Este artigo foi publicado como parte do Data Science Blogathon
Introdução
CSV isto é um típico formato de arquivo quer dizer frequentemente usado em domínios como METROOnetario Serviços, etc. A maioria dos aplicativos poderia permitir você para importar e exportar conhecimento em formato CSV.
Portanto, isto é necessário induzir um bom entendimento do formato CSV para um driver superior os dados você está usar com cotidiano.
Então, ao longo de Este artigo, veremos vários casos de operativo com arquivos CSV e fornecer exemplos para vincular tudo ao longo de.
Tabela de conteúdo
1. O que é CSV?
2. Operações básicas com arquivos CSV
- Trabalhe com arquivos CSV
- Abra um arquivo CSV
- Salvar um arquivo CSV
3. Por que arquivos CSV?
4. Read_csv Function Basics () por Pandas
- Importação de pandas
- Abra um arquivo CSV local
- Abra um arquivo CSV de um URL
5. Compreenda os parâmetros da função read_csv ()
- parâmetro sep
- parâmetro index_col
- parâmetro de cabeçalho
- parâmetro use_cols
- parâmetro de compressão
- parâmetro skiprows
- parâmetro nrows
- parâmetro de codificação
- parâmetro error_bad_lines
- parâmetro dtype
- parâmetro parse_dates
- parâmetro de conversores
- parâmetro na_values
Comecemos,
O que é um CSV?
CSV (Valores Separados Por Virgula) talvez um formato de arquivo simples usado para armazenar dados tabulares, igual que uma planilha ou um banco de dados. Arquivo CSV armazena dados tabulares (números e texto) em texto simples. Cada linha do arquivo poderia ser um registro de dados. Cada registro consiste a partir de 1 ou mais campos, separados por vírgulas, utilização vírgula como separador de campo é esse o fonte do nome para este formato de arquivo.
Operações básicas com arquivos CSV
Em Operações Básicas, vamos entender as três coisas a seguir:
- Como trabalhar com arquivos CSV
- Como abrir um arquivo CSV
- Como salvar um arquivo CSV
Trabalhe com arquivos CSV
Trabalhe com arquivos CSV não é aquela tarefa tediosa, mas é bastante simples. Porém, contando com seu fluxo de trabalho, lá Você pode se tornar advertências que simplesmente você pode querer para observar Sair para.
Abra um arquivo CSV
E você tem um arquivo CSV, tu abra-o no excel sem muitos problemas. Basta abrir o Excel, aberto e encontre o arquivo CSV descobrir com (ou clique com o botão direito no arquivo CSV e escolha Abrir no Excel). Depois de abrir o arquivo, você vai notar que a informação é simples texto simples em células diferentes.
Salvar um arquivo CSV
E você deseja para salvar muito sua pasta de trabalho atual em um arquivo CSV, você tem usar o posterior comandos:
Arquivo -> Salvar como … e escolha o arquivo CSV.
A maioria das vezes, você receberá este aviso:

Fonte da imagem: Imagens do google
Vamos entender o que esse erro está nos dizendo.
Aqui o Excel está tentando mencionar é que seus arquivos CSV não salvam nenhum razoável formatação no mínimo.
Por exemplo, As larguras das colunas não serão salvas, estilos de fonte, as cores, etc.
Apenas seus dados antigos estão salvou em um excessivamente arquivo separado por vírgula.
Observe que mesmo depois de você coloque de lado, O Excel continuará a mostrar os formatos que você sozinho eu tive, então não se deixe enganar por isso e pense que depois de abrir a pasta de trabalho novamente que seus formatos ainda estarão lá. Eles não serão.
Mesmo depois de abrir um CSV Entre Excel, se você aplicar um formato suficiente no mínimo, como ajustar a largura das colunas fazer exercício a informação, O Excel ainda irá avisá-lo que você sozinho Não consigo salvar os formatos que você sozinho adicional, tu receba um aviso como este:

Fonte da imagem: Imagens do google
Então, o objetivo usa quer dizer seus formatos nunca podem ser salvos em arquivos CSV.
Por que arquivos CSV?
Arquivos CSV são usados como a maneira mais simples falar dados entre diferentes aplicativos. Suponha que você tenha um aplicativo de banco de dados e deseja exportar a informação para um arquivo. E você deseja para exportá-lo para um arquivo Excel, o aplicativo de banco de dados faria suporta exportação para arquivos XLS *.
Porém, já que o formato de arquivo CSV é extremamente simples e luz (Muito de Muito de portanto do que arquivos XLS *), é mais fácil para variado aplicativos para apoiá-lo. Em seu uso básico, tem uma linha de texto, com cada coluna De dados e maneiras alternativas para uma vírgula. Isso é tudo. E por causa dessa simplicidade, é simples para desenvolvedores. para fazer Exportar importar sentido prático com arquivos CSV para transferir conhecimento entre aplicativos ao invés de Muito de sofisticado formatos de arquivo.
Por exemplo,
Vamos ter um dados tabulados na forma abaixo:

Se convertermos esses dados em um Formato CSV, então fica assim:

Agora, terminamos com todos os fundamentos dos arquivos CSV. Então, na parte de trás do item, discutiremos como trabalhar com arquivos CSV em detalhes.
Importação de pandas
Em primeiro lugar, importamos as dependências necessárias como Pandas Biblioteca Python.
importar pandas como pd
Então, dependência é importada, agora podemos carregar e ler o conjunto de dados facilmente.
função read-csv
- É uma função importante do pandas ler arquivos CSV e realizar operações neles.
- Esta função nos ajuda a carregar o arquivo de sua máquina local ou de qualquer URL.
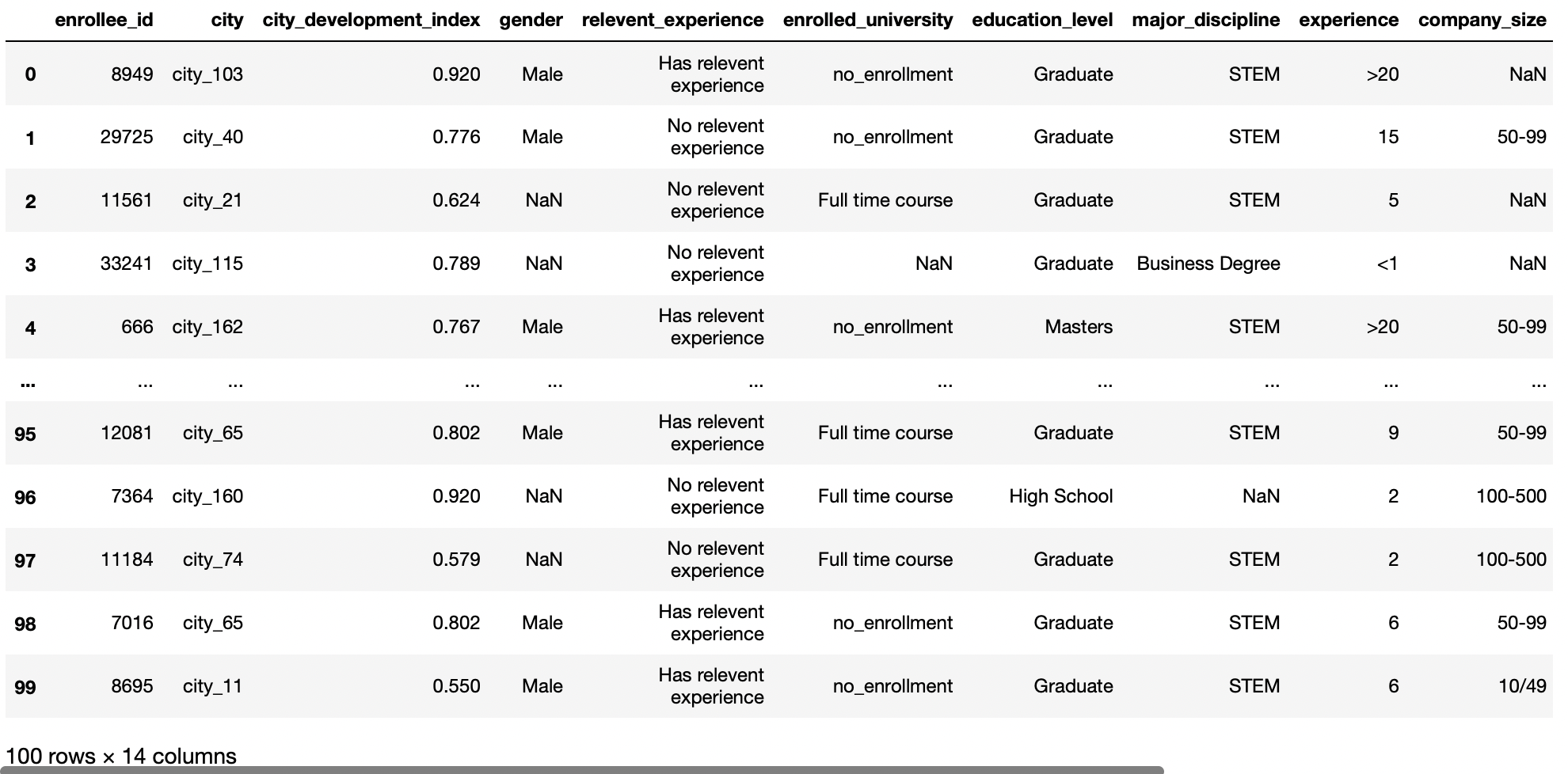
Abra um arquivo CSV local
Se o arquivo estiver presente no mesmo local que em nosso arquivo Python, em seguida, forneça o nome do arquivo apenas para fazer o upload desse arquivo; pelo contrário, você deve fornecer o caminho relativo a ele.
df = pd.read_csv('aug_train.csv')
df
Produção:
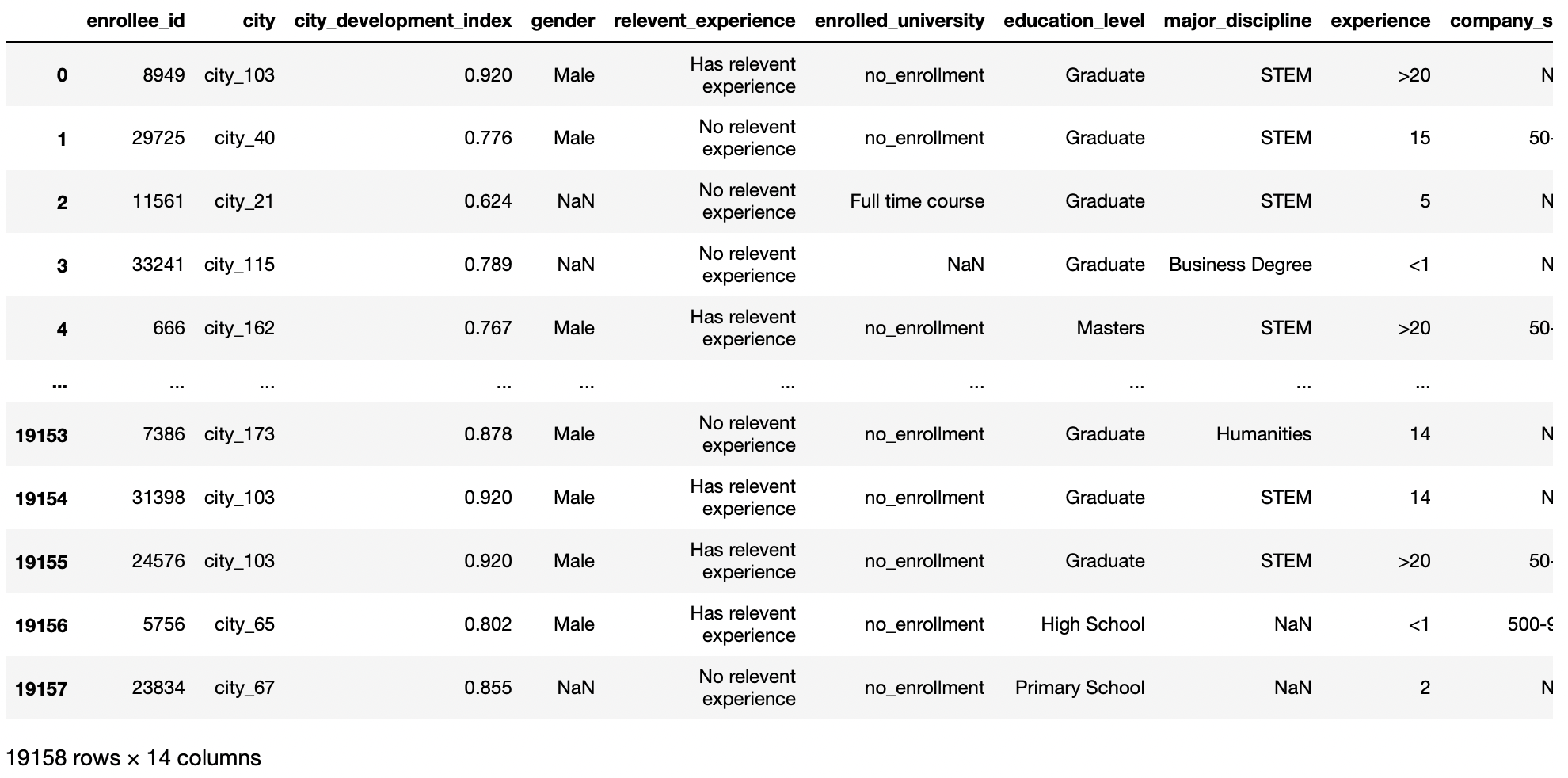
Abra um arquivo CSV de um URL
Se o arquivo não estiver presente diretamente em nossa máquina local, mas temos que pesquisar os dados de um determinado url, então pegamos a ajuda do módulo de solicitações para carregar esses dados.
pedidos de importação
from io import StringIO
url = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
cabeçalhos = {"Agente de usuário": "Mozilla / 5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko / 20100101 Firefox / 66.0"}
req = requests.get(url, headers = headers)
data = StringIO(req.text)
pd.read_csv(dados)
Produção:
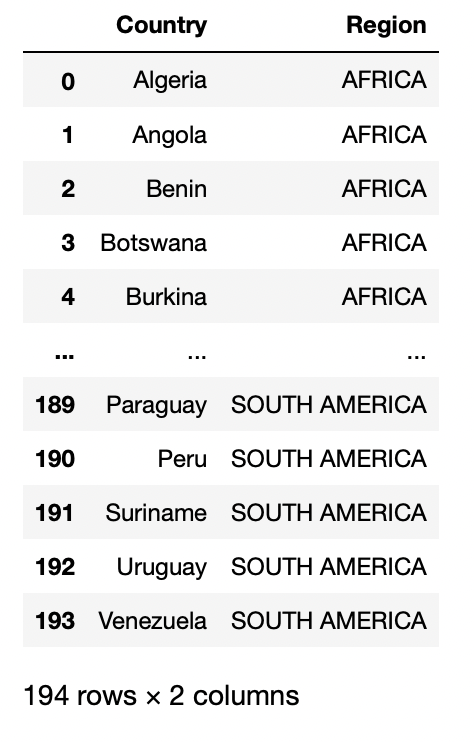
parâmetro sep
Se tivermos um conjunto de dados no qual as entidades em uma linha específica não são separadas por uma vírgula, então temos que usar o parâmetro sep para especificar o separador ou delimitador.
Por exemplo, Se tivermos um arquivo tsv, quer dizer, as entidades são separadas por guias e se tentarmos carregar diretamente esses dados, todas as entidades são carregadas combinadas.
importar pandas como pd
pd.read_csv('movie_titles_metadata.tsv')
Produção:
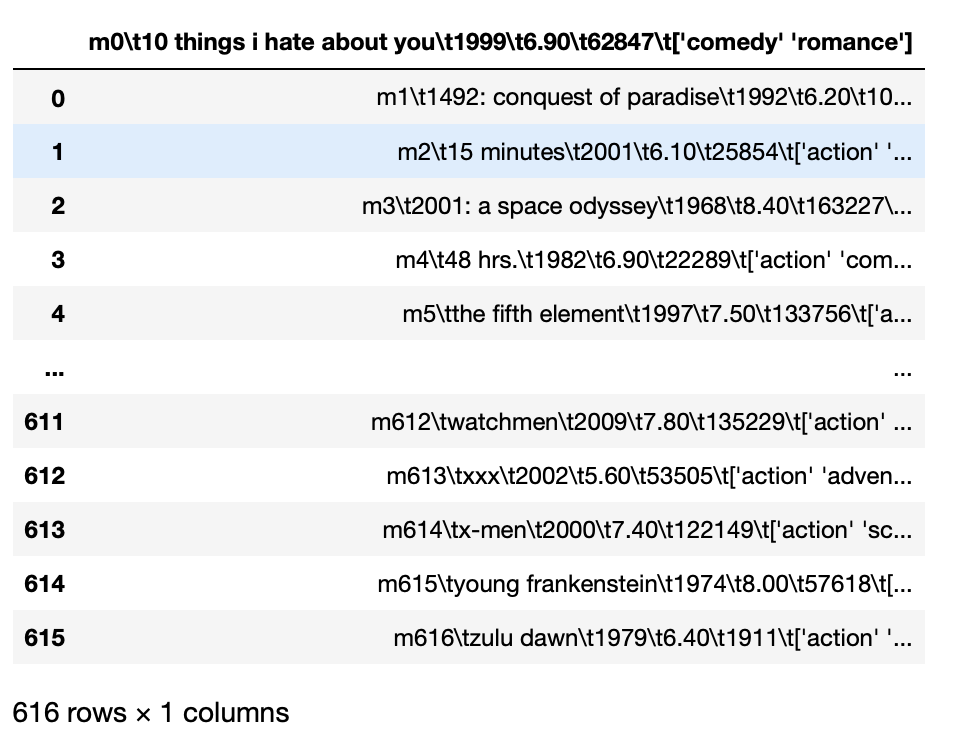
Para resolver o problema acima para o arquivo CSV, temos que substituir o parâmetro sep para ‘T’ ao invés de ‘,’ que é um separador padrão.
importar pandas como pd
pd.read_csv('movie_titles_metadata.tsv',sep = 't')
Produção:
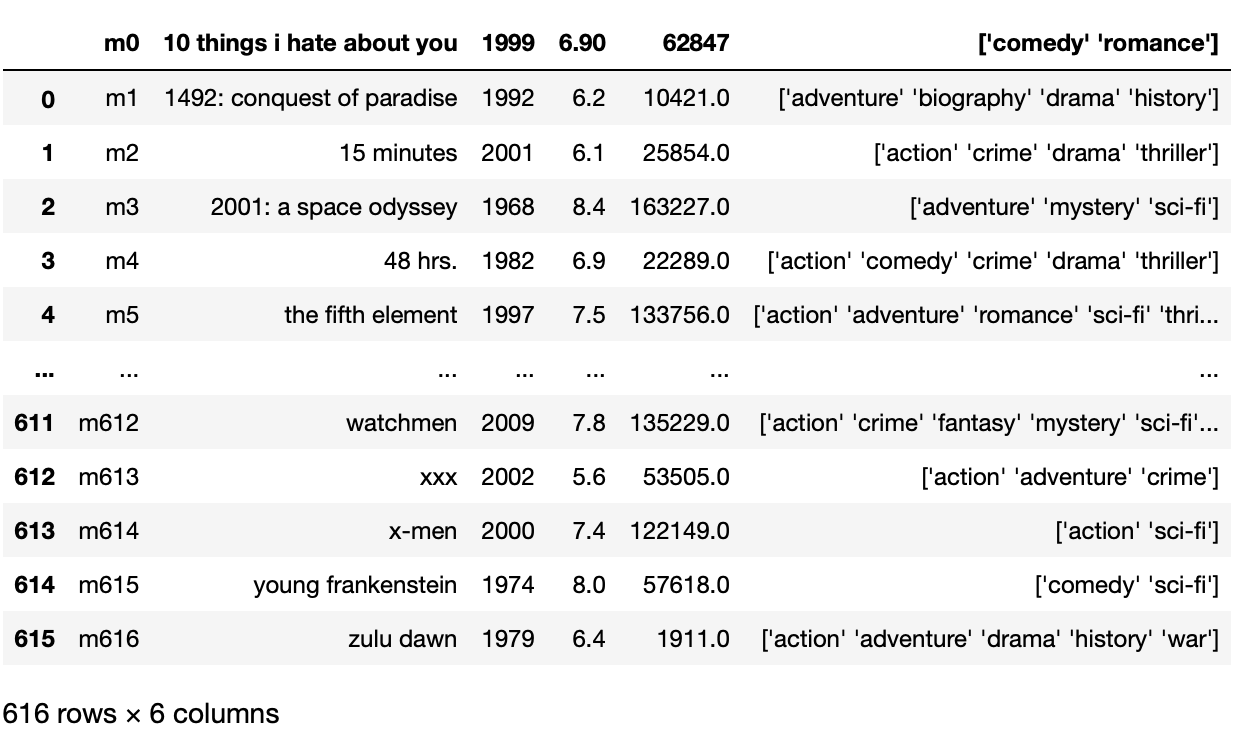
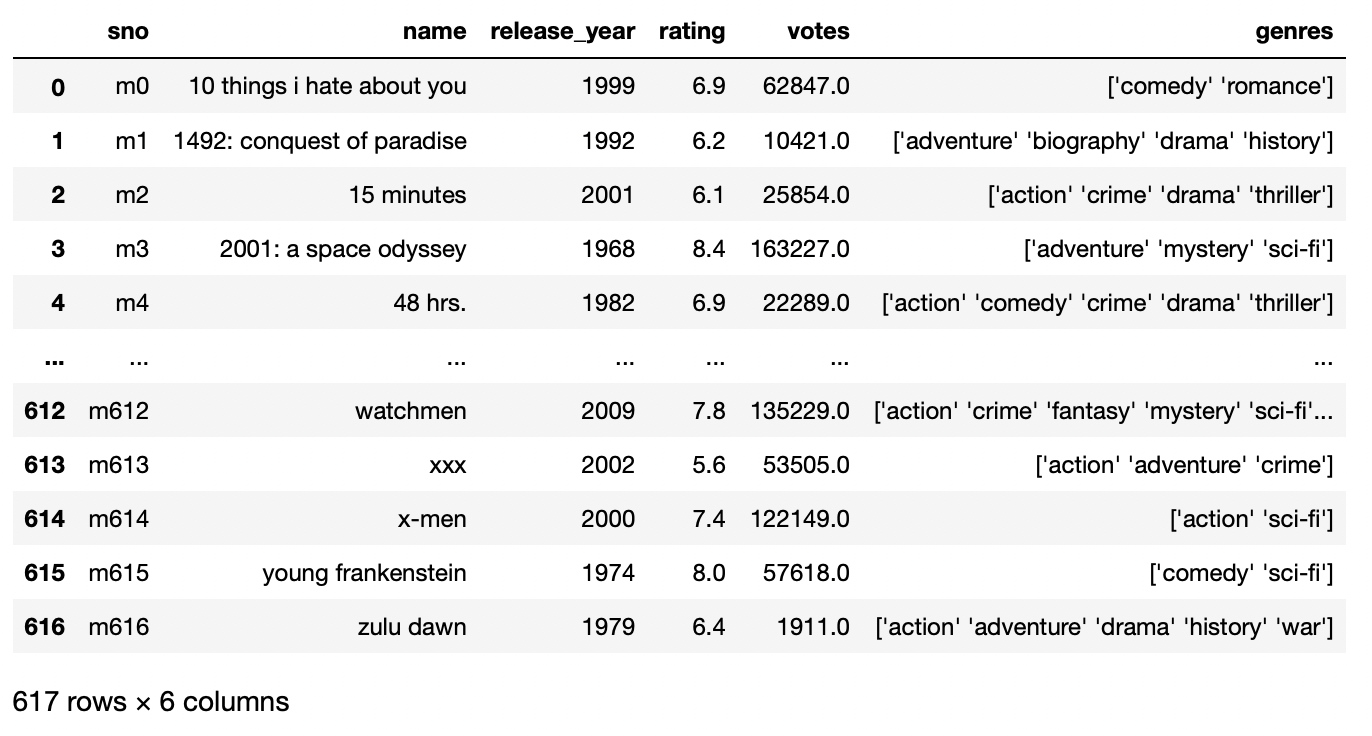
No exemplo acima, observamos que a primeira linha é tratada como o nome da coluna, e para resolver este problema e tornar nosso nome personalizado para as colunas, temos que especificar a lista de palavras com nomes como o nome da lista.
pd.read_csv('movie_titles_metadata.tsv',sep = 't',nomes =['sno','nome','ano de lançamento','Avaliação','votos','gêneros'])
Produção:
parâmetro index-col
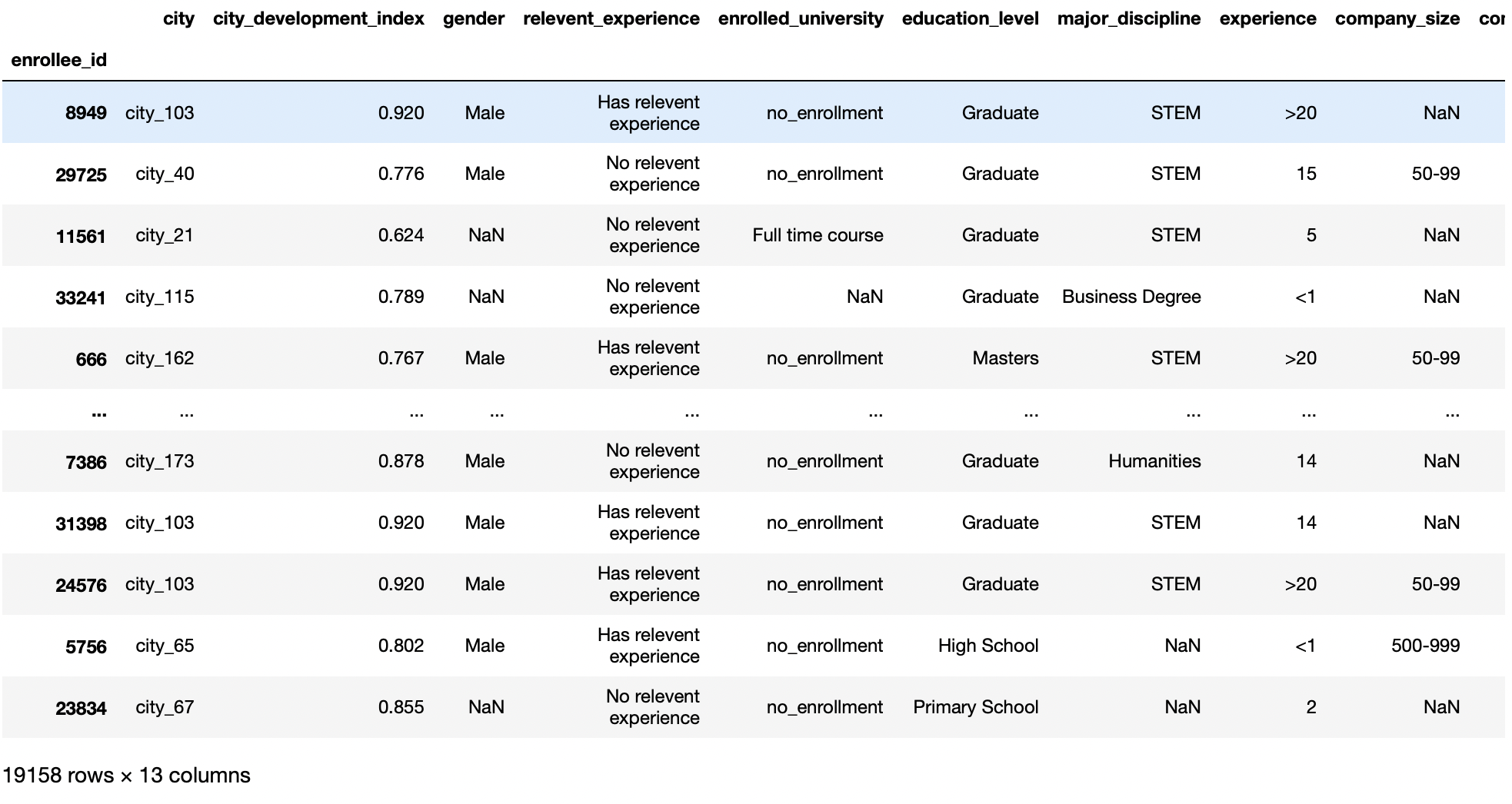
Este parâmetro nos permite definir quais colunas serão usadas como o índice do quadro de dados. O valor padrão para este parâmetro é Nenhum, e os pandas irão adicionar automaticamente uma nova coluna a partir de 0 para descrever a coluna de índice.
Então, nos permite usar uma coluna como rótulos de linha para um determinado DataFrame. Esta função é útil quando nos permite ter uma coluna de ID presente com nosso conjunto de dados e essa coluna não é afetada por nossas previsões, então fazemos dessa coluna nosso índice de linha em vez do padrão.
pd.read_csv('aug_train.csv',index_col ="enrollee_id")
Produção:
parâmetro de cabeçalho
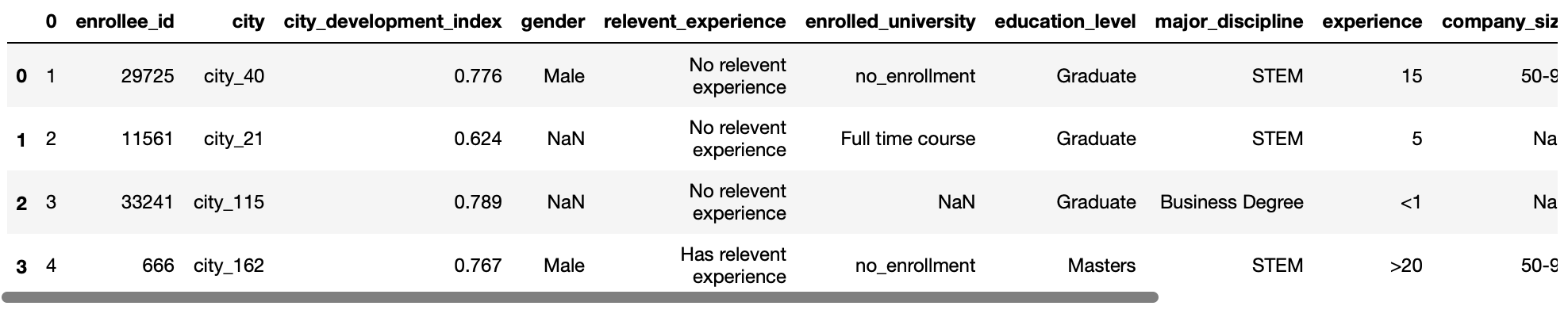
Isso nos permite especificar qual linha será usada como nomes de coluna para seu quadro de dados. Espere a entrada como um valor int ou uma lista de valores int.
O valor padrão para este parâmetro é header = 0, o que implica que a primeira linha do arquivo CSV será considerada como nomes de coluna.
pd.read_csv('test.csv',cabeçalho = 1)
Produção:
parâmetro use-cols
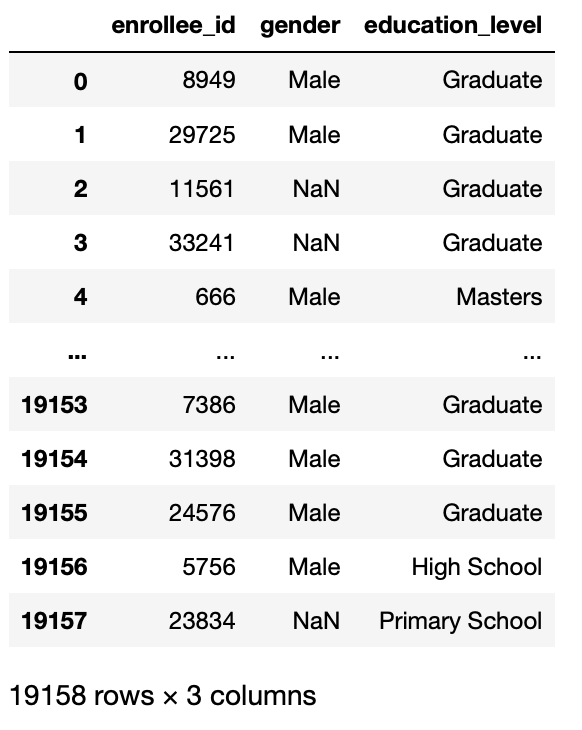
Especifique quais colunas importar do conjunto de dados completo para o quadro de dados. Você pode inserir uma lista de valores inteiros ou diretamente os nomes das colunas.
Esta função é útil quando temos que fazer nossa análise apenas em algumas colunas, não em todas as colunas do nosso conjunto de dados.
Então, este parâmetro retorna um subconjunto das colunas em seu conjunto de dados.
pd.read_csv('aug_train.csv',usecols =['enrollee_id','Gênero sexual','nível de educação'])
Produção:
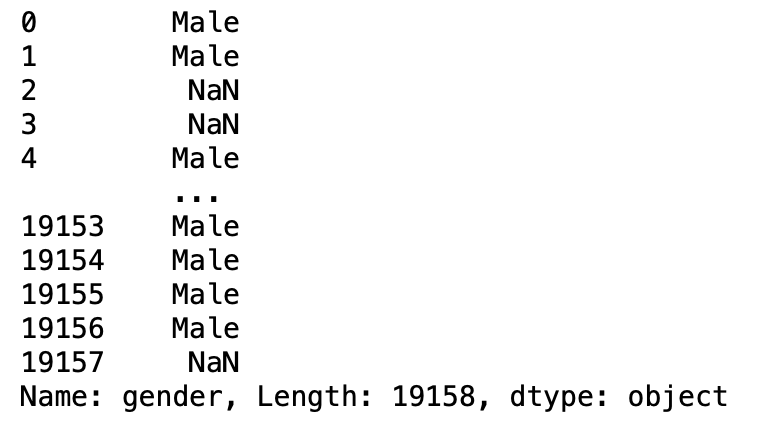
parâmetro de compressão
Se verdadeiro e apenas uma coluna é passada, retorna a string pandas em vez de um DataFrame.
pd.read_csv('aug_train.csv',usecols =['Gênero sexual'],squeeze = True)
Produção:
parâmetro skiprows
Este parâmetro é usado para pular linhas passadas no novo quadro de dados.
pd.read_csv('aug_train.csv',skiprows =[0,1])
Produção:
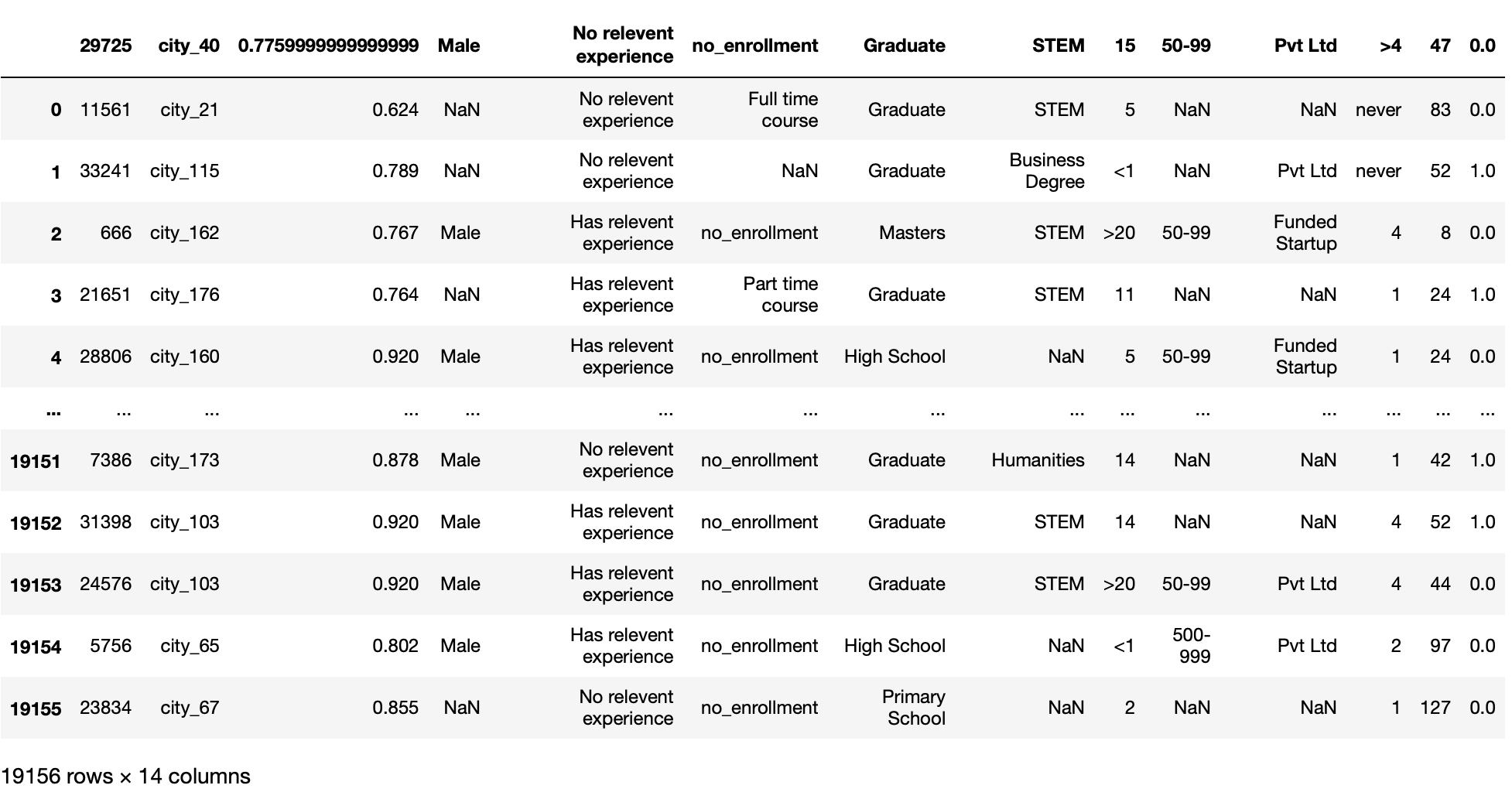
parâmetro nrows
Esta função só lê o número fixo (decidido pelo usuário) das primeiras linhas do arquivo. Você precisa de um valor int.
Este parâmetro é útil quando temos um grande conjunto de dados e queremos carregar nosso conjunto de dados em partes em vez de carregar diretamente o conjunto de dados inteiro.
pd.read_csv('aug_train.csv',nrows = 100)
Produção:
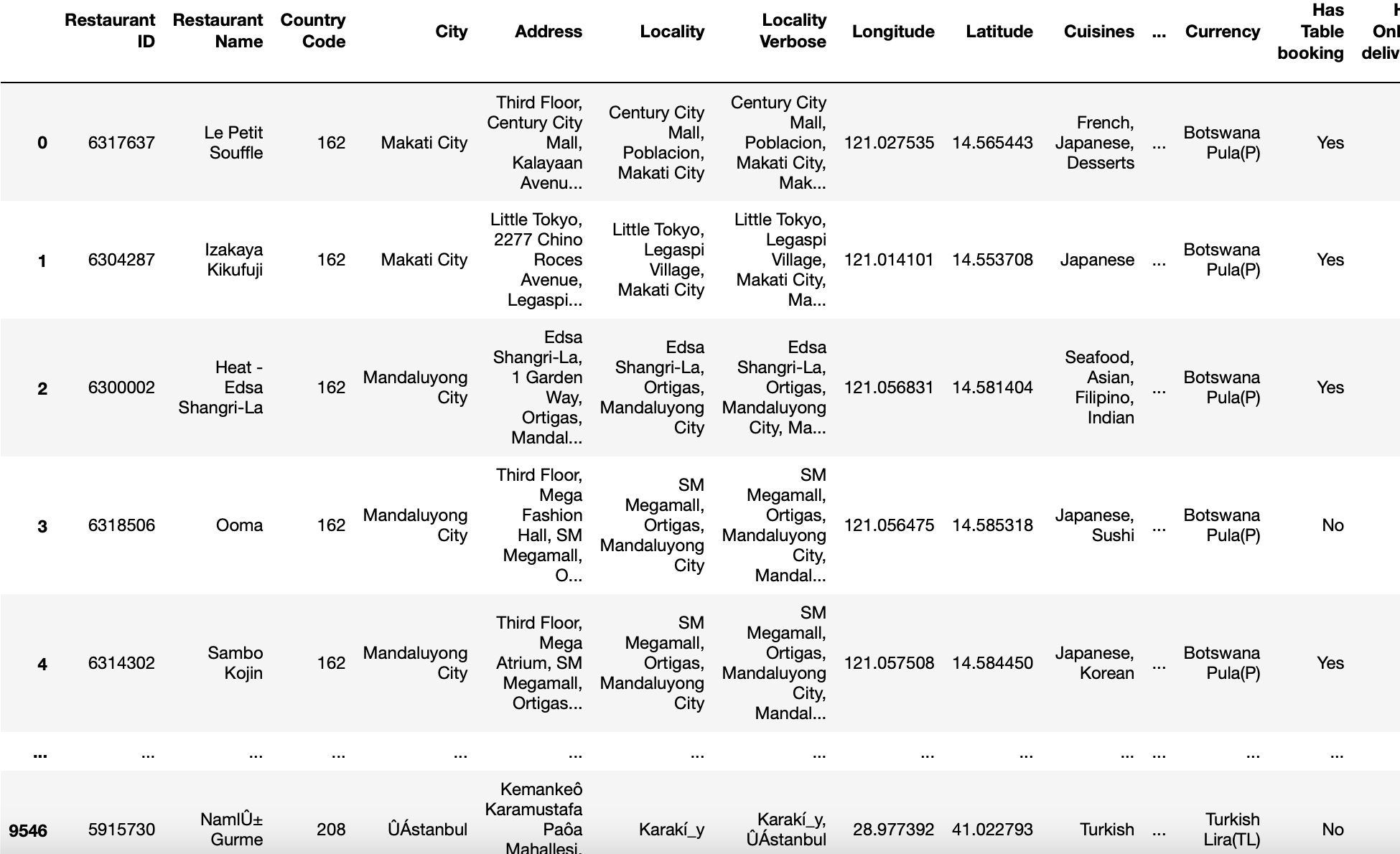
parâmetro de codificação
Este parâmetro ajuda a determinar qual codificação usar para UTF ao ler ou gravar arquivos.
As vezes, o que acontece é que nossos arquivos não são codificados da maneira padrão, quer dizer, UTF-8. Então, salve isso com um editor de texto ou adicione o parâmetro “Codificação = ‘utf-8 ′ não funciona. Em ambos os casos, retorna o erro.
Então, para resolver este problema, chamamos nossa função read_csv com encoding = ‘latin1 ′, codificação =’ iso-8859-1 ′ o encoding = ‘cp1252 ′ (estas são algumas das várias codificações encontradas no Windows).
pd.read_csv('zomato.csv',encoding = 'latin-1')
Produção:
parâmetro error-bad-lines
Se tivermos um conjunto de dados em que algumas linhas têm muitos campos (Por exemplo, uma linha CSV com muitas vírgulas), mais tarde, por padrão, uma exceção é lançada e causa, e nenhum DataFrame será retornado.
Então, para resolver este tipo de problema, temos que tornar este parâmetro False, então você é “linhas defeituosas” será removido do DataFrame que é retornado. (Válido apenas com analisador C)
pd.read_csv('BX-Books.csv', sep = ';', codificação ="latin-1",error_bad_lines = False)
Produção:
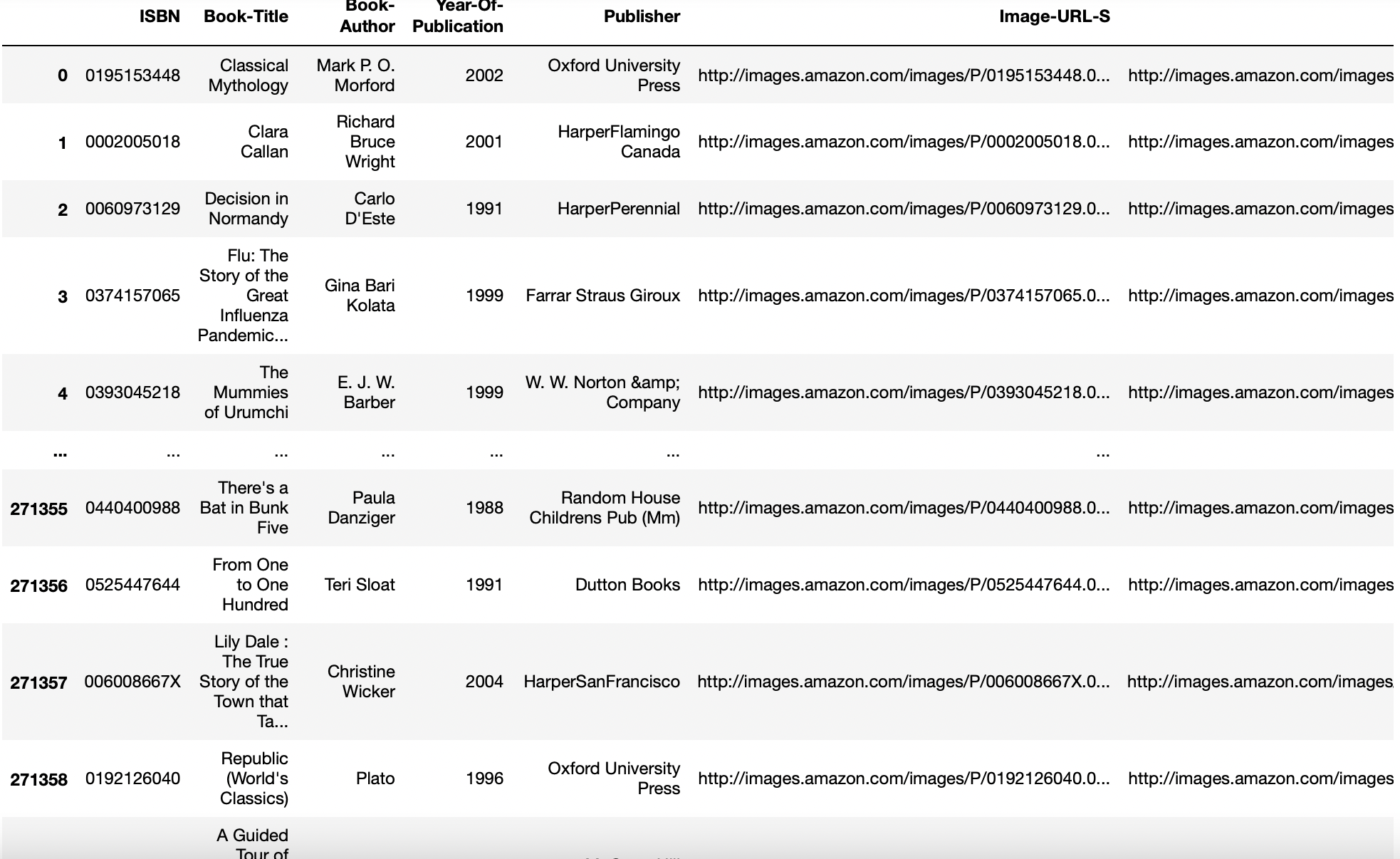
parâmetro dtype
Tipo de dados para dados ou colunas. Por exemplo, {'uma': por exemplo, float64, ‘B’: por exemplo, int32}
As vezes, para converter nossas colunas de tipo de dados float para tipo de dados int, esta função é útil.
pd.read_csv('aug_train.csv',dtype ={'alvo':int}).informação()
Produção:
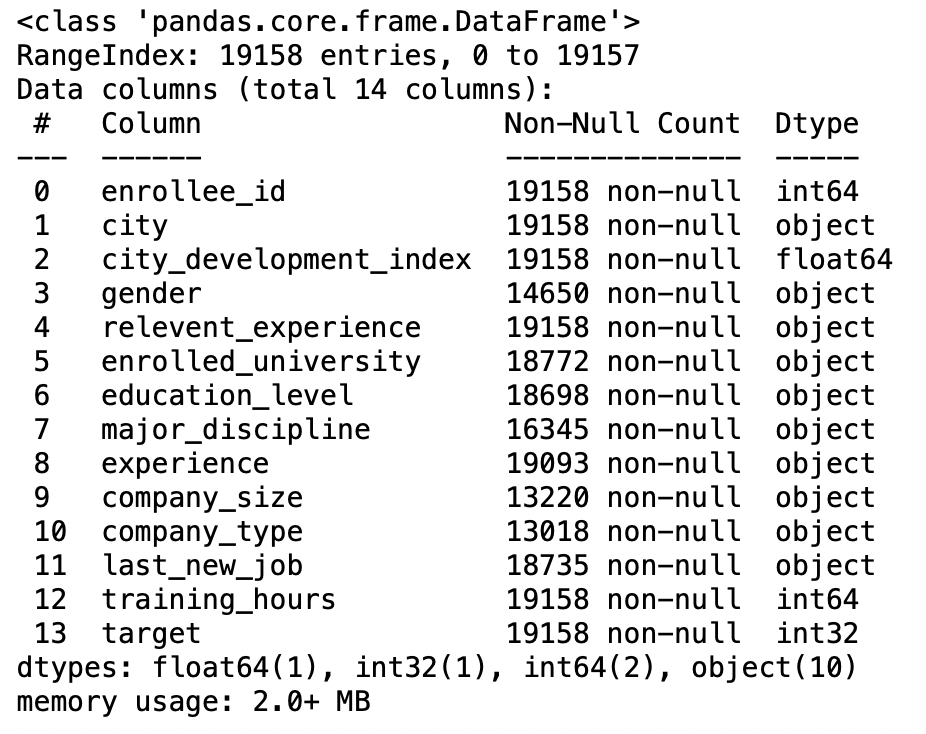
parâmetro de datas de análise
Se tornarmos este parâmetro True, em seguida, tente analisar o índice.
Por exemplo, E [1, 2, 3] -> tente analisar as colunas 1, 2, 3 cada um como uma coluna de data separada e se tivermos que combinar as colunas 1 e 3 e analisar como uma única coluna de data, usar [[1,3]].
pd.read_csv('IPL Matches 2008-2020.csv',parse_dates =['encontro']).informação()
Produção:
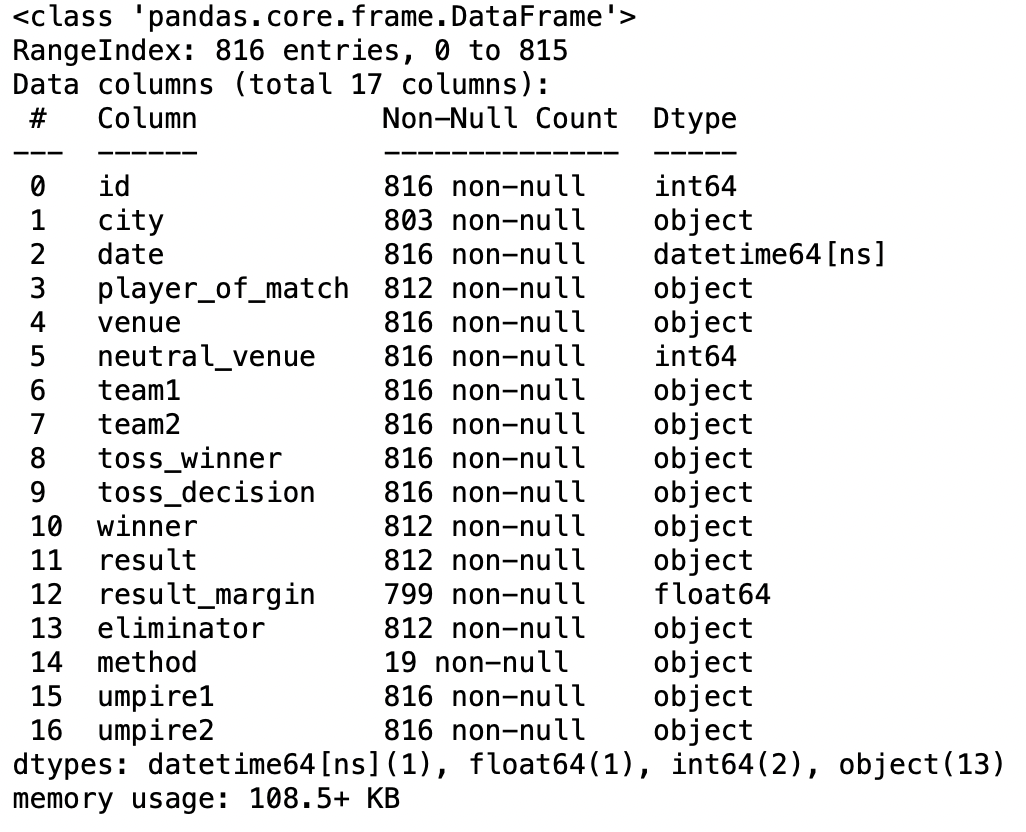
parâmetro de conversores
Este parâmetro nos ajuda a converter valores nas colunas com base em uma função personalizada fornecida pelo usuário.
def renomear(nome):
if name == "Royal Challengers Bangalore":
Retorna "RCB"
outro:
nome de retorno
renomear("Royal Challengers Bangalore")
Produção:
‘RCB’
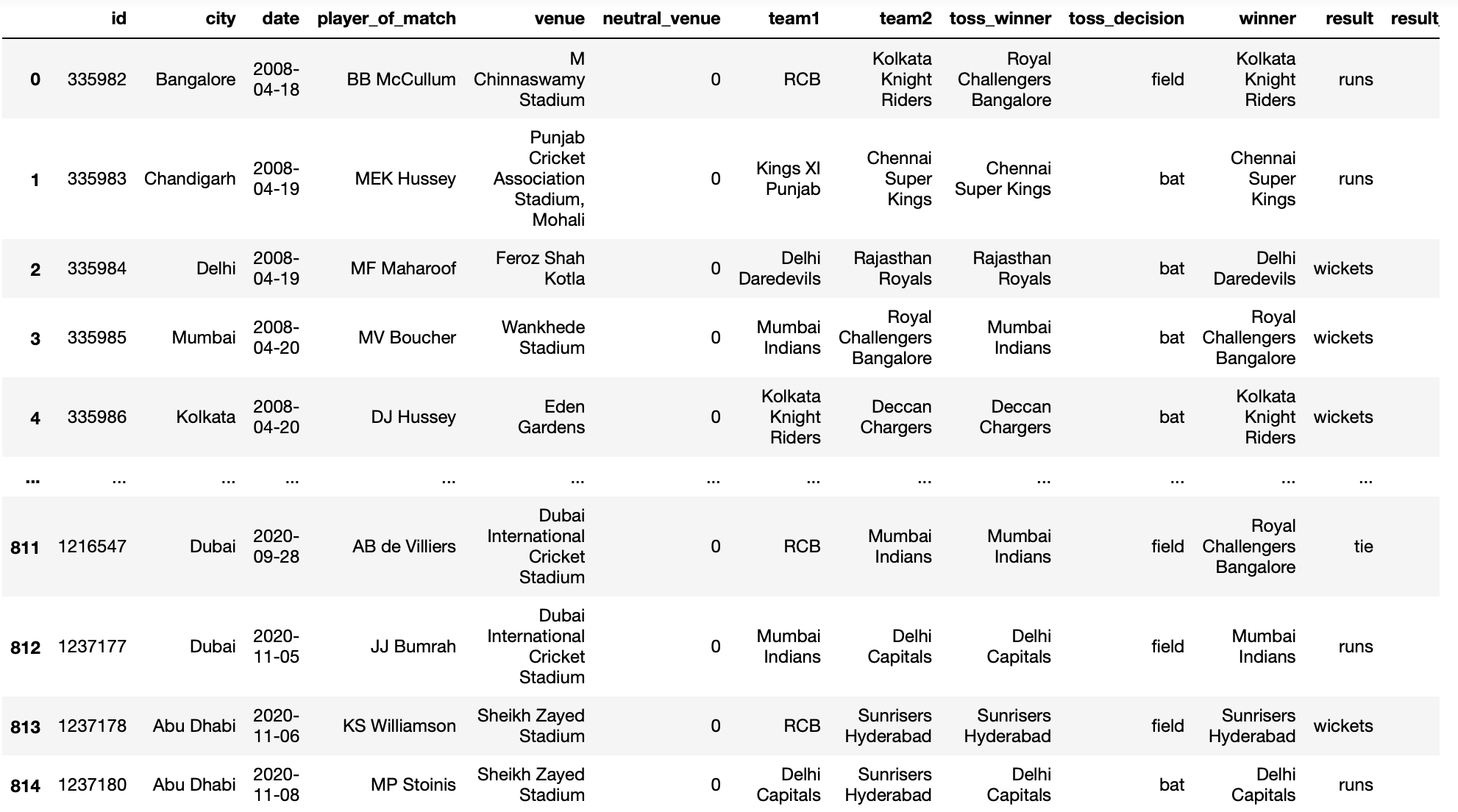
pd.read_csv('IPL Matches 2008-2020.csv',conversores ={'equipe1':renomear})
Produção:
valores de parâmetro em
Como sabemos, os valores omissos padrão serão NaN. Se quisermos que outras strings sejam consideradas como NaN, então temos que usar este parâmetro. Espere uma lista de strings como entrada.
As vezes, em nosso conjunto de dados, outro tipo de símbolo é usado para convertê-los em valores ausentes, então, naquele momento, para entender esses valores como perdidos, nós usamos este parâmetro.
pd.read_csv('aug_train.csv',na_values =['Masculino',])
Produção:
Isso conclui nossa discussão!!
NOTA: Neste artigo, Discutiremos apenas os parâmetros que são muito úteis ao trabalhar com arquivos CSV diariamente.. Mas se você estiver interessado em conhecer mais parâmetros, confira o site oficial do Pandas aqui.
Ou você pode se referir a este Ligação O que mais.
Notas finais
Obrigado pela leitura!
Se gostou e quer saber mais, vá para meus outros artigos sobre ciência de dados e aprendizado de máquina clicando no Ligação
Sinta-se à vontade para entrar em contato comigo em Linkedin, Correio eletrônico.
Qualquer coisa não mencionada ou você deseja compartilhar suas idéias? Sinta-se à vontade para comentar abaixo e eu entrarei em contato com você.
Sobre o autor
Chirag Goyal
Atualmente, Estou cursando bacharelado em tecnologia (B.Tech) em Ciência da Computação e Engenharia da Instituto Indiano de Tecnologia de Jodhpur (IITJ). Estou muito animado com o aprendizado de máquina, aprendizado profundo e inteligência artificial.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





