Este artigo foi publicado como parte do Data Science Blogathon
Depois de entender e trabalhar com este tutorial prático, poderia:
- Entenda o que é coorte e análise de coorte.
- Tratamento de valores ausentes
- Extração do mês a partir da data
- Asignar cohorte a cada transaçãoo "transação" refere-se ao processo pelo qual ocorre uma troca de mercadorias, serviços ou dinheiro entre duas ou mais partes. Este conceito é fundamental no campo econômico e jurídico, uma vez que envolve acordo mútuo e consideração de termos específicos. As transações podem ser formais, como contratos, ou informal, e são essenciais para o funcionamento dos mercados e negócios....
- Asignar índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... de cohorte a cada transacción
- Calcule o número de clientes únicos em cada grupo.
- Crie uma tabela de coorte para a taxa de retenção
- Visualice la tabla de cohortes usando el mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas....
- Interprete a taxa de retenção
O que é coorte e análise de coorte?
Um coorte é uma coleção de usuários que têm algo em comum. Uma coorte tradicional, por exemplo, divida as pessoas pela semana ou mês em que foram adquiridas pela primeira vez. Ao se referir a agrupamentos não dependentes de tempo, o termo segmento é frequentemente usado em vez de coorte.
El análisis de cohortes es una técnica analíticaAnalytics refere-se ao processo de coleta, Meça e analise dados para obter insights valiosos que facilitam a tomada de decisões. Em vários campos, como negócio, Saúde e esporte, A análise pode identificar padrões e tendências, Otimize processos e melhore resultados. O uso de ferramentas avançadas e técnicas estatísticas é essencial para transformar dados em conhecimento aplicável e estratégico.... descriptiva en el análisis de cohortes. Os clientes são divididos em coortes mutuamente exclusivas, que são rastreados ao longo do tempo. Os indicadores de vaidade não oferecem o mesmo nível de perspectiva que a pesquisa de coorte. Ajuda na interpretação mais profunda de padrões de alto nível, fornecendo métricas de ciclo de vida do consumidor e do produto.
Geralmente, existem três tipos principais de coortes:
- Coortes de tempo: clientes que se inscreveram para um produto ou serviço durante um determinado período de tempo.
- Coortes comportamentais: clientes que compraram um produto ou assinaram um serviço no passado.
- Coortes de tamanho: referem-se aos diferentes tamanhos de clientes que compram os produtos ou serviços da empresa.
Porém, estaremos fazendo Análise de coorte baseada no tempo. Os clientes serão divididos em coortes de aquisição com base no mês de sua primeira compra. Mais tarde, o índice de coorte seria atribuído a cada uma das compras do cliente, que representará o número de meses desde a primeira transação.
Objetivos:
- Encontre a porcentagem de clientes ativos em comparação com o número total de clientes após cada mês: Segmentações de clientes
- Interprete a taxa de retenção
Aqui está o código completo para este tutorial. si desea seguir la información a mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que avanza en el tutorial.
Etapa envolvida na análise da taxa de retenção da coorte
1. Carregando e limpando dados
2. Atribua a coorte e calcule o
Paso 2.1
- Truncar o objeto de dados para um necessário (aqui precisamos do mês, então a data da transação)
- Criar objeto groupby com coluna de destino (aqui, Identificação do Cliente)
- Transforme com uma função mínima () para atribuir a menor data de transação no valor do mês para cada cliente.
O resultado desse processo é a coorte do mês de aquisição para cada cliente, quer dizer, atribuímos a coorte do mês de aquisição a cada cliente.
Paso 2.2
- Calcule a compensação de tempo extraindo valores inteiros para o ano, mês e dia de um objeto datetime ().
- Calcule o número de meses entre qualquer transação e a primeira transação para cada cliente. Usaremos os valores TransactionMonth e CohortMonth para fazer isso.
O resultado disso será cohortIndex, quer dizer, a diferença entre “TransactionMonth” e “CohortMonth” em termos de número de meses e chame a coluna “cohortIndex”.
Paso 2.3
- Crie um objeto groupby com CohortMonth e CohortIndex.
- Conte o número de clientes em cada grupo aplicando a função pandas nunique ().
- Redefina o índice e crie o pivô do pandas com CohortMonth nas linhas, CohortIndex em colunas e customer_id conta como valores.
O resultado disso será a tabela que servirá de base para o cálculo da taxa de retenção e também de outras matrizes.
3. Calcular matrizes de negócios: Taxa de retenção.
Medidas de retenção quantos clientes de cada coorte retornaram nos meses seguintes.
- Usando a estrutura de dados chamada cohort_counts, vamos selecionar as primeiras colunas (igual ao número total de clientes em coortes)
- Calcule a proporção de quantos desses clientes retornaram nos meses seguintes.
O resultado dá uma taxa de retenção.
4. Visualização da taxa de retenção
5. Interpretação da taxa de retenção
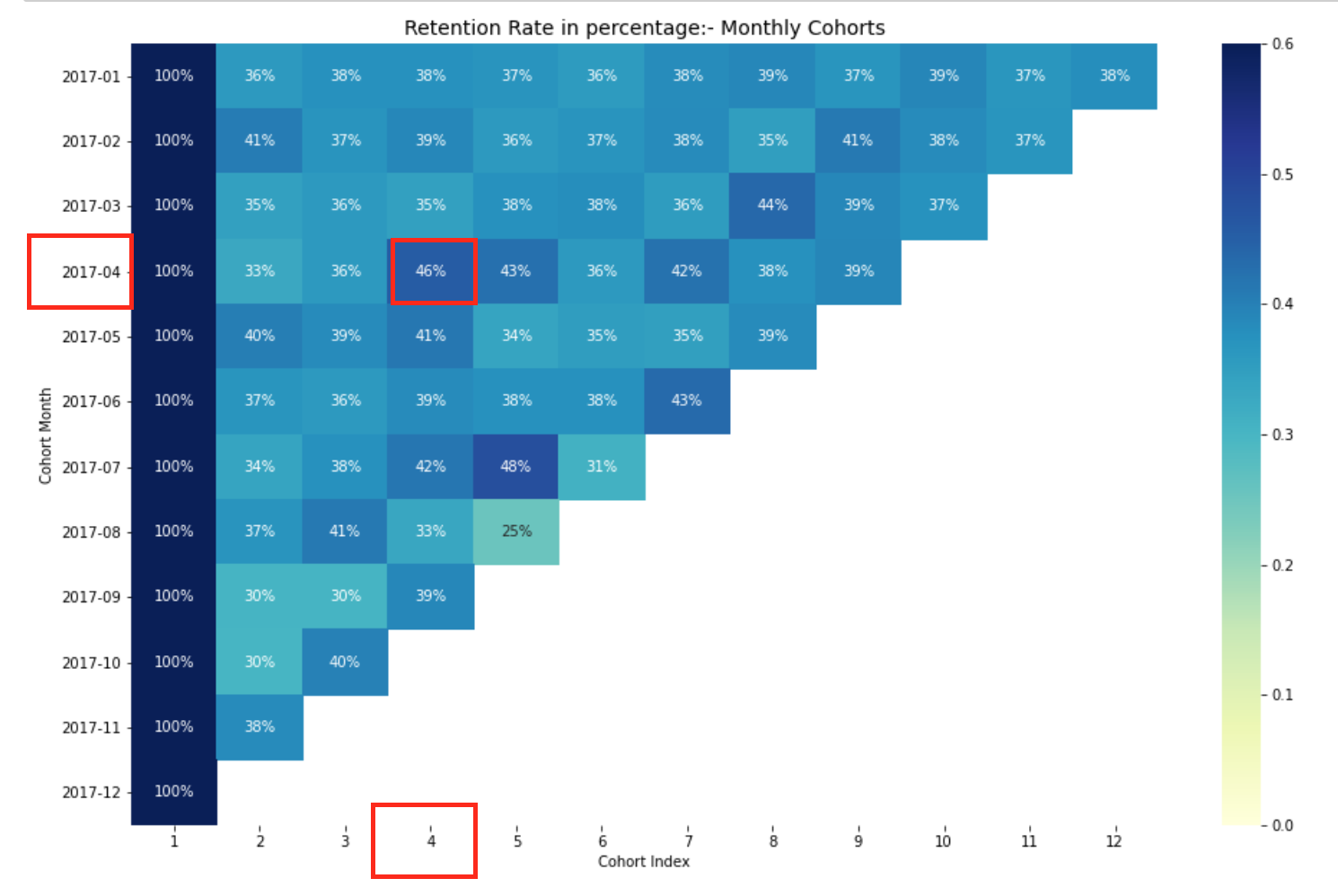
Taxa mensal de retenção de coortes.
Vamos começar:
Bibliotecas de importação
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import datetime as dt
import missingno as msno
from textwrap import wrap
Carregando e limpando dados
# Loading dataset transaction_df = pd.read_excel('transcações.xlsx') # View data transaction_df.head()

Comprobando y trabajando con valor faltante
# Inspect missing values in the dataset print(transaction_df.isnull().valores.soma()) # Replace the ' 's with NaN transaction_df = transaction_df.replace(" ",Np. Nan) # Impute the missing values with mean imputation transaction_df = transaction_df.fillna(transaction_df.média()) # Count the number of NaNs in the dataset to verify print(transaction_df.isnull().valores.soma())
imprimir(transaction_df.info())
para col em transaction_df.colunas:
# Check if the column is of object type
if transaction_df[col].dtypes == 'objeto':
# Impute with the most frequent value
transaction_df[col] = transaction_df[col].Fillna(transaction_df[col].valor_contas().índice[0])
# Count the number of NaNs in the dataset and print the counts to verify
print(transaction_df.isnull().valores.soma())
Aqui, podemos ver que tenemos 1542 valores nulos. Que tratamos con valores medios y más frecuentes según el tipo de datos. Ahora que hemos completado nuestra limpieza y comprensión de datos, comenzaremos el análisis de coorte.
Asignó las coortes y cálculo la compensación mensual.
# Uma função que analisará a coorte baseada em data: 1 day of month def get_month(x): retorno dt.datetime(x.ano, x.mês, 1) # Create transaction_date column based on month and store in TransactionMonth transaction_df['TransactionMonth'] = transaction_df['transaction_date'].Aplique(get_month) # Grouping by customer_id and select the InvoiceMonth value grouping = transaction_df.groupby('customer_id')['TransactionMonth'] # Assigning a minimum InvoiceMonth value to the dataset transaction_df['CoorteMonto'] = agrupamento.transform('min') # topo de impressão 5 rows print(transaction_df.cabeça())
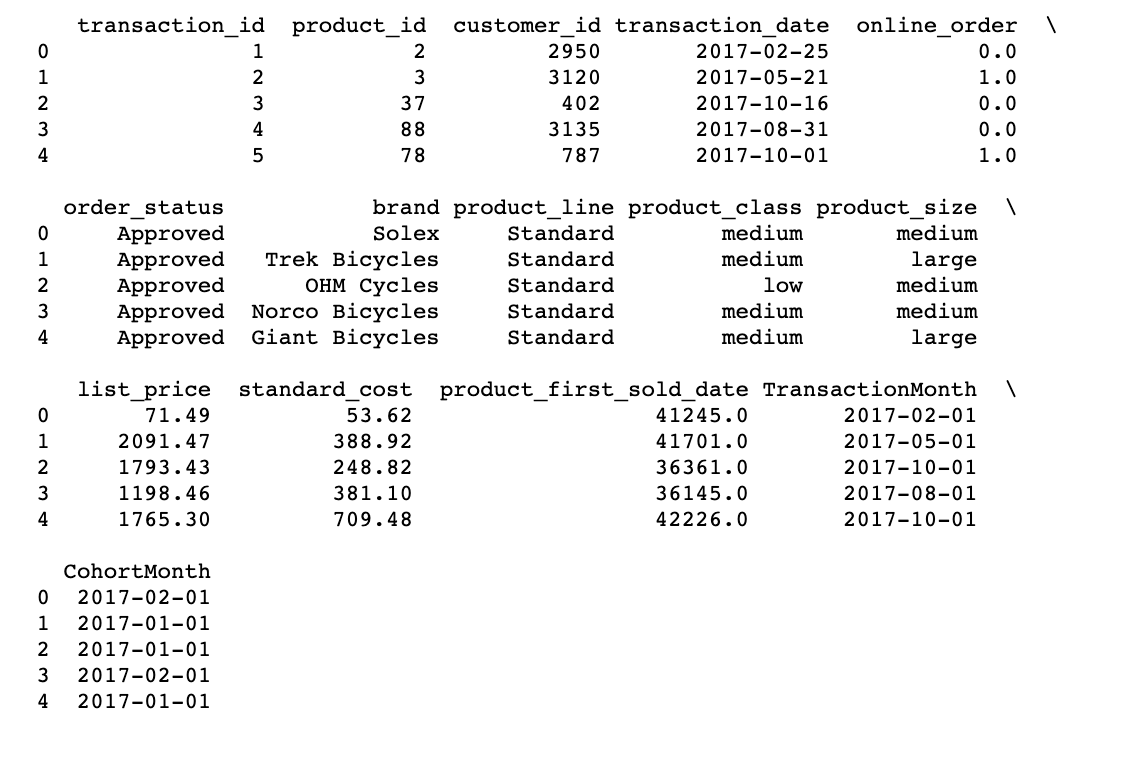
Cálculo de la compensación de tiempo en el mes como índice de coorte
Calcular a compensação de tempo para cada transação permite avaliar as métricas de cada coorte de forma comparável.
Primeiro, nós vamos criar 6 variáveis que capturam o valor inteiro de anos, meses e dias para Transação e Data de Coorte usando a função get_date_int ().
def get_date_int(df, coluna):
ano = df[coluna].dt.year
month = df[coluna].dt.month
day = df[coluna].dt.day
return year, mês, dia
# Getting the integers for date parts from the `InvoiceDay` column
transcation_year, transaction_month, _ get_date_int(transaction_df, 'TransactionMonth')
# Getting the integers for date parts from the `CohortDay` column
cohort_year, cohort_month, _ get_date_int(transaction_df, 'CoorteMonto')
Agora vamos calcular a diferença entre datas de fatura e datas de coorte em anos, meses separadamente. em seguida, calcular a diferença total de meses entre os dois. Este será o índice de coorte ou compensação do nosso mês, que usaremos na próxima seção para calcular a taxa de retenção.
# Get the difference in years years_diff = transcation_year - cohort_year # Calculate difference in months months_diff = transaction_month - cohort_month """ Extrair a diferença em meses de todos os valores anteriores "+1" em adicionado no final para que o primeiro mês é marcado como 1 ao invés de 0 para uma interpretação mais fácil. """ transaction_df['CoortIndex'] = years_diff * 12 + months_diff + 1 imprimir(transaction_df.cabeça(5))
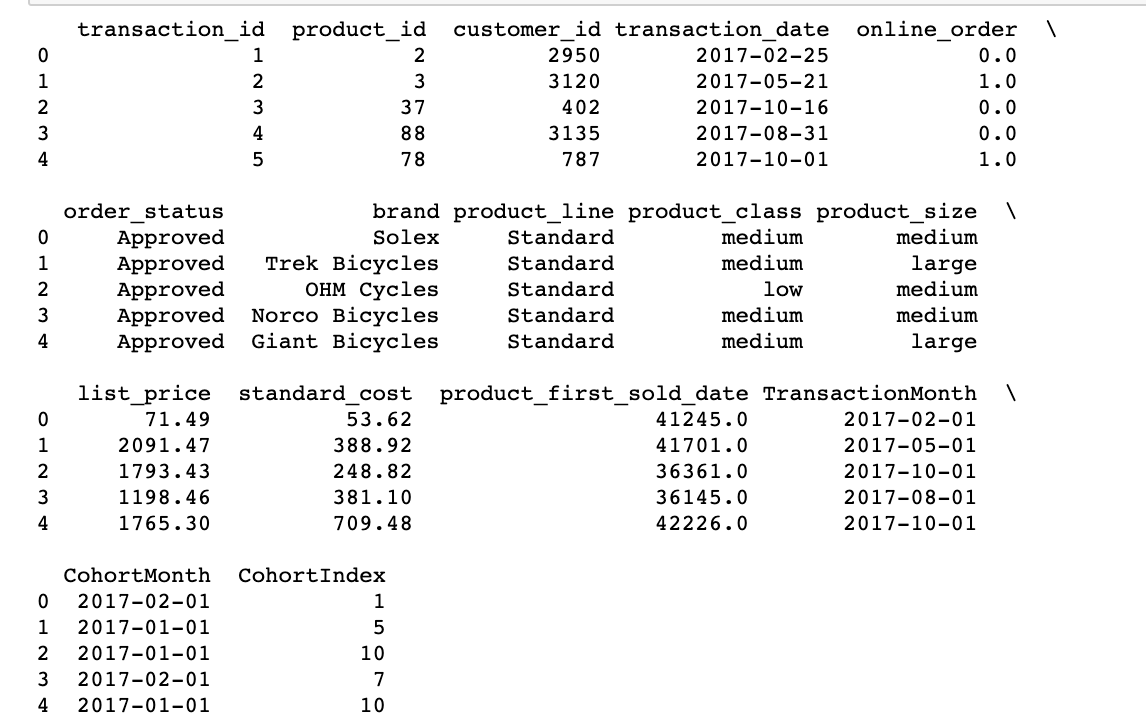
Aqui, no princípio, criamos um grupo() objeto com CoortMonth e CoorteIndex e salvá-lo como um agrupamento.
Mais tarde, chamamos esse objeto, selecionamos o Identificação do cliente coluna e calcular a média.
Em seguida, armazenamos os resultados como cohort_data. Mais tarde, redefinir o índice antes de chamar a função pivô para poder acessar as colunas agora armazenadas como índices.
Finalmente, creamos una tabela dinâmicaA Tabela Dinâmica é uma ferramenta poderosa em programas de planilhas, como o Microsoft Excel e o Google Sheets. Permite resumir, Analise e visualize grandes volumes de dados com eficiência. Através de sua interface intuitiva, Os usuários podem reorganizar as informações, Aplique filtros e crie relatórios personalizados, facilitar a tomada de decisões informadas em vários contextos, do campo empresarial à pesquisa acadêmica.... omitiendo
- CoortMes para o parâmetro de índice,
- Índice de coorte para o parâmetro coluna,
- Identificação do cliente ao parâmetro de valores.
e arredondar para 1 dígito e ver o que temos.
# Counting daily active user from each chort grouping = transaction_df.groupby(['CoorteMonto', 'CoortIndex']) # Counting number of unique customer Id's falling in each group of CohortMonth and CohortIndex cohort_data = grouping['customer_id'].Aplique(Pd. Série.nunique) cohort_data = cohort_data.reset_index() # Assigning column names to the dataframe created above cohort_counts = cohort_data.pivot(índice='CoorteMonto', colunas ="CoortIndex", valores ="Identificação do Cliente") # Topo de impressão 5 rows of Dataframe cohort_data.head()
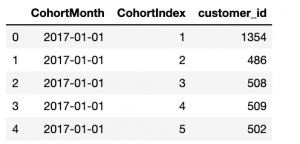
Calcular métricas de negócios: taxa de retenção
A porcentagem de clientes ativos em comparação com o número total de clientes após um intervalo de tempo especificado é chamada de taxa de retenção..
Nesta secção, vamos calcular a contagem de retenção para cada mês de coorte combinado com o índice de coorte
Agora que temos uma contagem dos clientes retidos para cada coorte e cohortIndex. Vamos calcular a taxa de retenção para cada coorte.
Vamos criar uma tabela dinâmica para este propósito.
cohort_sizes = cohort_counts.iloc[:,0] retenção = cohort_counts.divide(cohort_sizes, eixo = 0) # Converter a taxa de retenção em porcentagem e arredondar. retenção.round(3)*100
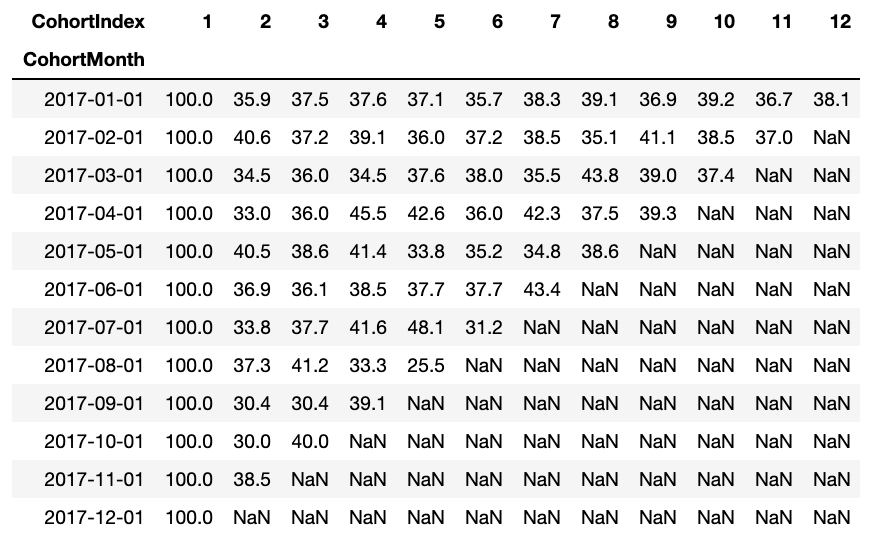
O quadro de dados da taxa de retenção representa o cliente retido em todas as coortes. Podemos ler da seguinte maneira:
- O valor do índice representa a coorte
- As colunas representam o número de meses desde a coorte atual
Por exemplo: O valor em CohortMonth 2017-01-01, CoortIndex 3 isto é 35,9 e representa 35,9% de clientes na coorte 2017-01 foram mantidos no 3é mes.
O que mais, você pode ver no DataFrame para taxa de retenção:
- Taxa de retenção O primeiro índice, quer dizer, o primeiro mês é a partir de 100%, uma vez que todos os clientes desse cliente em particular se inscreveram no primeiro mês
- A taxa de retenção pode aumentar ou diminuir nos índices subsequentes.
- Os valores no canto inferior direito têm muitos valores NaN.
Visualizando a taxa de retenção
Antes de começarmos a desenhar nosso mapa de calor, vamos definir o índice de nosso quadro de dados de taxa de retenção para um formato de string mais legível.
average_standard_cost.index = average_standard_cost.index.strftime('%Y-%m')
# Initialize the figure
plt.figure(figsize =(16, 10))
# Adding a title
plt.title('Custo padrão médio: Coortes Mensais, fontsize = 14)
# Creating the heatmap
sns.heatmap(average_standard_cost, annot = True,vmin = 0.0, vmax =20,cmap="YlGnBu", fmt="g")
plt.ylabel('Mês da Coorte')
plt.xlabel('Índice de Coorte')
plt.yticks( rotação='360')
plt.show()
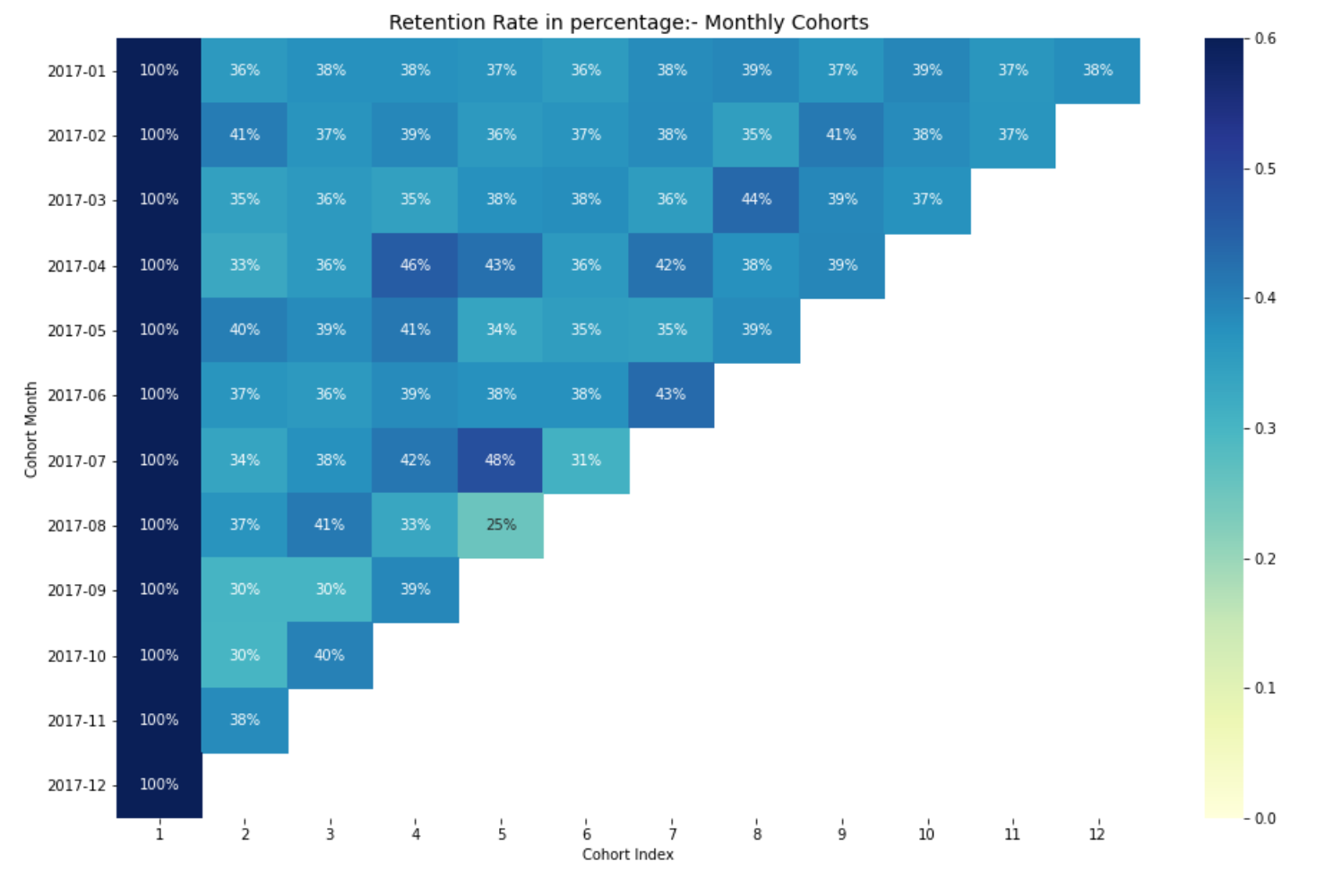
Interpretando a taxa de retenção
A maneira mais eficaz de visualizar e analisar dados de análise de coorte é através de um mapa de calor., como fizemos anteriormente. Fornece valores métricos reais e codificação de cores para ver diferenças nos números visualmente.
Se você não tem um conhecimento básico sobre mapa de calor, você pode verificar o meu blog. Análise exploratória de dados para iniciantes com Python, onde falei sobre mapas de calor para iniciantes.
Aqui, tenho 12 coortes para cada mês e 12 índices de coorte. Quanto mais escuros são os tons de azul, quanto maiores os valores. A) Sim, se virmos no mês da coorte 2017-07 no 5º índice de coorte, vemos o tom azul escuro com um 48% o que significa que o 48% das coortes que assinaram em julho 2017 eles eram ativos 5 meses depois.
Isso conclui nossa análise de coorte para a taxa de retenção.. de forma similar, podemos realizar análises de coorte para outras matrizes comerciais.
Clique aqui para saber mais sobre a análise de coorte para empresas grátis com DataCamp.(Link de afiliado)
Portanto, concluímos nossa análise de coorte, onde você aprendeu sobre análises básicas e de coorte, conduzindo coortes de tempo, trabalhando com o pivô do pandas e criando uma mesa de espera junto com a visualização. Também aprendemos como explorar outras matrizes.
Agora, você pode começar a criar e explorar as métricas que são importantes para o seu negócio por conta própria.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





