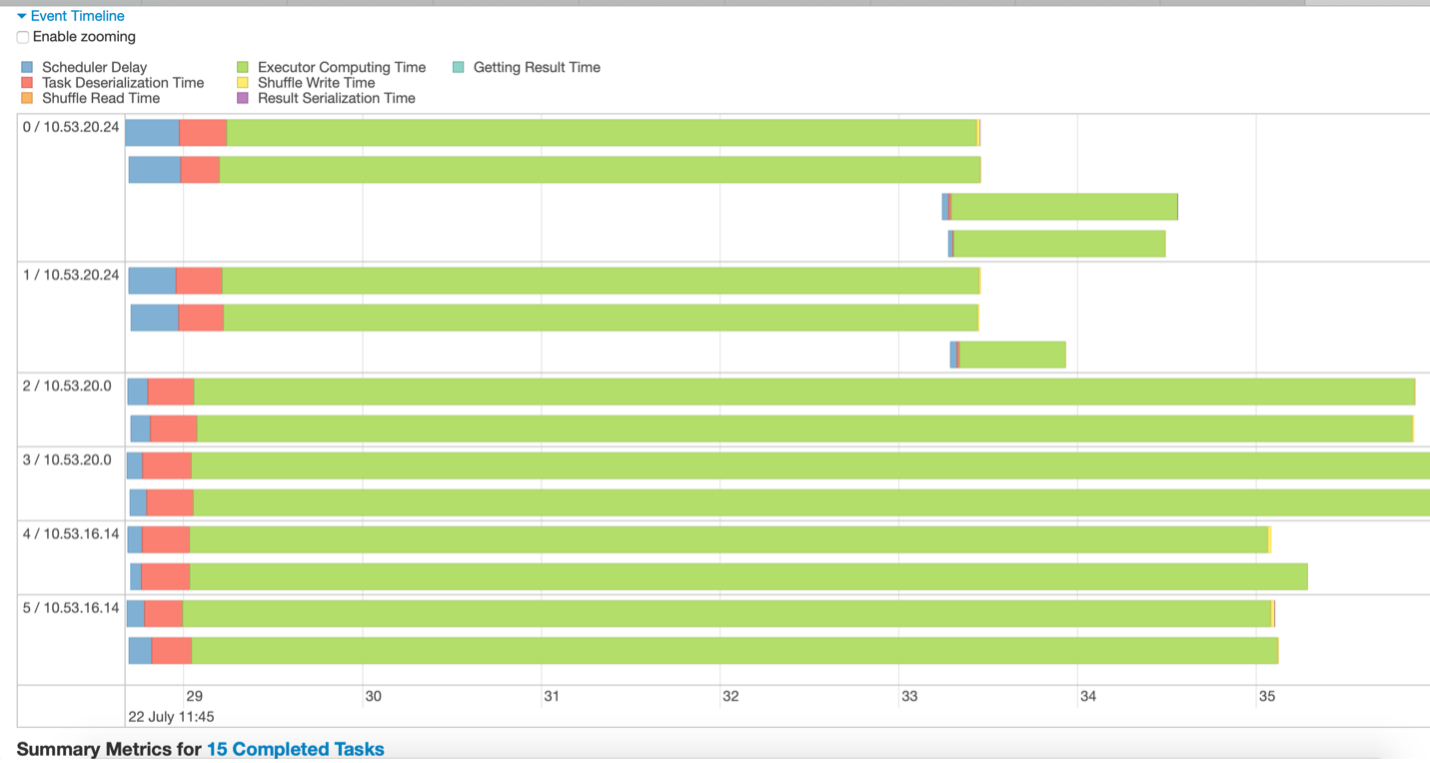
Por exemplo, as inferências tiradas da figura 3 Poderiam ser:
- Os dados são divididos em 15 partições. Portanto, Eles estão correndo 15 tarefas (representado com 15 linhas verdes).
- Tarefas executadas em 3 nós, cada um com 2 executores
- O estágio é concluído apenas quando a tarefa de execução mais longa termina. Outros executores permanecem inativos até que a tarefa mais longa seja concluída.
- Poucas tarefas de longa duração, enquanto poucas tarefas são executadas por um período muito curto, indicando que os dados não estão bem particionados.
- Não foi gasto muito tempo para atrasar o agendador ou a serialização nesta fase, qual é bom.
FIG. 4 – Linha do tempo do evento de um estágio com muitas partições de dados.
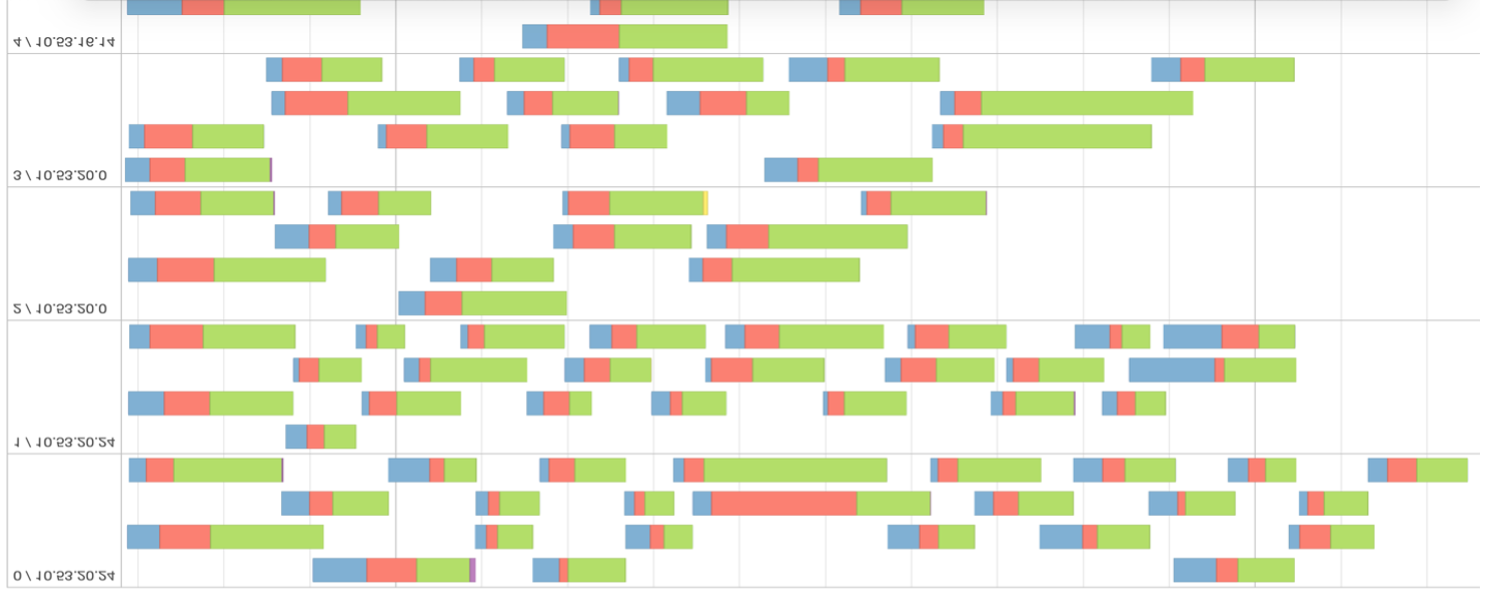
Observando a figura 4, podemos inferir que os dados não estão bem distribuídos e particionados desnecessariamente. Da métrica de avaliação, pode ser confirmado que o agendamento da tarefa demorou mais do que o tempo de execução real. Quanto maior a porcentagem de verde na linha do tempo, mais eficiente será o cálculo do estágio.
É desejável ter menos estágios no trabalho. Sempre que os dados são misturados, um novo estágio é criado. Embaralhar é caro e, portanto, tente reduzir o número de estágios de que seu programa precisa.
Tamanho dos dados de entrada
Outra informação importante é observar o tamanho da entrada dos dados que foram embaralhados. Um dos objetivos é também reduzir o tamanho desses dados aleatórios.
FIG. 5 – Visão geral da guia Estágios.
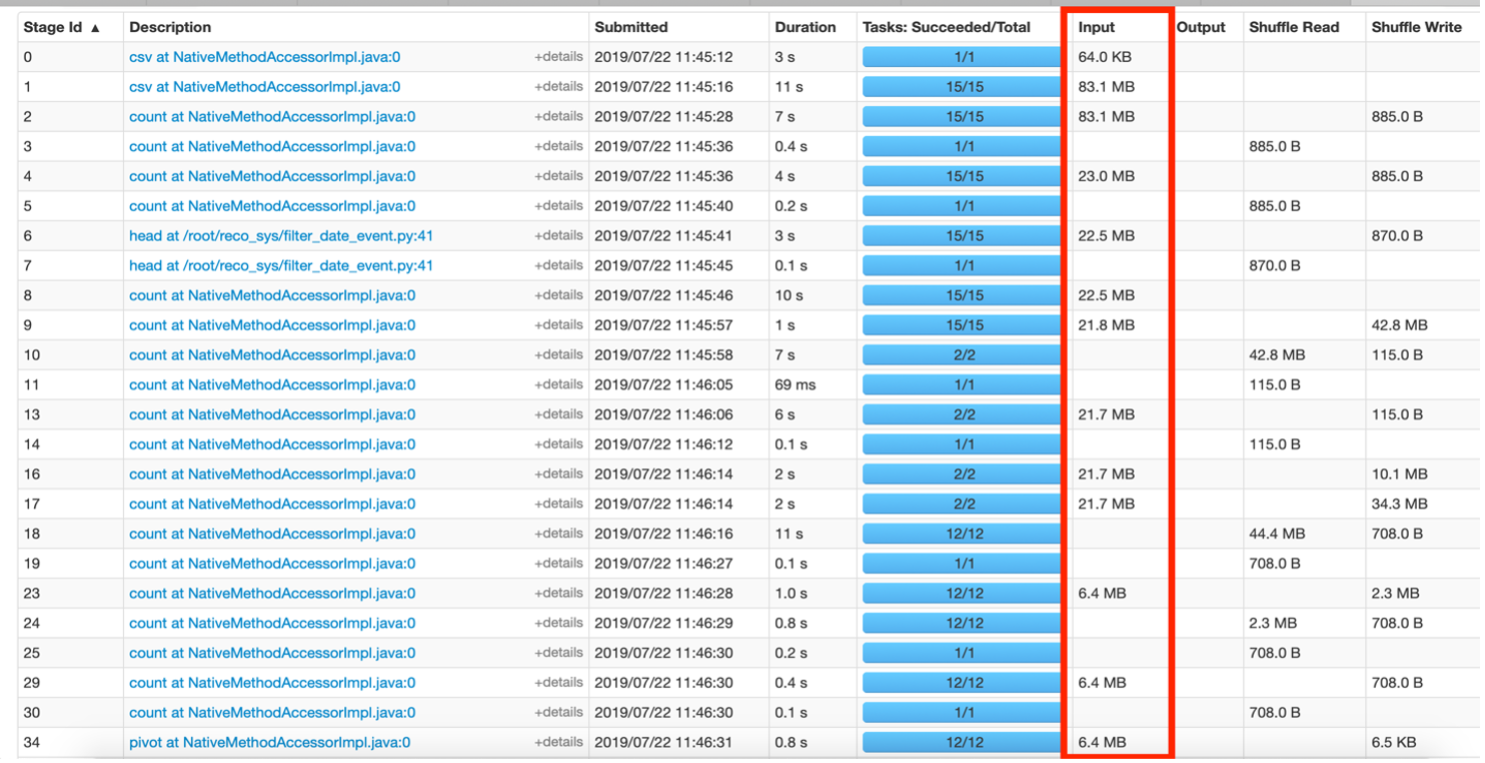
A figura 5 acima mostra os estágios em que os dados se movem em MB. Isso sugere que o código pode ser melhorado para reduzir o tamanho dos dados que foram trocados entre os estágios. Por exemplo, Digamos que se um filtro foi aplicado em alguns dados para um evento 'x’ dados, então no RDD resultante, a coluna "evento" torna-se redundante, pois tecnicamente todas as linhas são do evento 'x'. Esta coluna pode ser removida de futuros RDDs criados a partir desses dados filtrados para salvar informações adicionais transferidas durante as operações de embaralhamento.
Símboloo "Símbolo" É um termo usado em vários contextos, geralmente para se referir a um documento ou cartão que contém informações específicas sobre um tópico, pessoa ou produto. Em ambientes acadêmicos, É usado para registrar dados relevantes sobre pesquisas ou fontes bibliográficas. No ambiente empresarial, Os cartões podem ser ferramentas úteis para organizar dados de clientes ou produtos, facilitando a gestão e o acesso à informação.... de almacenamiento
Mostra apenas RDDs que foram preservados, quer dizer, que usam persistir () o esconder (). Para torná-lo mais legível, você pode nomear o RDD enquanto o armazena usando setName (). Apenas os RDDs que você deseja manter devem ser exibidos na guia Armazenamento e podem ser facilmente reconhecíveis com os nomes personalizados fornecidos.
Resumo
Este artigo ajuda a fornecer informações para identificar problemas de interface do usuário da web do Spark, como o tamanho dos dados que foram embaralhados, o tempo de execução das etapas, Recálculo de RDD devido à falta de cache. Se alguém entende seus dados e sua aplicação, então, a distribuição de dados ideal e o número desejado de partições podem ser medidos inferindo a partir da IU em execução. A sobrecarga de um nó em relação a outros no cluster é outra área de melhoria que pode ser vista nesta interface de usuário. o resoluçãoo "resolução" refere-se à capacidade de tomar decisões firmes e atingir metas estabelecidas. Em contextos pessoais e profissionais, Envolve a definição de metas claras e o desenvolvimento de um plano de ação para alcançá-las. A resolução é fundamental para o crescimento pessoal e o sucesso em várias áreas da vida, pois permite superar obstáculos e manter o foco no que realmente importa.... de algunos de estos problemas se discute más en el Artigo de ajuste de desempenho do Apache Spark.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





