Na última postagem (Clique aqui), falamos brevemente sobre os fundamentos da técnica de RNA. Mas antes de usar a técnica, um analista deve saber, Como a técnica realmente funciona? Mesmo quando a referência detalhada não é necessária, a estrutura do algoritmo deve ser conhecida. Este conhecimento serve a vários propósitos:
- Em primeiro lugar, nos ajuda a entender o impacto de aumentar / encolher o conjunto de dados vertical ou horizontalmente em tempo computacional.
- Em segundo lugar, nos ajuda a entender as situações ou casos em que o modelo se encaixa melhor.
- Em terceiro lugar, Também nos ajuda a explicar por que um determinado modelo funciona melhor em determinados ambientes ou situações..
Este post fornecerá uma compreensão básica da estrutura do neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. artificial (ANN). Não vamos entrar no desvio real, mas as informações fornecidas neste post serão suficientes para você apreciar e colocar o algoritmo em prática. No final da postagem, além disso, apresentarei minhas opiniões sobre os três objetivos básicos de compreensão de qualquer algoritmo mencionado anteriormente.
Formulação de rede neural
Começaremos entendendo a formulação de uma rede neural de camada oculta simples. Uma rede neural simples pode ser representada conforme mostrado a seguir figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas....:
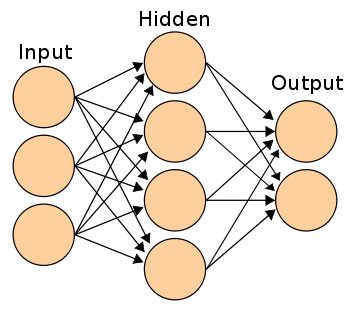
Links entre nós são os achados mais cruciais em uma RNA. Voltaremos a "como encontrar o peso de cada link" depois de discutir a estrutura geral. Os únicos valores conhecidos no diagrama acima são as entradas. Vamos chamar as entradas de I1, I2 e I3, estados ocultos como H1, H2.H3 e H4, saídas como O1 e O2. Pesos de link podem ser denotados com a seguinte notação:
C (I1H1) é o peso do link entre os nós I1 e H1.
Abaixo está a estrutura na qual as redes neurais artificiais funcionam (ANN):

Poucos detalhes estatísticos sobre a estrutura
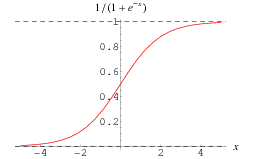
Cada cálculo de ligação em uma rede neural artificial (ANN) é equivalente. Em geral, assumimos uma ligação sigmóide entre as variáveis de entrada e a taxa de ativação dos nós ocultos ou entre os nós ocultos e a taxa de ativação dos nós de saída. Vamos preparar a equação para encontrar a taxa de ativação de H1.
Logit (H1) = W (I1H1) * I1 + C (I2H1) * I2 + C (I3H1) * I3 + Constante = f
=> P (H1) = 1 / (1 + e ^ (- f))
Aqui está a aparência da ligação sigmóide:
Como os pesos são recalibrados? Uma pequena nota
Recalibrar pesos é um procedimento fácil, mas longo. Os únicos nós onde sabemos a taxa de erro são os nós de saída. A recalibração de pesos na ligação entre o nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... oculto e o nó de saída é uma função dessa taxa de erro nos nós de saída. Mas, Como encontramos a taxa de erro em nós ocultos? Pode ser estatisticamente mostrado que:
Erro @ H1 = W (H1O1) *[e-mail protegido] + C (H1O2) *[e-mail protegido]
Usando esses erros, podemos recalibrar os pesos dos links entre os nós ocultos e os nós de entrada de forma equivalente. Imagine que esse cálculo é realizado várias vezes para cada uma das observações no conjunto de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.....
As três questões básicas
Qual é a correlação entre o tempo consumido pelo algoritmo e o volume de dados (em comparação com modelos tradicionais, como logística)?
como dito anteriormente, para cada observação, ANN realiza múltiplas recalibrações para cada peso de link. Por isso, o tempo gasto pelo algoritmo aumenta muito mais rápido do que outros algoritmos tradicionais para o mesmo aumento no volume de dados.
Em qual situação o algoritmo se ajusta melhor?
ANN é raramente usado para modelagem preditiva. A razão é que as Redes Neurais Artificiais (ANN) eles geralmente tentam encaixar demais na ligação. A RNA é geralmente usada em casos onde o que aconteceu no passado é repetido quase exatamente da mesma maneira. Como um exemplo, digamos que estejamos jogando black jack contra um computador. Um oponente inteligente baseado em ANN seria um oponente muito bom para este caso (assumindo que eles podem manter o tempo de computação baixo). Com o tempo, ANN irá se preparar para todos os casos de fluxo de cartão possíveis. E uma vez que não estamos embaralhando cartas com um dealer, ANN será capaz de memorizar cada chamada. Por isso, é um tipo de técnica de aprendizado de máquina que tem uma grande memória. Mas não funciona bem no caso de a população de pontuação ser significativamente diferente em comparação com a amostra de treinamento. Como um exemplo, se eu planejo atingir um cliente para uma campanha usando sua resposta anterior de um ANN. Provavelmente usarei a técnica errada, já que você pode ter super ajustado a ligação entre a solução e outros preditores.
Pela mesma razão, funciona muito bem em casos de credenciamento de imagem e credenciamento de voz.
O que torna a ANN um modelo muito forte quando se trata de memorização?
Redes neurais artificiais (ANN) tem muitos coeficientes diferentes, que você pode aproveitar ao máximo. Por isso, pode lidar com muito mais variabilidade em comparação com os modelos tradicionais.
A postagem foi útil para você? Você usou alguma outra ferramenta de aprendizado de máquina recentemente? Você está planejando usar ANN em algum dos seus problemas de negócios?? Se então, diga-nos como você planeja fazer isso.





