Visão geral
- Entendendo a arquitetura do Apache ColmeiaHive é uma plataforma de mídia social descentralizada que permite que seus usuários compartilhem conteúdo e se conectem com outras pessoas sem a intervenção de uma autoridade central. Usa a tecnologia blockchain para garantir a segurança e a propriedade dos dados. Ao contrário de outras redes sociais, O Hive permite que os usuários monetizem seu conteúdo por meio de recompensas criptográficas, que incentiva a criação e a troca ativa de informações .... e como funciona.
- Vamos aprender a realizar algumas operações básicas no Apache Hive.
Introdução
A maioria dos cientistas de dados usa consultas SQL para explorar os dados e obter insights a partir deles.. Agora, uma vez que o volume de dados está crescendo a uma taxa tão alta, precisamos de novas ferramentas dedicadas para lidar com grandes volumes de dados.
Inicialmente, O Hadoop surgiu e se tornou uma das ferramentas mais populares para processamento e armazenamento de big data. Mas os desenvolvedores tiveram que escrever um código de redução de mapa complexo para trabalhar com o Hadoop. Este é o Apache Hive do Facebook que veio para resgatar. É outra ferramenta projetada para funcionar com Hadoop. Podemos escrever consultas semelhantes a SQL no hive e no back-end ele as converte em tarefas de redução de mapa.

Neste artigo, veremos a arquitetura da colmeia e seu funcionamento. Também aprenderemos como realizar operações simples, como criar um base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... e uma mesa, Carregar dados, modificar a mesa.
Tabela de conteúdo
- O que é Apache Hive?
- Arquitectura Apache Hive
- Trabalho do Apache Hive
- Tipos de dados no Apache Hive
- Criar e excluir banco de dados
- Criar e eliminar tabela
- Carregar dados na tabela
- Modificar tabela
- Vantagem / Desvantagens do Hive
O que é Apache Hive?
![]()
Apache Hive é um sistema de armazenamento de dados desenvolvido pelo Facebook para processar uma grande quantidade de dados de estrutura no Hadoop. Sabemos que para processar os dados usando Hadoop, precisamos consertar funções complexas de redução de mapa, o que não é uma tarefa fácil para a maioria dos desenvolvedores. O Hive torna esse trabalho muito fácil para nós.
Ele usa uma linguagem de script chamada HiveQL, que é quase semelhante ao SQL. Então, só temos que escrever comandos do tipo SQL e no backend do Hive ele os converterá automaticamente em tarefas de redução de mapa.
Arquitectura Apache Hive
Vamos dar uma olhada no diagrama a seguir, mostrando a arquitetura.
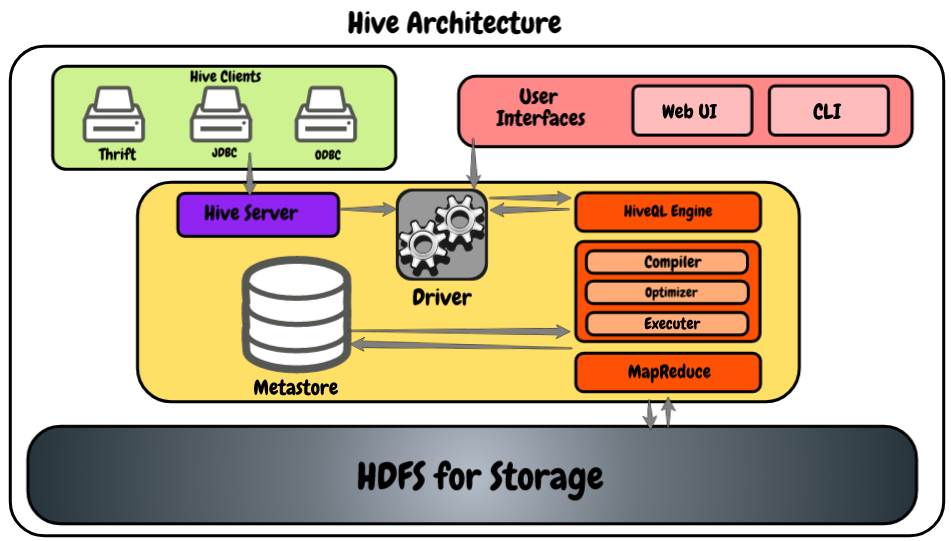
- Clientes Hive: Ele nos permite escrever aplicativos Hive usando diferentes tipos de clientes, como o servidor de salvamento, o driver JDBC para aplicativos Java e Hive, e também é compatível com aplicativos que usam o protocolo ODBC.
- Serviços de colmeia: Como desenvolvedor, se quisermos processar quaisquer dados, precisamos usar serviços Hive como Hive CLI (Interface da Linha de comando). Além daquela colmeia, também fornece uma interface baseada na web para executar os aplicativos Hive.
- Hive driver: É capaz de receber consultas de vários recursos como thrift, JDBC e ODBS usando servidor hive e diretamente do hive CLI e interface de usuário baseada na web. Depois de receber perguntas, transfere-os para o compilador.
- Motor HiveQL: Recebe a consulta do compilador e converte a consulta semelhante a SQL em trabalhos de redução de mapa.
- Meta store: Aqui, o Hive armazena as metainformações sobre os bancos de dados como o esquema da tabela, os tipos de dados das colunas, localização no HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações.., etc.
- HDFS: É simplesmente o Sistema de arquivos distribuídoUm sistema de arquivos distribuído (DFS) Permite armazenamento e acesso a dados em vários servidores, facilitando o gerenciamento de grandes volumes de informações. Esse tipo de sistema melhora a disponibilidade e a redundância, à medida que os arquivos são replicados para locais diferentes, Reduzindo o risco de perda de dados. O que mais, Permite que os usuários acessem arquivos de diferentes plataformas e dispositivos, promovendo colaboração e... que é usado para armazenar os dados. Eu recomendo fortemente que você leia este artigo para aprender mais sobre HDFS: Introdução ao ecossistema Hadoop
Trabalho do Apache Hive
Agora, Vamos dar uma olhada em como o Hive funciona na estrutura do Hadoop.
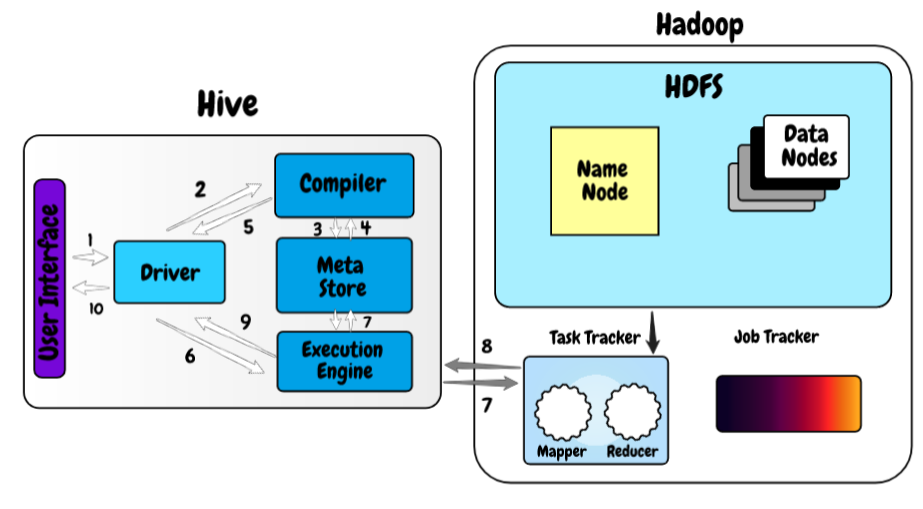
- Na primeira etapa, escrevemos a consulta usando a interface da web ou a interface de linha de comando do hive. Envia para o controlador para executar a consulta.
- Na próxima etapa, o controlador envia a consulta recebida para o compilador onde o compilador verifica a sintaxe.
- E uma vez que a verificação de sintaxe é feita, solicitar metadados de meta store.
- Agora, metadados fornecem informações como o banco de dados, Pranchas, tipos de dados da coluna em resposta à consulta do compilador.
- O compilador verifica novamente todos os requisitos recebidos do meta store e envia o plano de execução para o controlador.
- Agora, o controlador envia o plano de execução para o mecanismo de processo HiveQL, onde o motor converte a consulta no trabalho de redução de mapa.
- Uma vez que a consulta se torna o trabalho de redução de mapa, envia as informações da tarefa para o Hadoop, onde o processamento da consulta começa e, ao mesmo tempo, atualiza metadados sobre o trabalho de redução de mapa em meta store.
- Assim que o processamento estiver concluído, o tempo de execução recebe os resultados da consulta.
- O tempo de execução transfere os resultados para o controlador e, Finalmente, os envia para a interface do usuário do hive, de onde podemos ver os resultados.
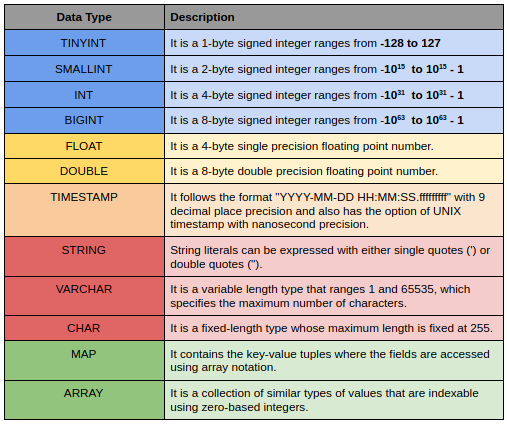
Tipos de dados no Apache Hive
Os tipos de dados do Hive são divididos nos seguintes 5 categorias diferentes:
- Tipo numérico: TINYINT, PEQUENO, INT, BIGINT
- Tipos de data / hora: HORA, ENCONTRO, INTERVALO
- Tipos de cordas: FRAGMENTO, VARCHAR, CARACTERES
- Tipos complexos: ESTRUTURA, MAPA, UNIÃO, VARIEDADE
- Tipos diversos: BOOLEO, TRILHAS
Aqui está uma pequena descrição de alguns deles.
Criar e excluir banco de dados
Criar e excluir um banco de dados é muito simples e semelhante ao SQL. Precisamos atribuir um nome exclusivo para cada um dos bancos de dados da colmeia. Se o banco de dados já existe, irá mostrar um aviso e para suprimir este aviso você pode adicionar as palavras-chave SE NÃO EXISTIR depois da palavra-chave do banco de dados.
CRIAR BASE DE DADOS <<nome do banco de dados>> ;
Excluir um banco de dados também é muito simples, você só precisa escrever um excluir banco de dados e nome do banco de dados ser abandonado. Se você tentar deletar o banco de dados que não existe, apresentará o erro SemanticException.
DROP DATABASE <<nome do banco de dados>> ;
Criar a tabela
Usamos a instrução create table para criar uma tabela e a sintaxe completa é a seguinte.
CRIAR TABELA SE NÃO EXISTIR <<nome do banco de dados.>><<Nome da tabela>>
(column_name_1 data_type_1,
column_name_2 data_type_2,
.
.
column_name_n data_type_n)
ROW FORMAT DELIMITED FIELDS
TERMINATED BY 't'
LINES TERMINATED BY 'n'
STORED AS TEXTFILE;
Se você já está usando o banco de dados, você não precisa digitar nombre_base_datos.table_name. Nesse caso, você só pode digitar o nome da tabela. No caso do Big Data, na maioria das vezes importamos os dados de arquivos externos para que aqui possamos predefinar o delimitador usado no arquivo, exterminador de linha e também podemos definir como queremos armazenar a mesa.
Existem 2 diferentes tipos de tabelas de colmeias tabelas internas e externas. Confira este artigo para saber mais sobre o conceito: Tipos de tabela no Apache Hive: uma visão geral rápida
Carregar dados na tabela
Agora, as tabelas foram criadas. É hora de carregar os dados nele. Podemos carregar os dados de qualquer arquivo local em nosso sistema usando a seguinte sintaxe.
CARREGAR DADOS LOCAL DE ENTRADA <<caminho do arquivo em seu sistema local>>
NA MESA
<<nome do banco de dados.>><<Nome da tabela>> ;
Quando trabalhamos com uma grande quantidade de dados, existe a possibilidade de haver tipos de dados incomparáveis em algumas das linhas. Nesse caso, a colmeia não lançará nenhum erro, em vez disso, ele preencherá valores nulos. Este é um recurso muito útil, pois o upload de arquivos de big data para o hive é um processo caro e não queremos fazer o upload do conjunto de dados completo apenas porque temos poucos arquivos.
Modificar tabela
Na colmeia, podemos fazer várias modificações nas tabelas existentes, como renomear tabelas, adicionar mais colunas à mesa. comandos para modificar a tabela são muito semelhantes a comandos sql.
Aqui está a sintaxe para renomear a tabela:
ALTER TABLE <<Nome da tabela>> RENOMEAR PARA <<new_name>> ;
Sintaxe para adicionar mais colunas na tabela:
## to add more columns
ALTER TABLE <<Nome da tabela>> ADICIONAR COLUNAS
(new_column_name_1 data_type_1,
new_column_name_2 data_type_2,
.
.
new_column_name_n data_type_n) ;
Vantagem / desvantagens da Colmeia Apache
- Usa SQL como uma linguagem de consulta que já é familiar para a maioria dos desenvolvedores, por isso facilita seu uso.
- É altamente escalável, você pode usá-lo para processar qualquer tamanho de dados.
- Suporta vários bancos de dados, como o MySQL, clássico, Postgres e Oracle para sua loja de metadados.
- Suporta vários formatos de dados e também permite a indexação, partição e grupo para otimizar consultas.
- Ele só pode lidar com dados frios e é inútil quando se trata de processamento de dados em tempo real.
- É comparativamente mais lento do que alguns de seus concorrentes. Se o seu caso de uso é principalmente sobre processamento em lote, Hive está bem.
Notas finais
Neste artigo, Vimos a arquitetura Apache Hive e como ela funciona e algumas das operações básicas para começar. No próximo artigo desta série, Veremos alguns dos conceitos mais complexos e importantes de particionamento e agrupamentoo "agrupamento" É um conceito que se refere à organização de elementos ou indivíduos em grupos com características ou objetivos comuns. Este processo é usado em várias disciplinas, incluindo psicologia, Educação e biologia, para facilitar a análise e compreensão de comportamentos ou fenômenos. No campo educacional, por exemplo, O agrupamento pode melhorar a interação e o aprendizado entre os alunos, incentivando o trabalho.. Em uma colmeia.
Se você tiver alguma dúvida relacionada a este artigo, Me avise na seção de comentários abaixo.





