Este artigo foi publicado como parte do Data Science Blogathon
Introdução
máquina. É inspirado no funcionamento de um cérebro humano e, portanto, é um conjunto de algoritmos de rede neural que tenta imitar o funcionamento do cérebro humano e aprender com as experiências.
Neste artigo, vamos aprender como funciona uma rede neural básica e como ela se aprimora para fazer as melhores previsões.
Tabela de conteúdos
- Redes neurais e seus componentes
- Perceptron e perceptron multicamadas
- Trabalho passo a passo da rede neural
- Propagação de retorno e como funciona
- Resumo sobre as funções de ativação
Redes neurais artificiais e seus componentes
Redes neurais é um sistema de aprendizagem computacional que usa uma rede de funções para entender e traduzir uma entrada de dados de uma forma em uma saída desejada, normalmente em outra forma. O conceito de rede neural artificial foi inspirado na biologia humana e na forma como neurônios do cérebro humano trabalham juntos para entender as entradas dos sentidos humanos.
Em palavras simples, redes neurais são um conjunto de algoritmos que tentam reconhecer padrões, relações de dados e informações através do processo que é inspirado e funciona como o cérebro / biologia humana.
Componentes (editar) / Arquitetura de rede neural
Uma rede neural simples consiste em três componentes :
- Camada de entrada
- Manto oculto
- Camada de saída

Fonte: Wikipedia
Camada de entrada: Também conhecido como nós de entrada, são as entradas / informações do mundo externo que são fornecidas ao modelo para aprender e tirar conclusões. Os nós de entrada passam as informações para a próxima camada, quer dizer, camada escondida.
Manto oculto: A camada oculta é o conjunto de neurônios onde todos os cálculos são realizados nos dados de entrada. Pode haver qualquer número de camadas ocultas em uma rede neural. A rede mais simples consiste em uma única camada oculta.
Camada de saída: A camada de saída é a saída / conclusões do modelo derivadas de todos os cálculos realizados. Pode haver um ou mais nós na camada de saída. Se tivermos um problema de classificação binária, o nó de saída é 1, mas no caso de classificação de múltiplas classes, nós de saída podem ser mais do que 1.
Perceptron e perceptron multicamadas
Perceptron é uma forma simples de rede neural e consiste em uma única camada onde todos os cálculos matemáticos são realizados.
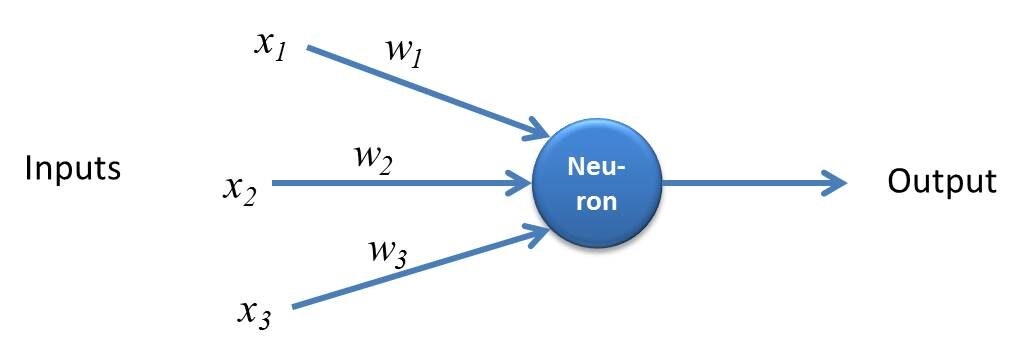
Fonte: kindonthegenius.com
Enquanto que, Perceptron Multicamadas também conhecido como Redes neurais artificiais Consiste em mais de uma percepção que é agrupada para formar uma rede neural de várias camadas.
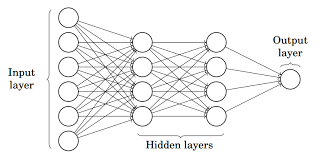
Fonte: Metade
Na foto acima, a rede neural artificial consiste em quatro camadas interconectadas:
- Uma camada de entrada, com 6 nós de entrada.
- Capa 1 escondido, com 4 nós ocultos / 4 perceptrons
- Manto oculto 2, com 4 nós ocultos
- Camada de saída com 1 nó de saída
Passo a passo Working de la red neuronal artificial
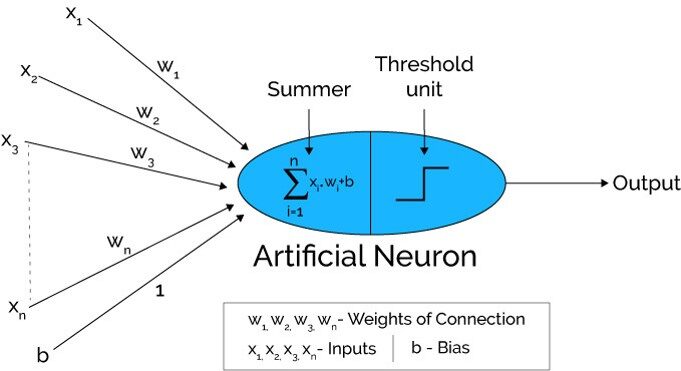
Fonte: Xenonstack.com
-
Na primeira etapa As unidades de entrada são passadas, quer dizer, os dados são passados com alguns pesos anexados à camada oculta.. Podemos ter qualquer número de camadas ocultas. Na foto acima, as entradas x1,X2,X3,… .XNorte passou.
-
Cada camada oculta consiste em neurônios. Todas as entradas estão conectadas a cada neurônio.
-
Depois de transmitir os ingressos, todos os cálculos são feitos na camada oculta (Oval azul na imagem)
O cálculo realizado em camadas ocultas é realizado em duas etapas que são as seguintes :
-
Em primeiro lugar, todas as entradas são multiplicadas por seus pesos. O peso é o gradiente ou coeficiente de cada variável. Mostra a força da entrada particular. Depois de atribuir os pesos, uma variável de polarização é adicionada. Tendência é uma constante que ajuda o modelo a se encaixar da melhor maneira possível.
COM1 = W1*Sobre1 + C2*Sobre2 + C3*Sobre3 + C4*Sobre4 + C5*Sobre5 + b
C1, C2, C3, C4, W5 são os pesos atribuídos às entradas de entrada1, Sobre2, Sobre3, Sobre4, Sobre5, e b é o viés.
- Mais tarde, na segunda etapa, a A função de ativação é aplicada à equação linear Z1. A função de ativação é uma transformação não linear que é aplicada à entrada antes de enviá-la para a próxima camada de neurônios. A importância da função de ativação é incutir não linearidade no modelo.
Existem várias funções de ativação que serão listadas na próxima seção.
-
Todo o processo descrito no ponto 3 realizado em cada camada oculta. Depois de passar por todas as camadas ocultas, nós vamos para a última camada, quer dizer, nossa camada de saída que nos dá a saída final.
O processo explicado acima é conhecido como propagação direta.
-
Depois de obter as previsões da camada de saída, o erro é calculado, quer dizer, a diferença entre a produção real e esperada.
Se o erro for grande, então, medidas são tomadas para minimizar o erro e com o mesmo propósito, A propagação para trás é realizada.
O que é propagação para trás e como funciona?
A propagação reversa é o processo de atualizar e encontrar os valores ideais de pesos ou coeficientes que ajuda o modelo a minimizar o erro, quer dizer, a diferença entre os valores reais e previstos.
Mas aqui está a questão: Como os pesos são atualizados e os novos pesos calculados??
Pesos são atualizados com a ajuda de otimizadores.. Otimizadores são os métodos / formulações matemáticas para mudar os atributos das redes neurais, quer dizer, os pesos para minimizar o erro.
Propagação para trás inclinada para baixo
Gradient Descent é um dos otimizadores que ajuda a calcular os novos pesos. Vamos entender passo a passo como o Gradient Descent otimiza a função de custo.
Na imagem abaixo, a curva é nossa curva de função de custo e nosso objetivo é minimizar o erro de tal forma que Jmin quer dizer, mínimos globais são alcançados.
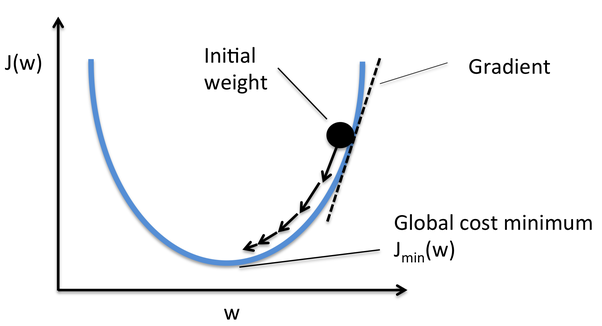
Fonte: Quora
Passos para alcançar mínimos globais:
-
Primeiro, pesos são inicializados aleatoriamente quer dizer, o valor aleatório do peso e as interseções são atribuídos ao modelo enquanto a propagação direta e erros são calculados depois de todo o cálculo. (Como discutido acima)
-
Então o o gradiente é calculado, quer dizer, derivado de erro com pesos atuais
-
Mais tarde, os novos pesos são calculados usando a seguinte fórmula, Onde a é a taxa de aprendizagem que é o parâmetro também conhecido como tamanho da etapa para controlar a velocidade ou etapas da propagação de retorno. Fornece controle adicional sobre a velocidade com que queremos nos mover ao redor da curva para atingir mínimos globais.
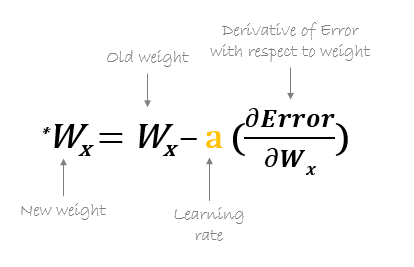
Fonte: hmkcode.com
4.Este processo de cálculo dos novos pesos, então os erros dos novos pesos e então a atualização dos pesos. continua até atingirmos as mínimas globais e a perda ser minimizada.
Um ponto a ter em mente aqui é que a taxa de aprendizagem, quer dizer, em nossa atualização de peso A equação deve ser escolhida com sabedoria. A taxa de aprendizagem é a quantidade de mudança ou o tamanho do passo dado para alcançar os mínimos globais. Não deve ser muito pequeno uma vez que vai demorar para convergir, assim como não deve ser muito grande que não atinge os mínimos globais em tudo. Por tanto, a taxa de aprendizagem é o hiperparâmetro que devemos escolher com base no modelo.
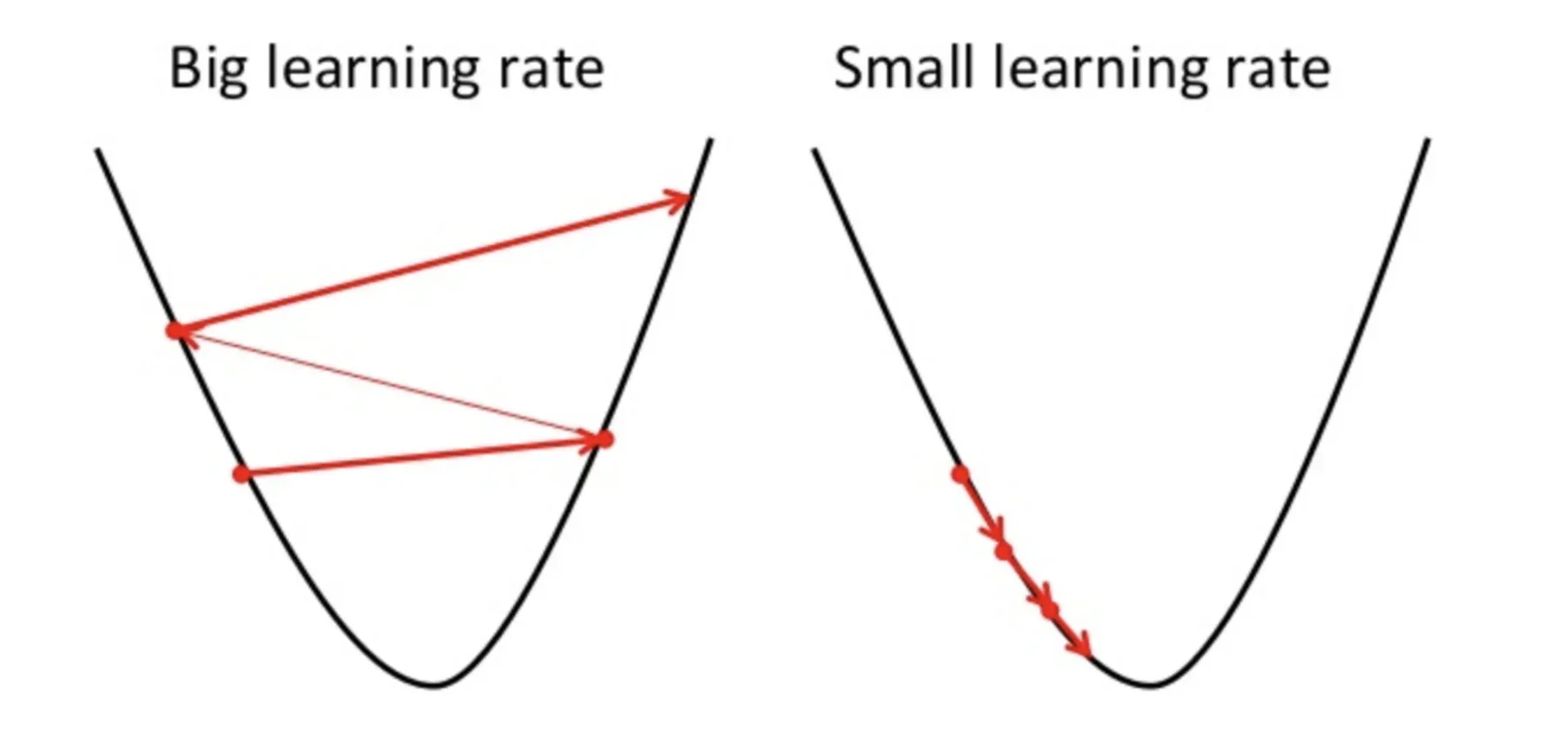
Fonte: Educative.io
Para saber a matemática detalhada e a regra da cadeia de retropropagação, ver anexo tutorial.
Resumo sobre as funções de ativação
Funções de gatilho são anexados a cada neurônio e são equações matemáticas que determinam se um neurônio deve disparar ou não com base em se a entrada do neurônio é relevante para a previsão do modelo ou não. O objetivo da função de ativação é introduzir não linearidade nos dados.
Vários tipos de funções de gatilho são:
- Função de ativação sigmóide
- Função de ativação TanH / Tangente hiperbólica
- Função de unidade linear retificada (retomar)
- Leaky ReLU
- Softmax
Confira este blog para uma explicação detalhada das funções de ativação.
Notas finais
Aqui eu concluo minha explicação passo a passo da primeira Rede Neural de Aprendizado Profundo que é ANA. Tentei explicar o processo de Propagation Forwarding e Backpropagation da maneira mais simples possível. Espero que valha a pena ler este artigo 🙂
Por favor, sinta-se à vontade para se conectar comigo no LinkedIn e compartilhe sua valiosa contribuição. Por favor, verifique meus outros artigos aqui.
Sobre o autor
Soy Deepanshi Dhingra, Atualmente trabalho como pesquisador de ciência de dados e tenho formação em análise, Análise exploratória de dados, aprendizado de máquina e aprendizado profundo.
A mídia mostrada neste artigo sobre a rede neural artificial não é propriedade da DataPeaker e é usada a critério do autor.





