Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
Isso tem funcionado convencionalmente com o plano de negócios e as novas tendências. Com o advento da ciência de dados e aprendizado de máquina, Diversas abordagens de pesquisa foram projetadas para automatizar este processo manual. Este processo de negociação automatizado ajudará a dar sugestões na hora certa com cálculos melhores.. Uma estratégia de negociação automatizada que oferece lucro máximo é altamente desejável para fundos mútuos e fundos de hedge.. O tipo de retorno lucrativo esperado terá algum risco potencial. Projetar uma estratégia de negociação automatizada lucrativa é uma tarefa complexa.
Todo ser humano quer ganhar seu potencial máximo no mercado de ações. É muito importante projetar uma estratégia equilibrada e de baixo risco que possa beneficiar a maioria das pessoas.. Uno de estos enfoques habla sobre el uso de agentes de Aprendizado por reforçoO aprendizado por reforço é uma técnica de inteligência artificial que permite que um agente aprenda a tomar decisões interagindo com um ambiente. Por meio de feedback na forma de recompensas ou punições, O agente otimiza seu comportamento para maximizar as recompensas acumuladas. Essa abordagem é usada em uma variedade de aplicações, De videogames a robótica e sistemas de recomendação, destacando-se por sua capacidade de aprender estratégias complexas.... para proporcionarnos estrategias comerciales automatizadas basadas en datos históricos.
Aprendizagem reforçada
Aprendizagem por reforço é um tipo de aprendizagem de máquina em que existem ambientes e agentes. Esses agentes realizam ações para maximizar as recompensas. O aprendizado por reforço tem um potencial enorme quando usado para simulações para treinar um modelo de IA. Não há tag associada a nenhum dado, o aprendizado por reforço pode aprender melhor com muito poucos pontos de dados. Todas as decisões, neste caso, são tomadas sequencialmente. O melhor exemplo seria encontrado em Robótica e Jogos.
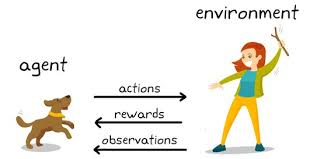
Q – Aprendendo
Q-learning é um algoritmo de aprendizagem por reforço sem modelo. Informa o agente sobre a ação a ser tomada com base nas circunstâncias. É um método baseado em valor que é usado para fornecer informações a um agente para uma ação iminente. É considerado um algoritmo fora da política, uma vez que a função q-learning aprende com ações que estão fora da política atual, como realizar ações aleatórias e, portanto, nenhuma política necessária.
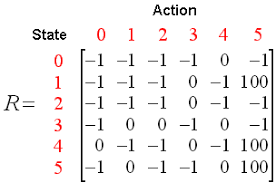
Q aqui significa qualidade. Qualidade refere-se à qualidade da ação e até que ponto essa recompensa será benéfica com base na ação realizada.. Uma tabela Q com dimensões é criada [Estado,açao]Um agente interage com o ambiente de duas maneiras: explodir e explorar. Uma opção de exploração sugere que todas as ações sejam consideradas e aquela que dê mais valor ao meio ambiente seja realizada. Uma opção de exploração é aquela em que uma ação aleatória é considerada sem considerar a recompensa futura máxima.

Q de st e at é representado por uma fórmula que calcula a recompensa futura máxima com desconto quando uma ação é realizada em um estado s.
La función definida nos proporcionará la recompensa máxima al final del número n de ciclos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... o iteraciones.
A negociação pode ter as seguintes chamadas: comprar, vender ou segurar
O Q-learning avaliará cada uma das ações e aquela com o valor máximo será selecionada. O Q-Learning é baseado na aprendizagem dos valores da mesa Q. Funciona bem sem os recursos de recompensa e probabilidades de transição de estado.
Aprendizagem reforçada na negociação de ações
A aprendizagem por reforço pode resolver vários tipos de problemas. El comercio es una tarea continua sin ningún punto final. La negociación también es un proceso de decisión de Markov parcialmente observable, ya que no tenemos información completa sobre los comerciantes en el mercado. Como no conocemos la función de recompensa y la probabilidad de transición, utilizamos el aprendizaje por refuerzo sin modelo, que es Q-Learning.
Pasos para ejecutar un agente de RL:
-
Instalar bibliotecas
-
Obtenha os dados
-
Definir el agente de Q-Learning
-
Treine o agente
-
Prueba al agente
-
Trazar las señales
Instalar bibliotecas
Instale e importe las bibliotecas de finanzas necesarias de NumPy, pandas, matplotlib, seaborn y yahoo.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set() !pip install yfinance --upgrade --no-cache-dir from pandas_datareader import data as pdr import fix_yahoo_finance as yf from collections import deque import random Import tensorflow.compat.v1 as tf tf.compat.v1.disable_eager_execution()
Obtenha os dados
Utilice la biblioteca de Yahoo Finance para obtener los datos de una acción en particular. Las acciones utilizadas aquí para nuestro análisis son las acciones de Infosys.
yf.pdr_override() df_full = pdr.get_data_yahoo("INFY", start ="2018-01-01").reset_index() df_full.to_csv(‘INFY.csv',index = False) df_full.head()
Este código creará un marco de datos llamado df_full que contendrá los precios de las acciones de INFY en el transcurso de 2 anos.
Definir el agente de Q-Learning
La primera función es la clase Agente define el tamaño del estado, tamaño de la ventana, Tamanho do lote, deque que es la memoria utilizada, inventario como una lista. Defina também algumas variáveis estáticas como épsilon, decair, gama, etc. Se definen dos capas de neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. para la compra, reter e vender chamadas. GradientDescentOptimizer também é usado.
O Agente definiu funções para opções de chamada e venda. A função get_state e act faz uso da rede neural para gerar o próximo estado da rede neural. As recompensas são subsequentemente calculadas adicionando ou subtraindo o valor gerado pela execução da opção de chamada. A ação realizada no próximo estado é influenciada pela ação realizada no estado anterior. 1 refere-se a uma chamada de compra, enquanto que 2 refere-se a uma chamada de vendas. Em cada iteração, el estado se determina sobre la base del cual se toma una acción que comprará o venderá algunas acciones. Las recompensas generales se almacenan en la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de beneficio total.
df= df_full.copy() nome ="Q-learning agent" class Agent: def __init__(auto, state_size, window_size, tendência, skip, tamanho do batch): self.state_size = state_size self.window_size = window_size self.half_window = window_size // 2 self.trend = trend self.skip = skip self.action_size = 3 self.batch_size = batch_size self.memory = deque(maxlen = 1000) auto.inventário = [] self.gamma = 0.95 self.epsilon = 0.5 self.epsilon_min = 0.01 self.epsilon_decay = 0.999 tf.reset_default_graph() self.sess = tf.InteractiveSession() self.X = tf.placeholder(tf.float32, [Nenhum, self.state_size]) self.Y = tf.placeholder(tf.float32, [Nenhum, self.action_size]) feed = tf.layers.dense(self.X, 256, activation = tf.nn.relu) self.logits = tf.layers.dense(feed, self.action_size) self.cost = tf.reduce_mean(tf.square(self.Y - self.logits)) self.optimizer = tf.train.GradientDescentOptimizer(1e-5).minimize( self.cost ) self.sess.run(tf.global_variables_initializer()) def act(auto, Estado): if random.random() <= self.epsilon: retorno aleatório.randrange(self.action_size) retorno np.argmax( self.sess.run(self.logits, feed_dict = {self.X: Estado})[0] ) def get_state(auto, t): window_size = self.window_size + 1 d = t - window_size + 1 block = self.trend[d : t + 1] se d >= 0 outra coisa -d * [self.trend[0]] + self.trend[0 : t + 1] res = [] para eu no alcance(window_size - 1): res.append(bloquear[eu + 1] - bloquear[eu]) retorno np.array([res]) def replay(auto, tamanho do batch): mini_batch = [] l = len(auto.memória) para eu no alcance(eu - tamanho do batch, eu): mini_batch.append(auto.memória[eu]) replay_size = len(mini_batch) X = np.empty((replay_size, self.state_size)) Y = np.empty((replay_size, self.action_size)) states = np.array([uma[0][0] for a in mini_batch]) new_states = np.array([uma[3][0] for a in mini_batch]) Q = self.sess.run(self.logits, feed_dict = {self.X: estados}) Q_new = self.sess.run(self.logits, feed_dict = {self.X: new_states}) para eu no alcance(len(mini_batch)): Estado, açao, recompensa, next_state, done = mini_batch[eu] target = Q[eu] alvo[açao] = reward if not done: alvo[açao] += self.gamma * np.amax(Q_new[eu]) X[eu] = state Y[eu] = target cost, _ = self.sess.run( [self.cost, self.optimizer], feed_dict = {self.X: X, self.Y: E} ) se self.epsilon > self.epsilon_min: self.epsilon *= self.epsilon_decay return cost def buy(auto, initial_money): starting_money = initial_money states_sell = [] states_buy = [] inventory = [] state = self.get_state(0) para t no intervalo(0, len(self.trend) - 1, self.skip): action = self.act(Estado) next_state = self.get_state(t + 1) se a ação == 1 and initial_money >= self.trend inventory.append(self.trend initial_money -= self.trend states_buy.append print('day %d: comprar 1 unit at price %f, total balance %f'% (t, self.trend elif action == 2 e len(inventory): bought_price = inventory.pop(0) initial_money += self.trend states_sell.append try: invest = ((close except: invest = 0 imprimir( 'day %d, sell 1 unit at price %f, investment %f %%, total balance %f,' % (t, close ) state = next_state invest = ((initial_money - starting_money) / starting_money) * 100 total_gains = initial_money - starting_money return states_buy, states_sell, total_gains, invest def train(auto, Iterações, Ponto de verificação, initial_money): para eu no alcance(Iterações): total_profit = 0 inventory = [] state = self.get_state(0) starting_money = initial_money for t in range(0, len(self.trend) - 1, self.skip): action = self.act(Estado) next_state = self.get_state(t + 1) se a ação == 1 and starting_money >= self.trend inventory.append(self.trend starting_money -= self.trend elif action == 2 e len(inventory) > 0: bought_price = inventory.pop(0) total_profit += self.trend starting_money += self.trend invest = ((starting_money - initial_money) / initial_money) self.memory.append((Estado, açao, invest, next_state, starting_money < initial_money)) state = next_state batch_size = min(self.batch_size, len(auto.memória)) cost = self.replay(tamanho do batch) E se (i+1) % checkpoint == 0: imprimir('epoch: %d, total rewards: %f.3, custar: %f, total money: %f'%(eu + 1, total_profit, custar, starting_money))
Treine o agente
Una vez definido el agente, inicialícelo. Especifique el número de iteraciones, dinero inicial, etc. para capacitar al agente para que decida las opciones de compra o venta.
close = df.Close.values.tolist() initial_money = 10000 window_size = 30 skip = 1 batch_size = 32 agente = Agente(state_size = window_size, window_size = window_size, trend = close, skip = skip, batch_size = batch_size) agent.train(iterações = 200, checkpoint = 10, initial_money = initial_money)
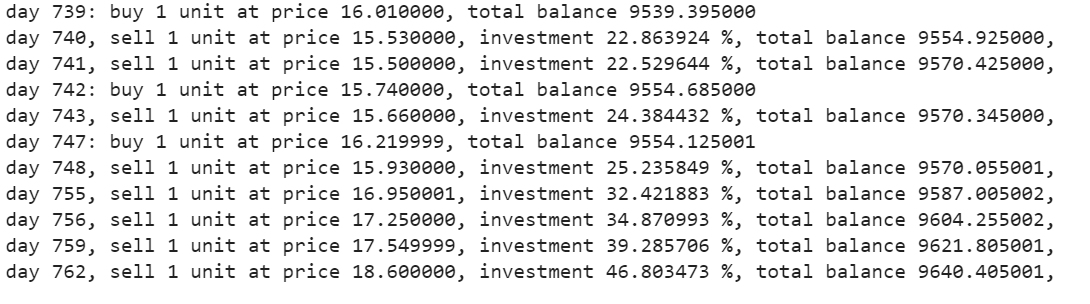
Produção –

Prueba al agente
La función de compra devolverá las cifras de compra, oferta, lucro e investimento.
estados_comprar, states_sell, total_gains, invest = agent.buy(initial_money = initial_money)
Rastrear chamadas
Traçar ganhos totais versus valores investidos. Todas as opções de compra e venda foram devidamente marcadas de acordo com as opções de compra / venda sugerida por rede neural.
fig = plt.figure(figsize = (15,5)) plt.plot(close, color ="r", lw = 2.) plt.plot(close, '^', markersize = 10, color ="m", rótulo ="sinal de compra", markevery = states_buy) plt.plot(close, 'v', markersize = 10, color ="k", rótulo ="sinal de venda", markevery = states_sell) plt.title('ganhos totais% f, investimento total% f %% '%(total_gains, invest)) plt.legend() plt.savefig(nome + '. png') plt.show()
Produção –
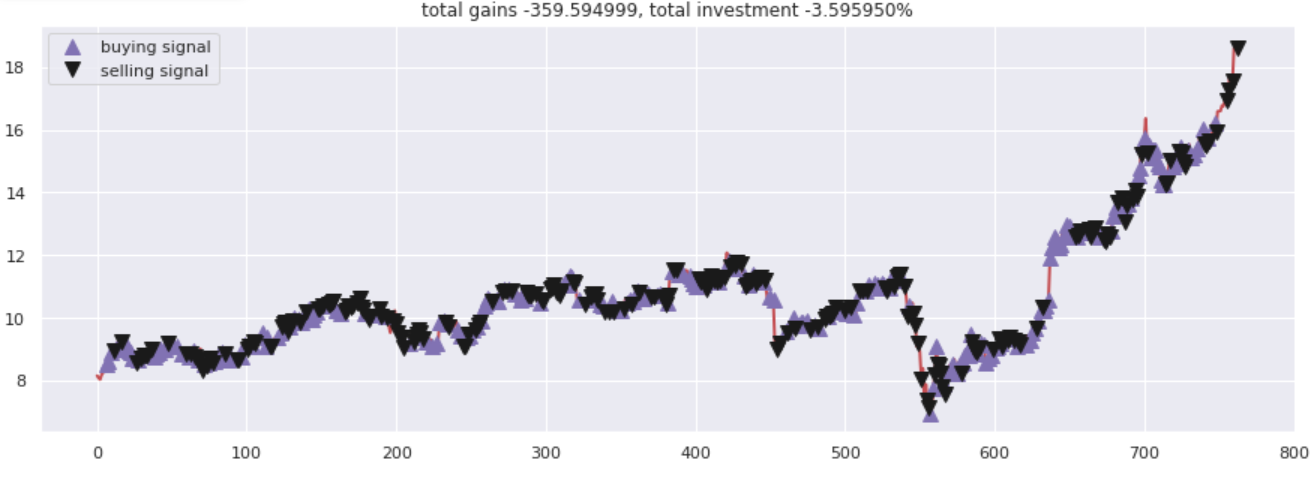
Notas finais
Q-Learning é uma técnica que o ajuda a desenvolver uma estratégia de negociação automatizada. Pode ser usado para experimentar opções de compra ou venda. Existem muitos outros agentes de aprendizagem por reforço comerciais para experimentar. Tente brincar com os diferentes tipos de agentes RL com ações diferentes.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





