Em Machine Learning, Usamos vários tipos de algoritmos para permitir que as máquinas aprendam as relações dentro dos dados fornecidos e façam previsões baseadas em padrões ou regras identificadas no conjunto de dados.. Então, Regressão é uma técnica de aprendizado de máquina onde o modelo prevê a produção como um valor numérico contínuo.
Fonte: https://www.hindish.com
A análise de regressão é frequentemente usada nas finanças, investimentos e outros, e descobrir a relação entre um único variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... dependente (variável alvo) que depende de vários independentes. Por exemplo, Prever o preço da habitação, o mercado de ações ou o salário de um funcionário, etc.são os mais comuns
problemas de regressão.
Os algoritmos que vamos cobrir são:
1. Regressão linear
2. Árvore de decisão
3. Suporte à regressão vetorial
4. Regressão de loop
5. Floresta aleatória
1. Regressão linear
A regressão linear é um algoritmo de aprendizado de máquina usado para o aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em.... A regressão linear realiza a tarefa de prever uma variável dependente (objetivo) dependendo das variáveis independentes dadas. Então, Esta técnica de regressão encontra uma relação linear entre uma variável dependente e as outras variáveis independentes.. Portanto, o nome deste algoritmo é Regressão Linear.
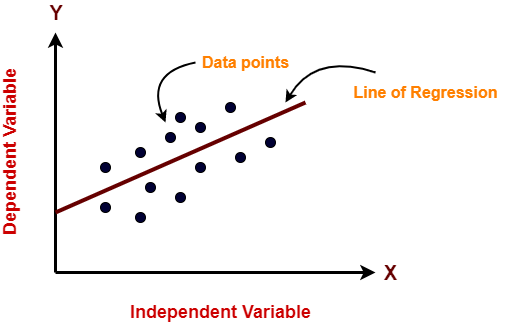
No figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... anterior, no eixo X é a variável independente e no eixo y é a saída. A linha de regressão é a linha que melhor se encaixa em um modelo. E nosso principal objetivo neste algoritmo é encontrar a linha que melhor se encaixa..
Prós:
- Regressão linear é simples de implementar.
- Menos complexidade em comparação com outros algoritmos.
- Regressão linear pode causar superequiptação, Mas pode ser evitado usando algumas técnicas de redução de dimensionalidade, Técnicas regularizaçãoA regularização é um processo administrativo que busca formalizar a situação de pessoas ou entidades que atuam fora do marco legal. Esse procedimento é essencial para garantir direitos e deveres, bem como promover a inclusão social e econômica. Em muitos países, A regularização é aplicada em contextos migratórios, Trabalhista e Tributário, permitindo que aqueles que estão em situação irregular tenham acesso a benefícios e se protejam de possíveis sanções.... e validação cruzada.
Contras:
- Outliers afetam severamente este algoritmo.
- Simplifica demais os problemas do mundo real ao assumir uma relação linear entre variáveis, por isso não recomendado para casos de uso prático.
Implementação
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[2, 1], [3, 2], [4, 2], [5, 3]])
# y = 1 * x_0 + 2 * x_1 + 3
y = np.dot(X, np.array([1, 2])) + 3
lr = LinearRegression().ajuste(X, e)
Lr.predict(np.array([[1, 5]]))
Saída
variedade([14.])
2. Árvore de decisão
Modelos de árvore de decisão podem ser aplicados a todos os dados que contenham características numéricas e características categóricas. As árvores de decisão são boas para capturar a interação não linear entre características e a variável alvo. As árvores de decisão coincidem de alguma forma com o pensamento no nível humano, por isso é muito intuitivo entender os dados.
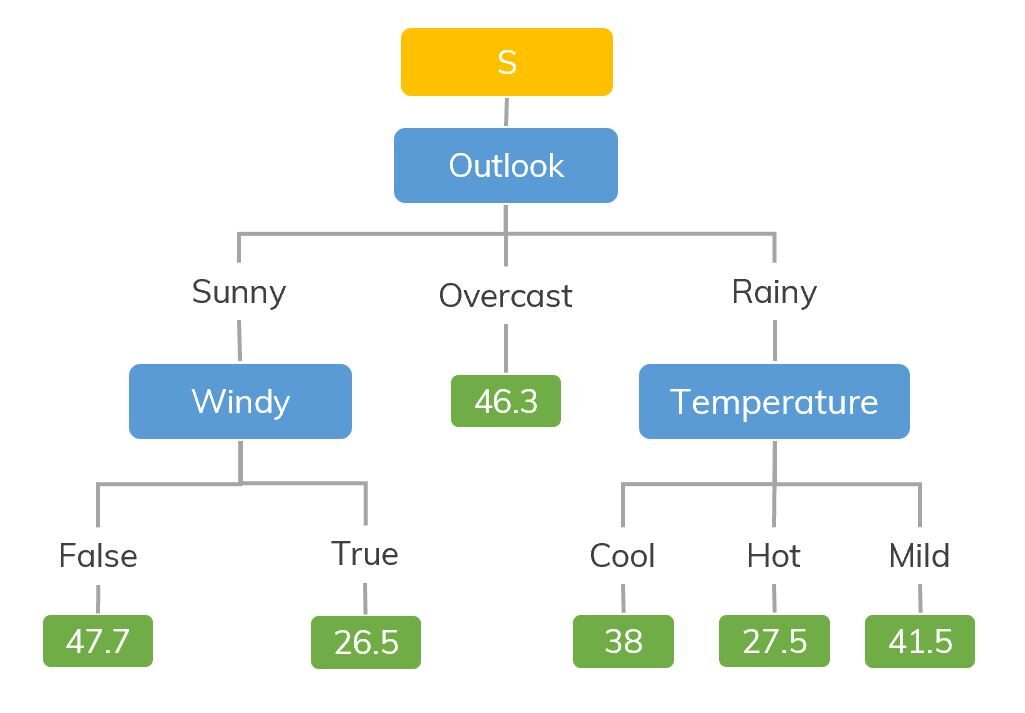
Fonte: https://dinhanhthi.com
Por exemplo, Se estamos resolvendo quantas horas uma criança joga em um clima particular, A árvore de decisão se parece um pouco com isso na foto.
Então, em resumo, Uma árvore de decisão é uma árvore em que cada nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... representa uma característica, Cada ramo representa uma decisão e cada folha representa um resultado (valor numérico para regressão).
Prós:
- Fácil de entender e interpretar, Visualmente intuitivo.
- Pode trabalhar com características numéricas e categóricas.
- Requer pouco processamento pré-dados: Não há necessidade de codificação one-hot, variáveis falsas, etc.
Contras:
- Tende a se curvar demais.
- Uma pequena mudança nos dados tende a fazer uma grande diferença na estrutura da árvore., o que causa instabilidade.
Implementação
import numpy as np from sklearn.tree import DecisionTreeRegressor rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), eixo = 0) y = np.sin(X).Ravel() e[::5] += 3 * (0.5 - rng.rand(16)) # Fit regression model regr = DecisionTreeRegressor(max_depth=2) regr.fit(X, e) # Predict X_test = np.arange(0.0, 5.0, 1)[:, por exemplo, newaxis] resultado = regr.predict(X_test) imprimir(resultado) Saída: [ 0.05236068 0.71382568 0.71382568 0.71382568 -0.86864256]
3. Suporte à regressão vetorial
Você deve ter ouvido falar de SVM, quer dizer, Máquina de vetores de suporte. SVR também usa a mesma ideia de SVM, mas aqui ele tenta prever os valores reais. Este algoritmo usa hiperplanos para segregar dados. Caso essa separação não seja possível, em seguida, use o truque do kernel em que o dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e... aumenta e, em seguida, os pontos de dados se tornam separáveis por um hiperplano.
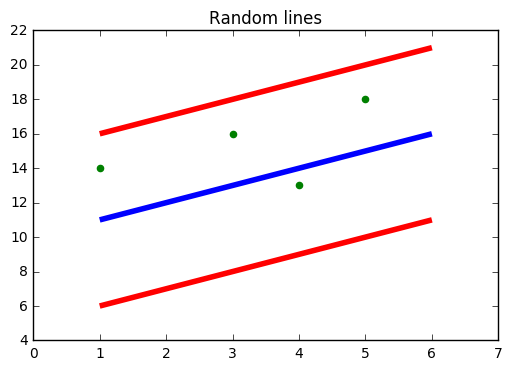
Fonte: https://www.medium.com
Na figura acima, A Linha Azul é o Hiperplano; A linha vermelha é a linha de fronteira
Todos os pontos de dados estão dentro da linha de fronteira (Linha Vermelha). O principal objetivo do SVR é basicamente considerar os pontos que estão dentro da linha de fronteira..
Prós:
- Robusto para outliers.
- Excelente generalizabilidade
- Alta precisão de previsão.
Contras:
- Não é adequado para grandes conjuntos de dados.
- Eles não funcionam muito bem quando o conjunto de dados tem mais ruído.
Implementação
from sklearn.svm import SVR import numpy as np rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), eixo = 0) y = np.sin(X).Ravel() e[::5] += 3 * (0.5 - rng.rand(16)) # Fit regression model svr = SVR().ajuste(X, e) # Predict X_test = np.arange(0.0, 5.0, 1)[:, por exemplo, newaxis] svr.predict(X_test)
Saída: variedade([-0.07840308, 0.78077042, 0.81326895, 0.08638149, -0.6928019 ])
4. Regressão de loop
- LASSO significa Operador de Contração de Seleção Mínima Absoluta. A contração é basicamente definida como uma restrição de atributo ou parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.....
- O algoritmo funciona encontrando e aplicando uma restrição aos atributos do modelo que fazem com que os coeficientes de regressão de algumas variáveis sejam reduzidos a zero..
- Variáveis com coeficiente de regressão de zero são excluídas do modelo.
- Portanto, A análise de regressão de loop é basicamente um método de seleção variável e contração e ajuda a determinar quais dos preditores são mais importantes..
Prós:
Contras:
- O LASSO selecionará apenas um recurso de um grupo de recursos mapeados
- Os recursos selecionados podem ser fortemente tendenciosos.
Implementação
from sklearn import linear_model import numpy as np rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), eixo = 0) y = np.sin(X).Ravel() e[::5] += 3 * (0.5 - rng.rand(16)) # Fit regression model lassoReg = linear_model.Lasso(alfa=0,1) lassoReg.fit(X,e) # Predict X_test = np.arange(0.0, 5.0, 1)[:, por exemplo, newaxis] lassoReg.prever(X_test)
Saída: variedade([ 0.78305084, 0.49957596, 0.21610108, -0.0673738 , -0.35084868])
5. Regressor florestal aleatório
Florestas aleatórias são um conjunto (combinação) de árvores de decisão. É um algoritmo de aprendizagem supervisionado que é usado para classificação e regressão. Os dados de entrada são passados através de várias árvores de decisão. Ele é executado construindo um número diferente de árvores de decisão no momento da TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... e gerando a classe que é o modo do (para classificação) o previsão média (para regressão) de árvores individuais.
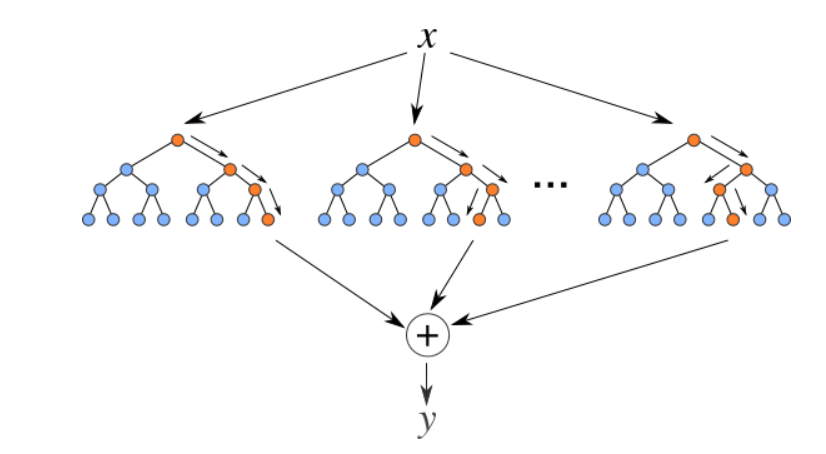
Fonte: https://levelup.gitconnected.com
Prós:
- Bom para aprender relacionamentos complexos e não lineares
- Muito fácil de interpretar e entender.
Contras:
- São propensos a superequipar
- Usar matrizes florestais aleatórias maiores para alcançar maior desempenho diminui sua velocidade e, em seguida, eles também precisam de mais memória.
Implementação
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features=4, n_informative=2, random_state = 0, shuffle = False)
rfr = RandomForestRegressor(max_depth=3)
rfr.fit(X, e)
imprimir(rfr.predict([[0, 1, 0, 1]]))
Saída:
[33.2470716]
Notas finais
Aqui estão alguns algoritmos de regressão populares, Há muito mais e também algoritmos avançados. Explore-os também.. Você também pode seguir esses algoritmos de classificação para aumentar seu conhecimento de aprendizado de máquina..
Obrigado por ler se você chegou aqui 🙂
Vamos conectar LinkedIn
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





