Este artigo foi publicado como parte do Data Science Blogathon

De acordo com os especialistas, a 80% dos dados existentes no mundo está na forma de dados não estruturados (imagens, videos, texto, etc.). Esses dados podem ser gerados por tweets / postagens nas redes sociais, transcrições de chamadas, resenhas de pesquisas ou entrevistas, mensagens de texto em blogs, fóruns, notícia, etc.
É humanamente impossível ler todo o texto na web e encontrar padrões. Porém, há definitivamente a necessidade de a empresa analisar esses dados para tomar melhores ações.
Um desses processos de obter insights de dados textuais é a análise de sentimentos.. Para obter os dados para análise de sentimentos, pode-se raspar diretamente o conteúdo das páginas da web usando diferentes técnicas de raspagem da web.
Se você é novo no web scraping, sinta-se à vontade para verificar meu artigo “Raspagem da Web com Python: BeautifulSoup”.
O que é análise de sentimento?
Análise de sentimentos (também conhecido como mineração de opinião ou IA de emoção) é um subcampo da PNL que mede o viés das opiniões das pessoas (positivo / negativo / neutro) dentro de texto não estruturado.
A análise de sentimento pode ser realizada usando duas abordagens: baseado em regras, baseado em aprendizado de máquina.
Poucas aplicações de análise de sentimentos
- Análise de mercado
- Monitoramento de mídia social
- Análise do feedback do cliente: sentimento de marca ou análise de reputação
- Investigação de mercado
O que é processamento de linguagem natural (PNL)?
A linguagem natural é a forma como, os humanos, nós nos comunicamos. Pode ser voz ou texto. A PNL é a manipulação automática da linguagem natural por software.. PNL é um termo de nível superior e é a combinação de Compreensão de linguagem natural (NLU) e Geração de linguagem natural (NLG).
PNL = NLU + NLG
Algumas das bibliotecas de processamento de linguagem natural do Python (PNL) filho:
- Kit de ferramentas de linguagem natural (NLTK)
- TextBlob
- ESPAÇO
- Gensim
- CoreNLP
Espero que tenhamos uma compreensão básica dos termos Análise de Sentimento, PNL.
Este artigo se concentra na abordagem baseada em regras para análise de sentimentos..
Abordagem baseada em regras
Esta é uma abordagem prática para analisar texto sem treinamento ou usando modelos de aprendizado de máquina. O resultado dessa abordagem é um conjunto de regras com base nas quais o texto é rotulado como positivo. / negativo / neutro. Essas regras também são conhecidas como léxicos.. Portanto, a abordagem baseada em regras é chamada de abordagem baseada em léxico.
Abordagens amplamente utilizadas baseadas em léxico são TextBlob, VADER, SentiWordNet.
Etapas de pré-processamento de dados:
- Limpando o texto
- Tokenización
- Enriquecimento: marcação ponto de venda
- Removendo palavras irrelevantes
- Obter as palavras raiz
Antes de mergulhar nas etapas acima, deixe-me importar os dados de texto de um arquivo txt.
Importe um arquivo de texto usando Pandas lêem CSV Função
# instalar e importar biblioteca pandas importar pandas como pd # Creating a pandas dataframe from reviews.txt file data = pd.read_csv('comentários.txt', sep = 't') data.head()


Isso não parece bom.. Então, agora vamos liberar o “Anónimo: 0 ″ coluna usando o df.drop Função.
mydata = data.drop('Sem nome: 0', eixo = 1)
mydata.head()

Nosso conjunto de dados tem um total de 240 observações (avaliações).
Paso 1: Limpe o texto
Nesta etapa, precisamos remover caracteres especiais, números de texto. Podemos usar o operações de expressão regular Biblioteca Python.
# Define a function to clean the text def clean(texto): # Removes all special characters and numericals leaving the alphabets text = re.sub('[^A-Za-z]+', '', texto) texto de retorno # Cleaning the text in the review column mydata['Resenhas Limpas'] = mydata['Reveja'].Aplique(limpar) mydata.head()
Explicação: "Limpo" é a função que leva o texto como entrada e o devolve sem pontuação ou números. Aplicamos na coluna 'review'’ e criamos uma nova coluna 'Clean Reviews'’ com texto limpo.

Fantástico, ver a imagem acima, todos os caracteres especiais e números são removidos.
Paso 2: Tokenización
Tokenização é o processo de divisão do texto em partes menores chamadas Tokens.. Pode ser realizado no nível de oração (tokenização de sentença) ou palavra (tokenização de palavras).
Vou realizar tokenização em nível de palavra usando tokenizar nltk função word_tokenize ().
Observação: Como nossos dados de texto são um pouco grandes, Vou primeiro ilustrar os passos 2-5 com frases curtas de exemplo.
Digamos que temos uma oração “Este é um artigo sobre análise de sentimentos.“. Pode ser quebrado em pequenos pedaços (registros) como é mostrado a seguir.

Paso 3: Enriquecimento: Rotulagem de PDV
Rotulando partes do discurso (POS) é um processo de conversão de cada token em uma tupla com a forma (palavra, rótulo). A marcação POS é essencial para preservar o contexto da palavra e é essencial para a lematização.
Isso pode ser feito usando nltk pos_tag Função.
Abaixo estão as tags POS da frase de exemplo “Este é um artigo sobre análise de sentimentos”.
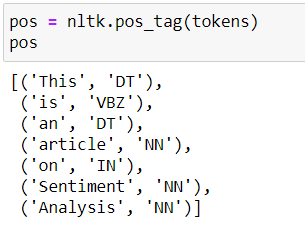
Veja a lista de rótulos pos possíveis para aqui.
Paso 4: remoção de palavras de ruído
Palavras de parada em inglês são palavras que contêm muito pouca informação útil.. Precisamos removê-los como parte do pré-processamento de texto. nltk tem uma lista de palavras irrelevantes para cada idioma.
Verifique as palavras de parada em inglês.

Exemplo de remoção de stopword:

As palavras vazias Isso, é, um, on são removidos e a frase de saída é 'Análise de sentimento do artigo'.
Paso 5: obter as palavras de raiz
Uma raiz é parte de uma palavra responsável por seu significado lexical.. As duas técnicas populares para obter as palavras-raiz / raiz são Stemming e Lematization.
A principal diferença é que Stemming muitas vezes dá algumas palavras de raiz sem sentido., como ele simplesmente corta alguns caracteres no final. Lemmatização fornece raízes significativas, porém, requer tags pos de palavras.
Exemplo para ilustrar a diferença entre Stemming e Lematization: Clique aqui para obter o código

Se olharmos para o exemplo anterior, a saída de Stemming é Stem e a saída de Lemmatizatin é Lemma.
Pela palavra olhar, o caule glanc não faz sentido. Considerando que, o Lema olhar É perfeito..
Agora entendemos os passos 2-5 tomando exemplos simples. Sem mais demora, vamos voltar para o nosso problema real.
Código para as etapas 2 uma 4: tokenización, Marcação de PDV, remoção de palavras de ruído
import nltk nltk.download('Apontar') from nltk.tokenize import word_tokenize from nltk import pos_tag nltk.download('stopwords') from nltk.corpus import stopwords nltk.download('wordnet') de nltk.corpus importar wordnet # POS tagger dictionary pos_dict = {'J':wordnet. ADJ, 'V':wordnet. VERBO, 'N':wordnet. SUBSTANTIVO, 'R':wordnet. ADV} def token_stop_pos(texto): tags = pos_tag(word_tokenize(texto)) newlist = [] por palavra, tags: se a palavra.baixar() não no conjunto(stopwords.words('inglês')): newlist.append(tupla([palavra, pos_dict.(marcação[0])])) return newlist mydata['Pos marcado'] = mydata['Resenhas Limpas'].Aplique(token_stop_pos) mydata.head()
Explicação: token_stop_pos é a função que pega o texto e executa a tokenização, remover palavras vazias e tag palavras em seu PDV. Aplicamos na coluna 'Clean Reviews'’ e criamos uma nova coluna para os dados 'PDV marcados'.
Como mencionado anteriormente, para obter o lemma preciso, WordNetLemmatizer requer tags POS na forma de 'n', 'uma', etc. Mas as tags POS obtidas de pos_tag têm o formulário 'NN', 'ADJ', etc.
Para atribuir pos_tag às tags wordnet, criamos um dicionário pos_dict. Qualquer pos_tag que começa com J é mapeada para o wordnet. ADJ, qualquer pos_tag que começa com R é mapeada para o wordnet. ADV, e assim por diante.
Nossas etiquetas de interesse são substantivas, Adjetivo, Advérbio, Verbo. Qualquer um desses quatro é atribuído a Nenhum.

No figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... anterior, podemos observar que cada palavra na coluna 'POS marcado’ é atribuído ao seu PDV a partir de pos_dict.
Código para a etapa 5: obter as palavras de raiz – Lematización
from nltk.stem import WordNetLemmatizer wordnet_lemmatizer = WordNetLemmatizer() def lemmatize(pos_data): lemma_rew = " " por palavra, pos em pos_data: se não pos: lemma = word lemma_rew = lemma_rew + " " + lemma else: lemma = wordnet_lemmatizer.lemmatize(palavra, pos=pos) lemma_rew = lemma_rew + " " + lemma return lemma_rew mydata['Lemma'] = mydata['Pos marcado'].Aplique(lemmatize) mydata.head()
Explicação: lemmatize é uma função que leva tuplas pos_tag e dá o Lemma para cada palavra em pos_tag com base no pos dessa palavra. Nós o aplicamos à coluna ‘POS rotulado’ e crie uma coluna 'Lemma’ para armazenar a saída.
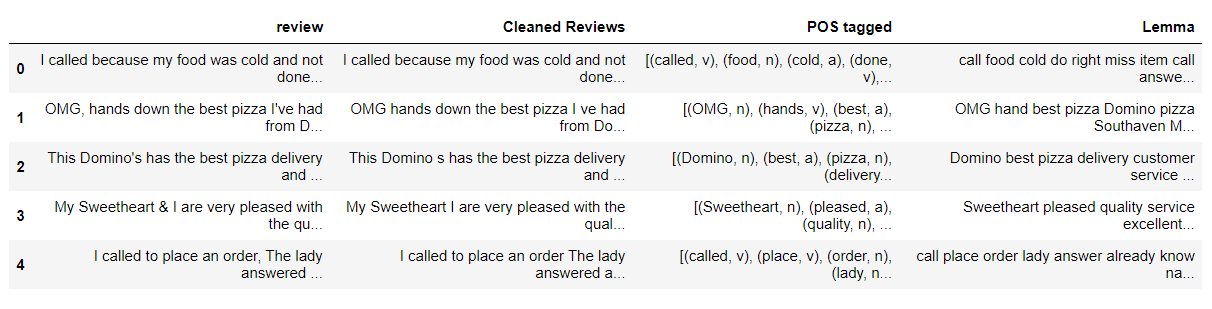
sim, depois de uma longa viagem, terminamos o pré-processamento de texto.
Agora, reserve um minuto para ver as colunas de 'revisão', 'Lema’ e observe como o texto é renderizado.
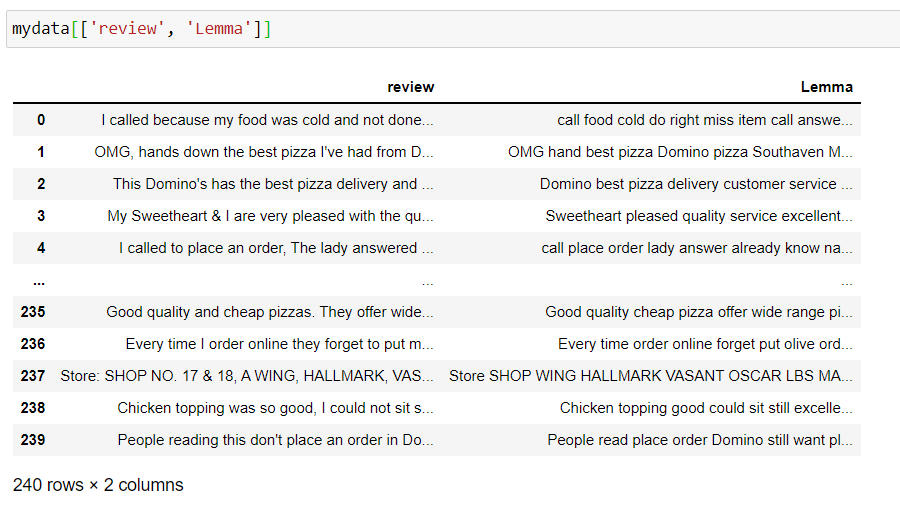
Quando terminarmos o pré-processamento de dados, nossos dados finais parecem limpos. Faça uma pequena pausa e volte para continuar com a tarefa real.
Análise de sentimentos usando TextBlob:
TextBlob é uma biblioteca Python para processamento de dados textuais. Fornece uma API consistente para mergulhar em tarefas comuns de processamento de linguagem natural (PNL), como rotulagem de parte do discurso, extração de frase nominal, análise sentimento e mais.
As duas medidas que são usadas para analisar o sentimento são:
- Polaridade: fala sobre o quão positivo ou negativo a opinião é.
- Subjetividade: fala sobre como a opinião subjetiva é.
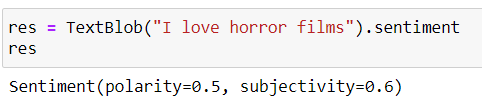
TextBlob (texto) .sentimento nos dá os valores da Polaridade, Subjetividade.
Polaridade varia de -1 uma 1 (1 é mais positivo, 0 é neutro, -1 é mais negativo)
A subjetividade varia de 0 uma 1 (0 é muito objetivo e 1 muito subjetivo)
Código Python:
de textblob importação TextBlob # function to calculate subjectivity def getSubjectivity(Reveja): retornar TextBlob(Reveja).sentimento.subjetividade # function to calculate polarity def getPolarity(Reveja): retornar TextBlob(Reveja).sentimento.polaridade # function to analyze the reviews def analysis(pontuação): se pontuação < 0: return 'Negative' elif score == 0: return 'Neutral' else: retorno 'Positivo'
Explicação: funções criadas para obter valores de polaridade, subjetividade e rotule a revisão com base na pontuação de polaridade.
Crie um novo dataframe com a revisão, Colunas de lema e aplique as funções acima
fin_data = pd.DataFrame(meus dados[['Reveja', 'Lemma']])
# fin_data['Subjetividade'] = fin_data['Lemma'].Aplique(getSubjetividade) fin_data['Polaridade'] = fin_data['Lemma'].Aplique(getPolarity) fin_data['Análise'] = fin_data['Polaridade'].Aplique(análise) fin_data.head()
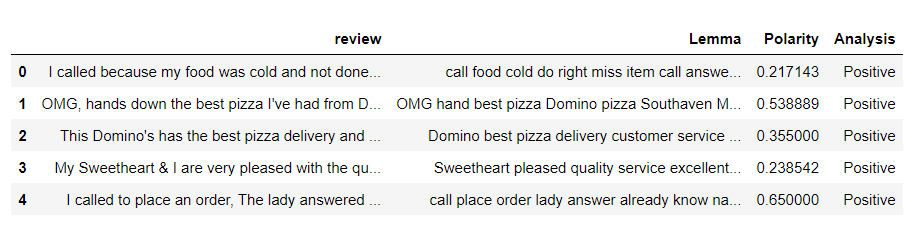
Conte o número de avaliações positivas, negativo e neutro.
tb_counts = fin_data.Analysis.value_counts() tb_counts
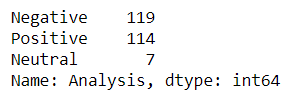
Análise de sentimento com VADER
VADER significa Valence Aware Dictionary and Sentiment Reasoner. O sentimento de Vader não apenas informa se a afirmação é positiva ou negativa, juntamente com a intensidade da emoção.

A soma das intensidades, neg, novo lá 1. O composto varia de -1 uma 1 y é a métrica usada para desenhar o sentimento geral.
positivo se composto> = 0.5
neutro se -0,5 <composto <0,5
negativo se -0,5> = composto
Código Python:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer analyzer = SentimentIntensityAnalyzer() # function to calculate vader sentiment def vadersentimentanalysis(Reveja): vs = Analyzer.polarity_scores(Reveja) retorno vs['composto'] fin_data['Sentimento Vader'] = fin_data['Lemma'].Aplique(vadersentimentanalysis) # function to analyse def vader_analysis(composto): se composto >= 0.5: return 'Positive' elif compound <= -0.5 : return 'Negative' else: return 'Neutral' fin_data['Análise Vader'] = fin_data['Sentimento Vader'].Aplique(vader_analysis) fin_data.head()
Explicação: Recursos criados para obter pontuações vader e avaliações de tags com base em pontuações compostas
Conte o número de avaliações positivas, negativo e neutro.
vader_counts = fin_data['Análise Vader'].valor_contas() vader_counts
Análise de sentimento usando SentiWordNet
SentiWordNet utiliza la base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... WordNet. É importante pegar o PDV., lema de cada palavra. Então usaremos o lema, PDV para obter os conjuntos de sinônimos (synsets). A seguir, temos as pontuações objetivas, negativo e positivo para todos os sintetizadores possíveis ou o primeiro sintetizador e rotulamos o texto.
se pontuação positiva> pontuação negativa, o sentimento é positivo
se pontuação positiva <pontuação negativa, o sentimento é negativo
se o resultado positivo = resultado negativo, o sentimento é neutro
Código Python:
nltk.download('sentiwordnet')
from nltk.corpus import sentiwordnet as swn
def sentiwordnetanalysis(pos_data):
sentimento = 0
tokens_count = 0
por palavra, pos em pos_data:
se não pos:
continue
lemma = wordnet_lemmatizer.lemmatize(palavra, pos=pos)
se não lemma:
continue
synsets = wordnet.synsets(lema, pos=pos)
se não síndeos:
Prosseguir
# Tome o primeiro sentido, the most common
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
sentimento += swn_synset.pos_score() - swn_synset.neg_score()
tokens_count += 1
# imprimir(swn_synset.pos_score(),swn_synset.neg_score(),swn_synset.obj_score())
se não tokens_count:
Retorna 0
se o sentimento>0:
Retorna "Positivo"
se o sentimento==0:
Retorna "Neutro"
outro:
Retorna "Negativo"
fin_data['Análise SWN'] = mydata['Pos marcado'].Aplique(sentiwordnetanalysis)
fin_data.head()
Explicação: Criamos uma função para obter os escores positivos e negativos para a primeira palavra do sínduco e, em seguida, rotulamos o texto calculando o sentimento como a diferença de pontuações positivas e negativas..
Conte o número de avaliações positivas, negativo e neutro.
swn_counts= fin_data['Análise SWN'].valor_contas() swn_counts
Até aqui, vimos a implementação da análise de sentimento usando algumas das técnicas populares baseadas no léxico. Agora faça rapidamente uma visualização e compare os resultados.
Representação visual dos resultados do TextBlob, VADER, SentiWordNet
Vamos traçar a contagem de avaliações positivas, negativo e neutro para todas as três técnicas.
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize =(15,7))
plt.subplot(1,3,1)
plt.title("Resultados do TextBlob")
plt.pie(tb_counts.values, rótulos = tb_counts.index, explodir = (0, 0, 0.25), autopct ="%1.1f %%", sombra=Falso)
plt.subplot(1,3,2)
plt.title("resultados do VADER")
plt.pie(vader_counts.values, rótulos = vader_counts.index, explodir = (0, 0, 0.25), autopct ="%1.1f %%", sombra=Falso)
plt.subplot(1,3,3)
plt.title("Resultados do SentiWordNet")
plt.pie(swn_counts.values, rótulos = swn_counts.index, explodir = (0, 0, 0.25), autopct ="%1.1f %%", sombra=Falso)
Se olharmos para a imagem acima, Os resultados do TextBlob e do SentiWordNet parecem um pouco próximos, enquanto os resultados do VADER mostram uma grande variação.
Notas finais:
Parabéns 🎉 para nós. No final deste artigo, aprendemos as várias etapas do pré-processamento de dados e as diferentes abordagens baseadas em léxico para análise de sentimentos. Comparamos os resultados do TextBlob, VADER, SentiWordNet usando gráficos de pizza.
Referências:
Confira o notebook Jupyter completo aqui hospedado no GitHub.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





