Este artigo foi publicado como parte do Data Science Blogathon.
“Para ganhar no mercado, você deve vencer no local de trabalho” –Steve Jobs, fundador da Apple Inc..
Introdução
Por que usamos regressão logística para analisar o atrito de funcionários?
Se um funcionário vai ficar ou sair de uma empresa, sua resposta é simplesmente binomial, quer dizer, pode ser “SIM” o “NÃO”. Então, podemos ver que nossa variável dependente Atrito de funcionário é apenas uma variável categórica. No caso de uma variável dependente categórica, não podemos usar regressão linear, nesse caso, Temos que usar "REGRESSÃO LOGÍSTICA“.
Metodologia
Aqui, Vou vestir 5 Etapas simples para analisar o desgaste de funcionários usando o software R
- COLETA DE DADOS
- PRÉ-PROCESSAMENTO DE DADOS
- DIVIDINDO OS DADOS EM DUAS PARTES “TREINAMENTO” E “TESTES”
- CONSTRUA O MODELO COM O “CONJUNTO DE DADOS DE TREINAMENTO”
- FAÇA O TESTE DE PRECISÃO USANDO O “CONJUNTO DE DADOS DE TESTE”
Exploração de dados
Este conjunto de dados é coletado do departamento de Recursos Humanos da IBM. O conjunto de dados contém 1470 observações e 35 variáveis. Dentro de 35 variáveis, "Desgaste" é a variável dependente.
Uma rápida olhada no conjunto de dados:
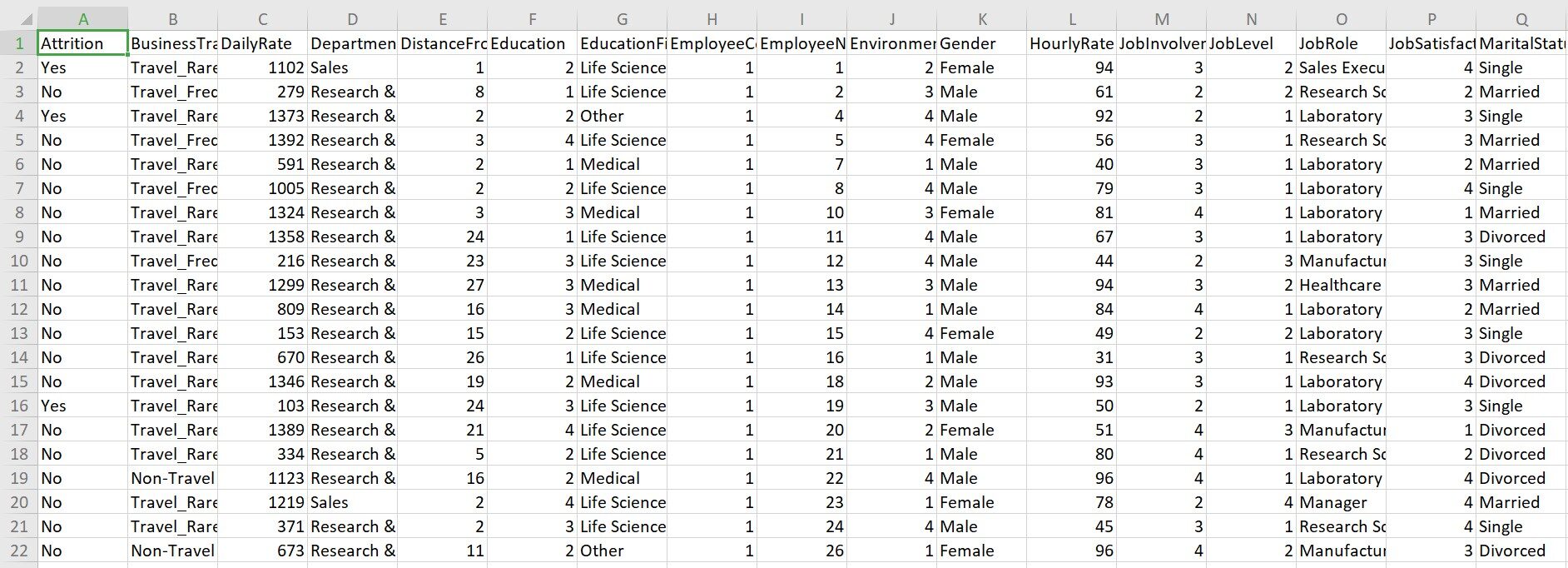
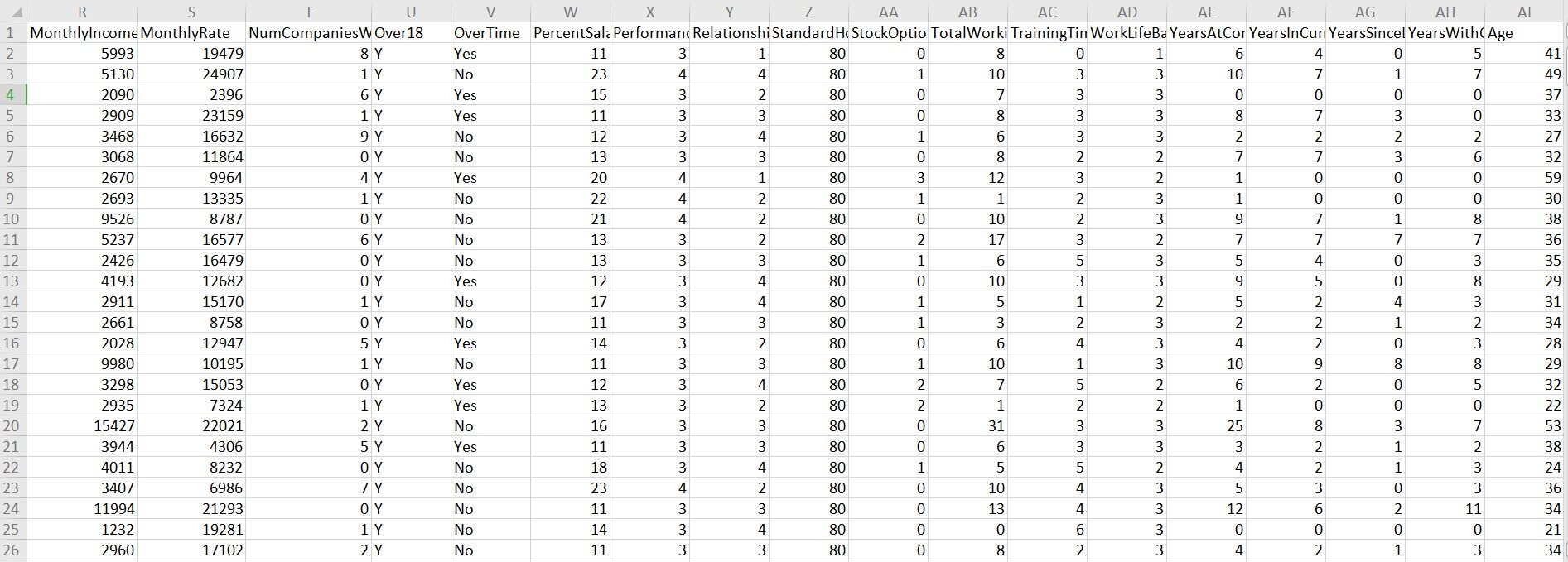
Conferir:
Preparação de dados
-
Alterar tipos de dados:
Em primeiro lugar, temos que mudar o tipo de dados da variável dependente “Desgaste”. É fornecido na forma de "Sim" e "Não", quer dizer, é uma variável categórica. Para fazer um modelo adequado, temos que convertê-lo em forma numérica. Para isso, vamos atribuir o valor 1 para "Sim" e o valor 0 para "Não" e vamos convertê-lo para numérico.
JOB_Attrition $ Attrition[JOB_Attrition $ Attrition =="sim"]=1 JOB_Attrition$Attrition[JOB_Attrition $ Attrition =="Não"]=0 JOB_Attrition$Attrition=as.numeric(JOB_Attrition $ Attrition)
próximo, cambiaremos todas las variables de “carácter” uma “Factor”
Existem 8 variables de carácter: viajes de negocios, departamento, Educação, campo educativo, Gênero sexual, función laboral, Estado civil, a lo largo del tiempo. Los números de columna son 2, 4, 6, 7, 11, 15, 17, 22 respectivamente.
JOB_Attrition[,c(2,4,6,7,11,15,17,22)]=lapply(JOB_Attrition[,c(2,4,6,7,11,15,17,22)],as.fator)
Finalmente, hay otra variable “Más de 18” que tiene todas las entradas como “E”. También es una variable de carácter. Nos transformaremos en numérico ya que solo tiene un nivel por lo que transformar en factor no dará un buen resultado. Para isso, vamos atribuir o valor 1 a “Y” y lo transformaremos en numérico.
JOB_Attrition$Over18[JOB_Attrition$Over18=="E"]=1 JOB_Attrition$Over18=as.numeric(JOB_Attrition$Over18)
Dividir el conjunto de datos en “Treinamento” e “prova”
En cualquier análisis de regresión, tenemos que dividir el conjunto de datos en 2 partes:
- CONJUNTO DE DADOS DE TREINAMENTO
- JUEGO DE DATOS DE PRUEBA
Con la ayuda del conjunto de datos de entrenamiento, crearemos nuestro modelo y probaremos su precisión utilizando el conjunto de datos de prueba.
set.seed(1000) ranuni=sample(x=c("Training","Testing"),size=nrow(JOB_Attrition),replace=T,prob=c(0.7,0.3)) TrainingData=JOB_Attrition[ranuni=="Training",] TestingData=JOB_Attrition[ranuni=="Testing",] agora(TrainingData) agora(TestingData)
Hemos dividido con éxito todo el conjunto de datos en dos partes. Agora temos 1025 Datos de entrenamiento y 445 e depois verifique se o segundo parâmetro tem um valor.
Construyendo el modelo
Ahora vamos a construir el modelo siguiendo unos sencillos pasos como sigue:
- Identificar las variables independientes
- Incorporar la variable dependiente “Desgaste” en el modelo.
- Transformar el tipo de datos del modelo de “carácter” uma “Fórmula”
- Incorporar datos de ENTRENAMIENTO en la fórmula y construir el modelo
independentvariables=colnames(JOB_Attrition[,2:35]) independentvariables Model=paste(independentvariables,collapse="+") Model Model_1=paste("Attrition~",Modelo) Model_1 class(Model_1) formula=as.formula(Model_1) formula
Produção:

Próximo, Incorporaremos “Datos de entrenamiento” en la fórmula usando la función “glm” y construiremos un modelo de regresión logística.
Trainingmodel1=glm(formula=formula,data=TrainingData,familia ="binômio")
Agora, vamos a diseñar el modelo por el “Selección paso a paso”Método para obtener variables significativas del modelo. Executar o código nos dará uma lista de saída onde as variáveis são adicionadas e removidas com base em nossa importância do modelo. O valor do AIC em cada nível reflete a bondade do respectivo modelo. Como o valor continua caindo, um modelo de regressão logística é obtido que se ajusta melhor.
A aplicação do resumo no modelo final nos dará a lista das variáveis significativas finais e suas respectivas informações importantes..
Trainingmodel1 = step(objeto = Trainingmodel1, direction = "Ambas") resumo(Trainingmodel1)
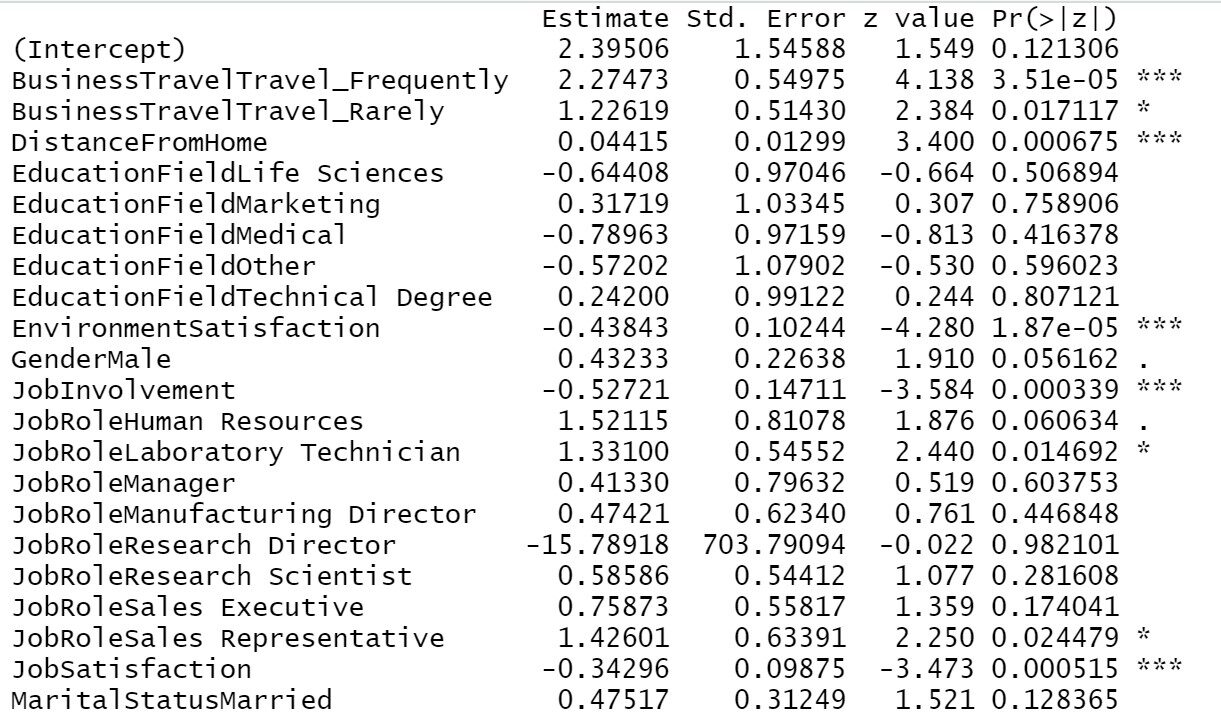
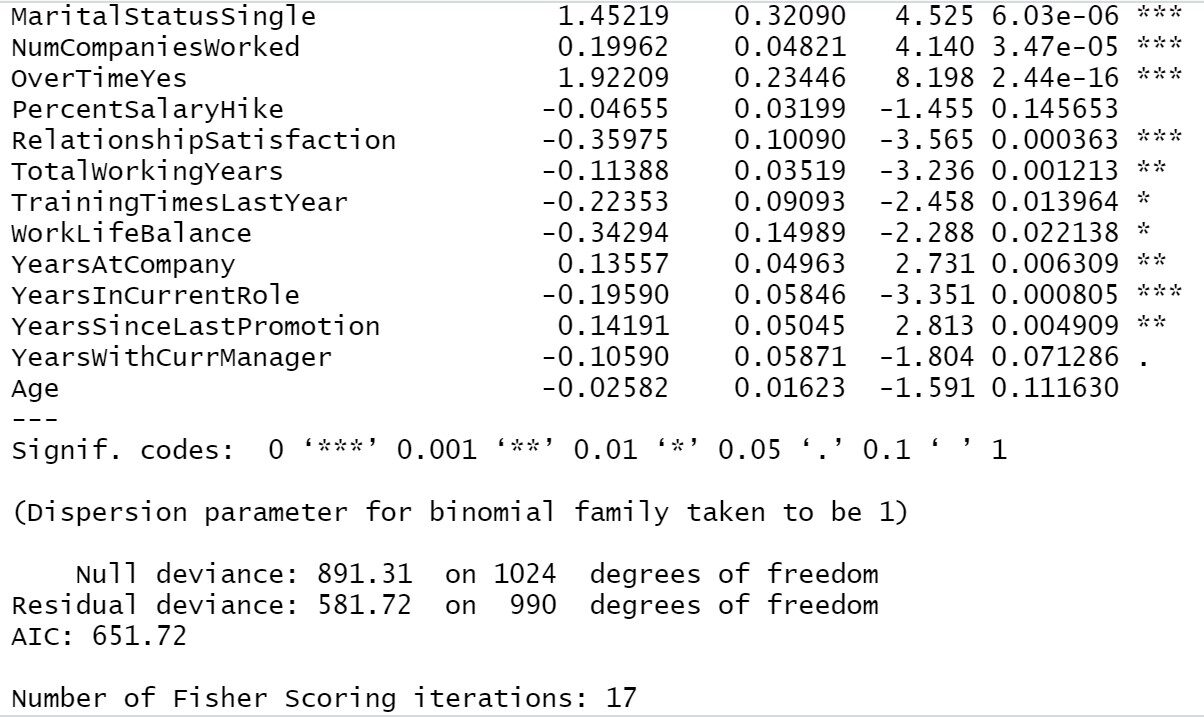
Do nosso resultado anterior, podemos ver, Viagem de negócios, Distância de casa, Satisfação com o meio ambiente, Envolvimento de trabalho, Satisfação no trabalho, Estado civil, Número de empresas trabalhadas, Ao longo do tempo, Satisfação nos relacionamentos, Total de anos de trabalho, Anos na empresa, anos desde a última promoção, anos na posição atual todas essas são as variáveis mais importantes na determinação do desgaste de funcionários. Se a empresa lida principalmente com essas áreas, haverá menos chance de perder um funcionário.
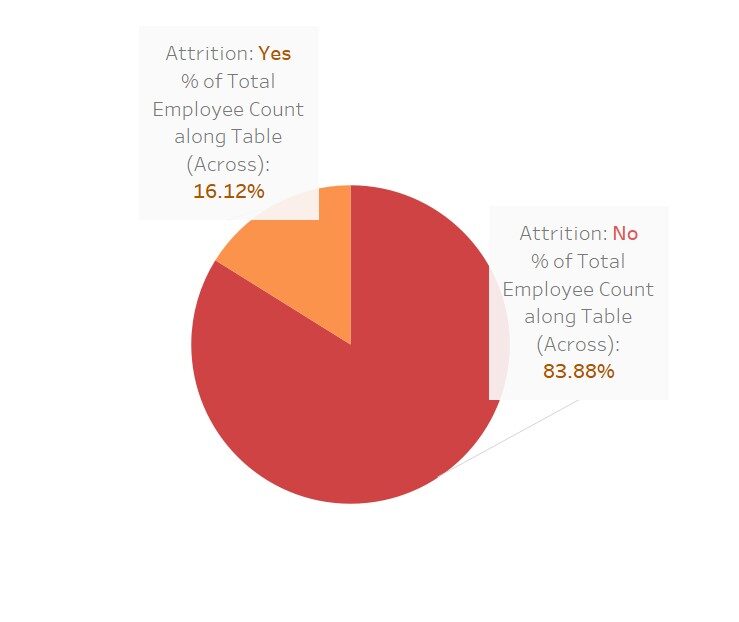
Uma rápida visualização para ver o quanto essas variáveis afetam o “desgaste”
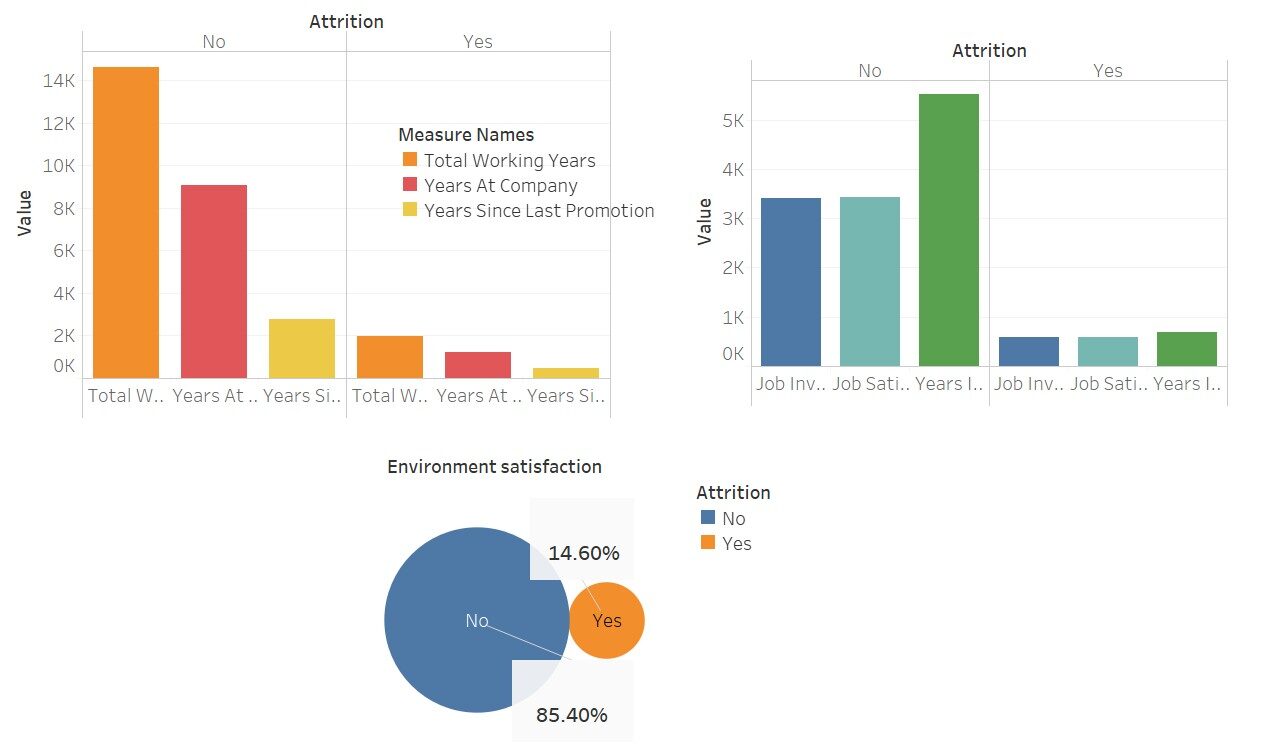
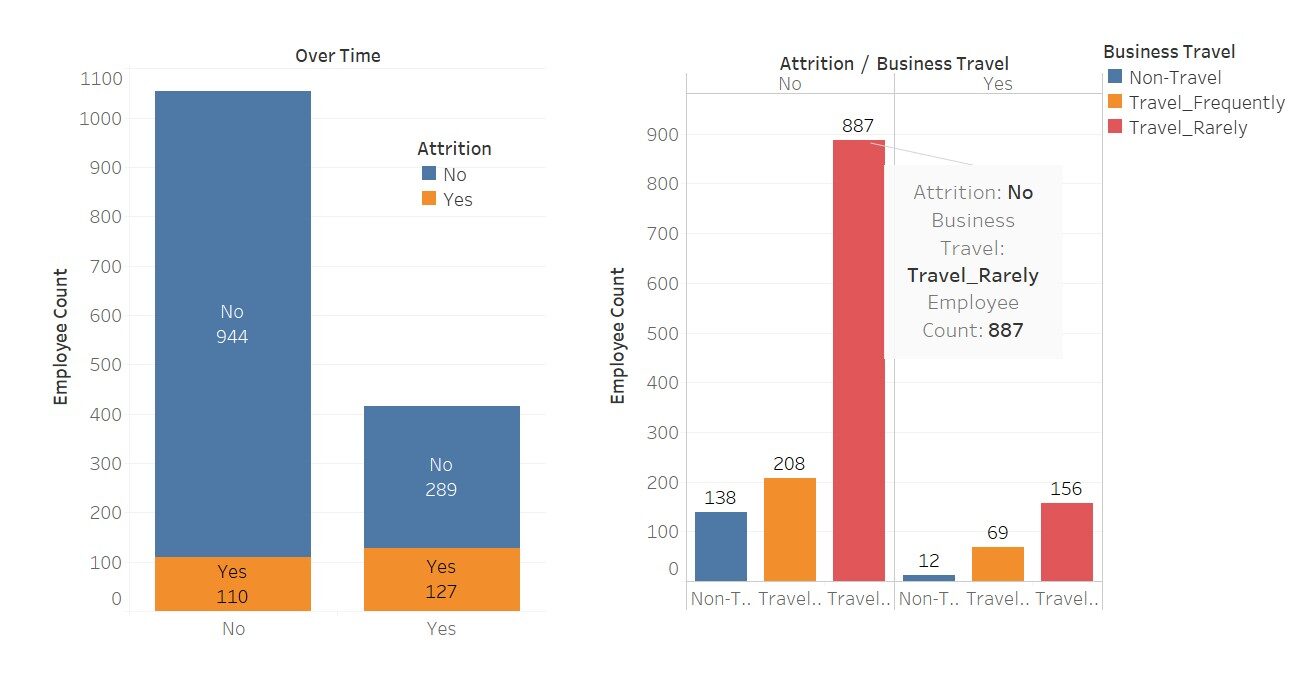
Aqui, usei o Tableau para essas visualizações; não é bonito Este software apenas torna nosso trabalho mais fácil.
Agora, nós podemos perceber o show Hoshmer-Lemes teste de adequação do conjunto de dados, para julgar a precisão da probabilidade prevista do modelo.
A hipótese é:
H0: O modelo se encaixa bem.
H1: O modelo não se encaixa bem.
E, valor p> 0,05 vamos aceitar H0 e rejeitar H1.
Para realizar o teste em R, precisamos instalar o mkMisc pacote.
HLgof.test(fit = Trainingmodel1 $ installed.values,obs = Trainingmodel1 $ y)

Aqui, podemos ver que o valor p é maior do que 0.05, portanto, vamos aceitar H0. Agora, está comprovado que nosso modelo está bem ajustado.
Gerando uma Curva ROC para Dados de Treinamento
Outra técnica para analisar a qualidade do ajuste da regressão logística é o Medidas ROC (características de operação do receptor). Medidas ROC são sensibilidade, especificidade 1, falso positivo e falso negativo. As duas medidas que usamos amplamente são sensibilidade e especificidade.. A sensibilidade mede a qualidade da precisão do modelo, enquanto a especificidade mede a fraqueza do modelo.
Para fazer isso em R, precisamos instalar um pacote pROC.
permuta = rocha(resposta = Trainingmodel1 $ y,preditor = Trainingmodel1 $ fit.values,plot = T) permuta $ auc
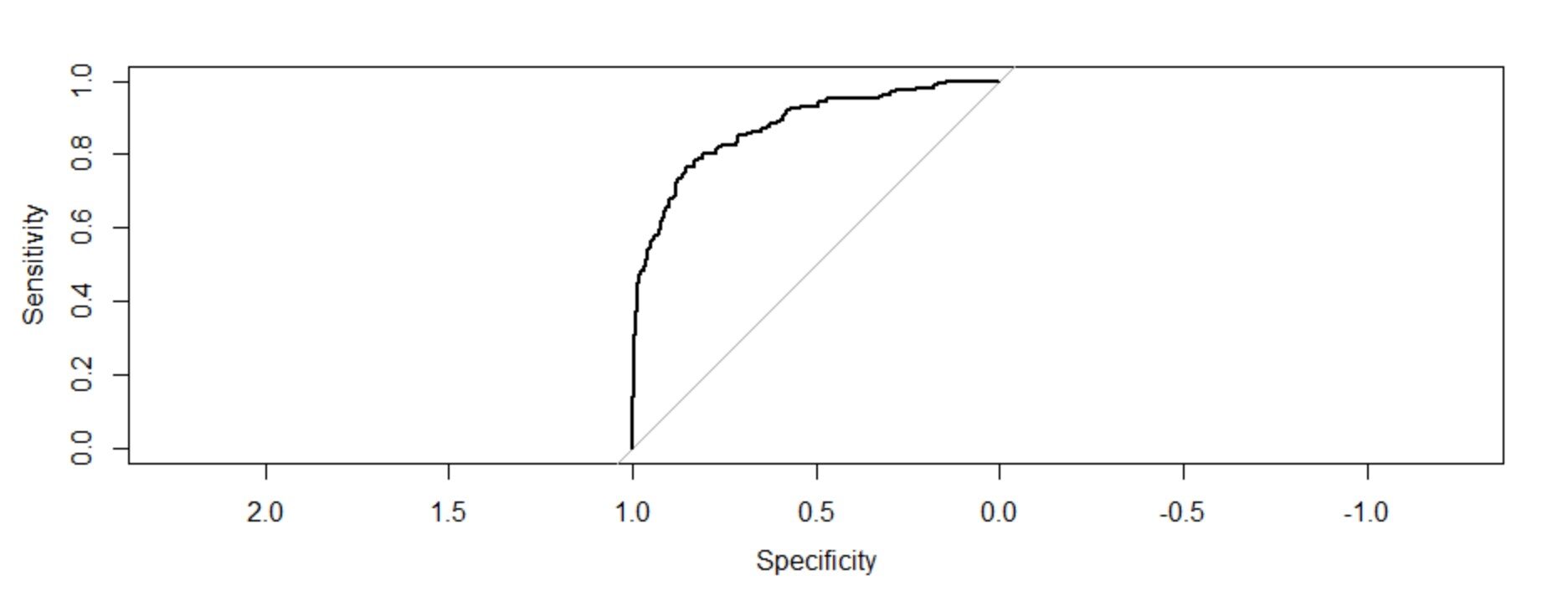
A área sob a curva: 0.8759
Interpretação da figura:
O gráfico dessas duas medições nos dá um gráfico côncavo que mostra como a sensibilidade está aumentando 1 - a especificidade está aumentando, mas em uma taxa decrescente. O valor C (AUC) o o valor do índice de concordância dá a medida da área sob a curva ROC. Se c = 0,5, significaria que o modelo não pode discriminar perfeitamente entre 0 e 1 respostas. Isso implica que o modelo inicial não pode dizer perfeitamente quais funcionários vão sair e quem vão ficar..
Mas aqui podemos ver que nosso valor c é muito maior do que 0.5. Isto é 0,8759. Nosso modelo pode discriminar perfeitamente entre 0 e 1. Portanto, podemos concluir com sucesso que é um modelo bem ajustado.
Criação da tabela de classificação para o conjunto de dados de treinamento:
trpred = ifelse(test = Trainingmodel1 $ installed.values>0.5,sim = 1, não = 0) tabela(Trainingmodel1 $ y,trpred)
Os conjuntos de códigos acima, o valor previsto da probabilidade maior que 0, .5, então o valor do estado é 1, caso contrário, é 0. com base neste critério, este código rotula novamente as respostas “sim” e “Não” a partir de “Desgaste”. Agora, é importante entender a porcentagem de previsões que correspondem à crença inicial obtida a partir do conjunto de dados. Aqui iremos comparar o par (1-1) e (0-0).
Tenho 1025 dados de treinamento. Previmos {(839 + 78) / 1025} * 100 =89% corretamente.
Comparando o resultado com os dados de teste:
Agora vamos comparar o modelo com os dados de teste. É muito parecido com um teste de precisão.
testpred = predict.glm(object=Trainingmodel1,newdata=TestingData,tipo = "resposta") testpred tsroc=roc(response=TestingData$Attrition,predictor = testpred,plot = T) tsroc$auc
Agora, incorporamos dados de teste ao modelo de treinamento e veremos o ROC.
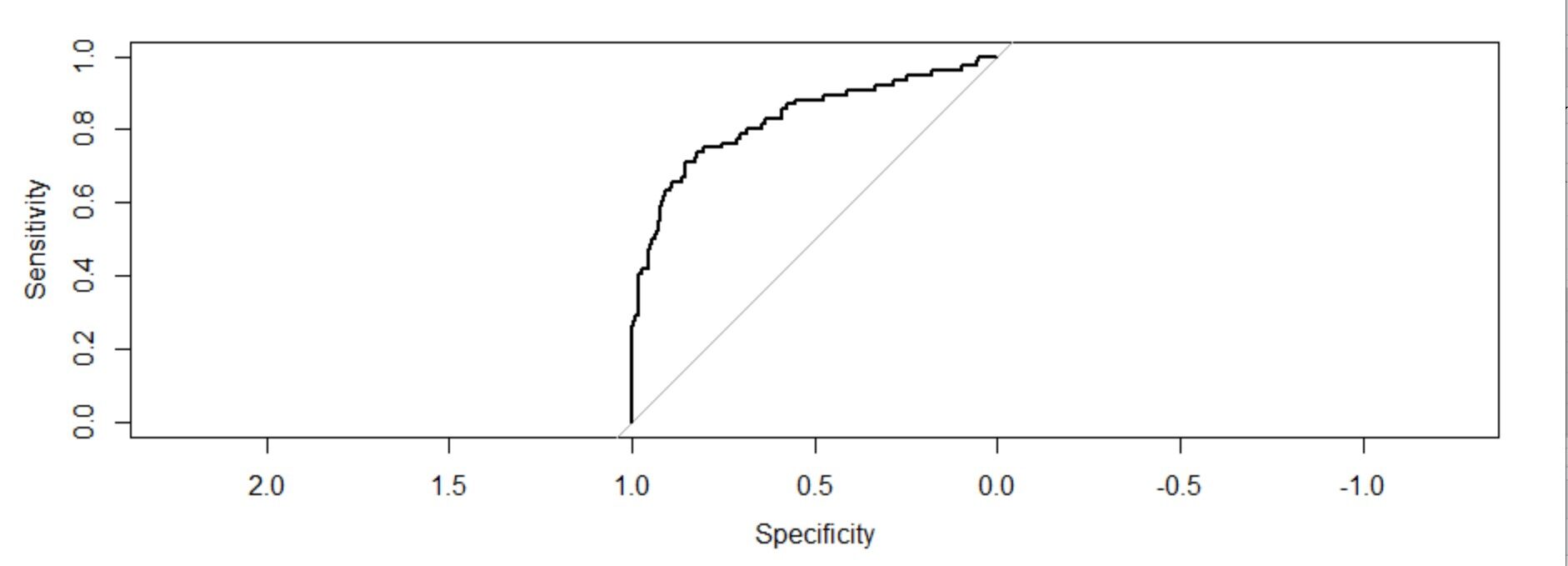
A área sob a curva: 0,8286 (valor c). Também é muito superior a 0,5. Também é um modelo bem ajustado.
Crie a tabela de classificação para o conjunto de dados de teste
testpred = ifelse(test = testpred>0.5,sim = 1, não = 0) tabela(TestingData $ Attrition,testpred)

Tenho 445 dados de teste. nós previmos corretamente {(362 + 28) / 445} * 100 =87,64%.
Como consequência, podemos dizer que nosso modelo de regressão logística é um modelo muito bem ajustado. Qualquer conjunto de dados de atrito de funcionários pode ser analisado usando este modelo.
O que você acha que é um bom modelo? Comente abaixo
CONCLUSÃO:
Aprendemos com sucesso como analisar o atrito de funcionários usando "LOGISTIC REGRESSION" com a ajuda do software R. Apenas com alguns códigos e um conjunto de dados adequado, uma empresa pode entender facilmente quais áreas precisam cuidar para tornar o local de trabalho mais confortável para seus funcionários e restaurar a energia de seus recursos humanos por um período mais longo.
A imagem em destaque foi tirada de trainingjournal.com
Link para meu perfil no LinkedIn:
https://www.linkedin.com/in/tiasa-patra-37287b1b4/





